一、部署环境
主机列表:
| 主机名 | Centos版本 | ip | docker version | flannel version | Keepalived version | 主机配置 | 备注 |
|---|---|---|---|---|---|---|---|
| master01 | 7.6.1810 | 172.27.34.3 | 18.09.9 | v0.11.0 | v1.3.5 | 4C4G | control plane |
| master02 | 7.6.1810 | 172.27.34.4 | 18.09.9 | v0.11.0 | v1.3.5 | 4C4G | control plane |
| master03 | 7.6.1810 | 172.27.34.5 | 18.09.9 | v0.11.0 | v1.3.5 | 4C4G | control plane |
| work01 | 7.6.1810 | 172.27.34.93 | 18.09.9 | / | / | 4C4G | worker nodes |
| work02 | 7.6.1810 | 172.27.34.94 | 18.09.9 | / | / | 4C4G | worker nodes |
| work03 | 7.6.1810 | 172.27.34.95 | 18.09.9 | / | / | 4C4G | worker nodes |
| VIP | 7.6.1810 | 172.27.34.130 | 18.09.9 | v0.11.0 | v1.3.5 | 4C4G | 在control plane上浮动 |
| client | 7.6.1810 | 172.27.34.234 | / | / | / | 4C4G | client |
共有7台服务器,3台control plane,3台work,1台client。
k8s 版本:
| 主机名 | kubelet version | kubeadm version | kubectl version | 备注 |
|---|---|---|---|---|
| master01 | v1.16.4 | v1.16.4 | v1.16.4 | kubectl选装 |
| master02 | v1.16.4 | v1.16.4 | v1.16.4 | kubectl选装 |
| master03 | v1.16.4 | v1.16.4 | v1.16.4 | kubectl选装 |
| work01 | v1.16.4 | v1.16.4 | v1.16.4 | kubectl选装 |
| work02 | v1.16.4 | v1.16.4 | v1.16.4 | kubectl选装 |
| work03 | v1.16.4 | v1.16.4 | v1.16.4 | kubectl选装 |
| client | / | / | v1.16.4 | client |
二、高可用架构
本文采用kubeadm方式搭建高可用k8s集群,k8s集群的高可用实际是k8s各核心组件的高可用,这里使用主备模式,架构如下:

主备模式高可用架构说明:
| 核心组件 | 高可用模式 | 高可用实现方式 |
|---|---|---|
| apiserver | 主备 | keepalived |
| controller-manager | 主备 | leader election |
| scheduler | 主备 | leader election |
| etcd | 集群 | kubeadm |
- apiserver 通过keepalived实现高可用,当某个节点故障时触发keepalived vip 转移;
- controller-manager k8s内部通过选举方式产生领导者(由--leader-elect 选型控制,默认为true),同一时刻集群内只有一个controller-manager组件运行;
- scheduler k8s内部通过选举方式产生领导者(由--leader-elect 选型控制,默认为true),同一时刻集群内只有一个scheduler组件运行;
- etcd 通过运行kubeadm方式自动创建集群来实现高可用,部署的节点数为奇数,3节点方式最多容忍一台机器宕机。
三、安装准备工作
control plane和work节点都执行本部分操作。
Centos7.6安装详见:Centos7.6操作系统安装及优化全纪录
安装Centos时已经禁用了防火墙和selinux并设置了阿里源。
1. 配置主机名
1.1 修改主机名
[root@centos7 ~]# hostnamectl set-hostname master01
[root@centos7 ~]# more /etc/hostname
master01
退出重新登陆即可显示新设置的主机名master01
1.2 修改hosts文件
[root@master01 ~]# cat >> /etc/hosts << EOF
172.27.34.3 master01
172.27.34.4 master02
172.27.34.5 master03
172.27.34.93 work01
172.27.34.94 work02
172.27.34.95 work03
EOF

2. 验证mac地址uuid
[root@master01 ~]# cat /sys/class/net/ens160/address
[root@master01 ~]# cat /sys/class/dmi/id/product_uuid

保证各节点mac和uuid唯一
3. 禁用swap
3.1 临时禁用
[root@master01 ~]# swapoff -a
3.2 永久禁用
若需要重启后也生效,在禁用swap后还需修改配置文件/etc/fstab,注释swap
[root@master01 ~]# sed -i.bak '/swap/s/^/#/' /etc/fstab

4. 内核参数修改
本文的k8s网络使用flannel,该网络需要设置内核参数bridge-nf-call-iptables=1,修改这个参数需要系统有br_netfilter模块。
4.1 br_netfilter模块加载
查看br_netfilter模块:
[root@master01 ~]# lsmod |grep br_netfilter
如果系统没有br_netfilter模块则执行下面的新增命令,如有则忽略。
临时新增br_netfilter模块:
[root@master01 ~]# modprobe br_netfilter
该方式重启后会失效
永久新增br_netfilter模块:
[root@master01 ~]# cat > /etc/rc.sysinit << EOF
#!/bin/bash
for file in /etc/sysconfig/modules/*.modules ; do
[ -x $file ] && $file
done
EOF
[root@master01 ~]# cat > /etc/sysconfig/modules/br_netfilter.modules << EOF
modprobe br_netfilter
EOF
[root@master01 ~]# chmod 755 /etc/sysconfig/modules/br_netfilter.modules
4.2 内核参数临时修改
[root@master01 ~]# sysctl net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-iptables = 1
[root@master01 ~]# sysctl net.bridge.bridge-nf-call-ip6tables=1
net.bridge.bridge-nf-call-ip6tables = 1
4.3 内核参数永久修改
[root@master01 ~]# cat < /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
[root@master01 ~]# sysctl -p /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
5. 设置kubernetes源
5.1 新增kubernetes源
[root@master01 ~]# cat < /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
- [] 中括号中的是repository id,唯一,用来标识不同仓库
- name 仓库名称,自定义
- baseurl 仓库地址
- enable 是否启用该仓库,默认为1表示启用
- gpgcheck 是否验证从该仓库获得程序包的合法性,1为验证
- repo_gpgcheck 是否验证元数据的合法性 元数据就是程序包列表,1为验证
- gpgkey=URL 数字签名的公钥文件所在位置,如果gpgcheck值为1,此处就需要指定gpgkey文件的位置,如果gpgcheck值为0就不需要此项了
5.2 更新缓存
[root@master01 ~]# yum clean all
[root@master01 ~]# yum -y makecache
6. 免密登录
配置master01到master02、master03免密登录,本步骤只在master01上执行。
6.1 创建秘钥
[root@master01 ~]# ssh-keygen -t rsa
6.2 将秘钥同步至master02/master03
[root@master01 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub [email protected]
[root@master01 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub [email protected]
6.3 免密登陆测试
[root@master01 ~]# ssh 172.27.34.4
[root@master01 ~]# ssh master03

master01可以直接登录master02和master03,不需要输入密码。
四、Docker安装
control plane和work节点都执行本部分操作。
1. 安装依赖包
[root@master01 ~]# yum install -y yum-utils device-mapper-persistent-data lvm2
2. 设置Docker源
[root@master01 ~]# yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo

3. 安装Docker CE
3.1 docker安装版本查看
[root@master01 ~]# yum list docker-ce --showduplicates | sort -r
3.2 安装docker
[root@master01 ~]# yum install docker-ce-18.09.9 docker-ce-cli-18.09.9 containerd.io -y

指定安装的docker版本为18.09.9
4. 启动Docker
[root@master01 ~]# systemctl start docker
[root@master01 ~]# systemctl enable docker
5. 命令补全
5.1 安装bash-completion
[root@master01 ~]# yum -y install bash-completion
5.2 加载bash-completion
[root@master01 ~]# source /etc/profile.d/bash_completion.sh

6. 镜像加速
由于Docker Hub的服务器在国外,下载镜像会比较慢,可以配置镜像加速器。主要的加速器有:Docker官方提供的中国registry mirror、阿里云加速器、DaoCloud 加速器,本文以阿里加速器配置为例。
6.1 登陆阿里云容器模块
登陆地址为:https://cr.console.aliyun.com ,未注册的可以先注册阿里云账户

6.2 配置镜像加速器
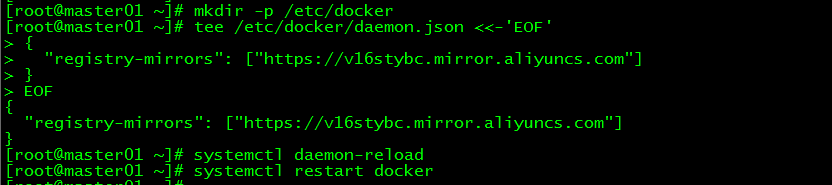
配置daemon.json文件
[root@master01 ~]# mkdir -p /etc/docker
[root@master01 ~]# tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://v16stybc.mirror.aliyuncs.com"]
}
EOF
重启服务
[root@master01 ~]# systemctl daemon-reload
[root@master01 ~]# systemctl restart docker
加速器配置完成
7. 验证
[root@master01 ~]# docker --version
[root@master01 ~]# docker run hello-world

通过查询docker版本和运行容器hello-world来验证docker是否安装成功。
8. 修改Cgroup Driver
8.1 修改daemon.json
修改daemon.json,新增‘"exec-opts": ["native.cgroupdriver=systemd"’
[root@master01 ~]# more /etc/docker/daemon.json
{
"registry-mirrors": ["https://v16stybc.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"]
}
8.2 重新加载docker
[root@master01 ~]# systemctl daemon-reload
[root@master01 ~]# systemctl restart docker
修改cgroupdriver是为了消除告警:
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
五、keepalived安装
control plane节点都执行本部分操作。
1. 安装keepalived
[root@master01 ~]# yum -y install keepalived
2. keepalived配置
master01上keepalived配置:
[root@master01 ~]# more /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id master01
}
vrrp_instance VI_1 {
state MASTER
interface ens160
virtual_router_id 50
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.27.34.130
}
}
master02上keepalived配置:
[root@master02 ~]# more /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id master02
}
vrrp_instance VI_1 {
state BACKUP
interface ens160
virtual_router_id 50
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.27.34.130
}
}
master03上keepalived配置:
[root@master03 ~]# more /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id master03
}
vrrp_instance VI_1 {
state BACKUP
interface ens160
virtual_router_id 50
priority 80
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.27.34.130
}
3. 启动keepalived
所有control plane启动keepalived服务并设置开机启动
[root@master01 ~]# service keepalived start
[root@master01 ~]# systemctl enable keepalived
4. VIP查看
[root@master01 ~]# ip a
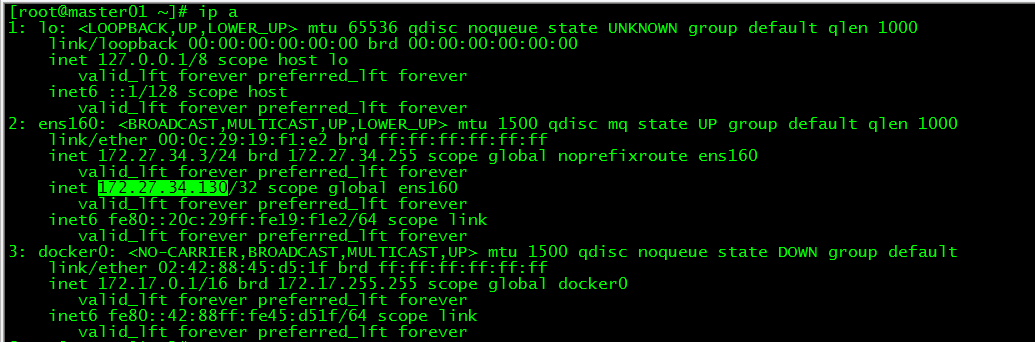
vip在master01上
六、k8s安装
control plane和work节点都执行本部分操作。
1. 版本查看
[root@master01 ~]# yum list kubelet --showduplicates | sort -r

本文安装的kubelet版本是1.16.4,该版本支持的docker版本为1.13.1, 17.03, 17.06, 17.09, 18.06, 18.09。
2. 安装kubelet、kubeadm和kubectl
2.1 安装三个包
[root@master01 ~]# yum install -y kubelet-1.16.4 kubeadm-1.16.4 kubectl-1.16.4
2.2 安装包说明
- kubelet 运行在集群所有节点上,用于启动Pod和容器等对象的工具
- kubeadm 用于初始化集群,启动集群的命令工具
- kubectl 用于和集群通信的命令行,通过kubectl可以部署和管理应用,查看各种资源,创建、删除和更新各种组件
2.3 启动kubelet
启动kubelet并设置开机启动
[root@master01 ~]# systemctl enable kubelet && systemctl start kubelet
2.4 kubectl命令补全
[root@master01 ~]# echo "source <(kubectl completion bash)" >> ~/.bash_profile
[root@master01 ~]# source .bash_profile
3. 下载镜像
3.1 镜像下载的脚本
Kubernetes几乎所有的安装组件和Docker镜像都放在goolge自己的网站上,直接访问可能会有网络问题,这里的解决办法是从阿里云镜像仓库下载镜像,拉取到本地以后改回默认的镜像tag。本文通过运行image.sh脚本方式拉取镜像。
[root@master01 ~]# more image.sh
#!/bin/bash
url=registry.cn-hangzhou.aliyuncs.com/loong576
version=v1.16.4
images=(`kubeadm config images list --kubernetes-version=$version|awk -F '/' '{print $2}'`)
for imagename in ${images[@]} ; do
docker pull $url/$imagename
docker tag $url/$imagename k8s.gcr.io/$imagename
docker rmi -f $url/$imagename
done
url为阿里云镜像仓库地址,version为安装的kubernetes版本。
3.2 下载镜像
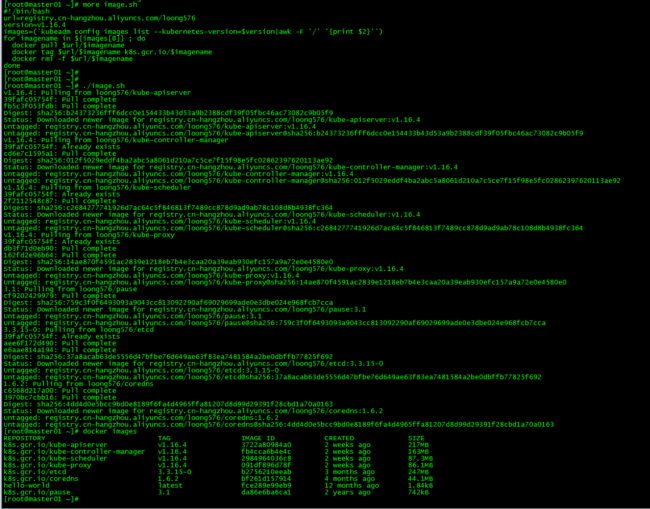
运行脚本image.sh,下载指定版本的镜像
[root@master01 ~]# ./image.sh
[root@master01 ~]# docker images
七、初始化Master
master01节点执行本部分操作。
1. kubeadm.conf
[root@master01 ~]# more kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta2
kind: ClusterConfiguration
kubernetesVersion: v1.16.4
apiServer:
certSANs: #填写所有kube-apiserver节点的hostname、IP、VIP
- master01
- master02
- master03
- node01
- node02
- node03
- 172.27.34.3
- 172.27.34.4
- 172.27.34.5
- 172.27.34.93
- 172.27.34.94
- 172.27.34.95
- 172.27.34.130
controlPlaneEndpoint: "172.27.34.130:6443"
networking:
podSubnet: "10.244.0.0/16"
kubeadm.conf为初始化的配置文件
2. master初始化
[root@master01 ~]# kubeadm init --config=kubeadm-config.yaml
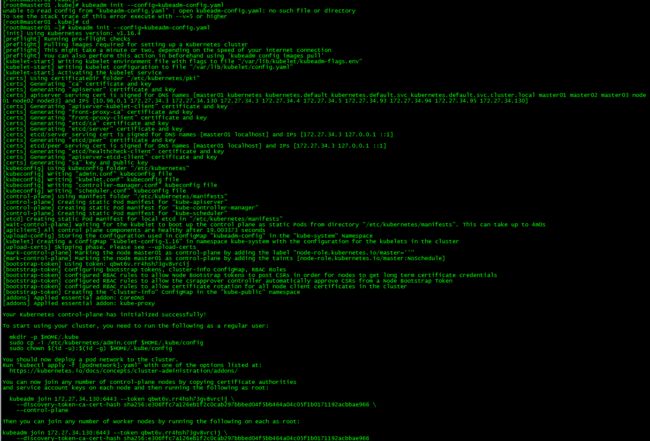
记录kubeadm join的输出,后面需要这个命令将work节点和其他control plane节点加入集群中。
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join 172.27.34.130:6443 --token qbwt6v.rr4hsh73gv8vrcij \
--discovery-token-ca-cert-hash sha256:e306ffc7a126eb1f2c0cab297bbbed04f5bb464a04c05f1b0171192acbbae966 \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 172.27.34.130:6443 --token qbwt6v.rr4hsh73gv8vrcij \
--discovery-token-ca-cert-hash sha256:e306ffc7a126eb1f2c0cab297bbbed04f5bb464a04c05f1b0171192acbbae966
初始化失败:
如果初始化失败,可执行kubeadm reset后重新初始化
[root@master01 ~]# kubeadm reset
[root@master01 ~]# rm -rf $HOME/.kube/config
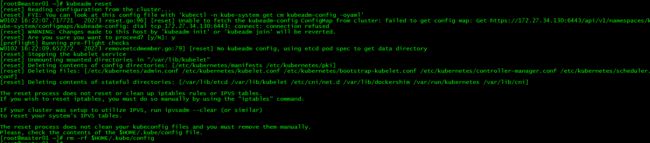
3. 加载环境变量
[root@master01 ~]# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
[root@master01 ~]# source .bash_profile
本文所有操作都在root用户下执行,若为非root用户,则执行如下操作:
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
4. 安装flannel网络
在master01上新建flannel网络
[root@master01 ~]# kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/2140ac876ef134e0ed5af15c65e414cf26827915/Documentation/kube-flannel.yml

由于网络原因,可能会安装失败,可以在文末直接下载kube-flannel.yml文件,然后再执行apply
八、control plane节点加入集群
1. 证书分发
master01分发证书:
在master01上运行脚本cert-main-master.sh,将证书分发至master02和master03
[root@master01 ~]# ll|grep cert-main-master.sh
-rwxr--r-- 1 root root 638 1月 2 15:23 cert-main-master.sh
[root@master01 ~]# more cert-main-master.sh
USER=root # customizable
CONTROL_PLANE_IPS="172.27.34.4 172.27.34.5"
for host in ${CONTROL_PLANE_IPS}; do
scp /etc/kubernetes/pki/ca.crt "${USER}"@$host:
scp /etc/kubernetes/pki/ca.key "${USER}"@$host:
scp /etc/kubernetes/pki/sa.key "${USER}"@$host:
scp /etc/kubernetes/pki/sa.pub "${USER}"@$host:
scp /etc/kubernetes/pki/front-proxy-ca.crt "${USER}"@$host:
scp /etc/kubernetes/pki/front-proxy-ca.key "${USER}"@$host:
scp /etc/kubernetes/pki/etcd/ca.crt "${USER}"@$host:etcd-ca.crt
# Quote this line if you are using external etcd
scp /etc/kubernetes/pki/etcd/ca.key "${USER}"@$host:etcd-ca.key
done

master02移动证书至指定目录:
在master02上运行脚本cert-other-master.sh,将证书移至指定目录
[root@master02 ~]# pwd
/root
[root@master02 ~]# ll|grep cert-other-master.sh
-rwxr--r-- 1 root root 484 1月 2 15:29 cert-other-master.sh
[root@master02 ~]# more cert-other-master.sh
USER=root # customizable
mkdir -p /etc/kubernetes/pki/etcd
mv /${USER}/ca.crt /etc/kubernetes/pki/
mv /${USER}/ca.key /etc/kubernetes/pki/
mv /${USER}/sa.pub /etc/kubernetes/pki/
mv /${USER}/sa.key /etc/kubernetes/pki/
mv /${USER}/front-proxy-ca.crt /etc/kubernetes/pki/
mv /${USER}/front-proxy-ca.key /etc/kubernetes/pki/
mv /${USER}/etcd-ca.crt /etc/kubernetes/pki/etcd/ca.crt
# Quote this line if you are using external etcd
mv /${USER}/etcd-ca.key /etc/kubernetes/pki/etcd/ca.key
[root@master02 ~]# ./cert-other-master.sh
master03移动证书至指定目录:
在master03上也运行脚本cert-other-master.sh
[root@master03 ~]# pwd
/root
[root@master03 ~]# ll|grep cert-other-master.sh
-rwxr--r-- 1 root root 484 1月 2 15:31 cert-other-master.sh
[root@master03 ~]# ./cert-other-master.sh
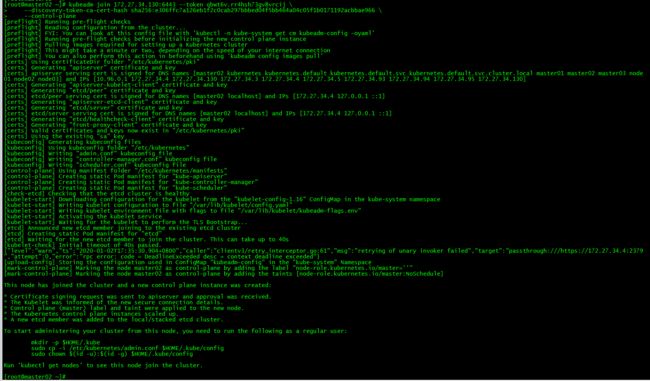
2. master02加入集群
kubeadm join 172.27.34.130:6443 --token qbwt6v.rr4hsh73gv8vrcij \
--discovery-token-ca-cert-hash sha256:e306ffc7a126eb1f2c0cab297bbbed04f5bb464a04c05f1b0171192acbbae966 \
--control-plane
运行初始化master生成的control plane节点加入集群的命令
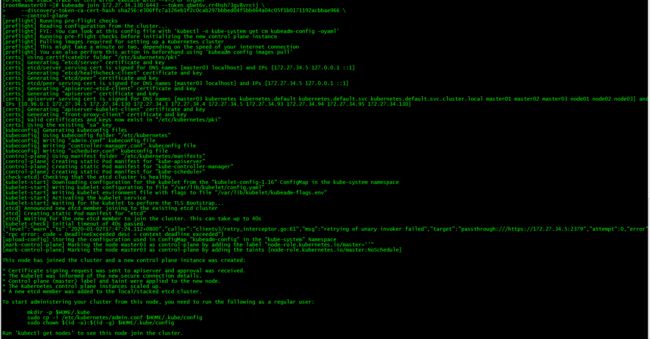
3. master03加入集群
kubeadm join 172.27.34.130:6443 --token qbwt6v.rr4hsh73gv8vrcij \
--discovery-token-ca-cert-hash sha256:e306ffc7a126eb1f2c0cab297bbbed04f5bb464a04c05f1b0171192acbbae966 \
--control-plane
4. 加载环境变量
master02和master03加载环境变量
[root@master02 ~]# scp master01:/etc/kubernetes/admin.conf /etc/kubernetes/
[root@master02 ~]# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
[root@master02 ~]# source .bash_profile
[root@master03 ~]# scp master01:/etc/kubernetes/admin.conf /etc/kubernetes/
[root@master03 ~]# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
[root@master03 ~]# source .bash_profile
该步操作是为了在master02和master03上也能执行kubectl命令。
5. 集群节点查看
[root@master01 ~]# kubectl get nodes
[root@master01 ~]# kubectl get po -o wide -n kube-system

所有control plane节点处于ready状态,所有的系统组件也正常。
九、work节点加入集群
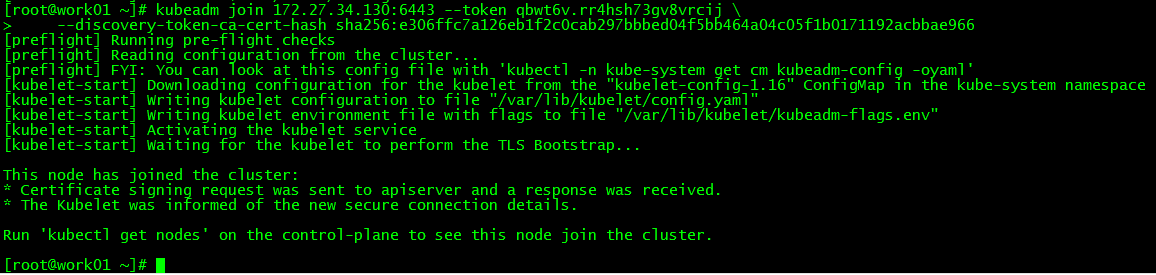
1. work01加入集群
kubeadm join 172.27.34.130:6443 --token qbwt6v.rr4hsh73gv8vrcij \
--discovery-token-ca-cert-hash sha256:e306ffc7a126eb1f2c0cab297bbbed04f5bb464a04c05f1b0171192acbbae966
运行初始化master生成的work节点加入集群的命令
2. work02加入集群
3. work03加入集群
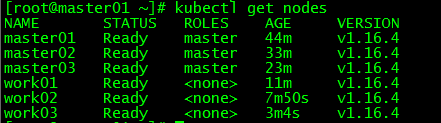
4. 集群节点查看
[root@master01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master01 Ready master 44m v1.16.4
master02 Ready master 33m v1.16.4
master03 Ready master 23m v1.16.4
work01 Ready 11m v1.16.4
work02 Ready 7m50s v1.16.4
work03 Ready 3m4s v1.16.4
十、client配置
1. 设置kubernetes源
1.1 新增kubernetes源
[root@client ~]# cat < /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF

1.2 更新缓存
[root@client ~]# yum clean all
[root@client ~]# yum -y makecache
2. 安装kubectl
[root@client ~]# yum install -y kubectl-1.16.4

安装版本与集群版本保持一致
3. 命令补全
3.1 安装bash-completion
[root@client ~]# yum -y install bash-completion
3.2 加载bash-completion
[root@client ~]# source /etc/profile.d/bash_completion.sh

3.3 拷贝admin.conf
[root@client ~]# mkdir -p /etc/kubernetes
[root@client ~]# scp 172.27.34.3:/etc/kubernetes/admin.conf /etc/kubernetes/
[root@client ~]# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
[root@client ~]# source .bash_profile

3.4 加载环境变量
[root@master01 ~]# echo "source <(kubectl completion bash)" >> ~/.bash_profile
[root@master01 ~]# source .bash_profile
4. kubectl测试
[root@client ~]# kubectl get nodes
[root@client ~]# kubectl get cs
[root@client ~]# kubectl get po -o wide -n kube-system

十一、Dashboard搭建
本节内容都在client端完成
1. 下载yaml
[root@client ~]# wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0-beta8/aio/deploy/recommended.yaml
如果连接超时,可以多试几次。recommended.yaml已上传,也可以在文末下载。
2. 配置yaml
2.1 修改镜像地址
[root@client ~]# sed -i 's/kubernetesui/registry.cn-hangzhou.aliyuncs.com\/loong576/g' recommended.yaml
由于默认的镜像仓库网络访问不通,故改成阿里镜像
2.2 外网访问
[root@client ~]# sed -i '/targetPort: 8443/a\ \ \ \ \ \ nodePort: 30001\n\ \ type: NodePort' recommended.yaml
配置NodePort,外部通过https://NodeIp:NodePort 访问Dashboard,此时端口为30001
2.3 新增管理员帐号
[root@client ~]# cat >> recommended.yaml << EOF
---
# ------------------- dashboard-admin ------------------- #
apiVersion: v1
kind: ServiceAccount
metadata:
name: dashboard-admin
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: dashboard-admin
subjects:
- kind: ServiceAccount
name: dashboard-admin
namespace: kubernetes-dashboard
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
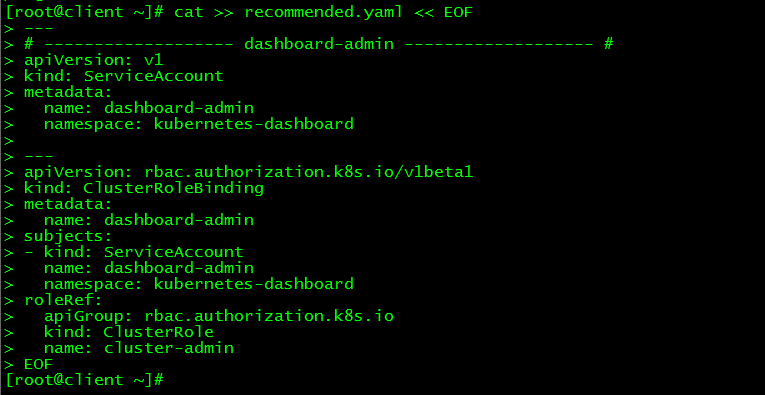
创建超级管理员的账号用于登录Dashboard
3. 部署访问
3.1 部署Dashboard
[root@client ~]# kubectl apply -f recommended.yaml
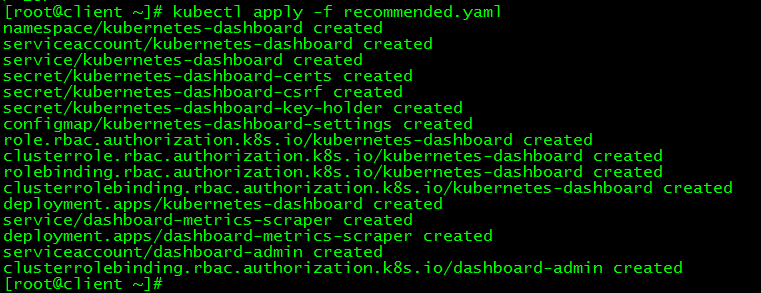
3.2 状态查看
[root@client ~]# kubectl get all -n kubernetes-dashboard

3.3 令牌查看
[root@client ~]# kubectl describe secrets -n kubernetes-dashboard dashboard-admin

令牌为:
eyJhbGciOiJSUzI1NiIsImtpZCI6Ikd0NHZ5X3RHZW5pNDR6WEdldmlQUWlFM3IxbGM3aEIwWW1IRUdZU1ZKdWMifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtYWRtaW4tdG9rZW4tNms1ZjYiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGFzaGJvYXJkLWFkbWluIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiZjk1NDE0ODEtMTUyZS00YWUxLTg2OGUtN2JmMWU5NTg3MzNjIiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmVybmV0ZXMtZGFzaGJvYXJkOmRhc2hib2FyZC1hZG1pbiJ9.LAe7N8Q6XR3d0W8w-r3ylOKOQHyMg5UDfGOdUkko_tqzUKUtxWQHRBQkowGYg9wDn-nU9E-rkdV9coPnsnEGjRSekWLIDkSVBPcjvEd0CVRxLcRxP6AaysRescHz689rfoujyVhB4JUfw1RFp085g7yiLbaoLP6kWZjpxtUhFu-MKh1NOp7w4rT66oFKFR-_5UbU3FoetAFBmHuZ935i5afs8WbNzIkM6u9YDIztMY3RYLm9Zs4KxgpAmqUmBSlXFZNW2qg6hxBqDijW_1bc0V7qJNt_GXzPs2Jm1trZR6UU1C2NAJVmYBu9dcHYtTCgxxkWKwR0Qd2bApEUIJ5Wug
3.4 访问
请使用火狐浏览器访问:https://VIP:30001

接受风险
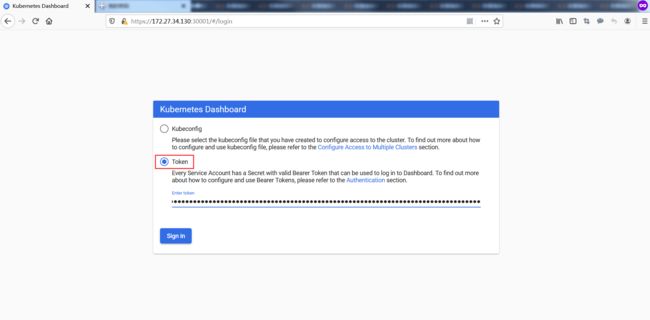
通过令牌方式登录

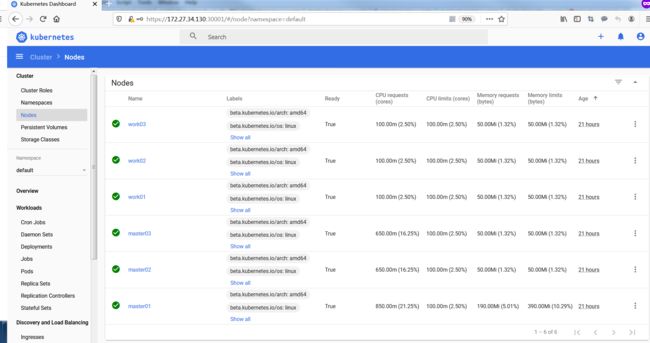
Dashboard提供了可以实现集群管理、工作负载、服务发现和负载均衡、存储、字典配置、日志视图等功能。
十二、集群高可用测试
本节内容都在client端完成
1. 组件所在节点查看
通过ip查看apiserver所在节点,通过leader-elect查看scheduler和controller-manager所在节点:
[root@master01 ~]# ip a|grep 130
inet 172.27.34.130/32 scope global ens160
[root@client ~]# kubectl get endpoints kube-controller-manager -n kube-system -o yaml |grep holderIdentity
control-plane.alpha.kubernetes.io/leader: '{"holderIdentity":"master01_6caf8003-052f-451d-8dce-4516825213ad","leaseDurationSeconds":15,"acquireTime":"2020-01-02T09:36:23Z","renewTime":"2020-01-03T07:57:55Z","leaderTransitions":2}'
[root@client ~]# kubectl get endpoints kube-scheduler -n kube-system -o yaml |grep holderIdentity
control-plane.alpha.kubernetes.io/leader: '{"holderIdentity":"master01_720d65f9-e425-4058-95d7-e5478ac951f7","leaseDurationSeconds":15,"acquireTime":"2020-01-02T09:36:20Z","renewTime":"2020-01-03T07:58:03Z","leaderTransitions":2}'
| 组件名 | 所在节点 |
|---|---|
| apiserver | master01 |
| controller-manager | master01 |
| scheduler | master01 |
2. master01关机
2.1 关闭master01,模拟宕机
[root@master01 ~]# init 0
2.2 各组件查看
vip飘到了master02
[root@master02 ~]# ip a|grep 130
inet 172.27.34.130/32 scope global ens160
controller-manager和scheduler也发生了迁移
[root@client ~]# kubectl get endpoints kube-controller-manager -n kube-system -o yaml |grep holderIdentity
control-plane.alpha.kubernetes.io/leader: '{"holderIdentity":"master02_b3353e8f-a02f-4322-bf17-2f596cd25ba5","leaseDurationSeconds":15,"acquireTime":"2020-01-03T08:04:42Z","renewTime":"2020-01-03T08:06:36Z","leaderTransitions":3}'
[root@client ~]# kubectl get endpoints kube-scheduler -n kube-system -o yaml |grep holderIdentity
control-plane.alpha.kubernetes.io/leader: '{"holderIdentity":"master03_e0a2ec66-c415-44ae-871c-18c73258dc8f","leaseDurationSeconds":15,"acquireTime":"2020-01-03T08:04:56Z","renewTime":"2020-01-03T08:06:45Z","leaderTransitions":3}'
| 组件名 | 所在节点 |
|---|---|
| apiserver | master02 |
| controller-manager | master02 |
| scheduler | master03 |
2.3 集群功能性测试
查询:
[root@client ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master01 NotReady master 22h v1.16.4
master02 Ready master 22h v1.16.4
master03 Ready master 22h v1.16.4
work01 Ready 22h v1.16.4
work02 Ready 22h v1.16.4
work03 Ready 22h v1.16.4
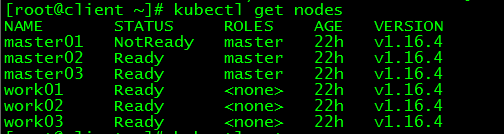
master01状态为NotReady
新建pod:
[root@client ~]# more nginx-master.yaml
apiVersion: apps/v1 #描述文件遵循extensions/v1beta1版本的Kubernetes API
kind: Deployment #创建资源类型为Deployment
metadata: #该资源元数据
name: nginx-master #Deployment名称
spec: #Deployment的规格说明
selector:
matchLabels:
app: nginx
replicas: 3 #指定副本数为3
template: #定义Pod的模板
metadata: #定义Pod的元数据
labels: #定义label(标签)
app: nginx #label的key和value分别为app和nginx
spec: #Pod的规格说明
containers:
- name: nginx #容器的名称
image: nginx:latest #创建容器所使用的镜像
[root@client ~]# kubectl apply -f nginx-master.yaml
deployment.apps/nginx-master created
[root@client ~]# kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-master-75b7bfdb6b-lnsfh 1/1 Running 0 4m44s 10.244.5.6 work03
nginx-master-75b7bfdb6b-vxfg7 1/1 Running 0 4m44s 10.244.3.3 work01
nginx-master-75b7bfdb6b-wt9kc 1/1 Running 0 4m44s 10.244.4.5 work02

2.4 结论
当有一个control plane节点宕机时,VIP会发生漂移,集群各项功能不受影响。
3. master02关机
在关闭master01的同时关闭master02,测试集群还能否正常对外服务。
3.1 关闭master02:
[root@master02 ~]# init 0
3.2 查看VIP:
[root@master03 ~]# ip a|grep 130
inet 172.27.34.130/32 scope global ens160
vip漂移至唯一的control plane:master03
3.3 集群功能测试
[root@client ~]# kubectl get nodes
Error from server: etcdserver: request timed out
[root@client ~]# kubectl get nodes
The connection to the server 172.27.34.130:6443 was refused - did you specify the right host or port?
etcd集群崩溃,整个k8s集群也不能正常对外服务。
本文所有脚本和配置文件已上传:Centos7.6-install-k8s-v1.16.4-HA-cluster