单机有什么问题?
1.机器故障
2.容量瓶颈
3.QPS瓶颈
主从复制的作用
1.数据备份
2.一主多从,高可用和分布式的基础
3.扩展读性能
注意:
1.一个master可以有多个slave
2.一个slave只能有一个master
3.数据流向是单向的,master到slave
主从复制的配置
1.通过slaveof命令
2.通过配置文件
命令实现
# 创建主从,该命令是异步的,返回OK,但不代表操作已完成
slaveof 127.0.0.1:6379
#删除主从,返回OK,但数据并不会删除,只是连接断开
#如果又重新创建一个主,则第一步会把改从节点的所有数据先清除
slave no one
配置实现
在从节点的配置文件中设置其主是多少
设置slave-read-only yes #设置从节点只能读,不能写,否则写入从节点的数据,主不会知道,造成数据不同步
复制偏移量
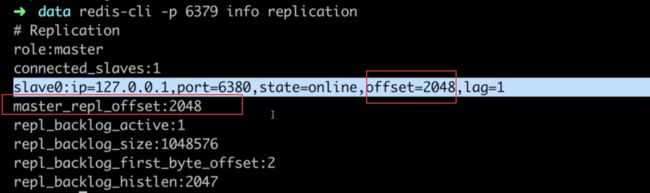
主从偏移量理论上应该一致,否则就数据不同步。
全量复制
每个redis运行时都会有一个run_id,当redis重启后,run_id就会发生变化。
从节点生成时,会知道主节点的run_id,当主节点run_id变化,从节点会重新复制主节点的全部数据,即全量复制
全量复制的过程
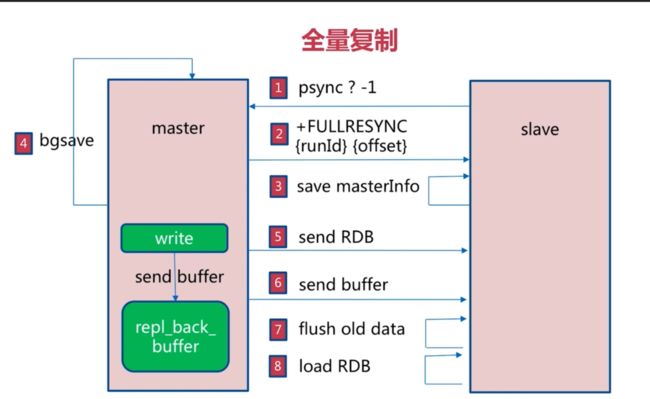
第一步:从节点会像主节点发送psync 命令,它有2个参数,第一个是偏移量,第二个是run_id,首次传送不知道主节点的run_id所以命令为psync -1?
第二步:主节点判断参数,由于是?-1,则会返回run_id和offset
第三步:从节点保存主节点信息
第四步:主节点进行bgsave
第五步:send_rdb
第六步:send_buffer
需要将部分数据,即新生数据,RDB开始生成到RDB传输过程中的一个新增命令进行保存,在send_rdb之后传输过去
repl_back_buffer:复制缓冲区,可以记录最新写入的命令,默认是1MB的数据大小
第七步:清空老数据
第八步:加载rdb文件和buffer文件
全量复制的开销非常大

部分复制
由于全量复制的开销非常大,如果从节点网络出现故障,与主节点断开时,如果没有部分复制就需要全量复制。
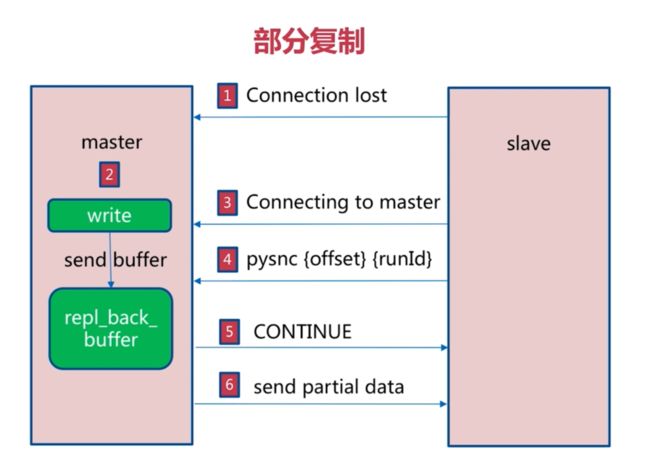
第四步:从节点会将断开前的offset和run_id传给主节点
第五步:主节点会判断从节点传过来的offset是否在队列中,找到断开时的偏移量,将这部分数据传过去
主从复制常见问题
1.读写分离
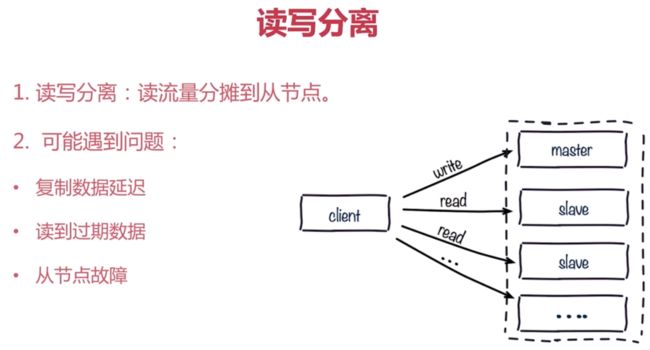
2.配置不一致

3.减少全量复制

4.规避复制风暴
当主节点宕机后重启,所有从节点都需要进行主从复制,开销非常大
