关于Python使用Camelot库优化提取PDF三线表的技巧,解决识别的表字段名错位,过多的空白单元的问题
关于Python使用Camelot库优化提取PDF三线表的技巧:解决识别的表字段名错位,过多的空白单元的问题
-
- 依赖库
- 问题描述
-
-
- 测试文件
- 原始代码
- 原始提取效果
-
- 原因分析
- 解决方案
-
-
- 针对表字段错位
- 针对空白单元
- 最终实现代码
- 最终效果
-
参考文章:camelot官方文档
依赖库
camelot
问题描述
测试文件
自行准备的含有三线表的PDF文件
原始代码
tables = camelot.read_pdf(path, pages=str(pageID), flavor="stream", table_areas=[area])
原始提取效果
1: 内存中提取时出现的字段错位

2: 输出文件中出现的过多空白单元
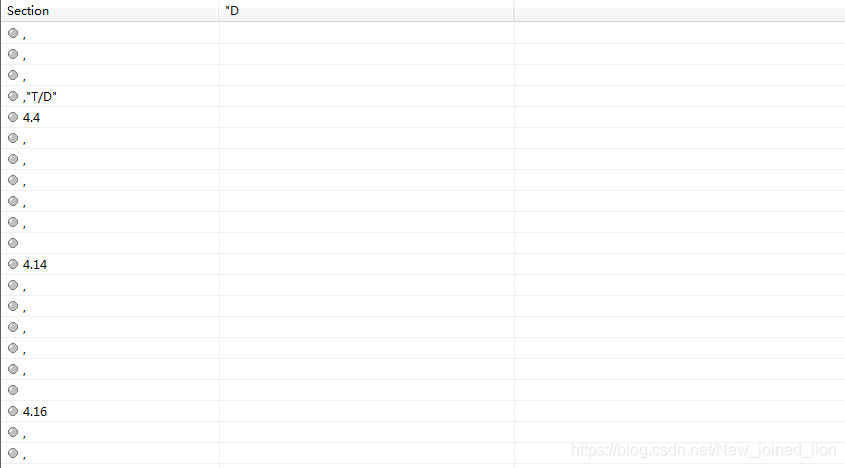
原因分析
针对表字段错位:
可能是由于Camelot库在进行扫描过程中,对 单行高度的检测阈值 设置过低。查阅源码后其阈值默认为2,可以进行修改为10。
针对空白单元:
可能是由于Camelot库在扫描的过程中, 对 单行高度的检测阈值 设置过高,导致获得了多余的 \n 换行符,使得换行符之后的文本内容没有写入输出文件。
内存中由于单行高度的检测阈值设置过高,所出现的情况:

解决方案
针对表字段错位
将 单行高度的检测阈值 设置 合适的值,官方推荐为 10 ,(默认为2),当阈值设置超过10后,会导致多行并为一行的情况发生。
即,设置 row_tol属性, 例:row_tol=10
针对空白单元
对提取出的文本信息,将其中的“\n”字符过滤掉。
即,设置strip_text属性, 例: strip_text="\n"
最终实现代码
tables = camelot.read_pdf(path, pages=str(pageID), flavor="stream", table_areas=[area], row_tol=10,
strip_text="\n")
最终效果
优化后识别的Table1 (内存中表示)

优化后识别的Table1 (输出文件中表示)
