数据下载地址:链接:https://pan.baidu.com/s/1nwJiu4T 密码:6joq
本文代码地址:https://github.com/princewen/tensorflow_practice/tree/master/myPtrNetwork
1、什么是pointer-network
Pointer Networks 是发表在机器学习顶级会议NIPS 2015上的一篇文章,其作者分别来自Google Brain和UC Berkeley。
Pointer Networks 也是一种seq2seq模型。他在attention mechanism的基础上做了改进,克服了seq2seq模型中“输出严重依赖输入”的问题。
什么是“输出严重依赖输入”呢?
论文里举了个例子,给定一些二维空间中[0,1]*[1,0]范围内的点,求这些点的凸包(convex hull)。凸包是凸优化里的重要概念,含义如下图所示,通俗来讲,即找到几个点能把所有点“包”起来。比如,模型的输入是序列{P1,P2,...,P7},输出序列是凸包{P2,P4,P3,P5,P6,P7,P2}。到这里,“输出严重依赖输入”的意思也就明了了,即输出{P2,P4,P3,P5,P6,P7,P2}是从输入序列{P1,P2,...,P7}中提取出来的。换个输入,如{P1,....,P1000},那么输出序列就是从{P1,....,P1000}里面选出来。用论文中的语言来描述,即{P1,P2,...,P7}和{P1,....,P1000}的凸包,输出分别依赖于输入的长度,两个问题求解的target class不一样,一个是7,另一个是1000。

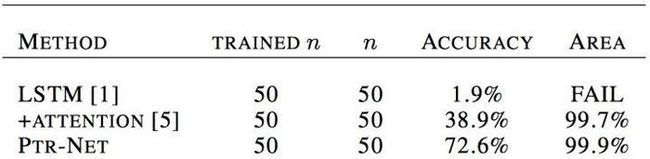
Pointer Network在求凸包上的效果如何呢?
从Accuracy一栏可以看到,Ptr-net明显优于LSTM和LSTM+Attention。
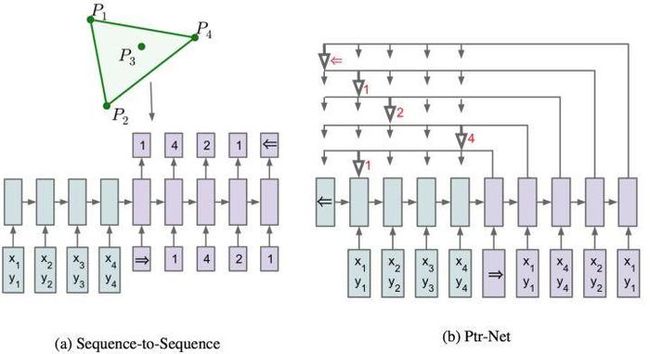
为啥叫pointer network呢?
前面说到,对于凸包的求解,就是从输入序列{P1,....,P1000}中选点的过程。选点的方法就叫pointer,他不像attetion mechanism将输入信息通过encoder整合成context vector,而是将attention转化为一个pointer,来选择原来输入序列中的元素。
与attention的区别:如果你也了解attention的原理,可以看看pointer是如何修改attention的?如果不了解,这一部分就可以跳过了。
首先搬出attention mechanism的公式,前两个公式是整合encoder和decoder的隐式状态,学出来encoder、decoder隐式状态与当前输出的权重关系a,然后根据权重关系a和隐式状态e得到context vector用来预测下一个输出。

Pointer Net没有最后一个公式,即将权重关系a和隐式状态整合为context vector,而是直接进行通过softmax,指向输入序列选择中最有可能是输出的元素。

如果你对上面的理论还没有理解的很到位,那么我们通过代码来进一步讲解,相信你通过这段代码,可以对Ptr的理论有一个更深入的认识。
2、pointer-network实现
这段代码源自:https://github.com/devsisters/pointer-network-tensorflow
上面的代码 实现比较复杂,连下载数据的过程都有,真的是十分费劲,我直接把数据下载好了,上传到百度云上了,大家可以自行下载(地址见文章开头)。
代码目录如下:

config.py 定义了模型的配置
data_util.py 定义了数据处理过程
main.py 模型的主入口,定义了模型的训练过程
model.py 定义了我们的pointer-network模型
我们这里主要讲解我们的数据处理和模型定义两个文件
2.1 数据处理
好了,我们来看看我们的数据吧:

每行是一条数据,由于一条太长,所以分了三行显示。输入和target由output隔开,每个输入的点由两个坐标构成。
我们用下面的代码读入数据,这里,我们把最后一个target的最后一个去掉了,我们认为我们正常的target的输出序列不包含最后一个1,最后一个1作为结束标记在后面的代码里会加入。
def read_paper_dataset(path):
enc_seq , target_seq , enc_seq_length , target_seq_length = [],[],[],[]
tf.logging.info("Read dataset {} which is used in the paper..".format(path))
length = max(re.findall('\d+', path))
with open(path,'r') as f:
for l in tqdm(f):
# 使用output分割数据
inputs, outputs = l.split(' output ')
inputs = np.array(inputs.split(), dtype=np.float32).reshape([-1, 2])
outputs = np.array(outputs.split(), dtype=np.int32)[:-1]
# x分割成横纵坐标两列
enc_seq.append(inputs)
# y要忽略最后一个
target_seq.append(outputs) # skip the last one
enc_seq_length.append(inputs.shape[0])
target_seq_length.append(outputs.shape[0])
return enc_seq,target_seq,enc_seq_length,target_seq_length
由于每条记录的长度可能不同,因此,我们需要把所有数据的长度补成一样的:
def gen_data(path):
x,y,enc_seq_length,target_seq_length = read_paper_dataset(path)
# max_length 是 config的序列的最大长度
enc_seq = np.zeros([len(x), 10, 2], dtype=np.float32)
target_seq = np.zeros([len(y), 10], dtype=np.int32)
# 这里的作用就是将所有的输入都变成同样长度,用0补齐
for idx, (nodes, res) in enumerate(tqdm(zip(x, y))):
enc_seq[idx, :len(nodes)] = nodes
target_seq[idx, :len(res)] = res
return enc_seq,target_seq,enc_seq_length,target_seq_length
2.2 模型建立
在model.py文件中,我们定义了Model类以及两个辅助的函数:
trainable_initial_state :建立可训练的lstm初始状态
index_matrix_to_pairs:这个主要是帮助我们使用gather_nd函数来选择输入的内容,该函数的一个简单处理效果如下:
[[3,1,2], [2,3,1]] -> [[[0, 3], [1, 1], [2, 2]],
[[0, 2], [1, 3], [2, 1]]]
我们这里重点讲解Model类的_build_model函数,该函数用来建立一个pointer-network模型。
定义输入
我们定义了四部分的输入,分别是encoder的输入及长度,decoder的预测序列及长度
self.enc_seq = tf.placeholder(dtype=tf.float32,shape=[self.batch_size,self.max_enc_length,2],name='enc_seq')
self.target_seq = tf.placeholder(dtype=tf.int32,shape=[self.batch_size,self.max_dec_length],name='target_seq')
self.enc_seq_length = tf.placeholder(dtype=tf.int32,shape=[self.batch_size],name='enc_seq_length')
self.target_seq_length = tf.placeholder(dtype=tf.int32,shape=[self.batch_size],name='target_seq_length')
输入处理
我们要对输入进行处理,将输入转换为embedding,embedding的长度和lstm的隐藏神经元个数相同。
这里指的注意的就是 tf.nn.conv1d函数了,这个函数首先会对输入进行一个扩展,然后再调用tf.nn.conv2d进行二维卷积。关于该函数的过程可以看代码中的注释或者看该函数的源代码。
# input_dim 是 2,hidden_dim 是 lstm的隐藏层的数量
input_embed = tf.get_variable(
"input_embed", [1, self.input_dim, self.hidden_dim],
initializer=self.initializer)
# 将 输入转换成embedding,一下是根据源码的转换过程:
# enc_seq :[batch_size,seq_length,2] -> [batch_size,1,seq_length,2],在第一维进行维数扩展
# input_embed : [1,2,256] -> [1,1,2,256] # 在第0维进行维数扩展
# tf.nn.conv1d首先将input和filter进行填充,然后进行二维卷积,因此卷积之后维度为batch * 1 * seq_length * 256
# 卷积的步长是[1,1,第三个参数,1],因此为[1,1,1,1]
# 最后还有一步squeeze的操作,从tensor中删除所有大小是1的维度,所以最后的维数为batch * seq_length * 256
self.embeded_enc_inputs = tf.nn.conv1d(
self.enc_seq, input_embed, 1, "VALID")
在对输入进行处理之后,输入的形状就变为[batch , max_enc_seq_length, hidden_dim]
Encoder
根据配置中的lstm层数,我们建立encoder,同时将我们处理好的输入输入到模型中,得到encoder的输出以及encoder的最终状态。:
with tf.variable_scope("encoder"):
# 构建一个多层的LSTM
self.enc_cell = LSTMCell(
self.hidden_dim,
initializer=self.initializer)
if self.num_layers > 1:
cells = [self.enc_cell] * self.num_layers
self.enc_cell = MultiRNNCell(cells)
self.enc_init_state = trainable_initial_state(
self.batch_size, self.enc_cell.state_size)
# self.encoder_outputs : [batch_size, max_sequence, hidden_dim]
self.enc_outputs, self.enc_final_states = tf.nn.dynamic_rnn(
self.enc_cell, self.embeded_enc_inputs,
self.enc_seq_length, self.enc_init_state)
在得到输出之后,我们要给最前面的输出添加一个开始的输出,同时这个添加的开始的输出还将作为encoder的最开始的输入。看下面的图片:

# 给最开头添加一个结束标记,同时这个标记也将作为decoder的初始输入
# batch_size * 1 * hidden_dim
self.first_decoder_input = tf.expand_dims(trainable_initial_state(
self.batch_size, self.hidden_dim, name="first_decoder_input"), 1)
# batch_size * max_sequence + 1 * hidden_dim
self.enc_outputs = tf.concat(
[self.first_decoder_input, self.enc_outputs], axis=1)
training decoder
与seq2seq不同的是,pointer-network的输入并不是target序列的embedding,而是根据target序列的值选择相应位置的encoder的输出。
我们知道encoder的输出长度在添加了开始输出之后形状为[batch ,max_enc_seq_length + 1]。现在假设我们拿第一条记录进行训练,第一条记录的预测序列是[1,2,4],那么decoder依次的输入是
self.enc_outputs[0][0], self.enc_outputs[0][1],self.enc_outputs[0][2],self.enc_outputs[0][4],那么如何根据target序列来选择encoder的输出呢,这里就要用到我们刚刚定义的index_matrix_to_pairs函数以及gather_nd函数:
self.idx_pairs = index_matrix_to_pairs(self.target_seq)
self.embeded_dec_inputs = tf.stop_gradient(
tf.gather_nd(self.enc_outputs, self.idx_pairs))
#如果使用了结束标记的话,要给encoder的输出拼上开始状态,同时给decoder的输入拼上开始状态
self.embeded_dec_inputs = tf.concat(
[self.first_decoder_input, self.embeded_dec_inputs], axis=1)
由于decoder的输出变成了原先的target序列的长度+1,因此我们要在每个target后面补充一个结束标记,我们补充1作为结束标记:
# 给target最后一维增加结束标记,数据都是从1开始的,所以结束也是回到1,所以结束标记为1
tiled_zero_idxs = tf.tile(tf.zeros(
[1, 1], dtype=tf.int32), [self.batch_size, 1], name="tiled_zero_idxs")
self.add_terminal_target_seq = tf.concat([self.target_seq, tiled_zero_idxs], axis=1)
同样,我们建立一个多层的lstm网络:
# 建立一个多层的lstm网络
self.dec_cell = LSTMCell(
self.hidden_dim,
initializer=self.initializer)
if self.num_layers > 1:
cells = [self.dec_cell] * self.num_layers
self.dec_cell = MultiRNNCell(cells)
# encoder的最后的状态作为decoder的初始状态
dec_state = self.enc_final_states
对于decoder来说,这里我们每次每个batch只输入一个值,然后使用循环来实现整个decoder的过程:
# 预测的序列
self.predict_indexes = []
# 预测的softmax序列,用于计算损失
self.predict_indexes_distribution = []
# 训练self.max_dec_length + 1轮,每一轮输入batch * hiddennum
for j in range(self.max_dec_length + 1):
if j > 0:
tf.get_variable_scope().reuse_variables()
cell_input = tf.squeeze(self.embeded_dec_inputs[:, j, :]) # B * L
output, dec_state = self.dec_cell(cell_input, dec_state) # B * L
# 使用pointer 机制 选择得到softmax的输出,batch * enc_seq + 1
idx_softmax = self.choose_index(self.enc_outputs, output)
# 选择每个batch 最大的id [batch]
idx = tf.argmax(idx_softmax, 1, output_type=dtypes.int32)
# decoder的每个输出的softmax序列
self.predict_indexes_distribution.append(idx_softmax) # D+1 * B * E + 1
# decoder的每个输出的id
self.predict_indexes.append(idx)
self.predict_indexes = tf.convert_to_tensor(self.predict_indexes)
self.predict_indexes_distribution = tf.convert_to_tensor(self.predict_indexes_distribution)
可以看到,我们定义了两个数组来保存输出的序列,以及每次输出的softmax值。这里定义了一个choose_index函数,这个函数的作用即我们的pointer机制,即得到每个decoder输出与encoder输出按如下公式相互作用的softmax数组:

在论文中还提到一个词叫做glimpse function,他首先将上面式子中的q进行了处理,公式如下:

glimpse function可以实现多层,当然我们代码里只有一层:

def attention(self,ref, query, with_softmax, scope="attention"):
"""
:param ref: encoder的输出
:param query: decoder的输出
:param with_softmax:
:param scope:
:return:
"""
with tf.variable_scope(scope):
W_1 = tf.get_variable("W_e", [self.hidden_dim, self.attention_dim], initializer=self.initializer) # L x A
W_2 = tf.get_variable("W_d", [self.hidden_dim, self.attention_dim], initializer=self.initializer) # L * A
dec_portion = tf.matmul(query, W_2)
scores = [] # S * B
v_blend = tf.get_variable("v_blend", [self.attention_dim, 1], initializer=self.initializer) # A x 1
bais_blend = tf.get_variable("bais_v_blend", [1], initializer=self.initializer) # 1 x 1
for i in range(self.max_enc_length + 1):
refi = tf.matmul(tf.squeeze(ref[:,i,:]),W_1)
ui = tf.add(tf.matmul(tf.nn.tanh(dec_portion+refi),v_blend),bais_blend) # B * 1
scores.append(tf.squeeze(ui))
scores = tf.transpose(scores,[1,0]) # B * S
if with_softmax:
return tf.nn.softmax(scores,dim=1)
else:
return scores
def glimpse_fn(self,ref, query, scope="glimpse"):
p = self.attention(ref, query, with_softmax=True, scope=scope)
alignments = tf.expand_dims(p, 2)
return tf.reduce_sum(alignments * ref, [1])
def choose_index(self,ref,query):
if self.num_glimpse > 0:
query = self.glimpse_fn(ref,query)
return self.attention(ref, query, with_softmax=True, scope="attention")
可以看到,我们的attention函数高度还原了上面的式子,哈哈!
decoder predicting
对预测来说,我们不能实现选择好用哪个encoder的输出,必须根据上一轮的输出来决定,所以与training的代码不同的是,我们在每层循环里都是用index_matrix_to_pairs函数以及gather_nd函数来选择下一时刻的输出。
# 预测输出的id序列
self.infer_predict_indexes = []
# 预测输出的softmax序列
self.infer_predict_indexes_distribution = []
with tf.variable_scope("decoder", reuse=True):
dec_state = self.enc_final_states
# 预测阶段最开始的输入是之前定义的初始输入
self.predict_decoder_input = self.first_decoder_input
for j in range(self.max_dec_length + 1):
if j > 0:
tf.get_variable_scope().reuse_variables()
self.predict_decoder_input = tf.squeeze(self.predict_decoder_input) # B * L
output, dec_state = self.dec_cell(self.predict_decoder_input, dec_state) # B * L
# 同样根据pointer机制得到softmax输出
idx_softmax = self.choose_index(self.enc_outputs, output) # B * E + 1
# 选择 最大的那个id
idx = tf.argmax(idx_softmax, 1, output_type=dtypes.int32) # B * 1
# 将选择的id转换为pair
idx_pairs = index_matrix_to_pairs(idx)
# 选择的下一个时刻的输入
self.predict_decoder_input = tf.stop_gradient(
tf.gather_nd(self.enc_outputs, idx_pairs)) # B * 1 * L
# decoder的每个输出的id
self.infer_predict_indexes.append(idx)
# decoder的每个输出的softmax序列
self.infer_predict_indexes_distribution.append(idx_softmax)
self.infer_predict_indexes = tf.convert_to_tensor(self.infer_predict_indexes,dtype=tf.int32)
self.infer_predict_indexes_distribution = tf.convert_to_tensor(self.infer_predict_indexes_distribution,dtype=tf.float32)
** 定义loss**
这里定义的loss与seq2seq的loss相似:
training_logits = tf.identity(tf.transpose(self.predict_indexes_distribution[:-1],[1,0,2]))
targets = tf.identity(self.target_seq)
masks = tf.sequence_mask(self.target_seq_length,self.max_dec_length,dtype=tf.float32,name="masks")
self.loss = tf.contrib.seq2seq.sequence_loss(
training_logits,
targets,
masks
)
self.optimizer = tf.train.AdamOptimizer(self.lr_start)
self.train_op = self.optimizer.minimize(self.loss)
定义训练、验证、预测函数
我们还定义了训练、验证、预测函数:
def train(self, sess, batch):
#对于训练阶段,需要执行self.train_op, self.loss, self.summary_op三个op,并传入相应的数据
feed_dict = {self.enc_seq: batch['enc_seq'],
self.enc_seq_length: batch['enc_seq_length'],
self.target_seq: batch['target_seq'],
self.target_seq_length: batch['target_seq_length']}
_, loss = sess.run([self.train_op, self.loss], feed_dict=feed_dict)
return loss
def eval(self, sess, batch):
# 对于eval阶段,不需要反向传播,所以只执行self.loss, self.summary_op两个op,并传入相应的数据
feed_dict = {self.enc_seq: batch['enc_seq'],
self.enc_seq_length: batch['enc_seq_length'],
self.target_seq: batch['target_seq'],
self.target_seq_length: batch['target_seq_length']}
loss= sess.run([self.loss], feed_dict=feed_dict)
return loss
def infer(self, sess, batch):
feed_dict = {self.enc_seq: batch['enc_seq'],
self.enc_seq_length: batch['enc_seq_length'],
self.target_seq: batch['target_seq'],
self.target_seq_length: batch['target_seq_length']}
predict = sess.run([self.infer_predict_indexes], feed_dict=feed_dict)
return predict
2.3 训练及验证
在main.py函数中,我们获取数据,并进行训练。这里代码还有待完善,因为没有进行预测,嘻嘻!
model = Model(config)
batch_size = config.batch_size
train_enc_seq, train_target_seq, train_enc_seq_length, train_target_seq_length = gen_data('data/tsp10.txt')
eval_enc_seq,eval_target_seq,eval_enc_seq_length,eval_target_seq_length = train_enc_seq[-batch_size:], \
train_target_seq[-batch_size:], \
train_enc_seq_length[-batch_size:], \
train_target_seq_length[-batch_size:]
train_enc_seq, train_target_seq, train_enc_seq_length, train_target_seq_length= train_enc_seq[: -batch_size], \
train_target_seq[:-batch_size], \
train_enc_seq_length[:-batch_size], \
train_target_seq_length[:-batch_size]
test_enc_seq, test_target_seq, test_enc_seq_length, test_target_seq_length = gen_data('data/tsp10_test.txt')
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for step in range(min(config.max_step,len(train_enc_seq)//batch_size)):
train_batch={
'enc_seq': train_enc_seq[step * batch_size:(step + 1) * batch_size],
'enc_seq_length': train_enc_seq_length[step * batch_size:(step + 1) * batch_size],
'target_seq': train_target_seq[step * batch_size:(step + 1) * batch_size],
'target_seq_length': train_target_seq_length[step * batch_size:(step + 1) * batch_size]
}
loss = model.train(sess,train_batch)
print(str(step) + " train loss : " + str(loss))
if step > 0 and step % config.eval_step == 0:
eval_batch = {
'enc_seq': eval_enc_seq,
'enc_seq_length': eval_enc_seq_length,
'target_seq': eval_target_seq,
'target_seq_length': eval_target_seq_length
}
eval_loss = model.eval(sess,eval_batch)
print(str(step) + " eval loss : " + str(eval_loss))
实验效果如下:

3、 参考文献
1、神经网络之Pointer Net (Ptr-net) :https://zhuanlan.zhihu.com/p/30860157
2、https://github.com/devsisters/pointer-network-tensorflow