python问题总结
1. 谈下python的GIL
为了多线程间 数据完整性 和 状态同步 而加的锁
缺点:进程系统资源开销大
2. 简述线程同步和异步的区别?
同步:指一个线程需要主动等待上一个线程执行完之后才开始执行。
异步:指一个线程不需要主动等待上一个线程执行完之后就开始执行。
区别关键是 需不需要主动等待
3. 简述线程,进程,协程的区别?
线程:
操作系统能够进行运算调度的最小单位。 它包含在进程之中,是进程的实际运作单位。 一条线程指的是进程中一个单一顺序的控制流, 一个进程中可以并发多个线程,每一条线程并行执行不同的任务。
进程:
对一堆资源的整合。 比如说QQ就是一个进程。
目的:最大限度的利用CPU,节省时间。
从操作系统角度来讲,进程是资源分配单元,线程是执行单元,多个线程可以共享所在进程的资源。
协程:
从程序运行角度出发,是由用户(程序)控制和调度的一个过程。
多线程并不会充分调用两个CPU,而是会在一个CPU上充分运转;
而多进程则是会完全调用两个CPU,同时执行;
并行:多个处理器同时处理多个任务
并发:一个处理器同时交替处理多个任务
4. python如何开启一个进程?
知识点一:进程的理论
什么是进程?
进程是指一个程序在一个数据集上的动态执行过程(程序执行过程的抽象)
进程包含
-
程序:我们通过程序来描述一个进程所要执行的内容以及如何执行
-
数据集:数据集代表程序在执行过程中所需要的资源
-
进程控制块:用于描述进程的外部特征,记录进程的执行过程,系统可以用来控制/管理进程,也是操作系统感知进程存在的唯一标识
进程运行的的三种状态:
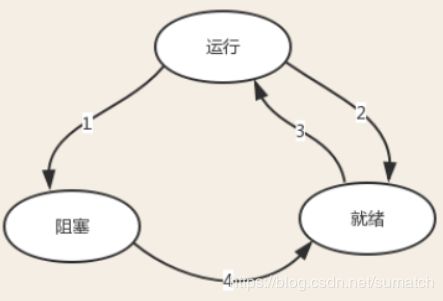
- 进程执行过程中出现IO,进入阻塞状态(操作系统强行剥夺CPU)
- 进程占用CPU时间过长/出现一个优先级更高的进程,进入就绪状态(CPU被剥夺)
- 就绪态的进程被分配到CPU,进入运行状态
- 阻塞态的进程出现有效输入,进入就绪态,等待操作系统分配CPU
此外,我们能直接控制的只有阻塞状态,减少阻塞,使进程尽可能的保持在就绪状态,提高效率
知识点二:开启进程的两种方式
开启进程:开启进程就是将父进程里面串行执行的程序放到子进程里,实现并发执行,这个过程中,会将父进程数据拷贝一份到子进程。
运行角度:是2个进程
注意:子进程内的初始数据与父进程的一样,如果子进程被创建或者被运行了,那么
子进程里面数据更改对父进程无影响,2个进程是存在运行的
方式一:通过调用multiprocessing模块下面的Process类方法
from multiprocessing import Process
def func(name):
print('%s is running...' % name)
print('%s is ending...' % name)
if __name__ == '__main__':
p = Process(target=func, args=('子进程',))
# 如果只有一个参数,args括号内一定要加逗号,确保以元组的形式传入
# 这一步:只是在向操作系统发我要开启一个子进程的信号(具体开子进程的操作是由操作系统来完成的)
p.start()
# 只是主进程给操作系统发送建立子进程的请求,并非立刻建立子进程
print('主进程')
运行结果:主进程
子进程 is running...
子进程 is ending...
方式二:借助process类,自定义一个类(继承Process),从而创造一个对象
定义process类的子类,并重写该类的run()方法,run()方法的中写进程需要完成的任务。
from multiprocessing import Process
class MyProcess(Process): # 继承Process类
def run(self): # run名字是固定的,不能更改
print("%s is running" % self.name) # 默认函数对象有name方法 ,结果为:Myprocess-1
print('%s is done' % self.name)
if __name__ == '__main__':
obj = MyProcess()
obj.start() # 本质上是在调用父类的start方法,而start方法下会触发run方法
print('主进程')
运行结果:主进程
MyProcess-1 is running
MyProcess-1 is done
为什么开启进程要在main内执行?
由于在windows系统下,子进程是通过导入模块的方式拿到父进程的代码,如果没有main会一直开启子进程,
而子进程的申请是需要开辟内存以及申请pid等的。
5. python如何开启一个线程?
方式一:通过thread类直接创建
import threading
def foo(n):
print('%s'%n)
def bar(n):
print('%s'%n)
print('33') # 主线程
t1 = threading.Thread(target=foo, args=(1,)) # 线程一
t2 = threading.Thread(target=bar, args=(2,)) # 线程二
t1.start()
t2.start()
# 创建线程,第一个参数是函数名字(不加括号,加括号就执行函数了)。
# 第二个参数是要传给函数的参数,以元组的形式。
# 创建线程之后, obj.start()启动线程。
执行结果:33
1
2
方式二:继承Thread类:
定义Thread类的子类,并重写该类的run()方法,run()方法的中写线程需要完成的任务。
import threading
# 定义MyThread类,其继承自threading.Thread这个父类
class MyThread(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
def run(self):
print("start t1")
print("end t1")
t1=MyThread() # 对类进行实例化
t1.start() # 启动线程
print("主线程")
运行结果:start t1
end t1
主线程
补充:Thread类的一些常用方法
- join(): 在子线程完成之前,主线程将一直被阻塞
- setDaemon(True) 方法: 将进程声明为守护线程,必须在
start()方法调用之前
6. 线程之间如何通信?
方式一:threading.Event 事件
Python提供了非常简单的通信机制 Threading.Event,通用的条件变量(event.isSet==False/True)。多个线程可以等待某个事件的发生,在事件发生后,所有的线程都会被激活。
关于Event的使用,就四个函数:
event = threading.Event()
- event.isSet() # 返回event的状态值。
- event.wait() # 等待接收event的状态值,决定是否阻塞程序执行。如果event.isSet==False,将阻塞线程。
- event.set() # 设置event的状态值为True,使所有设置该event事件的线程执行。
- event.clear() # 重置event的状态值为False,使得所有该event事件都处于待命状态。
举个例子:
import time
import threading
class MyThread(threading.Thread):
def __init__(self, name, event):
super().__init__()
self.name = name
self.event = event
def run(self):
print('Thread: {} start at {}'.format(self.name, time.ctime(time.time())))
# 等待event.set()后,才能往下执行
self.event.wait()
print('Thread: {} finish at {}'.format(self.name, time.ctime(time.time())))
threads = []
event = threading.Event()
# 定义三个线程,使用event事件
[threads.append(MyThread(str(i), event)) for i in range(1, 4)]
# 重置event,使得event.wait()起到阻塞作用
event.clear()
# 启动所有线程
[t.start() for t in threads]
print('等待5s...')
time.sleep(5)
print('唤醒所有线程...')
event.set()
执行结果:Thread: 1 start at Fri Jul 12 15:05:50 2019
Thread: 2 start at Fri Jul 12 15:05:50 2019
Thread: 3 start at Fri Jul 12 15:05:50 2019
等待5s...
唤醒所有线程...
Thread: 3 finish at Fri Jul 12 15:05:55 2019
Thread: 2 finish at Fri Jul 12 15:05:55 2019
Thread: 1 finish at Fri Jul 12 15:05:55 2019
可见在所有线程都启动 start() 后,并不会执行完,而是都在self.event.wait()阻塞了,需要通过event.set()来给所有线程发送执行指令才能往下执行。
方式二:threading.Condition条件
Condition和Event 是类似的,并没有多大区别。
Condition需要掌握几个函数:
cond = threading.Condition() # 创建一个cond条件 , 默认锁为 Rlock.
-
cond.acquire() # 类似lock.acquire()
-
cond.release() # 类似lock.release()
-
cond.wait() # 等待指定触发,同时会释放锁,直到被notify才重新占有琐。
-
cond.notify() # 发送指定,触发执行一个线程
-
cond.notifyAll() # 发送指定,触发执行所有线程
举个生产消费的例子:
import threading
import time
from random import randint
class Producer(threading.Thread):
def run(self):
global L
while True:
val=randint(0,100)
print('生产者',self.name,":Append"+str(val), L)
if lock_con.acquire():
L.append(val)
lock_con.notify()
lock_con.release()
time.sleep(3)
class Consumer(threading.Thread):
def run(self):
global L
while True:
lock_con.acquire()
if len(L)==0:
lock_con.wait()
print('消费者',self.name,":Delete"+str(L[0]),L)
del L[0]
lock_con.release()
time.sleep(0.25)
if __name__=="__main__":
L=[]
lock_con=threading.Condition()
threads=[]
for i in range(5):
threads.append(Producer())
threads.append(Consumer())
for t in threads:
t.start()
for t in threads:
t.join()
执行结果:生产者 Thread-1 :Append48 []
生产者 Thread-2 :Append9 [48]
生产者 Thread-3 :Append73 [48, 9]
生产者 Thread-4 :Append11 [48, 9, 73]
生产者 Thread-5 :Append94 [48, 9, 73, 11]
消费者 Thread-6 :Delete48 [48, 9, 73, 11, 94]
消费者 Thread-6 :Delete9 [9, 73, 11, 94]
消费者 Thread-6 :Delete73 [73, 11, 94]
消费者 Thread-6 :Delete11 [11, 94]
消费者 Thread-6 :Delete94 [94]
可见通过cond来通信,阻塞自己,并使对方执行。
方式三:queue.Queue队列
从一个线程向另一个线程发送数据最安全的方式可能就是使用 queue 库中的队列了。
创建一个被多个线程共享的 Queue 对象,这些线程通过使用put() 和 get() 操作来向队列中添加或者删除元素。
队列需要掌握的函数:
q = Queue(maxsize=0) # maxsize默认为0,不受限。
-
q.get() # 阻塞程序,等待队列消息。
-
q.get(timeout=5.0) # 获取消息,设置超时时间。
-
q.put() # 发送消息。
-
q.join() # 等待所有的消息都被消费完。
举一个老师点名的例子:
from threading import Thread
from queue import Queue
import time
class Student(Thread):
def __init__(self, name, queue):
super().__init__()
self.name = name
self.queue = queue
def run(self):
while True:
# 阻塞程序,时刻监听老师,接收消息
msg = self.queue.get()
# 一旦发现点到自己名字,就赶紧答到
if msg == self.name:
print("{}:到!".format(self.name))
class Teacher:
def __init__(self, queue):
self.queue = queue
def call(self, student_name):
print("老师:{}来了没?".format(student_name))
# 发送消息,要点谁的名
self.queue.put(student_name)
queue = Queue()
teacher = Teacher(queue=queue)
s1 = Student(name="小明", queue=queue)
s2 = Student(name="小亮", queue=queue)
s1.start()
s2.start()
print('开始点名~')
teacher.call('小明')
time.sleep(1)
teacher.call('小亮')
总结:
学习了以上三种通信方法,我们很容易就能发现Event 和 Condition 是threading模块原生提供的模块,原理简单,功能单一,它能发送 True 和 False 的指令,所以只能适用于某些简单的场景中。
而Queue则是比较高级的模块,它可能发送任何类型的消息,包括字符串、字典等。其内部实现其实也引用了Condition模块(譬如put和get函数的阻塞),正是其对Condition进行了功能扩展,所以功能更加丰富,更能满足实际应用。
7. 进程之间如何通信?
方式一:Queue队列,用于多个进程间实现通信
一个进程向 Queue 中放入数据,另一个进程从 Queue 中读取数据。
multiprocessing 模块下的 Queue 和 queue 模块下的 Queue 基本类似,它们都提供了 qsize()、empty()、full()、put()、put_nowait()、get()、get_nowait() 等方法。
区别只是 multiprocessing 模块下的 Queue 为进程提供服务,而 queue 模块下的 Queue 为线程提供服务。
from queue import Queue # 为线程提供服务
from multiprocessing import Queue # 为进程提供服务
举个例子:
import multiprocessing
def fun(que):
print('(%s) 进程开始放入数据...' % multiprocessing.current_process().pid)
que.put('Python') # 向 Queue 中放入数据
if __name__ == '__main__':
que = multiprocessing.Queue() # 创建进程通信的Queue
p = multiprocessing.Process(target=fun, args=(que,)) # 创建子进程
p.start() # 启动子进程
print('(%s) 进程开始取出数据...' % multiprocessing.current_process().pid) # 先走主进程
print(que.get()) # 从 Queue 中读取数据
执行结果:(6364) 进程开始取出数据...
(12716) 进程开始放入数据...
Python
方式二:Pipe管道,用于两个进程的通信
使用 Pipe 实现进程通信,程序会调用 multiprocessing.Pipe() 函数来创建一个管道,该函数会返回两个 PipeConnection 对象,代表管道的两个连接端,用于连接通信的两个进程。
PipeConnection 对象包含如下常用方法:
- send(obj):发送一个 obj 给管道的另一端,另一端使用 recv() 方法接收。
- recv():接收另一端通过 send() 方法发送过来的数据。
- fileno():关于连接所使用的文件描述器。
- close():关闭连接。
- poll([timeout]):返回连接中是否还有数据可以读取。
- send_bytes(buffer[, offset[, size]]):发送字节数据。
- recv_bytes([maxlength]):接收通过 send_bytes() 方法发迭的数据,maxlength 指定最多接收的字节数。
- recv_bytes_into(buffer[, offset]):功能与 recv_bytes() 方法类似,只是该方法将接收到的数据放在 buffer 中。
举一个例子:
import multiprocessing
def f(conn):
print('(%s) 进程开始发送数据...' % multiprocessing.current_process().pid)
# 使用conn发送数据
conn.send('Python')
if __name__ == '__main__':
parent_conn, child_conn = multiprocessing.Pipe() # 创建Pipe,该函数返回两个PipeConnection对象
p = multiprocessing.Process(target=f, args=(child_conn, )) # 创建子进程
p.start()
print('(%s) 进程开始接收数据...' % multiprocessing.current_process().pid)
# 通过conn读取数据
print(parent_conn.recv()) # Python
p.join()
执行结果:(13796) 进程开始接收数据...
(14792) 进程开始发送数据...
Python
8. python什么时候用多线程?什么时候用多进程?
- 多线程使用场景:IO密集型
- 多进程使用场景:CPU密集型
9. python是如何实现多态的?
多态:一类事物有多种形态,(一个抽象类有多个子类,因而多态的概念依赖于继承)
class Animal():
def __init__(self, name):
self.name = name
def talk(self): # 抽象方法,仅由约定定义
print(self.name, '叫') # 当子类没有重写talk方法的时候调用
def animal_talk(obj): # 多态
obj.talk()
class Cat(Animal):
def talk(self):
print('%s: 喵喵喵!' % self.name) # 重写talk方法
class Dog(Animal):
def talk(self):
print('%s: 汪汪汪!' % self.name)
a = Dog('小狗')
Animal.animal_talk(a) # 多态调用
b = Cat('小猫')
Animal.animal_talk(b)
c = Animal('111')
Animal.animal_talk(c)
执行结果:小狗: 汪汪汪!
小猫: 喵喵喵!
111 叫
10. 单元测试,单例模式
单元测试(unit testing),是指对软件中的最小可测试单元进行检查和验证。在python中指一个类。单元测试是在软件开发过程中要进行的最低级别的测试活动,软件的独立单元将在与程序的其他部分相隔离的情况下进行测试。
单例模式,是一种常用的软件设计模式。在它的核心结构中只包含一个被称为单例的特殊类。通过单例模式可以保证系统中,应用该模式的一个类只有一个对象实例。(详见面试总结一)
11. python如何实现单例模式?
什么是单例模式(Singleton)?
单例模式,也叫单子模式,是一种常用的软件设计模式。在应用这个模式时,单例对象的类必须保证只有一个实例存在。
单例模式优点:
1. 由于单例模式要求全局内只有一个实例,所以可以节省很多内存空间
2. 全局只有一个接入点,可以更好的进行数据同步,避免多重占用
3. 单例可以常驻内存,减少系统开销
单例模式应用:
1. 生成唯一序列号
2. 访问全局复用的唯一资源,如磁盘,总线等
3. 数据库连接池
4. 网站计数器
实现单例的方式?
- 全局变量:不直接调用 Config() ,而使用同一个全局变量
- 重写 __new__ 方法:重写 __new__来保证每次调用 Config() 都会返回同一个对象, __new__ 为对象分配空间,返回对象的引用
- 使用metaclass:metaclass重写__call__ 方法来保证每次调用 Config() 都会返回同一个对象
- 使用装饰器:使用装饰器来保证每次调用 Config() 都会返回同一个对象
原理:在真正调用 Config() 之前进行一些拦截操作,来保证返回的对象都是同一个:
具体实现:
-
全局变量
# config.py from dataclasses import dataclass @dataclass class Config: SQLALCHEMY_DB_URI = SQLALCHEMY_DB_URI config = Config(SQLALCHEMY_DB_URI = "mysql://")通过使用全局变量,我们在所有需要引用配置的地方,都使用 from config import config 来导入,这样就达到了全局唯一的目的。
-
重写__new__方法
class Singleton(object): _instance = None # _instance 作为类属性,保证了所有对象的实例都是同一个 def __new__(cls, *args, **kwargs): if cls._instance is None: cls._instance = super().__new__(cls) # 为对象分配空间 return cls._instance # 返回对象的引用 a = Singleton() # 创建对象时,new方法会被自动调用 b = Singleton() print(a) print(b)执行结果:<__main__.Singleton object at 0x0000023A88E0F2B0> <__main__.Singleton object at 0x0000023A88E0F2B0>每次实例化一个对象时,都会先调用
__new__()创建一个对象,再调用__init__()函数初始化数据。因而,在 new 函数中判断 Singleton类 是否已经实例化过,如果不是,调用父类的 new 函数创建实例;否则返回之前创建的实例。 -
使用metaclass元类
class SigletonMetaClass(type): _instance = None def __new__(cls, *args, **kwargs): return super().__new__(cls, *args, **kwargs) def __call__(self, *args, **kwargs): if self._instance is None: self._instance = super().__call__(*args, **kwargs) return self._instance class Singleton(metaclass=SigletonMetaClass): def __new__(cls, *args, **kwargs): return super().__new__(cls) a = Singleton() b = Singleton() print(a) print(b)执行结果:<__main__.Singleton object at 0x000001A11E4AC908> <__main__.Singleton object at 0x000001A11E4AC908>因此,用元类实现单例时仍需按照三步骤:1. 拦截 2. 判断是否已经创建过对象 3. 返回对象。与上个方法相比,区别在于拦截的地点不同。
-
装饰器
4.1 函数装饰器
def SingletonDecorator(cls): _instance = None def get_instance(*args, **kwargs): nonlocal _instance if _instance is None: _instance = cls(*args, **kwargs) return _instance return get_instance @SingletonDecorator class Singleton(object): pass a = Singleton() b = Singleton() print(a) print(b)执行结果:<__main__.Singleton object at 0x0000022194E6C438> <__main__.Singleton object at 0x0000022194E6C438>4.2 类装饰器
class SingletonDecorator(object): _instance = None def __init__(self, cls): self._cls = cls def __call__(self, *args, **kwargs): if self._instance is None: self._instance = self._cls(*args, **kwargs) return self._instance @SingletonDecorator class Singleton(object): pass a = Singleton() b = Singleton() print(a) print(b)执行结果:<__main__.Singleton object at 0x0000028F42CFC8D0> <__main__.Singleton object at 0x0000028F42CFC8D0>4.2 类装饰器
class SingletonDecorator(object): _instance = None def __init__(self, cls): self._cls = cls def __call__(self, *args, **kwargs): if self._instance is None: self._instance = self._cls(*args, **kwargs) return self._instance @SingletonDecorator class Singleton(object): pass a = Singleton() b = Singleton() print(a) print(b)执行结果:<__main__.Singleton object at 0x0000028F42CFC8D0> <__main__.Singleton object at 0x0000028F42CFC8D0>
12.列出几种魔法方法并简要介绍用途
_init_: 对象初始化方法
_new_:创建对象时候执行的方法,单列模式会用到
_str_ : 当使用print输出对象的时候,只要自己定义了__str__(self)方法,那么就会打印从在这个方法中return的数据
_del_: 删除对象执行的方法
13. 理解 new 和 init 的区别
_new_:创建对象时调用,会返回当前对象的一个实例
_init_:创建完对象后调用,对当前对象的一些实例初始化,无返回值
a. 在类中,如果__new__和__init__同时存在,会优先调用__new__
class Data(object):
def __init__(self):
print('init')
def __new__(cls, *args, **kwargs):
print('new')
data = Data()
运行结果:new
b. __new__方法会返回所构造的对象,__init__则不会。__init__无返回值。
class Data(object):
def __init__(self):
self.x = 2
print('init')
return self
data = Data()
运行结果:TypeError: __init__() should return None, not 'Data'
init
class Data(object):
def __new__(cls, *args, **kwargs):
print('new')
cls.x = 1
return cls
def __init__(self):
self.x = 2
print('init')
data = Data()
print(data.x)
data.x = 2
print(data.x)
运行结果:new
1
2
14. 普通方法,类方法,静态方法区别
- 普通方法,保存在类中,执行时通过对象调用
- 静态方法,保存在类中,需要加装饰器(@staticmethod),执行通过类直接调用。不需要创建对象,可直接通过类调用,相当于函数
- 类方法,保存在类中,需要加装饰器(@classmethod),执行通过类直接调用。不需要创建对象,可直接通过类调用,相当于函数
静态方法:
class Foo:
def bar(self): # 普通方法,self是对象名
print("bar")
@staticmethod
def sta(): # 成为静态方法后,self就是非必须了
print('123')
@staticmethod
def sta2(a1,a2): # 静态方法
print(a1,a2)
@classmethod
def cla(cls): # 类方法的第一参数必须是cls,cls是类名
print('class')
print(cls)
Foo.sta() # 123
Foo.sta2(1,3) # 1 3
Foo.cla() # class
# 静态方法是类中的函数,不需要实例。当某个方法不需要用到对象中的任何资源,将这个方法改为一个静态方法, 加一个@staticmethod。加上之后, 这个方法就和普通的函数没有什么区别了, 只不过写在了一个类中, 可以使用这个类的对象调用,也可以使用类直接调用。
类方法是将类本身作为对象进行操作的方法。它和静态方法的区别在于:不管这个方式是从实例调用还是从类调用,它都用第一个参数把类传递过来。
15. 可变对象和不可变对象
什么是可变/不可变对象?
- 不可变对象,该对象所指向的内存中的值不能被改变,当改变某个变量时候,由于其所指的值不能被改变,相当于把原来的值复制一份后再改变,这会开辟一个新的地址,变量再指向这个新的地址。
- 可变对象,该对象所指向的内存中的值可以被改变,变量(准确的说是引用)改变后,实际上是其所指的值直接发生改变,并没有发生复制行为,也没有开辟新的出地址,通俗点说就是原地改变。
Python中
可变对象:dict、list、set
不可变对象:str、int、tuple、float
附: python函数调用时,参数传递方式是值传递还是引用传递?
不可变参数: 值传递
可变参数: 引用传递
16. python传参数是传值还是传址?
Python中函数参数是引用传递(注意不是值传递)。
-
对于不可变类型(数值型、字符串、元组),因变量不能修改,所以运算不会影响到变量自身;
-
对于可变类型(列表、字典)来说,函数体运算可能会更改传入的参数变量。
17. def fun(a, b=[]): 这种写法有什么坑?
def func(a,b=[]):
b.append(a)
print(b)
func(1) # [1]
func(1) # [1, 1]
func(1) # [1, 1, 1]
func(1) # [1, 1, 1, 1]
函数的第二个默认参数是一个list,当第一次执行的时候实例化了一个list,第二次执行还是用第一次执行的时候实例化的地址存储,所以三次执行的结果就是 [1, 1, 1] 。
想每次执行只输出[1] ,b = [] 应该放在函数里面。
18. is 和 == 的区别?
- is 就是判断两个对象的id是否相同
- == 判断的则是内容是否相同
19. 连接字符串用 join 还是 +
字符串是不可变对象。
- 当用操作符
+连接字符串的时候,每执行一次+都会申请一块新的内存,然后复制上一个+操作的结果和本次操作的右操作符到这块内存空间,因此用+连接字符串的时候会涉及好几次内存申请和复制。 - 而
join在连接字符串的时候,会先计算需要多大的内存存放结果,然后一次性申请所需内存并将字符串复制过去,这是为什么join的性能优于+的原因。 - 所以在连接字符串数组的时候,我们应考虑优先使用join。
20.赋值,深拷贝,浅拷贝
浅拷贝: 拷贝对象的第一层。
深拷贝: 拷贝对象的所有层。
说大白话:
B 拷贝于 A
浅拷贝虽然说是拷贝,但也是 “ 身不由己 ” ,当修改除了第一层之外的值时,都会改动(内嵌列表表面上也拷贝过来了,但实际还是不是自己说了算的,只要改了内嵌列表的值,拷贝的也要改,这就是只拷贝一层,内嵌的就无能为力了),当A的第二层改变时,B的第二层也会随之改变。
深拷贝就是彻底的拷贝,两者就再毫无关系,虽然拷贝完不改的话长的一样,但是不管对谁改动,另一个也是毫不受影响。当A的第二层改变时,B的第二层不受影响。
21. Python中的复制(赋值),底层是怎么实现的?
Python中,对象的赋值实际上是简单的对象引用。也就是说,当你创建一个对象,然后把它复制给另一个变量的时候,Python并没有拷贝这个对象,而是拷贝了这个对象的引用(指针)。
22. python垃圾回收机制
python垃圾回收主要以引用计数为主,标记-清除和分代清除为辅的机制,其中标记-清除和分代回收主要是为了处理循环引用的难题。
引用计数
引用计数算法
当有1个变量保存了对象的引用时,此对象的引用计数就会加1。
当使用del删除变量指向的对象时,如果对象的引用计数不为1,比如3,那么此时只会让这个引用计数减1,即变为2,当再次调用del时,变为1,如果再调用1次del,此时会真的把对象进行删除。
引用计数+1的四种情况:
- 对象被创建 a=14
- 对象被引用 b=a
- 对象被作为参数,传到函数中 func(a)
- 对象作为一个元素,存储在容器中 List={a,”a”,”b”,2}
对应的引用计数-1的四种情况:
- 当该对象的别名被显式销毁时 del a
- 当该对象的引别名被赋予新的对象, a=26
- 一个对象离开它的作用域,例如 func函数执行完毕时,函数里面的局部变量的引用计数器就会减一(但是全局变量不会)
- 将该元素从容器中删除时,或者容器被销毁时。
优点: 简单实时,一旦没有引用,内存就直接释放了。处理回收内存的时间分摊到了平时。
缺点: 维护引用计数消耗资源,会造成循环引用导致无法回收,造成内存泄露,比如:
list1 = []
list2 = []
list1.append(list2)
list2.append(list1)
'''
list1与list2相互引用,即使不存在其他对象对它们的引用,list1与list2的引用计数也
仍然为1,所占用的内存永远无法被回收,这将是致命的。
'''
标记清除(Mark—Sweep)
算法是一种基于追踪回收(tracing GC)技术实现的垃圾回收算法。
它分为两个阶段:
- 第一阶段是标记阶段,GC会把所有的『活动对象』打上标记,
- 第二阶段是把那些没有标记的对象『非活动对象』进行回收。
那么GC又是如何判断哪些是活动对象哪些是非活动对象的呢?
- 对象之间通过引用(指针)连在一起,构成一个
有向图,对象构成这个有向图的节点,而引用关系构成这个有向图的边。 - 从根对象(root object)出发,沿着有向边遍历对象,可达的(reachable)对象标记为活动对象,不可达的对象就是要被清除的非活动对象。
根对象就是全局变量、调用栈、寄存器。
标记清除算法作为Python的辅助垃圾收集技术主要处理的是一些容器对象,比如list、dict、tuple,instance等,
因为对于字符串、数值对象是不可能造成循环引用问题。
缺点: 清除非活动的对象前它必须顺序扫描整个堆内存,哪怕只剩下小部分活动对象也要扫描所有对象。
分代回收
分代回收是一种以空间换时间的操作方式,Python将内存根据对象的存活时间划分为不同的集合,每个集合称为一个代。
- Python将内存分为了3“代”,分别为年轻代(第0代)、中年代(第1代)、老年代(第2代),
- 他们对应的是3个
链表,它们的垃圾收集频率与对象的存活时间的增大而减小。 - 新创建的对象都会分配在年轻代,年轻代链表的总数达到上限时,Python垃圾收集机制就会被
触发,把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去, - 依此类推,老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内。
- 同时,分代回收是建立在标记清除技术基础之上。
- 说明对象存在时间越长,越可能不是垃圾,应该越少去收集。
- 分代回收同样作为Python的辅助垃圾收集技术处理那些容器对象
23. fun(*args,**kwargs)中的 *args,**kwargs什么意思?
*args: 用来发送一个非键值对的可变数量的参数列表给一个函数。
**kwargs: 用来发送一个可变的键值对的参数给一个函数。
24. python2和python3的range(100)的区别
python2返回列表,python3返回迭代器,节约内存
25. 写一个打印时间的装饰器?
import time
# 装饰函数
def timer(func):
def wrapper(*args, **kw):
start =time.time()
# 这是函数真正执行的地方
func(*args, **kw)
end =time.time()
cost_time = end - start
print("花费时间:{}秒".format(cost_time))
return wrapper
@timer
def want_sleep(sleep_time):
time.sleep(sleep_time)
want_sleep(5)
26.请解释 Python 中的闭包?
闭包函数 指定义在一个函数内部的函数,被外层函数包裹着,其特点是可以访问外层函数的变量。
def outer():
num = 1
def inner():
print num # 内层函数可以访问外层函数中的 num
return inner # 外层函数的返回值必须是内层函数
fun = outer()
num = 1
fun() # 1
27.python中断言方法举例
assert()方法,断言成功,则程序继续执行,断言失败,则程序报错
a = 3
assert (a > 1)
print("断言成功,程序继续往下执行")
b = 4
assert (b > 7)
print("断言失败,程序报错")
28. 正则表达式匹配中,(.*)和(.*?)匹配区别?
(.*)是贪婪匹配,会把满足正则的尽可能多的往后匹配
(.*?)是非贪婪匹配,会把满足正则的尽可能少匹配
import re
s = "哈哈呵呵呵"
res1 = re.findall("(.*)",s)
print("贪婪匹配", res1)
res2 = re.findall("(.*?)",s)
print("非贪婪匹配", res2)
运行结果:贪婪匹配 ['哈哈呵呵呵']
非贪婪匹配 ['哈哈', '呵呵呵']
29.python字典和json字符串相互转化方法
- json.dumps() 字典转json字符串
- json.loads() json字符串转字典
30. 如何提高python的运行效率?
- 关键代码使用外部功能包(Cython,pylnlne,pypy,pyrex)
- 针对循环的优化–尽量避免在循环中访问变量的属性
- 使用较新版本的python
- 尝试多种编码方法
- 交叉编译应用程序
31. 时间复杂度
如何推导出时间复杂度呢?有如下几个原则:
-
如果运行时间是常数量级,用常数1表示;
-
只保留时间函数中的最高阶项;
-
如果最高阶项存在,则省去最高阶项前面的系数。
场景1:T(n) = 3n,执行次数是线性的,T(n) = O(n)
void eat1(int n){
for(int i=0; i<n; i++){
;
System.out.println("等待一天");
System.out.println("等待一天");
System.out.println("吃一寸面包");
}
}
场景2:T(n) = 5logn,执行次数是对数的,T(n) = O(log n)
void eat2(int n)
for(int i=1; i<n; i*=2){
System.out.println("等待一天");
System.out.println("等待一天");
System.out.println("等待一天");
System.out.println("等待一天");
System.out.println("吃一半面包");
}
}
场景3:T(n) = 2,执行次数是常量的, T(n) = O(1)
void eat3(int n){
System.out.println("等待一天");
System.out.println("吃一个鸡腿");
}
场景4:T(n) = 0.5n^2 + 0.5n,执行次数是一个多项式,T(n) = O(n^2)
void eat4(int n){
for(int i=0; i<n; i++){
for(int j=0; j<i; j++){
System.out.println("等待一天");
}
System.out.println("吃一寸面包");
}
}
这四种时间复杂度究竟谁用时更长,谁节省时间呢?
O(1)< O(logn)< O(n)< O(n^2)
32. python3高阶函数:map() , reduce() , filter() ,lambda()
1.map():遍历序列,根据提供的函数对指定序列做映射,对序列中每个元素进行操作,最终获取新的序列
例1:
print(list(map(str, [1, 2, 3, 4, 5, 6, 7, 8, 9])))
# 输出结果:['1', '2', '3', '4', '5', '6', '7', '8', '9']
例2:
def square(x):
return x**2
result = list(map(square,[1,2,3,4,5]))
print(result)
# 输出结果:[1, 4, 9, 16, 25]
备注:map() : Python 2.x 返回列表;Python 3.x 返回迭代器
2.reduce():对于序列内所有元素进行累计操作,即是序列中后面的元素与前面的元素做累积计算
(结果是所有元素共同作用的结果)
from functools import reduce
def addl(x,y):
return x + y
print(reduce(addl,range(1,5)))
# 输出结果:10
reduce()的作用是接收一个列表,[1,2,3,4]
首先,将1,2传给addl(),计算结果为3
接着,将3,3传给addl(),计算结果为6
接着,将6,4传给addl(),计算结果为10
…
3.filter():过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换
def func(x):
return x%2==0
print(list(filter(func,range(1,6))))
# 输出结果:[2, 4]
4.lambda(),匿名函数,不需要命名的函数def f ( x ,y):
def add(x,y):
return x + y
print(add(1,2))
# 等效于:
g = lambda x, y : x + y
print(g(1,2))
lambda表达式的作用:
- python写一些执行脚本时,使用lambda就可以省下定义函数过程,比如说我们只是需要写个简单的脚本来管理服务器时间,我们就不需要专门定义一个函数然后再写调用,使用lambda就可以使得代码更加精简。
- 对于一些比较抽象并且整个程序执行下来只需要调用一两次的函数,有时候给函数起个名字也是比较头疼的问题,使用lambda就不需要考虑命名的问题了。
- 简化代码的可读性,由于普通的函数阅读经常要跳到开头def定义部分,使用lambda函数可以省去这样的步骤。
33. python with用法+原理剖析
用法:with语句适用于对资源进行访问的场合,确保不管使用过程中是否发生异常都会释放资源,比如文件使用后自动关闭、线程中锁的自动获取和释放等。
with open("xxx") as f:
f.write() #文件操作
原理: 基本思想是with所求值的对象必须有一个__enter__()方法,一个__exit__()方法。
紧跟with后面的语句被求值后,__enter__()方法的返回值将被赋值给as后面的变量。当with下面的代码块全部被执行完之后,将调用前面返回对象的__exit__()方法,对象的__exit__要接受三个参数:异常类型、异常对象和异常跟踪。
34. 如何捕获异常,常用的异常机制有哪些?
捕获异常需调用python默认的异常处理器,并在终端输出异常信息。
-
try...except...finally语句:当try语句执行时发生异常,回到try语句层,寻找后面是否有except语句。找到except语句后,会调用这个自定义的异常处理器。except将异常处理完毕后,程序继续往下执行。finally语句表示,无论异常发生与否,finally中的语句都要执行。 -
assert语句:判断assert后面紧跟的语句是True还是False,如果是True则继续执行print,如果是False则中断程序,调用默认的异常处理器,同时输出assert语句逗号后面的提示信息。 -
with语句:如果with语句或语句块中发生异常,会调用默认的异常处理器处理,但文件还是会正常关闭。
35. copy()与deepcopy()的区别
copy是浅拷贝,只拷贝可变对象的父级元素。 deepcopy是深拷贝,递归拷贝可变对象的所有元素。
36.函数装饰器有什么作用(常考)
装饰器本质上是一个Python函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象。它经常用于有切面需求的场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景。有了装饰器,就可以抽离出大量与函数功能本身无关的雷同代码并继续重用。
37.简述Python的作用域以及Python搜索变量的顺序
Python作用域简单说就是一个变量的命名空间。代码中变量被赋值的位置,就决定了哪些范围的对象可以访问这个变量,这个范围就是变量的作用域。
在Python中,只有模块(module),类(class)以及函数(def、lambda)才会引入新的作用域。
Python的变量名解析机制也称为 LEGB 法则:本地作用域Local→当前作用域被嵌入的本地作用域Enclosing locals→全局/模块作用域Global→内置作用域Built-in
38.简述__new__和__init__的区别
创建一个新实例时调用 __new__,初始化一个实例时用__init__,这是它们最本质的区别。
__new__方法会返回所构造的对象,__init__则不会.
__new__函数必须以cls作为第一个参数,而__init__则以self作为其第一个参数.
39.Python垃圾回收机制(常考)
Python GC主要使用引用计数(reference counting)来跟踪和回收垃圾。在引用计数的基础上,通过“标记-清除”(mark and sweep)解决容器对象可能产生的循环引用问题,通过“分代回收”(generation collection)以空间换时间的方法提高垃圾回收效率。
- 引用计数
PyObject是每个对象必有的内容,其中ob_refcnt就是做为引用计数。当一个对象有新的引用时,它的ob_refcnt就会增加,当引用它的对象被删除,它的ob_refcnt就会减少.引用计数为0时,该对象生命就结束了。
优点: 简单, 实时性
缺点: 维护引用计数消耗资源, 循环引用
- 标记-清除机制
基本思路是先按需分配,等到没有空闲内存的时候从寄存器和程序栈上的引用出发,遍历以对象为节点、以引用为边构成的图,把所有可以访问到的对象打上标记,然后清扫一遍内存空间,把所有没标记的对象释放。
- 分代技术
分代回收的整体思想是:将系统中的所有内存块根据其存活时间划分为不同的集合,每个集合就成为一个“代”,垃圾收集频率随着“代”的存活时间的增大而减小,存活时间通常利用经过几次垃圾回收来度量。
Python默认定义了三代对象集合,索引数越大,对象存活时间越长。
40. Python中的@property有什么作用?如何实现成员变量的只读属性?
@property装饰器: 将一个方法的调用方式变成“属性调用”。
通常用在属性的get方法,set方法,通过设置@property可以实现实例成员变量的直接访问,又保留了参数的检查。
class Student(object):
@property
def score(self):
return self.__score
@score.setter
def score(self,value):
if value>=0 and value <= 100:
self.__score = value #还记得__score吗?前面加一个双下划线,表示private私有属性
else:
raise ValueError('score must between 0 ~ 100!')
s = Student()
s.score = 90 # 设置分数
print(s.score)
@property修饰函数score(getter),将score函数变成score属性输出,此外,@property本身又创建了另一个装饰器@score.setter,负责把一个 setter 函数变成属性赋值,于是,我们虽然看到了类Student内部定义了两个函数score,对,没错,都是score,但是,他们却被不同的装饰器装饰,getter函数被@property修饰,setter函数被@property创建的函数的setter装饰器@score.setter修饰,因此,我们可以直接用s.score=90来代替s.set_socre(90),达到给score属性赋值的效果,简单粗暴,精益求精,
我们上面创建了@property另一个装饰器函数@xxx.setter,对私有属性__score进行输入值的判断,如果,我们不创建装饰器@xxx.setter可以吗?如果不创建的话,属性xxx就是一个只读属性,意味着不能被修改,
41.文件操作时:xreadlines 和 readlines 的区别?
readlines() 是把文件全部读到内存,并解析为一个list, 当文件体积比较大时,会占用很多内存。
xreadlines() 直接返回一个 iter(file) 迭代器,在python2.3之后已经不推荐这种方法了,直接用for循环迭代文件对象。
42.列举布尔值为 False 的常见值?
0, [], (), {
}, '', False, None
43.现有字典 dict = {‘a’ : 24, ‘d’ : 55, ‘kj’ : 86},请按照字段中的的value值进行排序
dict = {
'a': 24, 'd': 55, 'kj': 30}
# 按照 value 进行排序
new_dict1 = sorted(dict.items(), key=lambda c: c[1])
print new_dict1
# 按照 key 进行排序
new_dict2 = sorted(dict.items(), key=lambda c: c[0])
print new_dict2
44.现有列表 list=[{‘name’: ‘a’, ‘age’: 24}, {‘name’: ‘d’, ‘age’: 55}, {‘name’: ‘c’, ‘age’: 67}],请按照 age 进行从大到小排序
list = [{
'name': 'a', 'age': 24}, {
'name': 'd', 'age': 55}, {
'name': 'c', 'age': 32}]
new_list1 = sorted(list, key=lambda c: c['age'], reverse=True)
print new_list1
45.下面代码输出结果是?
list = [1, 2, 3, 4, 5]
print list[10:]
'''
代码输出空列表[], 并不会出现 IndexError
'''
print list[10]
'''
IndexError: list index out of range
'''
46.python 递归的最大层数
python最大递归层数为:1000
如何修改最大递归层数?
在python内置的sys模块中,可以获取和调整最大递归深度
import sys
print sys.getrecursionlimit() # 1000
sys.setrecursionlimit(3000)
print sys.getrecursionlimit() # 3000
47.mro是什么?
Method Resolution Order, 方法解析顺序
方法调用时,对当前类以及基类进行搜索以确定方法所在的位置。搜索顺序即为方法解析顺序
48.双下划线和单下划线的区别?
“单下划线”开始的成员变量叫做保护变量,类对象和子类对象自己能访问。
“双下划线”开始的成员变量叫做私有成员,只有类对象自己能访问,子类对象不能访问。
49.select ,poll, epoll 模型的区别?
I/O 多路复用的本质是用 select/poll/epoll模型 去监听多个socket对象,用户进程可及时知道其中的socket对象发生的变化。
select 是不断轮询监听socket, socket个数有限制,一般为1024个。Apache用select模型。
poll 增强select模型,也是轮询监听,没有个数限制。
epoll 不采用轮询监听,而是当socket有变化时,通过回调(调用)的方式主动告知用户进程,高效。Nginx用这个模型。
所以Nginx比Apache更高效
50.进程间如何通信?
Queue: 多进程间通信
Pipe: 两个进程间通信
51.线程间如何通信?
threading.Event 事件
threading.Condition 条件
queue.Queue 队列
52.生产者和消费者模型
生产者和消费者模型 是通过一个容器来解决生产者和消费者的强耦合关系。
生产者和消费者不直接通信,而是利用阻塞队列通信,生产者生成数据后直接存入队列中,消费者需要数据时,从队列中获取。
主要解决生产者和消费者速率不一致的问题,平衡生产者和消费者的处理能力.
53.什么是反射?
'''
通过“字符串”的形式操作(获取、判断、设置、删除)对象中的成员
getattr() 返回一个对象属性值。
hasattr() 判断对象中是否含有某属性
setattr(obj,‘sex’, ‘men’) 给obj对象添加属性sex,值为men
delattr(obj,‘name’) 删除obj对象中的name属性
'''
class Foo:
def __init__(self,name,age):
self.name = name
self.age = age
obj = Foo('Alex',18)
print(getattr(obj,'name')) # Alex
print(hasattr(obj,'name')) # True
setattr(obj,'sex','men')
print(obj.sex) # men
delattr(obj,'name')
54.怎么样处理死锁?
首先回答死锁发生的条件和原因, 然后针对它来解决
原因:
- 互斥:每个资源要么已经分配给了一个进程,要么就是可用的。
- 占有并等待:已经得到了某个资源的进程可以再次请求新的资源。
- 不可抢占:已经分配给一个进程的资源不能强制性地被抢占,它只能被占有它的进程显式地释放。
- 环路等待:有两个或者两个以上的进程组成一条环路,该环路中的每个进程都在等待下一个进程所占有的资源。
解决:
- 允许某些资源同时被多个进程访问。
- 鸵鸟策略:直接忽略死锁。大多数操作系统,包括 Unix,Linux 和 Windows,处理死锁问题的办法仅仅是忽略它。
- 预分配
- 允许进程强行抢占被其它进程占有的资源
- 对资源设置优先级,只有占有了低优先级资源才可以申请高优先级资源
55.Python进制转换
将字符串先转换为十进制,再使用相应的函数进行转换。
| ↓ | 2进制 | 8进制 | 10进制 | 16进制 |
|---|---|---|---|---|
| 2进制 | - | bin(int(n,8)) | bin(int(n,10)) | bin(int(n,16)) |
| 8进制 | oct(int(n,2)) | - | oct(int(n,10)) | oct(int(n,16)) |
| 10进制 | int(n,2) | int(n,8) | - | int(n,16) |
| 16进制 | hex(int(n,2)) | hex(int(n,8)) | hex(int(n,10)) | - |
56. sorted() 函数
'''
sorted(iterable, cmp=None, key=None, reverse=False)
iterable -- 可迭代对象。
cmp -- 比较的函数,这个具有两个参数,参数的值都是从可迭代对象中取出,此函数必须遵守的规则为,大于则返回1,小于则返回-1,等于则返回0。
key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
reverse -- 排序规则,reverse = True 降序 , reverse = False 升序(默认)。
'''
57. 什么是python元类?
在Python当中万物皆对象,我们用class关键字定义的类本身也是一个对象,负责产生该对象的类称之为元类,元类可以简称为类的类,
元类的主要目的是为了控制类的创建行为.
type是Python的一个内建元类,用来直接控制生成类,在python当中任何class定义的类其实都是type类实例化的结果。
只有继承了type类才能称之为一个元类,否则就是一个普通的自定义类,自定义元类可以控制类的产生过程,类的产生过程其实就是元类的调用过程.