增强感受野SPP、ASPP、RFB、PPM
1、SPP(Spatial Pyramid Pooling)
SPP模块是何凯明大神在2015年的论文《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》中被提出。
由于CNN网络后面接的全连接层需要固定的输入大小,故往往通过将输入图像resize到固定大小的方式输入卷积网络,这会造成几何失真影响精度。SPP模块就解决了这一问题,他通过三种尺度的池化,将任意大小的特征图固定为相同长度的特征向量,传输给全连接层。因为卷积层后面的全连接层的结构是固定的。但在现实中,我们的输入的图像尺寸总是不能满足输入时要求的大小,然而通常的手法就是裁剪(crop)和拉伸(warp),但这样做总归是不好的,其扭曲了原始的特征。而SPP层通过将候选区的特征图划分为多个不同尺寸的网格,然后对每个网格内都做最大池化,这样依旧可以让后面的全连接层得到固定的输入。

上图,将256 channels 的 feature map 作为输入,在SPP layer被分成1x1,2x2,4x4三个pooling结构,对每个输入都作max pooling(论文使用的),这样无论输入图像大小如何,出来的特征固定是(16+4+1)x256维度。这样就实现了不管图像中候选区域尺寸如何,SPP层的输出永远是(16+4+1) x 256 特征向量。
Spp代码:
#coding=utf-8
import math
import torch
import torch.nn.functional as F
# 构建SPP层(空间金字塔池化层)
class SPPLayer(torch.nn.Module):
def __init__(self, num_levels, pool_type='max_pool'):
super(SPPLayer, self).__init__()
self.num_levels = num_levels
self.pool_type = pool_type
def forward(self, x):
num, c, h, w = x.size() # num:样本数量 c:通道数 h:高 w:宽
for i in range(self.num_levels):
level = i+1
kernel_size = (math.ceil(h / level), math.ceil(w / level))
stride = (math.ceil(h / level), math.ceil(w / level))
pooling = (math.floor((kernel_size[0]*level-h+1)/2), math.floor((kernel_size[1]*level-w+1)/2))
# 选择池化方式
if self.pool_type == 'max_pool':
tensor = F.max_pool2d(x, kernel_size=kernel_size, stride=stride, padding=pooling).view(num, -1)
else:
tensor = F.avg_pool2d(x, kernel_size=kernel_size, stride=stride, padding=pooling).view(num, -1)
# 展开、拼接
if (i == 0):
x_flatten = tensor.view(num, -1)
else:
x_flatten = torch.cat((x_flatten, tensor.view(num, -1)), 1)
return x_flatten
2、ASPP(Atrous Spatial Pyramid Pooling)
受到SPP的启发,语义分割模型DeepLabv2中提出了ASPP模块,该模块使用具有不同采样率的多个并行空洞卷积层。为每个采样率提取的特征在单独的分支中进一步处理,并融合以生成最终结果。该模块通过不同的空洞rate构建不同感受野的卷积核,用来获取多尺度物体信息,具体结构比较简单如下图所示:

ASPP(atrous spatial pyramid pooling)是在deeplab中提出来的,在后续的deeplab版本中对其做了改进,如加入BN层、加入深度可分离卷积等,但基本的思路还是没变。
讲到ASPP时,首先需要提到空洞卷积(Atrous/Dilated Convolution)。在于语义分割任务中,想要对图片提取的特征具有较大的感受野,并且又想让特征图的分辨率不下降太多(分辨率损失太多会丢失许多关于图像边界的细节信息),但这两个是矛盾的,想要获取较大感受野需要用较大的卷积核或池化时采用较大的strid,对于前者计算量太大,后者会损失分辨率。而空洞卷积就是用来解决这个矛盾的。即可让其获得较大感受野,又可让分辨率不损失太多。空洞卷积如下图:

(a)是rate=1的空洞卷积,卷积核的感受野为3×3,其实就是普通的卷积。
(b)是rate=2的空洞卷积,卷积核的感受野为7x7
(c)是rate=4的空洞卷积,卷积核的感受野为15x15
空洞卷积感受野的计算
空洞卷积感受野的大小分两种情况:
(1)正常的空洞卷积:
若空洞卷积率为dilate rate
则感受野尺寸= ( d i l a t e r a t e − 1 ) ∗ ( k − 1 ) + k (dilate rate-1)*(k-1)+k (dilaterate−1)∗(k−1)+k ( 其中 k为卷积核大小)
(2)padding的空洞卷积:
若空洞卷积率为dilate rate
则感受野尺寸= 2 ( d i l a t e r a t e − 1 ) ∗ ( k − 1 ) + k 2(dilate rate-1)*(k-1)+k 2(dilaterate−1)∗(k−1)+k ( 其中 k为卷积核大小)
进行分割任务时,图像存在多尺度问题,有大有小。一种常见的处理方法是图像金字塔,即将原图resize到不同尺度,输入到相同的网络,获得不同的feature map,然后做融合,这种方法的确可以提升准确率,然而带来的另外一个问题就是速度太慢。DeepLab v2为了解决这一问题,参考了SPP、PPM等引入了ASPP(atrous spatial pyramid pooling)模块,即是将feature map通过并联的采用不同膨胀速率的空洞卷积层用于捕获多尺度信息,并将输出结果融合得到图像的分割结果。如下图所示,这是在deeplab v3中改进后的ASPP。用了一个1×1的卷积和3个3×3的空洞卷积,每个卷积核有256个且都有BN层。事实上,1×1的卷积相当于rate很大的空洞卷积,因为rate越大,卷积核的有效参数就越小,这个1×1的卷积核就相当于大rate卷积核的中心的参数。

ASPP 代码:
class ASPP(nn.Module):
def __init__(self, in_channel=512, depth=256):
super(ASPP,self).__init__()
# global average pooling : init nn.AdaptiveAvgPool2d ;also forward torch.mean(,,keep_dim=True)
self.mean = nn.AdaptiveAvgPool2d((1, 1))
self.conv = nn.Conv2d(in_channel, depth, 1, 1)
# k=1 s=1 no pad
self.atrous_block1 = nn.Conv2d(in_channel, depth, 1, 1)
self.atrous_block6 = nn.Conv2d(in_channel, depth, 3, 1, padding=6, dilation=6)
self.atrous_block12 = nn.Conv2d(in_channel, depth, 3, 1, padding=12, dilation=12)
self.atrous_block18 = nn.Conv2d(in_channel, depth, 3, 1, padding=18, dilation=18)
self.conv_1x1_output = nn.Conv2d(depth * 5, depth, 1, 1)
def forward(self, x):
size = x.shape[2:]
image_features = self.mean(x)
image_features = self.conv(image_features)
image_features = F.upsample(image_features, size=size, mode='bilinear')
atrous_block1 = self.atrous_block1(x)
atrous_block6 = self.atrous_block6(x)
atrous_block12 = self.atrous_block12(x)
atrous_block18 = self.atrous_block18(x)
net = self.conv_1x1_output(torch.cat([image_features, atrous_block1, atrous_block6,
atrous_block12, atrous_block18], dim=1))
return net
3、RFB(Receptive Field Block)
RFB模块是在(ECCV2018:Receptive Field Block Net for Accurate and Fast Object Detection)一文中提出的,该文的出发点是模拟人类视觉的感受野从而加强网络的特征提取能力,在结构上RFB借鉴了Inception的思想,主要是在Inception的基础上加入了空洞卷积,从而有效增大了感受野
RFB的效果示意图如所示,其中中间虚线框部分就是RFB结构。RFB结构主要有两个特点:
1、不同尺寸卷积核的卷积层构成的多分枝结构,这部分可以参考Inception结构。在Figure2的RFB结构中也用不同大小的圆形表示不同尺寸卷积核的卷积层。
2、引入了dilated卷积层,dilated卷积层之前应用在分割算法Deeplab中,主要作用也是增加感受野,和deformable卷积有异曲同工之处。
在RFB结构中用不同rate表示dilated卷积层的参数。结构中最后会将不同尺寸和rate的卷积层输出进行concat,达到融合不同特征的目的。结构中用3种不同大小和颜色的输出叠加来展示。最后一列中将融合后的特征与人类视觉感受野做对比,从图可以看出是非常接近的,这也是这篇文章的出发点,换句话说就是模拟人类视觉的感受野进行RFB结构的设计

如下图是两种RFB结构示意图。(a)是RFB,整体结构上借鉴了Inception的思想,主要不同点在于引入3个dilated卷积层(比如3×3conv, rate=1),这也是这篇文章增大感受野的主要方式之一。(b)是RFB-s。RFB-s和RFB相比主要有两个改进,一方面用3×3卷积层代替5×5卷积层,另一方面用1×3和3×1卷积层代替3×3卷积层,主要目的应该是为了减少计算量,类似Inception后期版本对Inception结构的改进。

RFB代码:
class BasicConv(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, relu=True, bn=True):
super(BasicConv, self).__init__()
self.out_channels = out_planes
if bn:
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=False)
self.bn = nn.BatchNorm2d(out_planes, eps=1e-5, momentum=0.01, affine=True)
self.relu = nn.ReLU(inplace=True) if relu else None
else:
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=True)
self.bn = None
self.relu = nn.ReLU(inplace=True) if relu else None
def forward(self, x):
x = self.conv(x)
if self.bn is not None:
x = self.bn(x)
if self.relu is not None:
x = self.relu(x)
return x
class BasicRFB(nn.Module):
def __init__(self, in_planes, out_planes, stride=1, scale=0.1, map_reduce=8, vision=1, groups=1):
super(BasicRFB, self).__init__()
self.scale = scale
self.out_channels = out_planes
inter_planes = in_planes // map_reduce
self.branch0 = nn.Sequential(
BasicConv(in_planes, inter_planes, kernel_size=1, stride=1, groups=groups, relu=False),
BasicConv(inter_planes, 2 * inter_planes, kernel_size=(3, 3), stride=stride, padding=(1, 1), groups=groups),
BasicConv(2 * inter_planes, 2 * inter_planes, kernel_size=3, stride=1, padding=vision + 1, dilation=vision + 1, relu=False, groups=groups)
)
self.branch1 = nn.Sequential(
BasicConv(in_planes, inter_planes, kernel_size=1, stride=1, groups=groups, relu=False),
BasicConv(inter_planes, 2 * inter_planes, kernel_size=(3, 3), stride=stride, padding=(1, 1), groups=groups),
BasicConv(2 * inter_planes, 2 * inter_planes, kernel_size=3, stride=1, padding=vision + 2, dilation=vision + 2, relu=False, groups=groups)
)
self.branch2 = nn.Sequential(
BasicConv(in_planes, inter_planes, kernel_size=1, stride=1, groups=groups, relu=False),
BasicConv(inter_planes, (inter_planes // 2) * 3, kernel_size=3, stride=1, padding=1, groups=groups),
BasicConv((inter_planes // 2) * 3, 2 * inter_planes, kernel_size=3, stride=stride, padding=1, groups=groups),
BasicConv(2 * inter_planes, 2 * inter_planes, kernel_size=3, stride=1, padding=vision + 4, dilation=vision + 4, relu=False, groups=groups)
)
self.ConvLinear = BasicConv(6 * inter_planes, out_planes, kernel_size=1, stride=1, relu=False)
self.shortcut = BasicConv(in_planes, out_planes, kernel_size=1, stride=stride, relu=False)
self.relu = nn.ReLU(inplace=False)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
out = torch.cat((x0, x1, x2), 1)
out = self.ConvLinear(out)
short = self.shortcut(x)
out = out * self.scale + short
out = self.relu(out)
return out
4、PPM(Pyramid Pooling Module)
PPM(Pyramid Pooling Module)是PSPNet中提出的一个模块,PSPNET是用于语义分割的一个网络。
现在大多数先进的语义分割框架大多数基于FCN,FCN不能有效的处理场景之间的关系和全局信息。
一般来说网络越深感受野越大(resceptive field),但是理论上的感受野和实际网络中的感受野还是有差距的(实际的感受野小于理论的感受野),这使得网络无法有效的融合全局特征信息,作者提出的PPM就解决了这个问题。
GAP(Global Average Pooling,全局平均池化)能够有效的融合全局上下文信息,但是其对信息的融合和提取能力有限,而且简单的使用GAP将信息压缩为一个通道很容易损失很多有用的信息,因此将不同感受野的特征和子区域的特征融合可以增强特征表征能力。
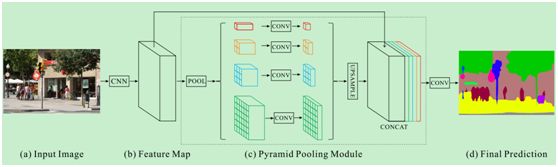
上图就是PPM模块,从前面网络中提取出的特征图在此处分成两个分支,一个分支分为多个子区域进行GAP(这与PSP模块中的结构类似),接着用1*1的卷积调整通道大小,再通过双线性插值获得未池化前的大小,最后将两个分支融合。
PSP模块能够聚合不同区域的上下文从而达到获取全局上下文的目的。
1.对骨干提取的feature map(channel =N)做池化得到特征金字塔,
2.然后通过1×1深度卷积降通道分别得到1×1,2×2,4×4,6×6的channel = 1/N的特征图
3.对特征图进行双线性插值填充上采样到原Feature map尺寸
4.与Feature map进行通道拼接(也叫级联)得到channel数增加1倍的特征图
5.再利用1×1卷积核将上述拼接后的特征图深度卷积降通道得到与输入特征图Feature通道数一致的最终的语义分割预测结果。
ppm代码:
class PyramidPooling(nn.Module):
"""Pyramid pooling module"""
def __init__(self, in_channels, out_channels, **kwargs):
super(PyramidPooling, self).__init__()
inter_channels = int(in_channels / 4) #这里N=4与原文一致
self.conv1 = _ConvBNReLU(in_channels, inter_channels, 1, **kwargs) # 四个1x1卷积用来减小channel为原来的1/N
self.conv2 = _ConvBNReLU(in_channels, inter_channels, 1, **kwargs)
self.conv3 = _ConvBNReLU(in_channels, inter_channels, 1, **kwargs)
self.conv4 = _ConvBNReLU(in_channels, inter_channels, 1, **kwargs)
self.out = _ConvBNReLU(in_channels * 2, out_channels, 1) #最后的1x1卷积缩小为原来的channel
def pool(self, x, size):
avgpool = nn.AdaptiveAvgPool2d(size) # 自适应的平均池化,目标size分别为1x1,2x2,3x3,6x6
return avgpool(x)
def upsample(self, x, size): #上采样使用双线性插值
return F.interpolate(x, size, mode='bilinear', align_corners=True)
def forward(self, x):
size = x.size()[2:]
feat1 = self.upsample(self.conv1(self.pool(x, 1)), size)
feat2 = self.upsample(self.conv2(self.pool(x, 2)), size)
feat3 = self.upsample(self.conv3(self.pool(x, 3)), size)
feat4 = self.upsample(self.conv4(self.pool(x, 6)), size)
x = torch.cat([x, feat1, feat2, feat3, feat4], dim=1) #concat 四个池化的结果
x = self.out(x)
return x
参考博客:
https://zhuanlan.zhihu.com/p/137387839
https://blog.csdn.net/qq_44901346/article/details/107052150等