一、思博伦C100测试仪
1.简介:
Spirent C100能够生成超过80Gbps的真实应用流量,以及9000万个并发TCP连接。
在移动性测试中,Spirent C100可仿真数以百万计的用户,且所有用户均具备真实的忙碌时段呼叫/数据模型,并将应用流量与复杂的2G/3G/LTE和Wi-Fi移动性场景结合在了一起。
在安全性应用性能方面,该解决方案可真实地仿真数千种漏洞和攻击,以及数千个IPsec隧道和多万兆的加密流量,从而可准确地确定智能电话应用对网络造成的影响,以及威胁是否会影响加密商业服务;
2.用途:
1、WEB服务器的性能测试:新建,并发,吞吐和响应时间等
2、网络设备的测试:新建,并发,吞吐等
3.需要测什么?
对于流量采集设备一般需要从三个方面去测试:新建,并发,吞吐,且测试时一般才用最常用的HTTP协议进行测试。验证设备最大的处理能力
新建数:不丢帧的情况下,设备每秒建立连接的最大能力
并发数:不丢帧的情况下,设备并发处理连接的最大能力
吞吐量:不丢帧的情况下,设备能处理的数据的最大速率
二、LINUX与性能监测相关的命令:
1.TOP:Top命令显示了实际CPU使用情况,默认情况下,它显示了服务器上占用CPU的任务信息并且每5秒钟刷新一次。你可以通过多种方式分类它们,包括PID、时间和内存使用情况。

PID:进程标识
USER;进程所有者的用户名
PRI:进程的优先级
NI:nice级别
SIZE:进程占用的内存数量(代码+数据+堆栈)
RSS;进程使用的物理内存数量
SHARE;该进程和其他进程共享内存的数量
STAT:进程的状态:S=休眠状态,R=运行状态,T=停止状态,D=中断休眠状态,Z=僵尸状态
%CPU:共享的CPU使用
%MEM;共享的物理内存
TIME:进程占用CPU的时间
COMMAND:启动任务的命令行(包括参数)
2.uptime
Uptime命令的显示结果包括服务器已经运行了多长时间,有多少登陆用户和对服务器性能的总体评估(load average)。load average值分别记录了上个1分钟,5分钟和15分钟间隔的负载情况,load average不是一个百分比,而是在队列中等待执行的进程的数量。如果进程要求CPU时间被阻塞(意味着CPU没有时间处理它),load average值将增加。另一方面,如果每个进程都可以立刻得到访问CPU的时间,这个值将减少。
UP kernel下的load average的最佳值是1,这说明每个进程都可以立刻被CPU处理,当然,更低不会有问题,只说明浪费了一部分的资源。但在不同的系统间这个值也是不同的,而在一个多CPU的系统中这个值应除以物理CPU的个数;
你可以使用uptime判断一个性能问题是出现在服务器上还是网络上。例如,如果一个网络应用运行性能不理想,运行uptime检查系统负载是否比较高,如果不是这个问题更可能出现在你的网络上。
3.iostat
iostat是sysstat包的一部分。Iostat显示自系统启动后的平均CPU时间(与uptime类似),它也可以显示磁盘子系统的使用情况,iostat可以用来监测CPU利用率和磁盘利用率。
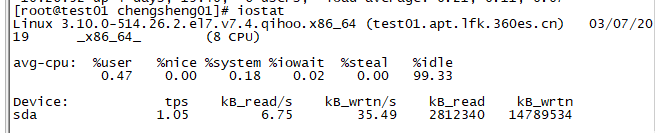
CPU利用率分四个部分:
%user:user level(应用)的CPU占用率情况
%nice:加入nice优先级的user level的CPU占用率情况
%sys:system level(内核)的CPU占用情况
%idle:空闲的CPU资源情况
磁盘占用率有下面几个部分:
Device:块设备名
Tps:设备每秒进行传输的数量(每秒的I/O请求)。多个单独的I/O请求可以被组成一个传输操作,因为一个传输操作可以是不同的容量。
Blk_read/s, Blk_wrtn/s:该设备每秒读写的块的数量。块可能为不同的容量。
Blk_read, Blk_wrtn:自系统启动以来读写的块设备的总量。
4.Vmstat
Vmstat命令提供了对进程、内存、页面I/O块和CPU等信息的监控,vmstat可以显示检测结果的平均值或者取样值,取样模式可以提供一个取样时间段内不同频率的监测结果。
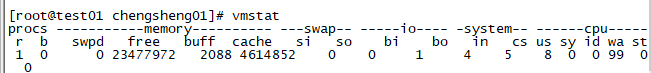
注:在取样模式中需要考虑在数据收集中可能出现的误差,将取样频率设为比较低的值可以尽可能的减小误差的影响。
下面介绍一下各列的含义
·process(procs)
r:等待运行时间的进程数量
b:处在不可中断睡眠状态的进程
w:被交换出去但是仍然可以运行的进程,这个值是计算出来的
·memoryswpd:虚拟内存的数量
free:空闲内存的数量
buff:用做缓冲区的内存数量
·swap
si:从硬盘交换来的数量
so:交换到硬盘去的数量
·IO
bi:向一个块设备输出的块数量
bo:从一个块设备接受的块数量
·system
in:每秒发生的中断数量, 包括时钟
cs:每秒发生的context switches的数量
·cpu(整个cpu运行时间的百分比)
us:非内核代码运行的时间(用户时间,包括nice时间)
sy:内核代码运行的时间(系统时间)
id:空闲时间,在Linux 2.5.41之前的内核版本中,这个值包括I/O等待时间;
wa:等待I/O操作的时间,在Linux 2.5.41之前的内核版本中这个值为0
Vmstat命令提供了大量的附加参数,下面列举几个十分有用的参数:
·m:显示内核的内存利用率
·a:显示内存页面信息,包括活跃和不活跃的内存页面
·n:显示报头行,这个参数在使用取样模式并将命令结果输出到一个文件时非常有用。例如root#vmstat –n 2 10以2秒的频率显示10输出结果
·当使用-p {分区}时,vmstat提供对I/O结果的统计
5.ps和pstree
ps和pstree命令是系统分析最常用的基本命令,ps命令提供了一个正在运行的进程的列表,列出进程的数量取决于命令所附加的参数。例如ps –A 命令列出所有进程和它们相应的进程ID(PID),进程的PID是使用其他一些工具之前所必须了解的,例如pmap或者renice。
在运行java应用的系统上,ps –A 命令的输出很容易就会超过屏幕的显示范围,这样就很难得到所有进程的完整信息。这时,使用pstree命令可以以树状结构来显示所有的进程信息并且可以整合子进程的信息。Pstree命令对分析进程的来源十分有用。
6、free
free命令显示系统的所有内存的使用情况,包括空闲内存、被使用的内存和交换内存空间。Free命令显示也包括一些内核使用的缓存和缓冲区的信息。
当使用free命令的时候,需要记住linux的内存结构和虚拟内存的管理方法,比如空闲内存数量的限制,还有swap空间的使用并不标志一个内存瓶颈的出现。

Free命令有用的参数:
引用
·-b,-k,-m和-g分别按照bytes, kilobytes, megabytes, gigabytes显示结果。
·-l区别显示low和high内存
·-c {count}显示free输出的次数
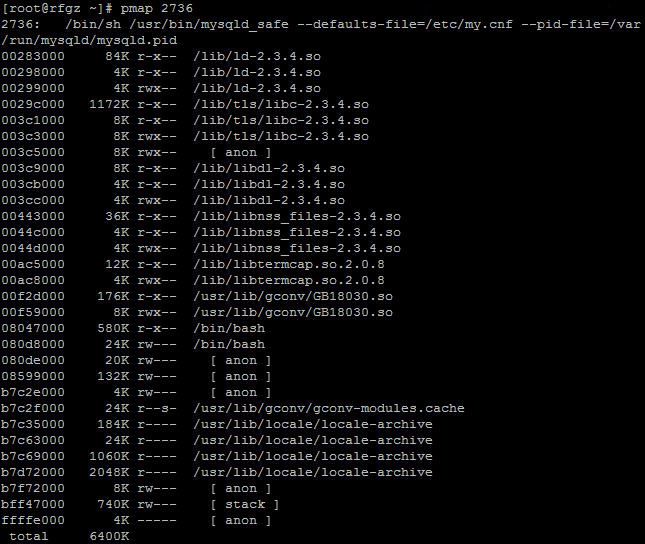
7、Pmap
pmap命令显示一个或者多个进程使用内存的数量,你可以用这个工具来确定服务器上哪个进程占用了过多的内存从而导致内存瓶颈。
8.netstat:该命令是一个监控TCP/IP网络的非常有用的工具,它可以显示路由表、实际的网络连接以及每一个网络接口设备的状态信息。
9.iptraf:监控网络流量‘