1. 啸叫的产生
1.1 啸叫产生的原理
啸叫常见于扩音系统,比如多媒体会议厅、多媒体教室。 当麦克风和扬声器在同一个会场时,声音从扬声器扩音后又从被麦克风拾取,形成了声音反馈回路。当扩音的增益足够大,在某些频率就会产生自激振荡,形成刺耳的啸叫, 那就无法正常讲话了。
在扩音系统中使用硬件或者软件方法去除这种啸叫,就是声反馈控制(Acoustic Feedback Control),或者叫啸叫抑制(Howling Suppression)。
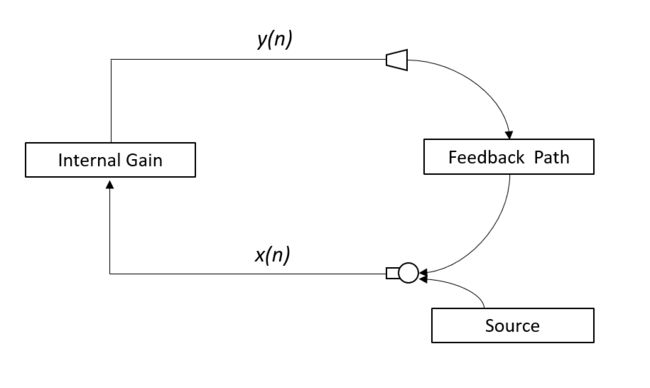
扬声器输出信号与麦克风输入信号之间的频率响应为:
根据奈奎斯特稳定判据,在某些频点,增益和相位满足以下条件,将产生自激振荡:
自激振荡导致了系统的不稳定,信号幅度不断增大,最终形成刺耳的啸叫。在频谱上看到一条连续的谱峰。
除了扩音系统,平常使用手机/电脑进行音视频通话,如果两个终端在同一个房间的话,也是可能产生啸叫的。 一般的商用软件和开源算法认为,通常通话的参与者不在一个房间的,所以很少遇到啸叫的问题,只需要解决噪声抑制和回声消除问题就可以了, 比如SpeexDsp和WebRTC。 但是从我个人经验而言,有两种情况是需要啸叫抑制的:
-在实验室做多终端通话测试
因资源限制,几台终端可能放在一个房间里面测试通话情况,这样一旦有人开始讲话,一台终端拾音后从另外一台终端上外放出来。 这样就形成了反馈回路,常常产生啸叫,测试就无法进行了。
-视频会议时多终端在同一个房间
开视频会议时,有部分参与者是同一个单位的,可能会在一个房间里面参加会议,如果房间里面一个人讲话,从同一个房间里面其他终端外放出来,就会产生啸叫。 这个情况如果让房间里面其他终端静音,是可以解决啸叫问题的。但是根据往常参加视频会议的经验,一般用户并不一定知道怎么操作。
Skype、微信、WebRTC之类应用,应该都没有对上面两种情况作优化。如果可以增加啸叫抑制的算法,语音通话或者视频会议遇到异常的机会就可以减少。
1.2 啸叫仿真
#simulate acoustic feekback, point-by-point
# _______________
# clean speech: x --> mic: x1 --> | Internal Gain | --> x2 -- > speaker : y
# ^ |______G________| |
# | |
# | _______________ |
# <-----------------y1--| Room Impulse |___________ v
# |____Response___|
#
N = min(2000, len(rir)) #limit room impulse response length
x2 = np.zeros(N) #buffer N samples of speaker output to generate acoustic feedback
y = np.zeros(len(x)) #save speaker output to y
y1 = 0.0 #init as 0
for i in range(len(x)):
x1 = x[i] + y1
y[i] = G*x1
y[i] = min(2, y[i]) #amplitude clipping
y[i] = max(-2, y[i])
x2[1:] = x2[:N-1]
x2[0] = y[i]
y1 = np.dot(x2, rir[:N])
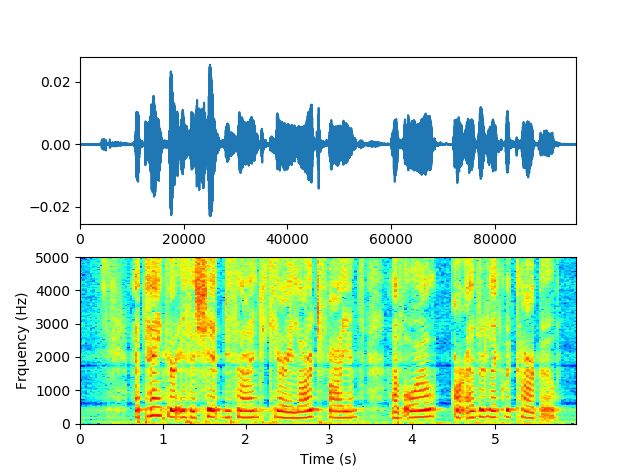
下面将一段干净语音经过反馈路径仿真,产生啸叫。反馈路径RIR直接使用参考资料[2]的path数据。非会员无法插入音频,音频可以上GibHub下载。下面分别是干净语音和啸叫语音的语谱图。
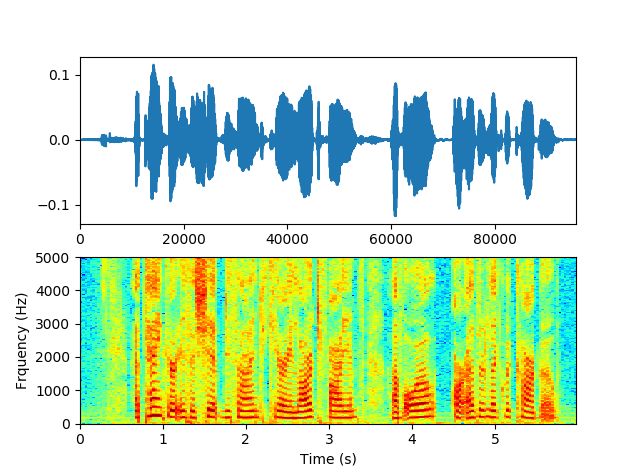
加啸叫后的音频,幅度已饱和,无法分辨原本语音,语谱图可以看见多个啸叫峰值。

2. 啸叫抑制的方法
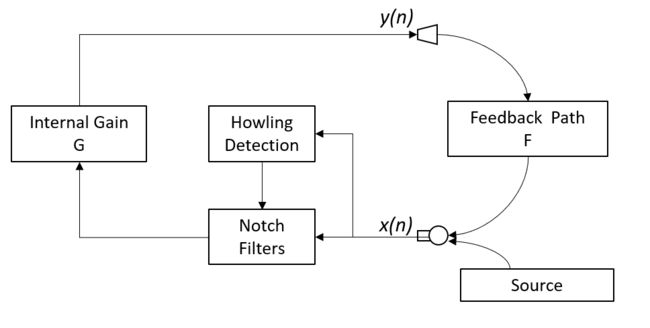
啸叫抑制的方法,主要有三种:频移/相移法、陷波法、和自适应方法。本文只实现第二种,陷波滤波器法。
顾名思义,陷波法就是要在声反馈系统的极点频率插入一个陷波滤波器,抑制极点的增益,使之无法达到啸叫的增益条件。因此陷波法需要分成两步:第一步,啸叫检测,将产生啸叫的频率找出来; 第二步,啸叫抑制,在找出来的啸叫频率设计陷波滤波器,并对麦克风信号进行滤波。
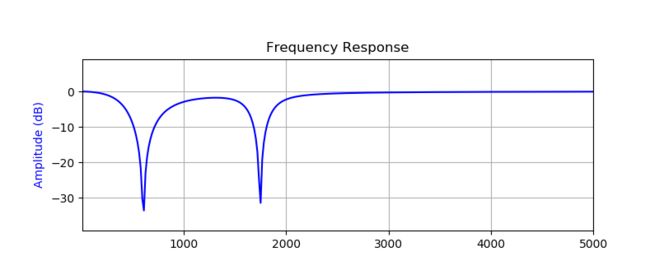
从前面啸叫语音的语谱图手动选择两个最大峰值,分别是603Hz和1745Hz (大概值,不是特别精确)。并且使用Python生成IIR Notch Filter 的系数b和a。
#notch filter
fs = Srate # Sample frequency (Hz)
f0 = 603 # Frequency to be removed from signal (Hz)
Q = 1 # Quality factor
# Design notch filter
b1, a1 = signal.iirnotch(f0, Q, fs)
sos1 = np.append(b1,a1)
#plot_notch_filter(b1, a1, fs)
f0 = 1745 # Frequency to be removed from signal (Hz)
Q = 5 # Quality factor
# Design notch filter
b2, a2 = signal.iirnotch(f0, Q, fs)
sos2 = np.append(b2,a2)
#plot_notch_filter(b2, a2, fs)
sos = np.vstack((sos1,sos2))
b, a = signal.sos2tf(sos)
plot_notch_filter(b, a, fs)
使用固定系数的陷波滤波器,插入到前面的声反馈系统中进行仿真。
#==============================Notch Filtering ==================================
# _______________ ______________
#clean speech: x --> mic: x1 --> | Internal Gain |-x2--> | Notch Filter |--> speaker: y
# ^ |______G________| |_____IIR______| |
# | |
# | _______________ |
# <-----------------y1--| Room Impulse |____________________ v
# |____Response___|
#
N = min(2000, len(rir)) #limit room impulse response length
x2 = np.zeros(len(b)) #
x3 = np.zeros(N) #buffer N samples of speaker output to generate acoustic feedback
y = np.zeros(len(x)) #save speaker output to y
y1 = 0.0 #init as 0
for i in range(len(x)):
x1 = x[i] + y1
x2[1:] = x2[:len(x2)-1]
x2[0] = G*x1
x2[0] = min(1, x2[0]) #amplitude clipping
x2[0] = max(-1, x2[0])
y[i] = np.dot(x2, b) - np.dot(x3[:len(a)-1], a[1:]) #IIR filter
x3[1:] = x3[:N-1]
x3[0] = y[i]
y1 = np.dot(x3, rir[:N])
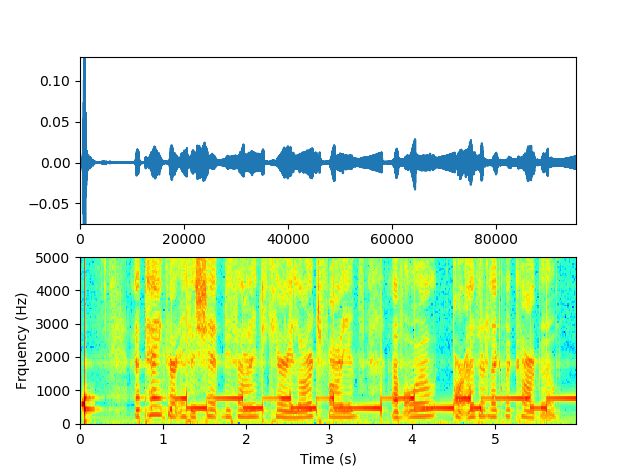
插入陷波滤波器后的扬声器输出信号频谱明显看见在603Hz和1745Hz 被抑制了,整体语音的谱图重现,可以听到清楚的语音信号 (除了陷波频率附近频率有损)。
2.1 啸叫检测
实际系统中,无法实现确定啸叫频率,所以需要出入啸叫检测。啸叫频点的检测,必须结合啸叫的时域和频域特征来进行分析。
频域上,啸叫频点功率很高,是一个峰值,远超其他语音或噪声频率的功率。
时域上,啸叫频点的功率有一个迅速增大的过程,达到饱和幅度后一直保持。
根据啸叫的时频特征,参考资料[1]总结了以下检测特征。
2.1.1 峰值阈值功率比(Peak-to-Threshold Power Raio, PTPR)
啸叫的功率远大于正常播放的音频。故设定一个阈值,只有功率超过阈值的频点,才会进行啸叫检测,减少无意义的检测判决。
2.1.2 峰值均值功率比(Peak-to-Average Power Raio, PAPR)
产生啸叫的频点功率远大于其他频点的功率,故可以先计算出整个频谱的平均功率,然后计算每个频点功率与平均功率之比。比值大于预设阈值的频点,记为候选啸叫频率。
2.1.3 峰值邻近功率比(Peak-to-Neighboring Power Raio, PNPR)
PNPR寻找功率谱的峰值点,加入候选啸叫频率。可以选取左右各M个相邻频点进行比较,当前频点功率比邻值都高时,记为候选啸叫频率。M选取5点左右
2.1.4 峰值谐波功率比(Peak-to-Harmonics Power Raio, PHPR)
语音谱有谐波峰,而啸叫频率是不含谐波峰的,故可以根据一个峰值点的谐波频率功率是不是也很大,来判断该峰值是否啸叫点。
2.1.5 帧间峰值保持度(Interframe Peak Magnitude Persistence, IPMP)
IPMP是时域特征,如果一个频点,连续几帧都是检测出来的候选啸叫峰值,那就认为这个点确实发生了啸叫。实现时可以选定5帧,超过3帧是候选啸叫频点的位置,判定为啸叫点。
2.1.6 帧间幅度斜率偏差度(Interframe Magnitude Slope Deviation, IMSD)
IMSD也是时域特征,是从啸叫开始发生时判断,这是啸叫频点幅度线性增长,那么帧间斜率就会保持不变。取帧进行区间观察,计算帧平均斜率,与区间内更短区间的斜率之间的差值,如果差值在设定阈值以下,就认为该区间斜率保持不变,可能是发生了啸叫。
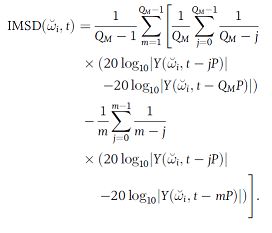
频域特征PTPR PAPR PNPR PHPR都是对一帧内频点进行分析,而时域特征是对多帧间的特征进行分析。所以在进行判决时,一般先对每帧频谱进行频域特征分析,然后对累计的时域特许证进行分析。
为了不影响原音频的频谱、以及限制滤波器计算量考虑,最后还需要限制啸叫频点的数量。一般系统可以选择五六个频点,简单的系统也可以尝试只选择啸叫程度最严重的一个或者两个频点。

下面进行仿真,暂时只把PTPR, PAPR, PNPR IPMP考虑进去。并且做一个Screening, 把离得太近的候选频点去除。
def howling_detect(frame, win, nFFT, Slen, candidates, frame_id):
insign = win * frame
spec = np.fft.fft(insign, nFFT, axis=0)
#========== Howling Detection Stage =====================#
ptpr_idx = pyHowling.ptpr(spec[:Slen], 10)
papr_idx, papr = pyHowling.papr(spec[:Slen], 10)
pnpr_idx = pyHowling.pnpr(spec[:Slen], 15)
intersec_idx = np.intersect1d(ptpr_idx, np.intersect1d(papr_idx,pnpr_idx))
for idx in intersec_idx:
candidates[idx][frame_id] = 1
ipmp = pyHowling.ipmp(candidates, frame_id)
result = pyHowling.screening(spec, ipmp)
return result
2.2 陷波法抑制啸叫
将啸叫检测和陷波滤波器都插入到声反馈系统中,动态监测啸叫频率,进行仿真。
#=============================Notch Filtering =======================================================
# ___________________
# -------> | Howling Detection | ______
# | |___________________| |
# | |
# | _______________ _______V______
#clean speech: x --> mic: x1 --> | Internal Gain |-x2--> | Notch Filter | -->speaker:y
# ^ |______G________| |_____IIR______| |
# | |
# | _______________ |
# <-----------------y1--| Room Impulse |____________________ v
# |____Response___|
#
b = [1.0, 0 ,0]
a = [0, 0, 0]
N = min(2000, len(rir)) #limit room impulse response length
x2 = np.zeros(100) #
x3 = np.zeros(N) #buffer N samples of speaker output to generate acoustic feedback
y = np.zeros(len(x)) #save speaker output to y
y1 = 0.0 #init as 0
current_frame = np.zeros(Slen)
pos = 0
candidates = np.zeros([Slen, Nframes+1], dtype='int')
frame_id = 0
notch_freqs = []
for i in range(len(x)):
x1 = x[i] + y1
current_frame[pos] = x1
pos = pos + 1
if pos==Slen:
#update notch filter frame by frame
freq_ids = howling_detect(current_frame, win, nFFT, Slen, candidates, frame_id)
#freq_ids = [46]
if(len(freq_ids)>0 and (len(freq_ids)!=len(notch_freqs) or not np.all(np.equal(notch_freqs, freqs[freq_ids])))):
notch_freqs = freqs[freq_ids]
sos = np.zeros([len(notch_freqs), 6])
for i in range(len(notch_freqs)):
b0, a0 = signal.iirnotch(notch_freqs[i], 1, Srate)
sos[i,:] = np.append(b0,a0)
b, a = signal.sos2tf(sos)
print("frame id: ", frame_id, "/", Nframes, "notch freqs:", notch_freqs)
current_frame[:Slen-len2] = current_frame[len2:] #shift by len2
pos = len2
frame_id = frame_id + 1
x2[1:] = x2[:len(x2)-1]
x2[0] = G*x1
x2[0] = min(2, x2[0]) #amplitude clipping
x2[0] = max(-2, x2[0])
y[i] = np.dot(x2[:len(b)], b) - np.dot(x3[:len(a)-1], a[1:]) #IIR filter
y[i] = min(2, y[i]) #amplitude clipping
y[i] = max(-2, y[i])
x3[1:] = x3[:N-1]
x3[0] = y[i]
y1 = np.dot(x3, rir[:N])
从结果上看,除了初始阶段产生了啸叫,后面基本抑制住了,可以听到语音信号。但是有断断续续的低幅度啸叫产生。IPMP等需要啸叫达到一定程度才能检测出来,如果换用IMSD,可能可以更快地动态抑制啸叫。
参考资料
[1] T. van Waterschoot and M. Moonen, "Fifty Years of Acoustic Feedback Control: State of the Art and Future Challenges," in Proceedings of the IEEE, vol. 99, no. 2, pp. 288-327, Feb. 2011, doi: 10.1109/JPROC.2010.2090998.
[2] https://github.com/Mathilda11/Speech-processing