本文是基于实现第一阶段的业务目标后,使用数据仓库实现的自主更新可视化看板。
项目目录
- 项目介绍
- 分析思路
- 数据自动化处理过程
- 可视化报表搭建
一、项目介绍
基于已经实现第一阶段的业务需求后,公司希望业务部门能够实现自主分析,从而实现对市场的快速判断,因此,要求数据部门和业务部门沟通需求的自主分析的数据指标,从而实现可视化看板。
二、分析思路
(一)项目操作流程

(二)观察数据
根据业务需求,从mysql数据库中梳理出三张表分析:



(三)数据指标分析

三、数据自动化处理过程
(一)Sqoop抽取mysql数据到hive
将日期维度表,订单明细表,每日新增用户表中的数据抽取到Hive数据库中
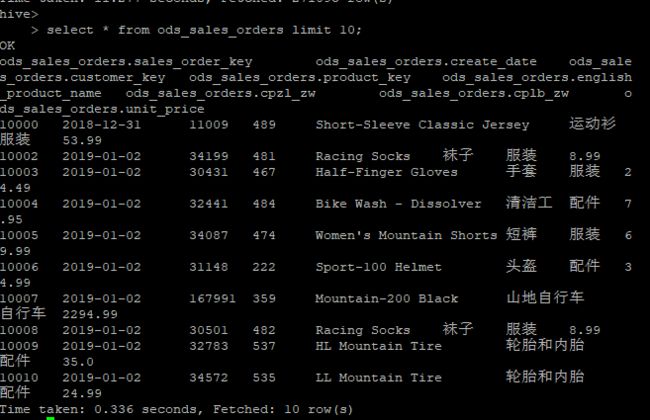
这里是导入订单明细表(ods_sales_orders),这里用订单明细表示范,其余两张表和这个一样。
hive -e "truncate table ods.ods_sales_orders"
sqoop import \
--hive-import \ #import 工具从RDBMS向hive的HDFS导入单独的表
--connect "jdbc:mysql://106.13.128.83:3306/adventure_ods?useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&dontTrackOpenResources=true&defaultFetchSize=50000&useCursorFetch=true" \
--driver com.mysql.jdbc.Driver \ #指定要使用的JDBC驱动程序类
--username frogdataXXXX \#连接mysql的用户名
--password mimaXXXX \#连接mysql的密码
--query \#构建SQL语句执行
"select * from ods_sales_orders where "'$CONDITIONS'" " \
--fetch-size 50000 \#一次从数据库读取50000个实例,就是50000条数据
--hive-table ods.ods_sales_orders \#导入到hive时用表名ods_sales_orders
--hive-drop-import-delims \#在导入数据到hive时,去掉数据中的\r\n\013\010这样的字符
--delete-target-dir \#若目标文件存在就删除他
--target-dir /user/hadoop/sqoop/ods_sales_orders \#目标HDFS目录
-m 1 #迁移过程使用1个map
导入成功后,可以查看一下表中的数据
(二)建立数据仓库,对数据进行聚合
数据聚合的思路
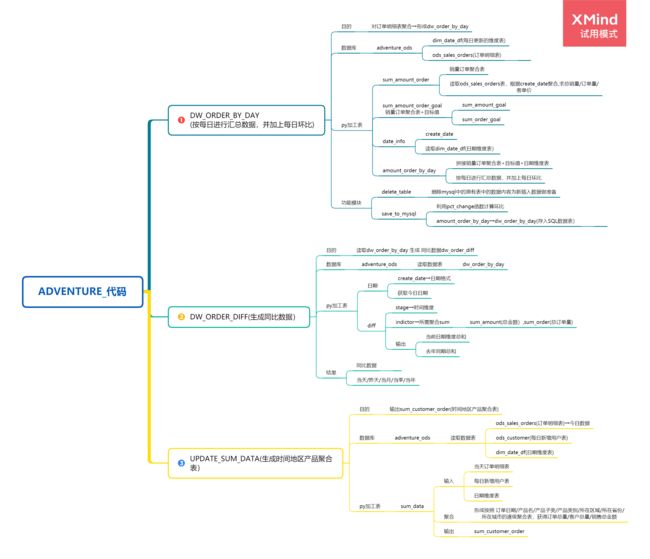
在hive中编写shell脚本,聚合生成dw_order_by_day,dw_amount_diff,dw_customer_order表
以下是dw_order_by_day的聚合,其他两张表步骤是一样的
hive -e "drop table if exists ods.dw_order_by_day"
hive -e "
CREATE TABLE ods.dw_order_by_day(
create_date string,
is_current_year bigint,
is_last_year bigint,
is_yesterday bigint,
is_today bigint,
is_current_month bigint,
is_current_quarter bigint,
sum_amount double,
order_count bigint)
"
hive -e "
with dim_date as
(select create_date,
is_current_year,
is_last_year,
is_yesterday,
is_today,
is_current_month,
is_current_quarter
from ods.dim_date_df),
sum_day as
(select create_date,
sum(unit_price) as sum_amount,
count(customer_key) as order_count
from ods.ods_sales_orders
group by create_date)
insert into ods.dw_order_by_day
select b.create_date,
b.is_current_year,
b.is_last_year,
b.is_yesterday,
b.is_today,
b.is_current_month,
b.is_current_quarter,
a.sum_amount,
a.order_count
from sum_day as a
inner join dim_date as b
on a.create_date=b.create_date
"
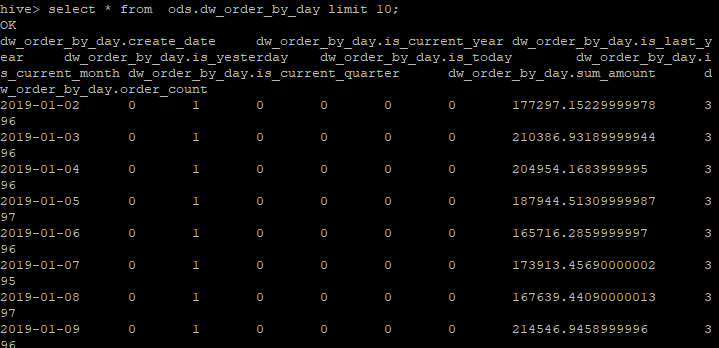
查看聚合后的数据
四、在Linux上做定时部署
把定时更新的任务写到schedule.py上,然后将我们写好的schedule.py文件挂到后台
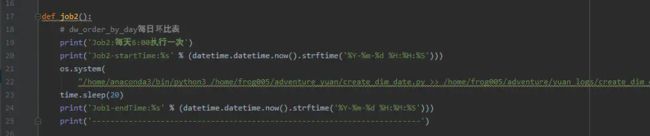
(1)定时更新dw_order_by_day,dw_order_diff,dw_customer_order表的schedule.py文件,导入schedule 模块实现定时更新,设定时间是早上6:00更新 代码如图所示(部分):
(2)定时任务挂到linux服务器后台,等待更新
nohup python3 schedule_job.py > schedule_job.log 2>&1 &
nohup :不挂断地运行命令
2>&1 将错误输出到终端,这里将输出定向到日志文件
& 放在命令到结尾,表示后台运行
(3)验证schedule程序是否顺利挂在后台
ps aux| grep schedule_job.py
五、Sqoop从Hive导出数据到mysql
将数据从Hadoop(如hive等)导入关系型数据库导中
步骤1:Sqoop与数据库Server通信,获取数据库表的元数据信息;
步骤2:并行导入数据:
将Hadoop上文件划分成若干个split;
每个split由一个Map Task进行数据导入
sqoop从hive数据库抽取数据到mysql数据库,这里是将dw_order_by_day的数据抽取到mysql数据库中,其余两张表和它方法相同。
sqoop export \
--connect "jdbc:mysql://域名/adventure_dw?useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&dontTrackOpenResources=true&defaultfetchSize=50000&useCursorfetch=true" \
--username 数据库账号\ ##数据库账号
--password 密码 \##数据库密码
--table dw_order_by_day \ ##mysql数据库建好的表
--export-dir /user/hive/warehouse/ods.db/dw_order_by_day \ #hive数据库数据路径,这个用show create table ods.dw_order_by_day 查hive表的路径
--columns ##抽取的列 create_date,is_current_year,is_last_year,is_yesterday,is_today,is_current_month,is_current_quart,sum_amount,order_count \
--fields-terminated-by '\001' \ ##hive中被导出的文件字段的分隔符```
五、可视化报表搭建
可视化链接
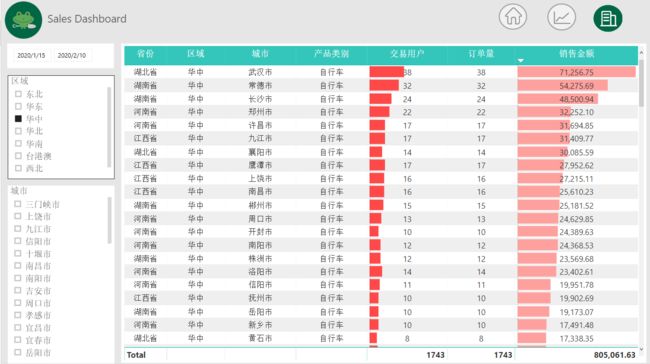
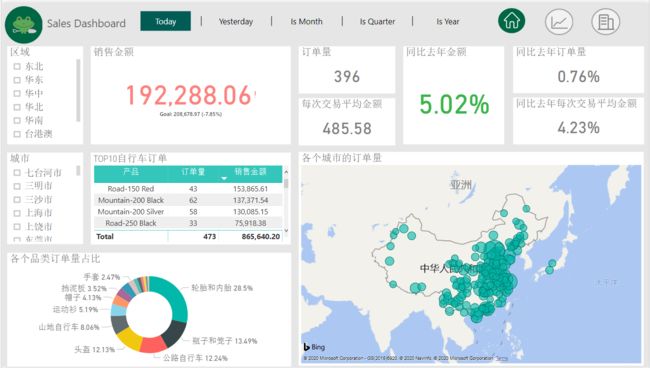
(一)总体销售情况展示
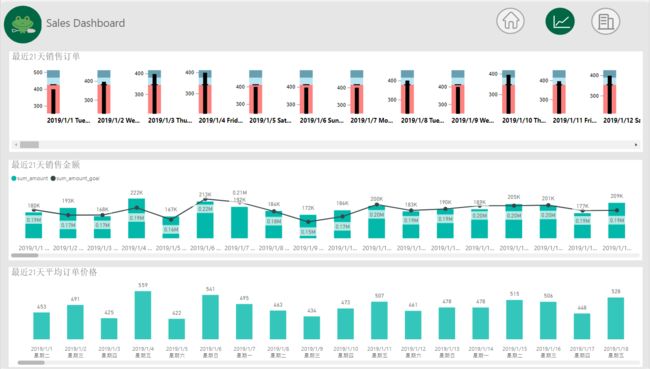
(二)最近21天销售趋势图
(三)区域销售详情图