资料汇总:
偏向理论原理 方面
https://www.cnblogs.com/lit10050528/p/12178822.html
https://www.cnblogs.com/Ace-suiyuan008/p/9958331.html
https://blog.csdn.net/weixin_42633131/article/details/82873731
https://zhuanlan.zhihu.com/p/109578675
http://www.ruanyifeng.com/blog/2017/08/elasticsearch.html
Es 是一个专门做搜索的数据库系统
Elasticsearch是一个基于Lucene的搜索服务器
4.4 Lucene、Solr、Elasticsearch关系
Lucene:底层的API,工具包
Lucene资料
Solr:基于Lucene开发的企业级的搜索引擎产品
Elasticsearch:基于Lucene开发的企业级的搜索引擎产品
Solr 和Elasticsearch 是并列的两种产品。
全文检索:
计算机索引程序通过扫描文章中国呢的每一个词,对每一个词建立一个索引,并指明该词在文章中出现的位置和次数,当用户查询时,检测程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式 。
lucene 全文检索就是对文档的全部内容进行分词,然后对所有的单词建立倒排索引的过程。
kibana 是es 客户端
Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。使用Kibana,可以通过各种图表进行高级数据分析及展示。
Kibana让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板(dashboard)实时显示Elasticsearch查询动态。

- INDEX
Elastic 会索引所有字段,经过处理后写入一个反向索引(Inverted Index)。查找数据的时候,直接查找该索引。
所以,Elastic 数据管理的顶层单位就叫做 Index(索引)。它是单个数据库的同义词。每个 Index (即数据库)的名字必须是小写。
-
Document
Index 里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。
Document 使用 JSON 格式表示,下面是一个例子。
 image.png
image.png Type
Document 可以分组,比如weather这个 Index 里面,可以按城市分组(北京和上海),也可以按气候分组(晴天和雨天)。这种分组就叫做 Type,它是虚拟的逻辑分组,用来过滤 Document。
Elastic 6.x 版只允许每个 Index 包含一个 Type,7.x 版将会彻底移除 Type
类型(Type)
在 7.0 之前,每一个索引是可以设置多个 Types 的,每个 Type 会拥有相同结构的文档,但是在 6.0 开始,Type 已经被废除,在 7.0 开始,一个索引只能创建一个 Type,也就是 _doc
安装es 和kibana
参考资料
es 数据库语法 (在kibana 客户端的操作 )
参考资料1
参考资料2
参考资料3
在这个之前需要再一次重新赘述一遍,
index 相当于是数据库;
文档 相当于是一行数据;
- 建立index
PUT /wangyd/
{
"settings":{
"index":{
"number_of_shards": 3,
"number_of_replicas": 0
}
}
"number_of_shards": 分片数
"number_of_replicas": 被分数
wangyd是创建的索引名
也可以使用默认配置
put wangyd
# 或者 put /wangyd/
结果执行后为:

注意在7.0之后可以直接创建并添加文档 ,用post
因为7版本之后,ES不再支持一个索引(index)可以创建多个类型(type),所以cmcc/后边不再需要写入类型名称,而是统一使用_create代替即可,同样的,查询操作使用_doc代替即可,右侧看到如下图所示类似形式表示创建成功

- 删除index
delete wangyd
# 或者delete /wangyd/
- 查看index 配置
GET /wangyd/_settings
- 增加文档
put /lib/user/1
{
"first_name":"Jane",
"last_name":"Smith",
"age":32,
"about":"I like to collect rock albums",
"interests":["music"]
user为该文档的类型
1是该文档的id
也可不指定id,但需要使用post命令,id会自动生成 [!!!!!!!!!!]
post /lib/user
{
"first_name":"zhou",
"last_name":"Lucky",
"age":18,
"about":"I like to collect rock albums",
"interests":["music"]
- 更新文档
1.直接覆盖
PUT /lib/user/1
{
"first_name" : "Jane",
"last_name" : "Smith",
"age" : 36,
"about" : "I like to collect rock albums",
"interests": [ "music" ]
}
2.只更新需要更新的字段(post)
POST /lib/user/1/_update
{
"doc":{
"age":33
}
- 查询
- 按照条件查询

-
1 或 逻辑(should)
 image.png
image.png -
2 并逻辑 (must)
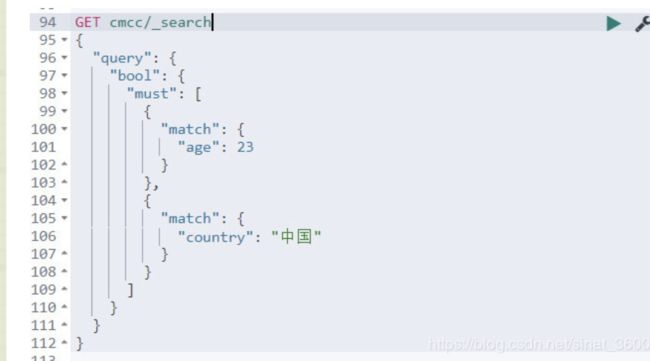 image.png
image.png -
3 范围查询并排序
 image.png
image.png
更多查询方法
https://zhuanlan.zhihu.com/p/46407263
- 6.条件删除文档
post lib/user/_delete_by_query
{
"query": {
"match": { "first_name": "zhou"}
}
利用类, elasticsearch-dsl 进行存储数据
from elasticsearch_dsl import connections
from datetime import datetime
from elasticsearch_dsl import Document, Date, Text,Float,Keyword
connections.create_connection(hosts=['ip:端口'], timeout=60)
class My_class(Document):
index_code = Keyword()
fund_code = Keyword()
fund_cname = Text()
update_time = Date()
class Index:
name = "name_fix-*"
settings = {
"number_of_shards": 2
}
def save(self, **kwargs):
# assign now if no timestamp given
if not self.update_time:
self.update_time = datetime.now()
# override the index to go to the proper timeslot
kwargs['index'] = self.update_time.strftime('name_fix-%Y%m%d')
return super().save(**kwargs)
使用方法 :
- 在index 类中对name 声明,即通过这种方式创建对index 的名称都是name-fix- z作为前缀开始的。在save 的函数中,kwargs['index'] = self.update_time.strftime('name_fix-%Y%m%d')是准确的对index 进行命名。
- 在kibana(es 的客户端)中不需要类似sql 数据库先建表,然后再插入,这里在My_class 中声明几个变量后,可以直接创建并存入。
- 我们在使用中需要对My_class 中的几个变量根据实际进行修改。
问题汇总
空值 处理原则
空值的就不传入进去,参加python 的参数 章节第一次插入数据的时候会自动初始化,在数据库中建立index ,但是有的行会没有数据,就导致建立的mapping 部分是没有相应的字段的 。所以解决方法是,在插入数据之前先进行初始化,建立mapping,然后再去插入值
# 1. create the mappings in elasticsearch
index_suffix = '2020'
index_name = DemoDoc._index._name[:-1] + index_suffix
if not indices_client.exists(index_name):
DemoDoc.init(index=index_name)
# 2. once, as part of application setup, during deploy/migrations:
# template用来查询
template_name = 'strategy-doc-demo'
docTemplate = DemoDoc._index.as_template(template_name)
# 生成indexTemplate
if not indices_client.exists_index_template(template_name):
docTemplate.save()
# 3. 创建DemoDoc文档
doc = DemoDoc(meta={'id': 43}, title='Hello world!', tags=['test'])
doc.body = ''' looong text '''
doc.published_from = datetime.now()
# 4.1 单个保存
doc.save()