Deep learning:二十(无监督特征学习中关于单层网络的分析)
本文是读Ng团队的论文” An Analysis of Single-Layer Networks in Unsupervised Feature Learning”后的分析,主要是针对一个隐含层的网络结构进行分析的,分别对比了4种网络结构,k-means, sparse autoencoder, sparse rbm, gmm。最后作者得出了下面几个结论:1. 网络中隐含层神经元节点的个数,采集的密度(也就是convolution时的移动步伐)和感知区域大小对最终特征提取效果的影响很大,甚至比网络的层次数,deep learning学习算法本身还要重要。2. Whitening在预处理过程中还是很有必要的。3. 在以上4种实验算法中,k-means效果竟然最好。因此在最后作者给出结论时的建议是,尽量使用whitening对数据进行预处理,每一层训练更多的特征数,采用更密集的方法对数据进行采样。
NORB:
该数据库参考网页:http://www.cs.nyu.edu/~ylclab/data/norb-v1.0/index.html。该数据库是由5种玩具模型的图片构成:4只脚的动物,飞机,卡车,人,小轿车,由于每一种玩具模型又有几种,所以总共是有60种类别。总共用2个摄像头,在9种高度和18种方位角拍摄的。部分截图如下:

CIFAR-10:
该数据库参考网页:http://www.cs.toronto.edu/~kriz/cifar.html。这个数据库也是图片识别的,共有10个类别,飞机,鸟什么的。每一个类别的图片有6000张,其中5000张用于训练,1000张用于测试。图片的大小为32*32的。部分截图如下:

一般在deep learning中,最大的缺陷就是有很多参数需要调整,比如说学习速率,稀疏度惩罚系数,权值惩罚系数,momentum(不懂怎么翻译,好像rbm中需要用到)等。而这些参数最终的确定需要通过交叉验证获得,本身这样的结构训练起来所用时间就长,这么多参数要用交叉验证来获取时间就更多了。所以本文得出的结论用kmeans效果那么好,且无需有这些参数要考虑。
下面是上面4种算法的一些简单介绍:
Sparse autoencoder:
其网络函数表达式如下:
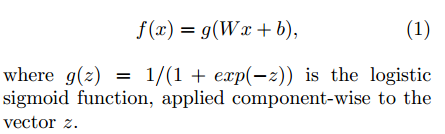
Sparse RBM:
和Sparse auto-encoder函数表达类似,只不过求解参数时的思想不同而已。另外在Sparse RBM中,参数优化主要用CD(对比散度)算法。而在Sparse autoencoder在参数优化时主要使用bp算法。
K-means聚类:
如果是用hard-kmeans的话,其目标函数公式如下:
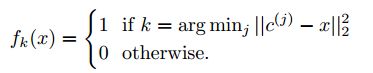
其中c(j)为聚类得到的类别中心点。
如果用soft-kmeasn的话,则表达式如下:
![]()
其中Zk的计算公式如下:
![]()
Uk为元素z的均值。
GMM:
其目标函数表达式如下:
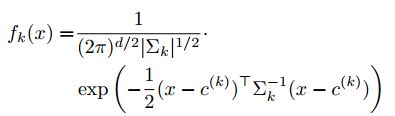
分类算法统一采用的是svm。
当训练出特征提取的网络参数后,就可以对输入的图片进行特征提取了,其特征提取的示意图如下所示:
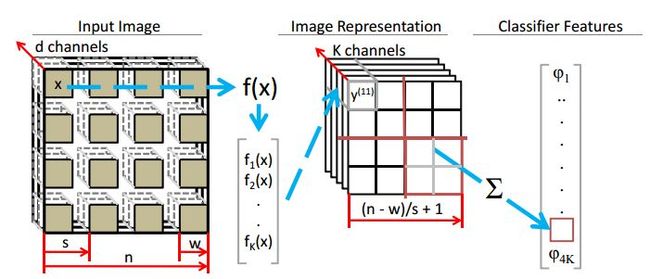
实验结果:
首先来看看有无whitening学习到的图片特征在这4种情况下的显示如下:

可以看出whitening后学习到更多的细节,且whitening后几种算法都能学到类似gabor滤波器的效果,因此并不一定是deep learning的结构才可以学到这些特性。
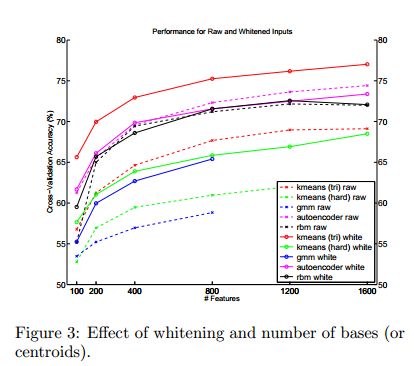
下面的这个曲线图表明,隐含层节点的个数越多则最后的识别率会越高,并且可以看出soft kmeans的效果要最好。
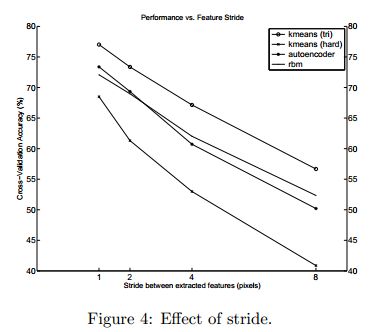
从下面的曲线可以看出当stride越小时,效果越好,不过作者建议最好将该参数设置为大于1,因为如果设置太小,则计算量会增大,比如在sparse coding中,每次测试图片输入时,对小patch进行convolution时都要经过数学优化来求其输出(和autoencoder,rbm等deep learning算法不同),所以计算量会特别大。不过当stride值越大则识别率会显著下降。
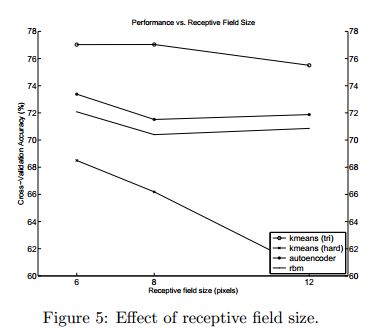
而这下面这张图则表明当Receptive filed size为6时,效果最好。不过作者也认为这不一定,因为如果把该参数调大,这意味着需要更多的训练样本才有可能体会出该参数的作用,因此这个感知器区域即使比较小,也是可以学到不错的特征的。
参考资料:
An Analysis of Single-Layer Networks in Unsupervised Feature Learning, Adam Coates, Honglak Lee, and Andrew Y. Ng. In AISTATS 14, 2011.
http://www.cs.nyu.edu/~ylclab/data/norb-v1.0/index.html
http://www.cs.toronto.edu/~kriz/cifar.html