FM家族中的靓仔——DeepFM及其工程化实现(tensorflow2)
点击上方“数据与智能”,“星标或置顶公众号”
第一时间获取好内容


作者 | xulu1352 目前在一家互联网公司从事推荐算法工作(知乎:xulu1352)
编辑 | auroral-L
(本篇文章已获得作者的独家授权)
0.前序
在之前推荐算法中的倚天剑: FM (tensorflow2实现)一文中阐述了FM的相关原理知识,FM凭借其巧妙的特征组合机制一举成为前深度学习推荐算法中的闪亮之星;进入深度学习推荐算法时代后,在深度学习与FM算法多次交融中,诞生了一个靓仔——DeepFM,并迅速成为业界CTR预估模型的一个重要候选者。关于DeepFM原理,本文不作过多阐释,一方面关于它的原理相关资料网上已经足够丰富,二是因为DeepFM ≈ FM + DNN,再配上原论文中经典的DeepFM结构图,已经可以让人对其概念有个宏观的了解。还是挂上“Talk is cheap ,show me your code”这句,撸一遍code算法理解会更透彻~
1.DeepFM原理概要
首先来看看DeepFM网络结构,上图,一图胜千言:

在ctr预估建模中,核心思想,就是如何让模型学习到更好的特征表示。传统的DNN通过特征间隐式交叉,自动学习特征之间复杂的高阶组合关系,对连续特征来说,非常有效;但对于高度稀疏的特征来说,这种隐式交叉并未带来足够的优异性。是不是可以引入一些能够显式特征交叉学习结构,来弥补DNN特征学习的局限呢?基于此,涌现了多种宽模型与深度模型结合的经典之作,DeepFM模型便是其中之一。它联合了FM模型和DNN模型,一起训练,同时学习低阶特征组合和高阶特征组合。对于DeepFM模型,我认为其精华的部分在于,它的Deep和FM是共享Embedding层输入的,这样做的优点是Embedding层的权重向量在训练学习时可以同时接受到Deep侧与FM侧的信息,从而使Embedding层的表征信息学习的更加快速与准确,进而达到提升推荐效果。
从上面的DeepFM结构图中,我们可以归纳出DeepFM的输出公式:
即就是FM与DNN输出的加和。对于FM部分,我们又可以将其拆分为一阶线性加和部分与二阶特征交叉部分。
所以实现DeepFM可以分为三个部分:线性部分、FM二阶特征交叉部分、DNN部分。接下来就来看看DeepFM实现。
2.DeepFM实现
关于DeepFM的线性部分与DNN部分的实现本身没有特别之处,不做额外阐述,这里单独说说FM二阶特征交叉部分。

从上面式(3)可以看出,实现FM二阶特征交叉部分,只需两个操作项,第一项“和平方”,第二项“平方和”。将式(3)直译成code,如下:
class FMLayer(Layer):
"""Factorization Machine models pairwise (order-2) feature interactions
without linear term and bias.
Input shape
- 3D tensor with shape: ``(batch_size,field_size,embedding_size)``.
Output shape
- 2D tensor with shape: ``(batch_size, 1)``.
References
- [Factorization Machines](https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf)
"""
def __init__(self, **kwargs):
super(FMLayer, self).__init__(**kwargs)
def build(self, input_shape):
if len(input_shape) != 3:
raise ValueError("Unexpected inputs dimensions % d, expect to be 3 dimensions" % (len(input_shape)))
super(FMLayer, self).build(input_shape) # Be sure to call this somewhere!
def call(self, inputs, **kwargs):
if K.ndim(inputs) != 3:
raise ValueError(
"Unexpected inputs dimensions %d, expect to be 3 dimensions" % (K.ndim(inputs)))
concated_embeds_value = inputs
# 先求和再平方
square_of_sum = tf.square(tf.reduce_sum(concated_embeds_value, axis=1, keepdims=True))
# 先平方再求和
sum_of_square = tf.reduce_sum(concated_embeds_value * concated_embeds_value, axis=1, keepdims=True)
cross_term = square_of_sum - sum_of_square
cross_term = 0.5 * tf.reduce_sum(cross_term, axis=2, keepdims=False)
return cross_term
def compute_output_shape(self, input_shape):
return (None, 1)
好了,DeepFM实现的精华部分就如上了,下面就来看看DeepFM的模型搭建,整个代码框架参照了开源deepctr包,有些code组件依据需要做了改动,下面就来动动手撸一遍吧。
为了更好地演示DeepFM模型完整的搭建及训练,这里拟造部分我们真实场景所用数据,如下:

字段介绍:
act:为label数据 1:正样本,0:负样本
client_id: 用户id
post_type:物料item形式 图文 ,视频
client_type:用户客户端类型
follow_topic_id: 用户关注话题分类id
all_topic_fav_7: 用户画像特征,用户最近7天对话题偏爱度刻画,kv键值对形式
topic_id: 物料所属的话题
keyword_id: 物料item对应的权重最大的关键词id
import numpy as np
import pandas as pd
import datetime
import tensorflow as tf
from tensorflow.keras.layers import *
import tensorflow.keras.backend as K
from tensorflow.keras import layers
from tensorflow.keras.models import Model
from tensorflow.keras.callbacks import TensorBoard
from collections import namedtuple, OrderedDict
########################################################################
#################数据预处理##############
########################################################################
# 定义参数类型
SparseFeat = namedtuple('SparseFeat', ['name', 'voc_size', 'hash_size', 'share_embed','embed_dim', 'dtype'])
DenseFeat = namedtuple('DenseFeat', ['name', 'pre_embed','reduce_type','dim', 'dtype'])
VarLenSparseFeat = namedtuple('VarLenSparseFeat', ['name', 'voc_size','hash_size', 'share_embed', 'weight_name', 'combiner', 'embed_dim','maxlen', 'dtype'])
# 筛选实体标签categorical 用于定义映射关系
DICT_CATEGORICAL = {"topic_id": [str(i) for i in range(0, 700)],
"keyword_id": [str(i) for i in range(0, 10)],
}
feature_columns = [SparseFeat(name="topic_id", voc_size=700, hash_size= None,share_embed=None, embed_dim=8, dtype='int32'),
SparseFeat(name="keyword_id", voc_size=10, hash_size= None,share_embed=None, embed_dim=8, dtype='int32'),
SparseFeat(name='client_type', voc_size=2, hash_size= None,share_embed=None, embed_dim=8,dtype='int32'),
SparseFeat(name='post_type', voc_size=2, hash_size= None,share_embed=None, embed_dim=8,dtype='int32'),
VarLenSparseFeat(name="follow_topic_id", voc_size=700, hash_size= None, share_embed='topic_id', weight_name = None, combiner= 'sum', embed_dim=8, maxlen=20,dtype='int32'),
VarLenSparseFeat(name="all_topic_fav_7", voc_size=700, hash_size= None, share_embed='topic_id', weight_name = 'all_topic_fav_7_weight', combiner= 'sum', embed_dim=8, maxlen=5,dtype='int32'),
]
# 线性侧特征及交叉侧特征
linear_feature_columns_name = ["all_topic_fav_7", "follow_topic_id", 'client_type', 'post_type', "topic_id", "keyword_id"]
fm_group_column_name = ["topic_id", "follow_topic_id", "all_topic_fav_7", "keyword_id"]
linear_feature_columns = [col for col in feature_columns if col.name in linear_feature_columns_name ]
fm_group_columns = [col for col in feature_columns if col.name in fm_group_column_name ]
DEFAULT_VALUES = [[0],[''],[0.0],[0.0], [0.0],
[''], [''],[0.0]]
COL_NAME = ['act', 'client_id', 'client_type', 'post_type', 'topic_id', 'follow_topic_id', 'all_topic_fav_7', 'keyword_id']
def _parse_function(example_proto):
item_feats = tf.io.decode_csv(example_proto, record_defaults=DEFAULT_VALUES, field_delim='\t')
parsed = dict(zip(COL_NAME, item_feats))
feature_dict = {}
for feat_col in feature_columns:
if isinstance(feat_col, VarLenSparseFeat):
if feat_col.weight_name is not None:
kvpairs = tf.strings.split([parsed[feat_col.name]], ',').values[:feat_col.maxlen]
kvpairs = tf.strings.split(kvpairs, ':')
kvpairs = kvpairs.to_tensor()
feat_ids, feat_vals = tf.split(kvpairs, num_or_size_splits=2, axis=1)
feat_ids = tf.reshape(feat_ids, shape=[-1])
feat_vals = tf.reshape(feat_vals, shape=[-1])
if feat_col.dtype != 'string':
feat_ids= tf.strings.to_number(feat_ids, out_type=tf.int32)
feat_vals= tf.strings.to_number(feat_vals, out_type=tf.float32)
feature_dict[feat_col.name] = feat_ids
feature_dict[feat_col.weight_name] = feat_vals
else:
feat_ids = tf.strings.split([parsed[feat_col.name]], ',').values[:feat_col.maxlen]
feat_ids = tf.reshape(feat_ids, shape=[-1])
if feat_col.dtype != 'string':
feat_ids= tf.strings.to_number(feat_ids, out_type=tf.int32)
feature_dict[feat_col.name] = feat_ids
elif isinstance(feat_col, SparseFeat):
feature_dict[feat_col.name] = parsed[feat_col.name]
elif isinstance(feat_col, DenseFeat):
if not feat_col.pre_embed:
feature_dict[feat_col.name] = parsed[feat_col.name]
elif feat_col.reduce_type is not None:
keys = tf.strings.split(parsed[feat_col.pre_embed], ',')
emb = tf.nn.embedding_lookup(params=ITEM_EMBEDDING, ids=ITEM_ID2IDX.lookup(keys))
emb = tf.reduce_mean(emb,axis=0) if feat_col.reduce_type == 'mean' else tf.reduce_sum(emb,axis=0)
feature_dict[feat_col.name] = emb
else:
emb = tf.nn.embedding_lookup(params=ITEM_EMBEDDING, ids=ITEM_ID2IDX.lookup(parsed[feat_col.pre_embed]))
feature_dict[feat_col.name] = emb
else:
raise "unknown feature_columns...."
label = parsed['act']
return feature_dict, label
pad_shapes = {}
pad_values = {}
for feat_col in feature_columns:
if isinstance(feat_col, VarLenSparseFeat):
max_tokens = feat_col.maxlen
pad_shapes[feat_col.name] = tf.TensorShape([max_tokens])
pad_values[feat_col.name] = '0' if feat_col.dtype == 'string' else 0
if feat_col.weight_name is not None:
pad_shapes[feat_col.weight_name] = tf.TensorShape([max_tokens])
pad_values[feat_col.weight_name] = tf.constant(-1, dtype=tf.float32)
# no need to pad labels
elif isinstance(feat_col, SparseFeat):
if feat_col.dtype == 'string':
pad_shapes[feat_col.name] = tf.TensorShape([])
pad_values[feat_col.name] = '0'
else:
pad_shapes[feat_col.name] = tf.TensorShape([])
pad_values[feat_col.name] = 0.0
elif isinstance(feat_col, DenseFeat):
if not feat_col.pre_embed:
pad_shapes[feat_col.name] = tf.TensorShape([])
pad_values[feat_col.name] = 0.0
else:
pad_shapes[feat_col.name] = tf.TensorShape([feat_col.dim])
pad_values[feat_col.name] = 0.0
pad_shapes = (pad_shapes, (tf.TensorShape([])))
pad_values = (pad_values, (tf.constant(0, dtype=tf.int32)))
filenames= tf.data.Dataset.list_files([
'./user_item_act_test.csv',
])
dataset = filenames.flat_map(
lambda filepath: tf.data.TextLineDataset(filepath).skip(1))
batch_size = 2
dataset = dataset.map(_parse_function, num_parallel_calls=60)
dataset = dataset.repeat()
dataset = dataset.shuffle(buffer_size = batch_size) # 在缓冲区中随机打乱数据
dataset = dataset.padded_batch(batch_size = batch_size,
padded_shapes = pad_shapes,
padding_values = pad_values) # 每1024条数据为一个batch,生成一个新的Datasets
dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
# 验证集
filenames_val= tf.data.Dataset.list_files(['./user_item_act_test.csv'])
dataset_val = filenames_val.flat_map(
lambda filepath: tf.data.TextLineDataset(filepath).skip(1))
val_batch_size = 2
dataset_val = dataset_val.map(_parse_function, num_parallel_calls=60)
dataset_val = dataset_val.padded_batch(batch_size = val_batch_size,
padded_shapes = pad_shapes,
padding_values = pad_values) # 每1024条数据为一个batch,生成一个新的Datasets
dataset_val = dataset_val.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
########################################################################
#################自定义Layer##############
########################################################################
# 多值查找表稀疏SparseTensor >> EncodeMultiEmbedding
class VocabLayer(Layer):
def __init__(self, keys, mask_value=None, **kwargs):
super(VocabLayer, self).__init__(**kwargs)
self.mask_value = mask_value
vals = tf.range(2, len(keys) + 2)
vals = tf.constant(vals, dtype=tf.int32)
keys = tf.constant(keys)
self.table = tf.lookup.StaticHashTable(
tf.lookup.KeyValueTensorInitializer(keys, vals), 1)
def call(self, inputs):
idx = self.table.lookup(inputs)
if self.mask_value is not None:
masks = tf.not_equal(inputs, self.mask_value)
paddings = tf.ones_like(idx) * (0) # mask成 0
idx = tf.where(masks, idx, paddings)
return idx
def get_config(self):
config = super(VocabLayer, self).get_config()
config.update({'mask_value': self.mask_value, })
return config
class EmbeddingLookupSparse(Layer):
def __init__(self, embedding, has_weight=False, combiner='sum',**kwargs):
super(EmbeddingLookupSparse, self).__init__(**kwargs)
self.has_weight = has_weight
self.combiner = combiner
self.embedding = embedding
def build(self, input_shape):
super(EmbeddingLookupSparse, self).build(input_shape)
def call(self, inputs):
if self.has_weight:
idx, val = inputs
combiner_embed = tf.nn.embedding_lookup_sparse(self.embedding,sp_ids=idx, sp_weights=val, combiner=self.combiner)
else:
idx = inputs
combiner_embed = tf.nn.embedding_lookup_sparse(self.embedding,sp_ids=idx, sp_weights=None, combiner=self.combiner)
return tf.expand_dims(combiner_embed, 1)
def get_config(self):
config = super(EmbeddingLookupSparse, self).get_config()
config.update({'has_weight': self.has_weight, 'combiner':self.combiner})
return config
class EmbeddingLookup(Layer):
def __init__(self, embedding, **kwargs):
super(EmbeddingLookup, self).__init__(**kwargs)
self.embedding = embedding
def build(self, input_shape):
super(EmbeddingLookup, self).build(input_shape)
def call(self, inputs):
idx = inputs
embed = tf.nn.embedding_lookup(params=self.embedding, ids=idx)
return embed
def get_config(self):
config = super(EmbeddingLookup, self).get_config()
return config
# 稠密转稀疏
class DenseToSparseTensor(Layer):
def __init__(self, mask_value= -1, **kwargs):
super(DenseToSparseTensor, self).__init__()
self.mask_value = mask_value
def call(self, dense_tensor):
idx = tf.where(tf.not_equal(dense_tensor, tf.constant(self.mask_value , dtype=dense_tensor.dtype)))
sparse_tensor = tf.SparseTensor(idx, tf.gather_nd(dense_tensor, idx), tf.shape(dense_tensor, out_type=tf.int64))
return sparse_tensor
def get_config(self):
config = super(DenseToSparseTensor, self).get_config()
config.update({'mask_value': self.mask_value})
return config
class HashLayer(Layer):
"""
hash the input to [0,num_buckets)
if mask_zero = True,0 or 0.0 will be set to 0,other value will be set in range[1,num_buckets)
"""
def __init__(self, num_buckets, mask_zero=False, **kwargs):
self.num_buckets = num_buckets
self.mask_zero = mask_zero
super(HashLayer, self).__init__(**kwargs)
def build(self, input_shape):
# Be sure to call this somewhere!
super(HashLayer, self).build(input_shape)
def call(self, x, mask=None, **kwargs):
zero = tf.as_string(tf.zeros([1], dtype='int32'))
num_buckets = self.num_buckets if not self.mask_zero else self.num_buckets - 1
hash_x = tf.strings.to_hash_bucket_fast(x, num_buckets, name=None)
if self.mask_zero:
mask = tf.cast(tf.not_equal(x, zero), dtype='int64')
hash_x = (hash_x + 1) * mask
return hash_x
def get_config(self, ):
config = super(HashLayer, self).get_config()
config.update({'num_buckets': self.num_buckets, 'mask_zero': self.mask_zero, })
return config
class Add(tf.keras.layers.Layer):
def __init__(self, **kwargs):
super(Add, self).__init__(**kwargs)
def build(self, input_shape):
# Be sure to call this somewhere!
super(Add, self).build(input_shape)
def call(self, inputs, **kwargs):
if not isinstance(inputs,list):
return inputs
if len(inputs) == 1 :
return inputs[0]
if len(inputs) == 0:
return tf.constant([[0.0]])
return tf.keras.layers.add(inputs)
class FMLayer(Layer):
"""Factorization Machine models pairwise (order-2) feature interactions
without linear term and bias.
Input shape
- 3D tensor with shape: ``(batch_size,field_size,embedding_size)``.
Output shape
- 2D tensor with shape: ``(batch_size, 1)``.
References
- [Factorization Machines](https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf)
"""
def __init__(self, **kwargs):
super(FMLayer, self).__init__(**kwargs)
def build(self, input_shape):
if len(input_shape) != 3:
raise ValueError("Unexpected inputs dimensions % d, expect to be 3 dimensions" % (len(input_shape)))
super(FMLayer, self).build(input_shape) # Be sure to call this somewhere!
def call(self, inputs, **kwargs):
if K.ndim(inputs) != 3:
raise ValueError(
"Unexpected inputs dimensions %d, expect to be 3 dimensions" % (K.ndim(inputs)))
concated_embeds_value = inputs
# 先求和再平方
square_of_sum = tf.square(tf.reduce_sum(concated_embeds_value, axis=1, keepdims=True))
# 先平方再求和
sum_of_square = tf.reduce_sum(concated_embeds_value * concated_embeds_value, axis=1, keepdims=True)
cross_term = square_of_sum - sum_of_square
cross_term = 0.5 * tf.reduce_sum(cross_term, axis=2, keepdims=False)
return cross_term
def compute_output_shape(self, input_shape):
return (None, 1)
########################################################################
#################定义输入帮助函数##############
########################################################################
# 定义model输入特征
def build_input_features(features_columns, prefix=''):
input_features = OrderedDict()
for feat_col in features_columns:
if isinstance(feat_col, DenseFeat):
input_features[feat_col.name] = Input([feat_col.dim], name=feat_col.name)
elif isinstance(feat_col, SparseFeat):
input_features[feat_col.name] = Input([1], name=feat_col.name, dtype=feat_col.dtype)
elif isinstance(feat_col, VarLenSparseFeat):
input_features[feat_col.name] = Input([None], name=feat_col.name, dtype=feat_col.dtype)
if feat_col.weight_name is not None:
input_features[feat_col.weight_name] = Input([None], name=feat_col.weight_name, dtype='float32')
else:
raise TypeError("Invalid feature column in build_input_features: {}".format(feat_col.name))
return input_features
# 构造 自定义embedding层 matrix
def build_embedding_matrix(features_columns, linear_dim=None):
embedding_matrix = {}
for feat_col in features_columns:
if isinstance(feat_col, SparseFeat) or isinstance(feat_col, VarLenSparseFeat):
vocab_name = feat_col.share_embed if feat_col.share_embed else feat_col.name
vocab_size = feat_col.voc_size + 2
embed_dim = feat_col.embed_dim if linear_dim is None else 1
name_tag = '' if linear_dim is None else '_linear'
if vocab_name not in embedding_matrix:
embedding_matrix[vocab_name] = tf.Variable(initial_value=tf.random.truncated_normal(shape=(vocab_size, embed_dim),mean=0.0,
stddev=0.001, dtype=tf.float32), trainable=True, name=vocab_name+'_embed'+name_tag)
return embedding_matrix
# 构造 自定义embedding层
def build_embedding_dict(features_columns):
embedding_dict = {}
embedding_matrix = build_embedding_matrix(features_columns)
for feat_col in features_columns:
if isinstance(feat_col, SparseFeat):
vocab_name = feat_col.share_embed if feat_col.share_embed else feat_col.name
embedding_dict[feat_col.name] = EmbeddingLookup(embedding=embedding_matrix[vocab_name],name='emb_lookup_' + feat_col.name)
elif isinstance(feat_col, VarLenSparseFeat):
vocab_name = feat_col.share_embed if feat_col.share_embed else feat_col.name
if feat_col.combiner is not None:
if feat_col.weight_name is not None:
embedding_dict[feat_col.name] = EmbeddingLookupSparse(embedding=embedding_matrix[vocab_name],combiner=feat_col.combiner, has_weight=True, name='emb_lookup_sparse_' + feat_col.name)
else:
embedding_dict[feat_col.name] = EmbeddingLookupSparse(embedding=embedding_matrix[vocab_name], combiner=feat_col.combiner, name='emb_lookup_sparse_' + feat_col.name)
else:
embedding_dict[feat_col.name] = EmbeddingLookup(embedding=embedding_matrix[vocab_name],name='emb_lookup_' + feat_col.name)
return embedding_dict
# 构造 自定义embedding层
def build_linear_embedding_dict(features_columns):
embedding_dict = {}
embedding_matrix = build_embedding_matrix(features_columns, linear_dim=1)
name_tag = '_linear'
for feat_col in features_columns:
if isinstance(feat_col, SparseFeat):
vocab_name = feat_col.share_embed if feat_col.share_embed else feat_col.name
embedding_dict[feat_col.name] = EmbeddingLookup(embedding=embedding_matrix[vocab_name],name='emb_lookup_' + feat_col.name+name_tag)
elif isinstance(feat_col, VarLenSparseFeat):
vocab_name = feat_col.share_embed if feat_col.share_embed else feat_col.name
if feat_col.combiner is not None:
if feat_col.weight_name is not None:
embedding_dict[feat_col.name] = EmbeddingLookupSparse(embedding=embedding_matrix[vocab_name],combiner=feat_col.combiner, has_weight=True, name='emb_lookup_sparse_' + feat_col.name +name_tag)
else:
embedding_dict[feat_col.name] = EmbeddingLookupSparse(embedding=embedding_matrix[vocab_name], combiner=feat_col.combiner, name='emb_lookup_sparse_' + feat_col.name+name_tag)
else:
embedding_dict[feat_col.name] = EmbeddingLookup(embedding=embedding_matrix[vocab_name],name='emb_lookup_' + feat_col.name+name_tag)
return embedding_dict
# dense 与 embedding特征输入
def input_from_feature_columns(features, features_columns, embedding_dict):
sparse_embedding_list = []
dense_value_list = []
for feat_col in features_columns:
if isinstance(feat_col, SparseFeat):
_input = features[feat_col.name]
if feat_col.dtype == 'string':
if feat_col.hash_size is None:
vocab_name = feat_col.share_embed if feat_col.share_embed else feat_col.name
keys = DICT_CATEGORICAL[vocab_name]
_input = VocabLayer(keys)(_input)
else:
_input = HashLayer(num_buckets=feat_col.hash_size, mask_zero=False)(_input)
embed = embedding_dict[feat_col.name](_input)
sparse_embedding_list.append(embed)
elif isinstance(feat_col, VarLenSparseFeat):
_input = features[feat_col.name]
if feat_col.dtype == 'string':
if feat_col.hash_size is None:
vocab_name = feat_col.share_embed if feat_col.share_embed else feat_col.name
keys = DICT_CATEGORICAL[vocab_name]
_input = VocabLayer(keys, mask_value='0')(_input)
else:
_input = HashLayer(num_buckets=feat_col.hash_size, mask_zero=True)(_input)
if feat_col.combiner is not None:
input_sparse = DenseToSparseTensor(mask_value=0)(_input)
if feat_col.weight_name is not None:
weight_sparse = DenseToSparseTensor()(features[feat_col.weight_name])
embed = embedding_dict[feat_col.name]([input_sparse, weight_sparse])
else:
embed = embedding_dict[feat_col.name](input_sparse)
else:
embed = embedding_dict[feat_col.name](_input)
sparse_embedding_list.append(embed)
elif isinstance(feat_col, DenseFeat):
dense_value_list.append(features[feat_col.name])
else:
raise TypeError("Invalid feature column in input_from_feature_columns: {}".format(feat_col.name))
return sparse_embedding_list, dense_value_list
def concat_func(inputs, axis=-1):
if len(inputs) == 1:
return inputs[0]
else:
return Concatenate(axis=axis)(inputs)
def combined_dnn_input(sparse_embedding_list, dense_value_list):
if len(sparse_embedding_list) > 0 and len(dense_value_list) > 0:
sparse_dnn_input = Flatten()(concat_func(sparse_embedding_list))
dense_dnn_input = Flatten()(concat_func(dense_value_list))
return concat_func([sparse_dnn_input, dense_dnn_input])
elif len(sparse_embedding_list) > 0:
return Flatten()(concat_func(sparse_embedding_list))
elif len(dense_value_list) > 0:
return Flatten()(concat_func(dense_value_list))
else:
raise "dnn_feature_columns can not be empty list"
def get_linear_logit(sparse_embedding_list, dense_value_list):
if len(sparse_embedding_list) > 0 and len(dense_value_list) > 0:
sparse_linear_layer = Add()(sparse_embedding_list)
sparse_linear_layer = Flatten()(sparse_linear_layer)
dense_linear = concat_func(dense_value_list)
dense_linear_layer = Dense(1)(dense_linear)
linear_logit = Add()([dense_linear_layer, sparse_linear_layer])
return linear_logit
elif len(sparse_embedding_list) > 0:
sparse_linear_layer = Add()(sparse_embedding_list)
sparse_linear_layer = Flatten()(sparse_linear_layer)
return sparse_linear_layer
elif len(dense_value_list) > 0:
dense_linear = concat_func(dense_value_list)
dense_linear_layer = Dense(1)(dense_linear)
return dense_linear_layer
else:
raise "linear_feature_columns can not be empty list"
########################################################################
#################定义模型##############
########################################################################
def DeepFM(linear_feature_columns, fm_group_columns, dnn_hidden_units=(128, 128), dnn_activation='relu', seed=1024,):
"""Instantiates the DeepFM Network architecture.
Args:
linear_feature_columns: An iterable containing all the features used by linear part of the model.
fm_group_columns: list, group_name of features that will be used to do feature interactions.
dnn_hidden_units: list,list of positive integer or empty list, the layer number and units in each layer of DNN
seed: integer ,to use as random seed.
dnn_activation: Activation function to use in DNN
return: A Keras model instance.
"""
feature_columns = linear_feature_columns + fm_group_columns
features = build_input_features(feature_columns)
inputs_list = list(features.values())
# 构建 linear embedding_dict
linear_embedding_dict = build_linear_embedding_dict(linear_feature_columns)
linear_sparse_embedding_list, linear_dense_value_list = input_from_feature_columns(features, feature_columns, linear_embedding_dict)
# linear part
linear_logit = get_linear_logit(linear_sparse_embedding_list, linear_dense_value_list)
# 构建 embedding_dict
cross_columns = fm_group_columns
embedding_dict = build_embedding_dict(cross_columns)
sparse_embedding_list, _ = input_from_feature_columns(features, cross_columns, embedding_dict)
# 将所有sparse的k维embedding拼接起来,得到 (n, k)的矩阵,其中n为特征数,
concat_sparse_kd_embed = Concatenate(axis=1, name="fm_concatenate")(sparse_embedding_list) # ?, n, k
# FM cross part
fm_cross_logit = FMLayer()(concat_sparse_kd_embed)
# DNN part
dnn_input = combined_dnn_input(sparse_embedding_list, [])
for i in range(len(dnn_hidden_units)):
if i == len(dnn_hidden_units) - 1:
dnn_out = Dense(units=dnn_hidden_units[i], activation='relu', name='dnn_'+str(i))(dnn_input)
break
dnn_input = Dense(units=dnn_hidden_units[i], activation='relu', name='dnn_'+str(i))(dnn_input)
dnn_logit = Dense(1, use_bias=False, activation=None, kernel_initializer=tf.keras.initializers.glorot_normal(seed),name='dnn_logit')(dnn_out)
final_logit = Add()([ linear_logit, fm_cross_logit, dnn_logit])
output = tf.keras.layers.Activation("sigmoid", name="dfm_out")(final_logit)
model = Model(inputs=inputs_list, outputs=output)
return model
########################################################################
#################模型训练##############
########################################################################
model = DeepFM(linear_feature_columns, fm_group_columns, dnn_hidden_units=(128, 128), dnn_activation='relu', seed=1024,)
model.compile(optimizer="adam", loss= "binary_crossentropy", metrics=tf.keras.metrics.AUC(name='auc'))
log_dir = '/mywork/tensorboardshare/logs/' + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tbCallBack = TensorBoard(log_dir=log_dir, # log 目录
histogram_freq=0, # 按照何等频率(epoch)来计算直方图,0为不计算
write_graph=True, # 是否存储网络结构图
write_images=True,# 是否可视化参数
update_freq='epoch',
embeddings_freq=0,
embeddings_layer_names=None,
embeddings_metadata=None,
profile_batch = 20)
total_train_sample = 100
total_test_sample = 100
train_steps_per_epoch=np.floor(total_train_sample/batch_size).astype(np.int32)
test_steps_per_epoch = np.ceil(total_test_sample/val_batch_size).astype(np.int32)
history_loss = model.fit(dataset, epochs=3,
steps_per_epoch=train_steps_per_epoch,
validation_data=dataset_val, validation_steps=test_steps_per_epoch,
verbose=1,callbacks=[tbCallBack])
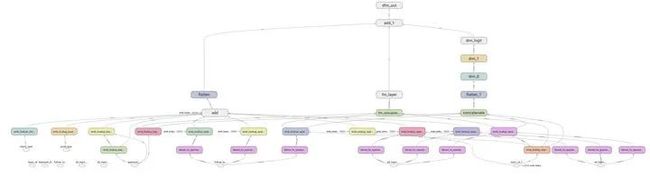
DeepFM搭建模型的整体代码就如上了,感兴趣的同学可以copy代码跑跑,动手才是王道,下面我们看看上述code搭建的模型结构
参考文献:
深度学习推荐模型DeepFM技术剖析:助力华为应用市场APP推荐
Charles Xiao:ctr预估之DeepFM
shenweichen/DeepCTR

