在Unite Copenhagen 2019上,Unity技术支持工程师Ignacio Liverotti进行了一次主题为《性能优化经验分享》的演讲,旨在帮助中级Unity开发者诊断和解决遇到的性能问题。
作为Unity EMEA(欧洲、中东和非洲)地区的咨询及开发团队的技术支持工程师。Ignacio Liverotti在大部分时间中会和Unity的大客户进行接触,帮助他们解决项目中出现的性能问题。
本文,我们将通过此次演讲的内容,让你一窥Unity技术支持工程师的工作内容,并介绍一些优化知识和技巧,帮助你应用到自己的项目中。

《性能优化经验分享》
《性能优化经验分享》演讲的主要内容包括:
- Unity技术支持工程师的简介和核心工作:项目审查。
- 优化和性能分析的介绍。
- 针对CPU、GPU和内存使用的优化,以及介绍解决问题时用到的工具和方法。
- 一系列通用优化原则。
- Q&A。
项目审查
项目审查是Unity技术支持工程师的核心工作。我们前往客户的办公室,通常花上整整两天时间来熟悉他们的项目,询问他们的需求和设计决策,然后使用各种的性能分析工具,来检测性能瓶颈。
在结构完善的项目中,例如:利用模块化场景和AssetBundles等功能的项目,构建时间一般较短,我们可以在现场优化,然后重新分析场景,确定是否有新的问题。
此时优化构建时间的重要性就体现出来了:好的优化可以实现更频繁的迭代。对于开发硬件和目标硬件之间区别较大的项目来说,例如:面向移动设备或游戏主机的项目,构建时间的优化就更重要了。
由于我们的客户非常多样,他们的项目类型涵盖了各种目标平台和需求,因此项目审查的工作内容也不尽相同。如果在现场工作时,我们遇到了没能解决的问题,我们会尽量收集信息,在回到Unity办公室后,继续进行进一步的调查,必要的话还会咨询R&D的同事。
最终结果会取决于客户需求,但通常情况下,我们会提供一份总结调查结果和建议方案的书面报告。在决定关注的重点时,我们的目标是始终为客户提供最有价值的信息。
虽然我们有Unity的源代码,但在进行项目审查时,我们会尽量将自己放在客户的位置上考虑。也就是说,我们会使用网上可找到的性能分析工具和最佳实践,来优化客户的项目。
如果我们需要深入研究来找到性能问题的根本原因,那么在问题解决后,我们会尽可能对相关文档进行更新,从而将这些新知识提供给所有用户,给用户带来更大的便利。
CPU绑定与GPU绑定
正如演讲里说的,在开始优化项目前,我们需要找出实际的瓶颈究竟在哪里。一个可行的方法是使用Unity Profiler性能分析器,来查看CPU的使用状况。
如下图所示,如果大部分的帧时间都用在“Rendering”(渲染)部分,首先我们要确定项目是CPU绑定还是GPU绑定。
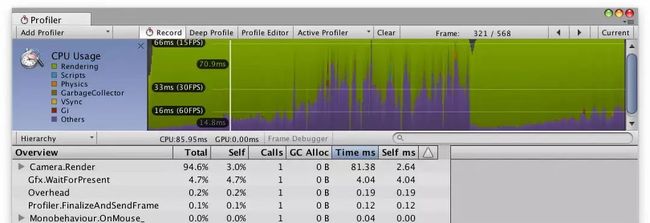
渲染过程会同时在CPU和GPU上执行,本文不会详细介绍渲染过程,简单来说,对于共用同一个材质的对象分组,场景的渲染过程主要包含以下步骤:
CPU将一系列指令传递给GPU,从而设置好内部状态,例如:着色器、绑定纹理、顶点格式等部分。该步骤又称为“set pass(设置通道)”调用。
CPU将几何体的批处理传递给GPU,让GPU根据上一步设置的状态来渲染几何体。这一步称为“Draw Call(绘制调用)”,耗费性能较大。
如果有更多相同材质类型的几何体需要渲染,那么就重复第二步操作。
以上操作的相应算法有许多的细节和注意事项,但关键点在于渲染过程会同时在CPU和GPU上执行。如下图所示,Xcode这类工具可以给我们提供CPU和GPU资源所花的具体时间。
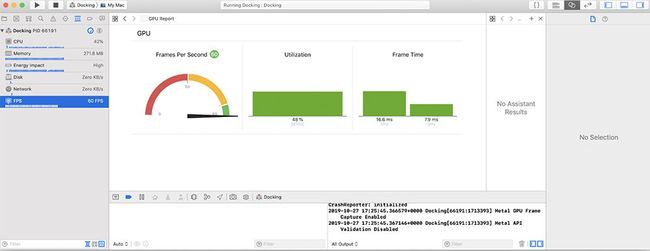
我们也可以在Unity性能分析器找到这类信息,不过由于这些信息取决于显卡和驱动提供的支持,因此GPU数据不总是会出现。

如果我们无法使用性能分析工具获取CPU和GPU的使用时间,则可以在性能分析器中观察任一帧的情况。
如果存在对Gfx.WaitForPresent的调用,并且显示“调用花费了不少时间”,这意味着CPU正在等待GPU完成所有的渲染指令,说明该项目属于GPU绑定。
了解WaitForTargetFPS和Gfx.PresentFrame等标记的含义:
https://docs.unity3d.com/Manual/ProfilerCPU.html

对GPU工作量影响较大的因素有以下几种:
Fill rate(填充率):在特定帧上,应用程序多次在过多的像素上进行着色,该过程称为“Overdraw”(过度绘制)。
内存带宽:应用程序可能会给GPU发送大量纹理数据。如果想减少内存占用,我们可以使用纹理图集来减少纹理数量,减少纹理大小,或在条件允许时将纹理压缩为特定格式。
顶点处理:应用程序向GPU发送过多的几何体。在Unite的演讲中,我们把这种情况作为案例进行了讲解。
此外,如果项目属于CPU绑定,那么会有许多东西会增加CPU时间,例如:物理、游戏代码等,我们同样应该查看性能分析器。
如果性能分析器告诉我们在渲染上花了很多时间,这可能表示CPU忙于给GPU传递过多的指令。这种情况可以通过减少状态变更的次数(或“SetPass”调用)和批处理次数,来实现优化的目的。
关于此问题的深入讨论,请阅读《Fixing Performance Problems(修补性能问题)》教程:
https://learn.unity.com/tutorial/fixing-performance-problems#5c7f8528edbc2a002053b596
案例学习:加载数据时出现CPU峰值情况
在客户的项目中,一个常见问题是:在应用程序启动时,或进入新关卡的时候,可能会出现的性能卡顿问题。
在Unity性能分析器中,这类卡顿问题会显示为峰值情况。

卡顿的原因主要是:性能开销较大的处理过程和大量的内存分配。在本案例中,CPU峰值情况造成了近10秒的卡顿,托管分配的内存量达到3.8 GB,如下图所示。
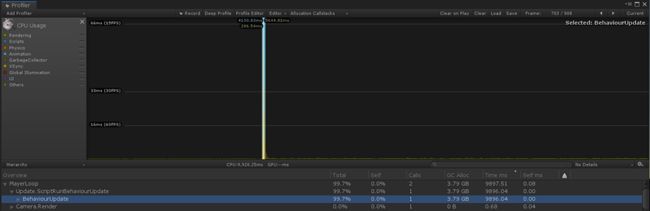
这种峰值情况应该是要避免的,主要有两个原因:
过长的运算时间会中断应用的运行过程。掩盖卡顿情况的一种方法是使用加载界面,然而如果画面中需要展示动态元素,那么该方法不会起到作用,因为动画也会在加载时发生卡顿。
大量的内存分配会造成托管堆的大小永久增大。Unity的自动内存管理系统的工作方式是:没有引用的内存会在后续分配过程中重用,但是托管堆的大小不会减小,而是只会增加。这种情况称为“非压缩式垃圾回收(Non-compacting garbage collection)”。
请参考Unity官方文档和Unity Learn的文章中了解更多信息。
Unity官方文档:
https://docs.unity3d.com/Manual/UnderstandingAutomaticMemoryManagement.html
Unity Learn文章:
https://learn.unity.com/tutorial/fixing-performance-problems#5c7f8528edbc2a002053b595
峰值情况往往由多种因素造成。根据我们的实地经验,其中一个原因是应用程序使用了未优化的格式来存储数据。例如:JSON格式和XML格式,而解析器需要分配大量内存来继续处理应用内容。除了这种分配外,对这类数据执行的大量计算和相应的内存分配都是罪魁祸首。
为了减小这些问题的影响,我们通常建议客户实现“预算时间管理器”系统,它会在每帧限制中实例化和初始化对象,并添加对二进制格式的支持。“预算时间管理器”会将运算分散到多个帧上,而对二进制数据的支持则会减少内存分配的大小。
“预算时间管理器”与使用单个方法加载所有数据之间的区别,类似普通垃圾回收器和增量式垃圾回收功能的区别:前者会在某一帧上卡顿,直到整个列表的托管对象处理完毕,而后者会将处理过程分散到多个帧上执行。
由于它们存在的本质特点,二进制数据通常难以在开发中使用。因此我们建议客户不要完全移除对文本格式的支持,而是支持和使用文本及二进制两种格式,具体取决于客户执行的是应用程序的开发版本还是发布版本。
垃圾回收过程
在演讲的《GC spikes in a fast-paced game”(快节奏游戏的GC峰值情况》案例中,我们建议客户启用Incremental Garbage Collector增量式垃圾回收功能,尽可能减少帧时间,给算法足够的空间在每帧的结束时完成执行过程。
但在演讲中,没有足够强调的一点是:对于最小化托管内存分配的数量和大小,增量式垃圾回收功能不是让该过程不够严谨的借口。
和常规垃圾回收器相比,增量式垃圾回收优点是可以将工作量分布到多个帧上完成,从而避免在单个帧上等待整个托管对象池处理完毕,这对维持稳定的帧率非常重要。
我们可以把GarbageCollector.GCMode静态字段的值更改为GarbageCollector.Mode.Disabled,从而禁用垃圾回收器。
GarbageCollector.GCMode = GarbageCollector.Mode.Disabled;
如果不想产生垃圾回收算法相关的处理开销,我们可以使用这个方法。但需要注意,使用这种方法时,我们需要确保在垃圾回收器禁用时,不会发生任何内存分配操作。
因为就如演讲中所说,在内存使用量超过特定阈值时,操作系统会主动关闭应用程序。在Android和iOS等移动平台上,这种情况更加明显。
案例学习:使用权威服务器的FPS游戏
权威服务器架构(Authoritative Server Architecture),这种架构的网络游戏是游戏客户端将输入(按键,命令)发送到服务器,服务器运行游戏,然后将结果发送回客户端。之所以称之为“权威服务器”,是因为关于游戏世界中发生的一切,唯一有权限处理的只有服务器。
几个月前我们对一款第一人称多人射击游戏进行项目审查,该游戏拥有一个权威服务器架构,而服务器通过无头模式(Headless mode)运行。
我们使用了Unity Memory Profiler内存分析器来获取内存信息,发现无头服务器上有许多不必要的网格、光照探针、音频剪辑、网格渲染器和各种其它类型的对象,累计分配了上百MB的内存。
虽然这些额外的内存占用没有影响服务器运行单个多人游戏会话,但是却明显影响到了游戏的可扩展性。具体来说,在特定服务器上增加活动实例数量会需要更多的内存。
在这种情况下,我们建议客户把每个游戏关卡场景分为两个部分,分别保存到不同的AssetBundle中。第一个部分是“逻辑场景”,其中包含了无头服务器需要的所有信息,第二个部分是“可视场景”,其中包含了只有客户端使用的所有信息。
这种划分操作可能会造成工作流程上的问题。更具体来说,美术师和关卡设计师将不能在同一个场景中协作。因此我们没有让客户变更内容创作者的工作流程,而是建议保持原有创作流程,在构建流程中额外加入划分为“逻辑场景”和“可视场景”的流程。
深度分析与分析器标记
我们的目标是在应用程序的核心运行循环中把内存分配降到接近0/帧。减少内存分配会减少垃圾回收算法产生的开销。
Unity性能分析器是最能胜任的工具,但在调用堆栈报告中,默认深度层次只能是引擎原生代码在转入应用编程代码中首次调用堆栈深度一致,例如:MonoBehaviour.Start()、MonoBehaviour. Update()及类似的方法。
在实际使用时,如果脚本调用了其它脚本的方法,我们无法轻易找到发生托管内存分配的具体位置。
解决问题的一种方法是:给脚本加上Profiler Markers分析器标记。这样我们可以在性能分析时记录额外的信息,帮助我们缩小内存分配的来源范围。
另一种方法是:启用Deep Profiling深度分析功能。
深度分析功能的具体操作请阅读Unity Learn的文章:
https://learn.unity.com/tutorial/profiling-applications-made-with-unity#5c7f8528edbc2a002053b5b6
请注意,深度分析功能会增加更多性能开销,大幅减慢应用运行速度,因此报告记录的时间并不准确。
我们建议首先在禁用深度分析过程时,运行性能分析流程,记录造成额外托管内存分配的情况,如果调用栈报告不能提供足够的信息来找出分配来源,那么我们要使用深度分析功能进行第二次分析,从而找到这些分配的来源。
在Unity 2019.3之前,深度分析功能只可以在使用Mono脚本后端时使用。Unity 2019.3的Beta版已经不存在这个限制,深度分析功能同时支持Mono后端和IL2CPP后端。
下面是Unity 2019.3 Beta的部分发行说明:
- Profiler:添加了Deep Profiler深度分析器对Mono后端和IL2CPP后端的支持。
- Profiler:添加了Deep Profiling深度分析器对运行版本构建选项的支持。当使用Deep Profiling深度分析功能构建运行版本时,可以动态地启用或禁用C#代码插装功能(C# Code Instrumentation)。
- Profiler:对运行版本添加了托管内存分配调用栈的支持。当启用调用栈回收时,GC.Alloc的样本将包含C#代码调用栈。
由于深度分析功能现在支持IL2CPP后端,开发者可以在iOS这类只支持IL2CPP的平台上执行深度分析数据收集。此外,新增的对托管内存分配调用栈的支持,可以帮助开发者找到运行版本内存分配来源,不必进行深度分析。
结语
性能优化是一个很大的话题,需要开发者掌握各式各样的技能,例如:了解底层硬件的操作原理和局限。
了解Unity提供的各种类和组件,算法和数据结构,并且要知道如何使用性能分析工具,开发者也需要发挥一定的创造力,来找到能够满足设计需求的高效解决方案。