
2019年的最后一个月里面我们收集了许多有关先进机器和深度学习研究的文章以及其开源代码,希望对大家有所帮助。
Contrastive Representation Distillation
本文在模型蒸馏领域利用对比目标族来捕获相关性和高阶输出相关性。它们在本文中被改编成从一个神经网络到另一个神经网络的知识提取。
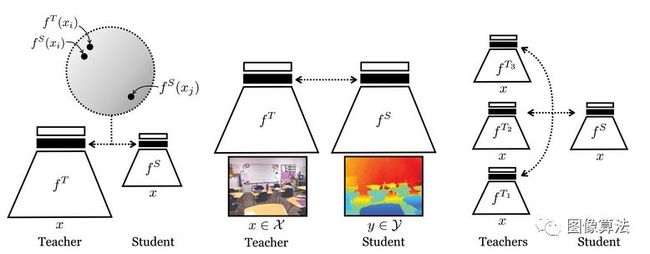
本文考虑了三个阶段:
模型压缩
将数据从一种格式(比如RGB)转移到另一种格式(例如深度)
将一组网络精简成一个网络
对比学习的主要思想是在一定的度量空间内学习一个接近正对的表示,同时去掉负对之间的表示。
论文地址:
https://arxiv.org/pdf/1910.10699.pdf
源码地址:
https://github.com/HobbitLong/RepDistiller
Network Pruning via Transformable Architecture Search
这是一篇在网络剪枝领域的论文。提出了将神经网络搜索直接应用于具有灵活信道和层大小的网络。最小化剪枝网络的损失有助于学习信道的数量。
剪枝网络的特征映射由K个特征映射片段组成,这些片段基于概率分布进行采样。损失被反向传播到网络权重和参数化分布。
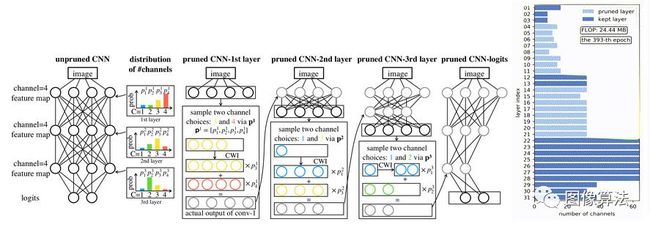
本文提出的修剪方法分为三个阶段:
训练不按标准分类培训程序运行的大型网络。
使用可切换架构搜索(TAS)搜索小型网络的深度和广度。TA的目标是找到网络的最佳规模。
利用简单(KD)方法将非操作网络中的信息传递到搜索到的小网络中。
论文地址:
https://arxiv.org/pdf/1905.09717.pdf
源码地址:
https://github.com/D-X-Y/NAS-Projects
Learning Data Augmentation Strategies for Object Detection
虽然这本身不是一个模型体系结构,但是本文介绍了创建可用于对象检测数据集的转换的方法,并且这些转换可以传输到其他对象检测数据集。变换通常在训练期间应用。
该模型将增广策略定义为训练过程中随机选择的n个策略集。该模型中应用的一些操作包括扭曲颜色通道、几何扭曲图像以及仅扭曲边界框批注中的像素内容。
论文地址:
https://arxiv.org/pdf/1906.11172.pdf
源码地址:
https://github.com/tensorflow/tpu/tree/master/models/official/detection
XLNet: Generalized Autoregressive Pretraining for Language Understanding
XLNet是一篇激动人心的论文,XLNET是一种一般的自回归预训练方法,它通过最大化分解因子的所有排列的期望似然来学习双向上下文。它不使用固定的正向或反向分解顺序。
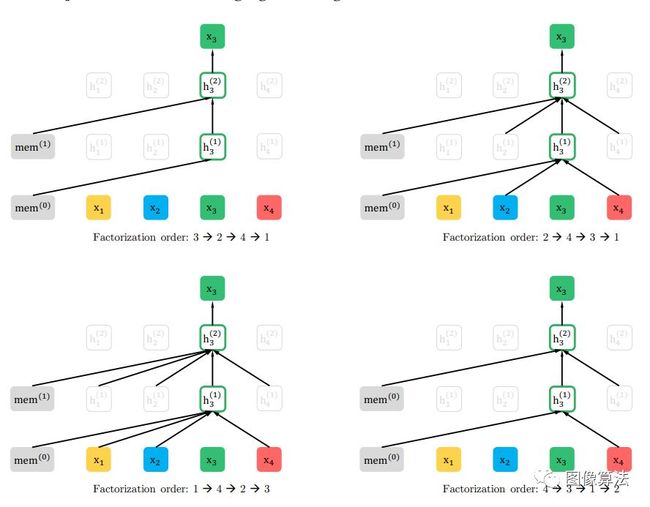
它解决了所有可能的排列顺序,以最大限度地提高序列的预期日志可能性。由于这些排列,每个位置的上下文可以由左标记和右标记组成。由于每个位置都学习使用来自所有位置的上下文信息,因此会捕获双向上下文。
论文地址:
https://arxiv.org/pdf/1906.08237.pdf
源码地址:
https://github.com/zihangdai/xlnet
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context (ACL 2019)
Transformer XL可以用来学习固定长度以外的依赖关系,而不会破坏时间一致性。它结合了段级递归和位置编码方案。TransformerXL的依赖比RNN长80%,比RNNs Transformers长450%。TensorFlow和Pythorch都可用。
作者将递归引入其深层自我注意网络。它们不再从头开始计算每个新段的隐藏状态,而是重用在前一段中获得的隐藏状态。重用的隐藏状态充当循环段的内存。
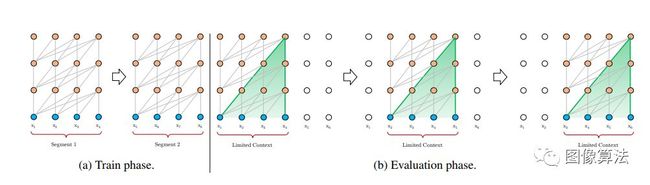
这将在段之间建立循环连接。建模长期依赖关系是可能的,因为信息是通过循环连接传递的。作者还介绍了一种更有效的相对位置编码方法,该方法可以将注意力集中到比训练时所观察到的注意力长度更长的位置上。
论文地址:
https://arxiv.org/pdf/1901.02860.pdf
源码地址:
https://github.com/kimiyoung/transformer-xl
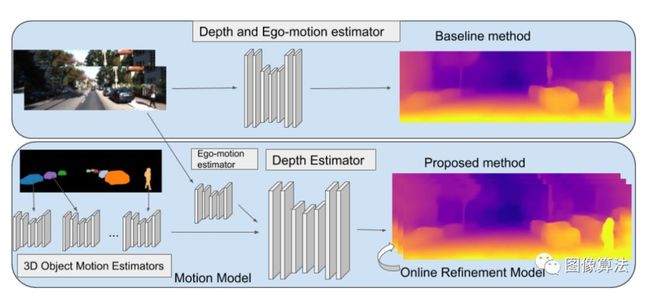
Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos (AAAI 2019)
本文研究的是场景深度和机器人自运动的无监督学习任务,其中监控由单目视频提供。这是通过在学习过程中引入几何结构来实现的。它包括对场景和单个对象建模、相机的自运动以及从单目视频输入中学习到的对象运动。介绍了一种在线优化方法。
介绍了一种与自运动网络结构相同的对象运动模型。然而,它是专门为预测三维中单个物体的运动而设计的。
它以一系列RGB图像作为输入。这由预先计算的实例细分掩码补充。运动模型的工作是学习预测三维空间中每个物体的变换矢量。这将在各种目标框中创建观察到的对象外观。
论文地址:
https://arxiv.org/pdf/1811.06152.pdf
源码地址:
https://github.com/tensorflow/models/tree/master/research/struct2depth
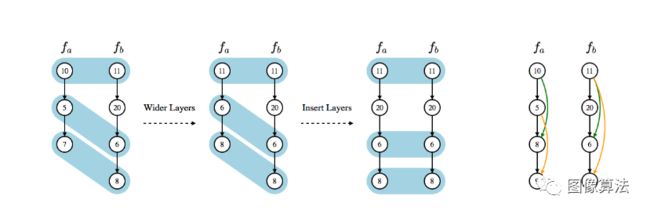
Auto-Keras: An Efficient Neural Architecture Search System
本文提出了一个贝叶斯优化的框架来指导网络形态的有效NAS。基于这种方法,作者构建了一个名为Auto-Keras的开源AutoML系统。
该方法的主要组成部分是在贝叶斯优化(BO)算法的指导下,通过变形神经网络结构来探索搜索空间。由于NAS空间不是欧几里德空间,作者通过设计神经网络核函数来解决这一问题。核函数是用来将一种神经结构转换成另一种神经结构的编辑距离。
论文地址:
https://arxiv.org/pdf/1806.10282.pdf
源码地址:
https://github.com/keras-team/autokeras
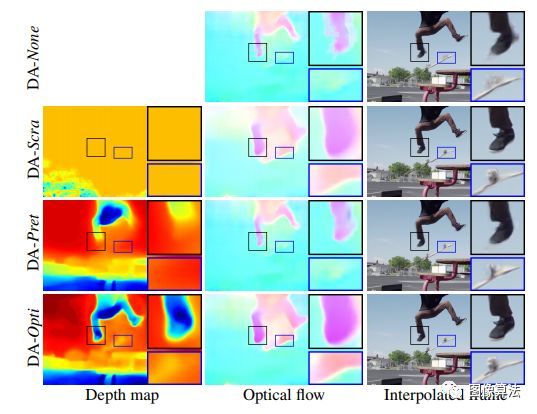
Depth-Aware Video Frame Interpolation (CVPR 2019)
提出了一种利用深度信息检测遮挡的视频帧插值方法。作者开发了一个深度感知流投影层,它可以合成一个即时流,对较近的对象进行采样,而不是对较远的对象进行采样。
通过从相邻像素中收集上下文信息来学习层次特征。然后,基于光流和局部插值核,通过扭曲输入帧、深度图和上下文特征来生成输出帧。
提出了一种深度感知视频帧内插(DAIN)模型,该模型可以有效地利用光流、局部内插核、深度图和上下文特征生成高质量的视频帧。
论文地址:
https://arxiv.org/pdf/1904.00830.pdf
源码地址:
https://github.com/baowenbo/DAIN
OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
open pose是一个开放源码的实时多人二维姿态估计系统,包括身体、脚、手和脸的关键点。提出了一种实时检测图像和视频中二维人体姿态的方法。
该方法使用一种称为零件关联域(PAF)的非参数表示。本文的一些作者来自IEEE。该方法以图像作为CNN的输入,预测用于检测人体部位的置信图和用于部位关联的PAF。本文还提出了一个带有15K个人类脚实例的带注释的脚数据集。

论文地址:
https://arxiv.org/pdf/1812.08008.pdf
源码地址:
https://github.com/CMU-Perceptual-Computing-Lab/openpose_train
FastFCN: Rethinking Dilated Convolution in the Backbone for Semantic Segmentation
本文提出了一种联合上采样模块,称为联合金字塔上采样(JPU),以取代耗时和内存密集的扩展卷积。它的工作原理是将提取高分辨率映射的函数表示为一个联合上采样问题。
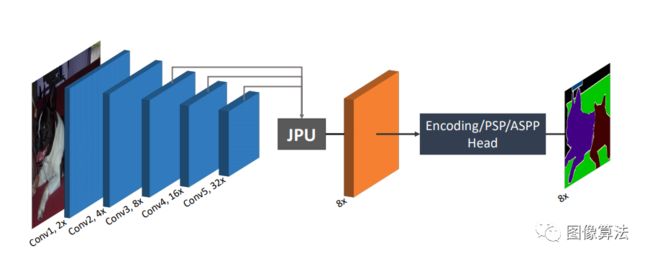
该方法以全连通网络(FCN)为骨干网络,利用JPU对低分辨率的最终特征图进行上采样,得到高分辨率的特征图。用JPU替换膨胀卷积不会导致性能损失。
论文地址:
https://arxiv.org/pdf/1903.11816.pdf
源码地址:
https://github.com/wuhuikai/FastFCN
总结
这些可以让你对2019年的机器和深度学习研究领域有所了解。希望对各位同学有所帮助。
更多论文或源码下载地址:关注“图像算法”微信公众号