1 项目需求背景
为了扩大贷款业务的客户人数,该银行去年针对现有的存款用户但未办理贷款业务的客户展开了一项推广活动,促使其办理个人贷款业务,取得了较好的转化效果。今年希望通过识别出更有贷款潜力的客户,提高活动转化率,降低营销费用
2 数据收集
去年营销活动的用户信息,共包含5000条记录,14个字段,对应字段含义如下:
ID - 客户
Age - 客户年龄
Experience - 客户工作经验
Income - 客户年收入(单位:千美元)
ZIPCode - 家庭地址邮政编码
Family - 客户的家庭规模
CCAvg - 每月信用卡消费额(单位:千美元)
Education - 教育水平 (1: 本科; 2: 研究生; 3: 高级)
Mortgage - 房屋抵押价值(如有)(单位:千美元)
Personal Loan - 此客户是否接受上一次活动中提供的个人贷款?(1:是 0:否)
Securities Account - 是否有证券账户?(1:是 0:否)
CD Account - 是否有存款证明(CD)帐户吗(1:是 0:否)
Online - 是否开通网上银行?(1:是 0:否)
CreditCard - 是否有信用卡?(1:是 0:否)
#导入相关库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns#设置全部行输出
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"#读取数据
data=pd.read_csv('Personal_Loan.csv')data.head()
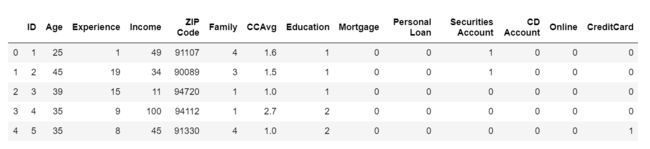
3 数据探索和清洗
3.1 查看数据的形状、类型,处理缺失值、重复值、异常值
#数据整体情况
data.info()

-- 无缺失值,需要把Mortgage和Income更改为float类型,ZIP Code改为字符型
#变量类型转换
data.Mortgage=data.Mortgage.astype('float')
data.Income=data.Income.astype('float')
data['ZIP Code']=data['ZIP Code'].astype('str')
data.info()

#查看重复值的个数
data.duplicated().sum()
-- 无重复值
#查看异常值
data.columns
#选择散点图方式
fig = plt.figure()
plt.scatter(data.values[:,0],data.values[:,2])

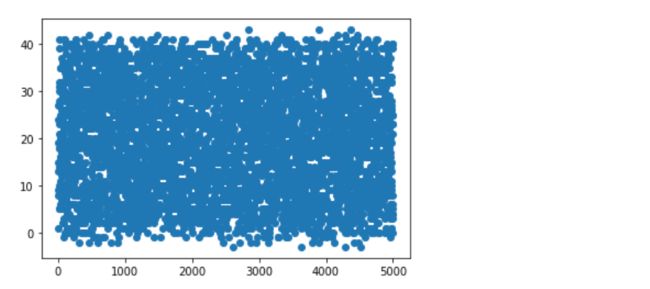
-- 查看各列的散点图,Experience列出现负数值,为异常数据
#把Experience负值改为0
data.loc[data.Experience<0,'Experience']=0
3.2 描述性统计
data.describe()

4 数据预处理
4.1 去年营销活动的效果如何
# 去年营销活动效果
data.groupby('Personal Loan').size()

-- 5000名客户中,有480个客户开通了个人贷款业务,转化率9.6%,说明此次推广活动的效果还是不错的。数据源的可信度也比较高
4.2 特征筛选
4.2.1 相关系数
#把ID设为索引,ID不属于变量
data.set_index(['ID'],inplace=True)
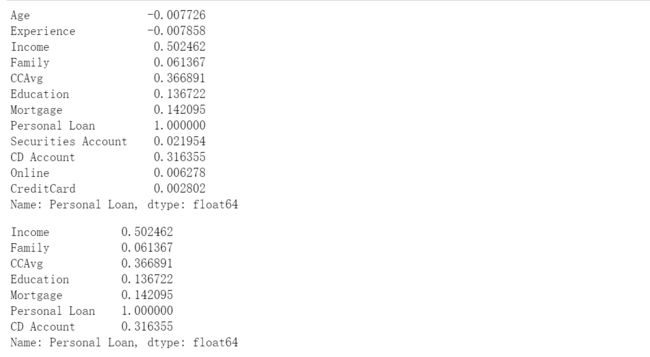
#因变量Personal Loan跟其他变量的相关系数
cor = data.corr()['Personal Loan']
cor
cor[abs(cor)>0.05
#fig代表绘图窗口(Figure);axis代表这个绘图窗口上的坐标系(axis)
fig,axis=plt.subplots(figsize=(10,10))
#绘制热力图,颜色越深,相关性越强
ax=sns.heatmap(data.corr(),annot=True,linecolor='black',cmap="BrBG_r",fmt='.2f')
#fmt设置小数位
#bottom代表y轴下限,top表示y轴上限(matplotlib版本画热力图上下边框只显示一半)
bottom, top = ax.get_ylim()
ax.set_ylim(bottom + 0.5, top - 0.5);
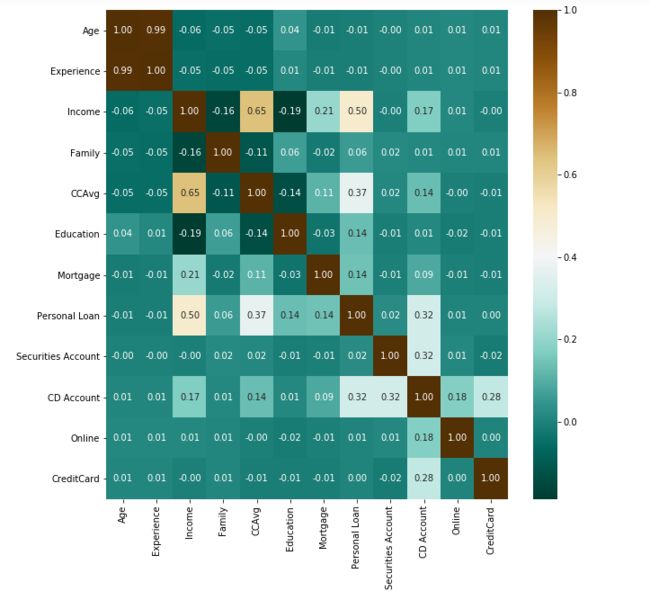
由相关系数和热力图:
1.与Personal Loan强相关的变量:Income收入、CCAvg信用卡还款额和CD Account是否有是存款证明帐户
2.与Personal Loan弱相关的变量:Education受教育程度,Mortgage房屋抵押价值和Family家庭人数
3.其中Age年龄、Experience工作经验和ZIP Code家庭地址邮政编码虽然关系不大,但它们属于连续型变量,需要进一步分析。可以分箱后再做观察,看看是否有某一段存在特殊值,也可以考虑放在模型中
定性变量:CD Account是否有是存款证明帐户、Education受教育程度、Family家庭人数
定量变量:Income收入、CCAvg信用卡还款额、Mortgage房屋抵押价值
4.2.2 定性变量
# rc参数
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#CD Account
#开通CD Account的用户贷款比例
data.groupby('CD Account')['Personal Loan'].agg(['mean','count'])
#可视化
f,ax1= plt.subplots()
sns.countplot(x='CD Account',hue='Personal Loan',data=data,ax=ax1)
ax1.set_title('用户贷款比例')#标题

-- 开通了CD Account的客户,贷款的比例远高于是没有开通的客户,说明开通CD Account的客户成为贷款业务的潜在客户可能性更大;且大量客户没有开通CD Account,找到方法让客户开通CD Account也是一个提高贷款率的可能选项
#Education
data.groupby('Education')['Personal Loan'].agg(['mean','count'])

-- 受教育水平越高,贷款的比例越高,尤其在本科以上学历差距明显,说明受教育水平高的用户成为贷款业务的潜在客户可能性更大
#Family
data.groupby('Family')['Personal Loan'].agg(['mean','count'])

-- 单身人士与没有孩子的家庭的贷款率都比较低,有孩子的家庭用户相对而言更有意愿转化为贷款用户,特别是独生子女家庭
4.2.3 定量分析-分箱
#Income收入
data['Income_bins']=pd.qcut(data.Income,20)
data.groupby('Income_bins')['Personal Loan'].agg(['mean','count'])
data.groupby('Income_bins')['Personal Loan'].mean().plot()


-- 高收入人群明显申请贷款的,收入小于64时,贷款率几乎为零,收入超过98时,贷款率急剧上升,超过170时,贷款意愿达到50%
#CCAvg信用卡还款额
data['CCAvg_bins']=pd.qcut(data.CCAvg,20)
data.groupby('CCAvg_bins')['Personal Loan'].agg(['mean','count'])
data.groupby('CCAvg_bins')['Personal Loan'].mean().plot()


-- CCAvge在2.8时,贷款率会增大将近4倍;在4.3-6.0区间会贷款率会达到45%;大于6时,贷款率会稍有回落,但贷款意愿依旧比较强
#Mortgage房屋抵押价值
data['Mortgage_bins']=pd.cut(data.Mortgage,10) #等深分箱会有重复边界值,为0的数据占比太多
data.groupby('Mortgage_bins')['Personal Loan'].agg(['mean','count'])
plt.subplots(figsize=(15,5))
data.groupby('Mortgage_bins')['Personal Loan'].mean().plot()

-- 当Mortgage大于190.5时,贷款申请的意愿有明显的提升,总体来看,抵押值越高,贷款转化率越高。但房屋抵押价值高的客户很少
4.2.4 对相关系数低的连续型变量分箱观察
#Age年龄
data['Age_bins']=pd.qcut(data.Age,6)
data.groupby('Age_bins')['Personal Loan'].agg(['mean','count'])
data.groupby('Age_bins')['Personal Loan'].mean().plot()

-- Age在32-39区间时贷款率较高,但总体年龄跟贷款率的相关性不高
#Experience工作经验
data['Experience_bins']=pd.qcut(data.Experience,6)
data.groupby('Experience_bins')['Personal Loan'].agg(['mean','count'])
data.groupby('Experience_bins')['Personal Loan'].mean().plot()

-- Experience在7-14区间时贷款率较高,但总体工作经验跟贷款率的相关性不高
#ZIP Code家庭地址邮政编码
#邮政编码的第一个数字代表美国各州,第二个和第三个数字一起代表一个地区(或一个大城市),所以按照第2、3个数字分区
data['ZIP Code_bins']=data['ZIP Code'].str.extract('9(\d\d)',expand=False)
plt.subplots(figsize=(15,5))
data.groupby('ZIP Code_bins')['Personal Loan'].agg(['mean','count'])
data.groupby('ZIP Code_bins')['Personal Loan'].mean().plot()
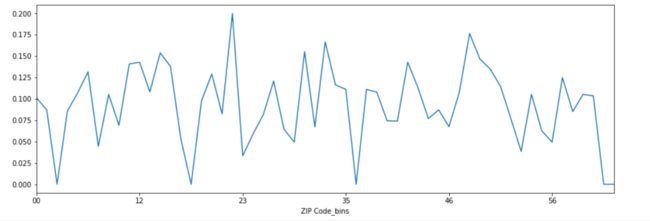
-- ZIP Code各地区与贷款率相关性不高
5 模型搭建
用连续型变量和分箱两种方式测试模型的效果
5.1 用原始数据的变量
data.head(2)

最终选取加入模型的6个变量:Income收入、Family家庭人数、CCAvg信用卡还款额、Education受教育程度、Mortgage房屋抵押价值和CD Account是否有是存款证明帐户(已尝试把Experience、Age、ZIP Code加入模型,没有改善模型)
data.iloc[:,[2,4,5,6,7,10]].head()
# model_selection模型选择功能
#train_test_split 训练测试分区
#cross_val_score 交叉验证得分
from sklearn.model_selection import train_test_split,cross_val_score
#划分训练集和测试集
xtrain,xtest,ytrain,ytest=train_test_split(data.iloc[:,[2,4,5,6,7,10]],data.iloc[:,8]
,test_size=0.3)
#test_size=0.2,指定训练测试集随机抽样20%的数据
#random_state=0 随机种子数的确定
xtrain.shape

#导入包和类
from sklearn.linear_model import LogisticRegression
#实例化
log=LogisticRegression(solver="lbfgs",C=0.04,max_iter=400)
#拟合数据
log.fit(xtrain,ytrain)
log.score(xtrain,ytrain)#训练集R方
log.score(xtest,ytest)#测试集R方
y_log=log.predict(xtest)#predict_proba 预测评分,y的估计值。根据预测的概率,大于0.5的返回1

-- 正确率都是94%,考虑到数据集0、1分布极不均衡,还要看下f1指标
5.2 使用连续型变量分箱后的数据
df=data.copy()
df=df.loc[:,['Income_bins','Family','CCAvg_bins','Education','Mortgage_bins','CD Account','Personal Loan']]
df.head()

#数字编码
from sklearn.preprocessing import LabelEncoder
encoder= LabelEncoder().fit(df["Income_bins"])
df["Income_bins"] = encoder.transform(df["Income_bins"])
encoder= LabelEncoder().fit(df["CCAvg_bins"])
df["CCAvg_bins"] = encoder.transform(df["CCAvg_bins"])
encoder= LabelEncoder().fit(df["Mortgage_bins"])
df["Mortgage_bins"] = encoder.transform(df["Mortgage_bins"])
df.info() #需要的变量是数值型了

# model_selection模型选择功能
#train_test_split 训练测试分区
#cross_val_score 交叉验证得分
from sklearn.model_selection import train_test_split,cross_val_score
#划分训练集和测试集
xtrain_new,xtest_new,ytrain_new,ytest_new=train_test_split(df.iloc[:,:6],df.iloc[:,-1]
,test_size=0.3,random_state=2)
#test_size=0.2,指定训练测试集随机抽样20%的数据
#random_state=0 随机种子数的确定
xtrain_new.shape

log_new=LogisticRegression(solver="lbfgs",C=0.3,max_iter=100)
#拟合数据
log_new.fit(xtrain_new,ytrain_new)
log_new.score(xtrain_new,ytrain_new)
log_new.score(xtest_new,ytest_new)
y_log_new=log_new.predict(xtest_new)

-- 正确率也是94%,跟方法一差不多
6 模型评估
6.1 混淆矩阵预测
对模型进行评价
#方法一:
from sklearn.metrics import confusion_matrix #混淆矩阵包
from sklearn.metrics import classification_report #分类报告包
cm=confusion_matrix(ytest,y_log)#行放y,列放y的预测值,形成2*2的交叉表
print(classification_report(ytest,y_log,target_names=['非贷款','贷款']))
sns.heatmap(cm,fmt="d",cmap="icefire",annot=True)#annot将数值显示在单元格里

-- 方法一:预测正确率95%,召回率53%,精准率88%,f1是66%,该数据中1和0的比例差距较大,所以不能看正确率,主要看f1,模型总体得分较低
#方法二:
from sklearn.metrics import confusion_matrix #混淆矩阵包
from sklearn.metrics import classification_report #分类报告包
cm_new=confusion_matrix(ytest_new,y_log_new)#行放y,列放y的预测值,形成2*2的交叉表
print(classification_report(ytest_new,y_log_new,target_names=['非贷款','贷款']))
sns.heatmap(cm_new,fmt="d",cmap="icefire",annot=True)#annot将数值显示在单元格里

-- 方法二:预测正确率95%,召回率57%,精准率82%,f1是68%,比方法一得分高一点,但差距不大
6.2 交叉验证
评估模型的稳定性
#方法一:
from sklearn.model_selection import cross_val_score,LeaveOneOut,KFold,GroupKFold
x,y=data.iloc[:,[1,2,4,5,6,7,10]],data.iloc[:,8]
scores=cross_val_score(log,x,y,cv=3,scoring="f1")
print('交叉验证:%s'%scores)
print('平均交叉验证得分:%s'% np.mean(scores))

-- 方法一:交叉验证得分之差超过2%,模型过拟合
#方法二:
x_new,y_new=df.iloc[:,:6],df.iloc[:,-1]
scores_new=cross_val_score(log_new,x_new,y_new,cv=3,scoring="f1")
print('交叉验证:%s'%scores_new)
print('平均交叉验证得分:%s'% np.mean(scores_new))

-- 方法二:得分之差减小,分组后的数据让模型更稳定了
6.3 解释模型
输出回归系数和OR值
log.coef_
(np.exp(log.coef_)-1)*100
#顺序:Income Family CCAvg Education Mortgage CD Account

#输出回归系数
log_new.coef_
(np.exp(log_new.coef_)-1)*100#方法二OR值
#顺序:Income_bins Family CCAvg_bins Education Mortgage_bins CD Account

-- 方法一和方法二的OR值差别很大
6.4 用SGD模型 结合网格搜索进行调参
#建模
from sklearn.linear_model import SGDClassifier
sgd_clf=SGDClassifier(loss="log")
sgd_clf.fit(xtrain,ytrain)#拟合训练集数据
sgd_clf.score(xtest,ytest)#非监督模型是transform

from sklearn.model_selection import GridSearchCV
#参数设置
parameters=[{'penalty':['l2','l1'],'alpha':[0.04,0.05,0.06]},
{'l1_ratio':[0.1,0.5,0.9,1]}
]
#线性回归中叫algha系数,logistic和svm叫C。惩罚系数的倒数,值越小,正则化越大(惩罚越大),修正过拟合,共线性
grid_search=GridSearchCV(sgd_clf,parameters,cv=3,scoring='accuracy')#scoring='accuracy'
grid_search.fit(xtrain,ytrain)
print("测试得分:%s" %grid_search.score(xtest,ytest))
print("全部及最优系数:%s" %grid_search.best_estimator_)

-- 方法一最优正则化系数是0.04,迭代正则化系数C
#建模
sgd_clf=SGDClassifier(loss="log")
sgd_clf.fit(xtrain_new,ytrain_new)#拟合训练集数据
sgd_clf.score(xtest_new,ytest_new)#非监督模型是transform

#参数设置
parameters=[{'penalty':['l2','l1'],'alpha':[0.04,0.05,0.06]},
{'l1_ratio':[0.1,0.5,0.9,1]}
]
#线性回归中叫algha系数,logistic和svm叫C。惩罚系数的倒数,值越小,正则化越大(惩罚越大),修正过拟合,共线性
grid_search=GridSearchCV(sgd_clf,parameters,cv=3,scoring='accuracy')#scoring='accuracy'
grid_search.fit(xtrain_new,ytrain_new)
print("测试得分:%s" %grid_search.score(xtest_new,ytest_new))
print("全部及最优系数:%s" %grid_search.best_estimator_)

-- 方法二最优正则化系数是0.0001,迭代正则化系数C(但是这个系数迭代过去效果并不好,疑问?)
7 结论
7.1 相关性部分
更容易转化为贷款客户的用户有如下特征:
· 开通了银行账户的用户相对于没有开通银行账户贷款意愿更强
· 教育水平越高的客户越容易接受贷款
· 家庭人口较多的家庭贷款意愿较强,尤其是独生子女的家庭
· 年龄区间在30-40岁的客户相对贷款意愿更强
· 相对收入越高,贷款的意愿越强烈, 当年收入超过82时,贷款意愿会有5倍以上的上升,超过98时,贷款意愿达到17%以上,超过170时,贷款意愿达到一半
· 当房屋抵押值大于190.5千美元时,贷款申请的意愿有明显的提升,但房屋抵押价值高的客户很少
· 每月消费额在2.8千美元以上的客户,贷款申请的意愿有明显的提升
7.2 模型部分
模型总体得分较低,OR值过高,还需要找原因优化,以下只是基于目前不成熟分析的结论
分组后的数据稳定性更好,目前得到的预测正确率95%,召回率57%,精准率82%,f1是68%
在其他条件不变的情况下:
· Income_bins增加一个单位,贷款率提高143%;
· Family增加一个单位,贷款率提高130%;
· CCAvg_bins增加一个单位,贷款率提高6%;
· Education增加一个单位,贷款率提高460%;
· Mortgage_bins增加一个单位,贷款率提高4%;
· CD Account增加一个单位,贷款率提高614%