XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用
文档及源码
中文文档
源码仓库地址
| 源码仓库地址 | Release Download |
|---|---|
| https://github.com/xuxueli/xxl-job | Download |
| http://gitee.com/xuxueli0323/xxl-job | Download |
一、调度中心部署
1.1 初始化“调度数据库”
数据库中根据“调度数据库初始化SQL脚本”创建调度数据库
“调度数据库初始化SQL脚本” 位置为:
调度中心支持集群部署,集群情况下各节点务必连接同一个mysql实例
如果mysql做主从,调度中心集群节点务必强制走主库
1.2 部署 xxl-job-admin(调度中心)
统一管理任务调度平台上调度任务,负责触发调度执行,并且提供任务管理平台
1.2.1 调度中心配置
### 调度中心JDBC链接
spring.datasource.url=jdbc:mysql://database_ip:port/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
spring.datasource.username=your_username
spring.datasource.password=your_password
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
### 报警邮箱
spring.mail.host=smtp.qq.com
spring.mail.port=25
[email protected]
spring.mail.password=xxx
spring.mail.properties.mail.smtp.auth=true
spring.mail.properties.mail.smtp.starttls.enable=true
spring.mail.properties.mail.smtp.starttls.required=true
spring.mail.properties.mail.smtp.socketFactory.class=javax.net.ssl.SSLSocketFactory
### 调度中心通讯TOKEN:非空时启用;
xxl.job.accessToken=
### 调度中心国际化配置:"zh_CN"/中文简体, "zh_TC"/中文繁体 and "en"/英文;
xxl.job.i18n=zh_CN
## 调度线程池最大线程配置
xxl.job.triggerpool.fast.max=200
xxl.job.triggerpool.slow.max=100
### 调度中心日志表数据保存天数:过期日志自动清理;限制大于等于7时生效,否则, 如-1,关闭自动清理功能;
xxl.job.logretentiondays=30
1.2.2 调度中心部署
如果已经正确进行上述配置,可将项目编译打包部署,本例使用的测试服务器 ip 为:10.91.198.13,端口为 18080
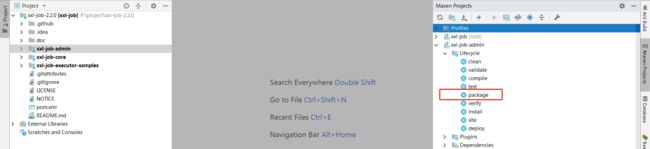
调度中心访问地址:http://10.91.198.13:18080/xxl-job-admin (该地址执行器将会使用到,作为回调地址)
默认登录账号 “admin/123456”, 登录后运行界面如下图所示
1.3 调度中心集群
调度中心集群部署时,有以下注意点:
- DB配置保持一致
- 集群机器时钟保持一致(单机集群忽视)
- 建议:推荐通过nginx为调度中心集群做负载均衡,分配域名。调度中心访问、执行器回调配置、调用API服务等操作均通过该域名进行
二、现有项目接入
2.1 引入POM
com.saicmotor.com
sp-xxl-job-core
1.0.0
2.2 添加 xxl-job 配置项
# 项目端口
server.port=8081
# no web
#spring.main.web-environment=false
# 日志配置
logging.config=classpath:logback.xml
### 调度中心部署跟地址 [选填]:如调度中心集群部署存在多个地址则用逗号分隔。执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调";为空则关闭自动注册
xxl.job.admin.addresses=http://10.91.198.13:18080/xxl-job-admin
### 执行器通讯TOKEN [选填]:非空时启用
xxl.job.accessToken=
### 执行器AppName [选填]:执行器心跳注册分组依据;为空则关闭自动注册
xxl.job.executor.appname=executor-test-lzn
### 执行器注册 [选填]:优先使用该配置作为注册地址,为空时使用内嵌服务 ”IP:PORT“ 作为注册地址。从而更灵活的支持容器类型执行器动态IP和动态映射端口问题
xxl.job.executor.address=http://项目ip:执行器端口号
### 执行器IP [选填]:默认为空表示自动获取IP,多网卡时可手动设置指定IP,该IP不会绑定Host仅作为通讯实用;地址信息用于 "执行器注册" 和 "调度中心请求并触发任务"
xxl.job.executor.ip=项目ip
### 执行器端口号 [选填]:小于等于0则自动获取;默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口
xxl.job.executor.port=9999
### 执行器运行日志文件存储磁盘路径 [选填] :需要对该路径拥有读写权限;为空则使用默认路径
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
### 执行器日志文件保存天数 [选填] : 过期日志自动清理, 限制值大于等于3时生效; 否则, 如-1, 关闭自动清理功能
xxl.job.executor.logretentiondays=30
2.3 添加执行器组件配置(现已自动装配)
@Configuration
public class XxlJobConfig {
private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
}
2.4 自定义定时任务
开发步骤:
- 在 Spring Bean 实例中,开发 Job 方法,方式格式要求为 "public ReturnT
execute(String param) " - 为 Job 方法添加注解 "@XxlJob(value="自定义 jobhandler 名称", init = "JobHandler 初始化方法", destroy = "JobHandler 销毁方法")",注解value值对应的是调度中心新建任务的 JobHandler 属性的值
/**
* XxlJob开发示例
*/
@Component
public class SampleXxlJobPools {
private static Logger logger = LoggerFactory.getLogger(SampleXxlJob.class);
@XxlJob(value = "testJobHandler", init = "init", destroy = "destroy")
public ReturnT demoJobHandler(String param) throws Exception {
XxlJobLogger.log("XXL-JOB, Hello World, Hello zll");
return ReturnT.SUCCESS;
}
public void init() {
logger.info("testJobHandler init");
}
public void destroy() {
logger.info("testJobHandler destory");
}
}
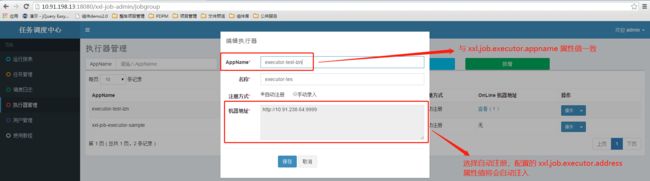
2.5 配置执行器
进入调度中心:http://10.91.198.13:18080/xxl-job-admin
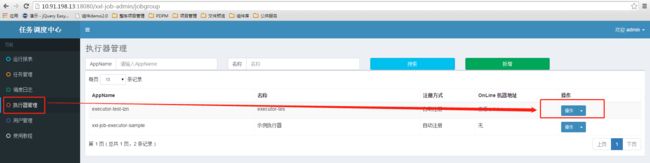
进入执行器管理,点击操作 -> 编辑,进入执行器编辑页面
2.6 配置及执行任务
进入调度中心:http://10.91.198.13:18080/xxl-job-admin

进入任务管理,点击新增,进入新增任务页面
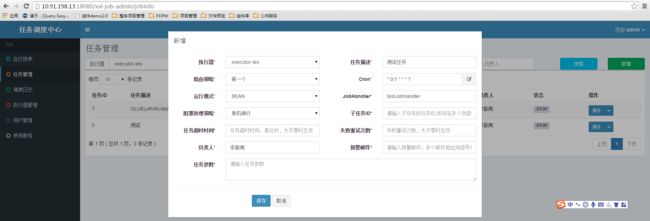
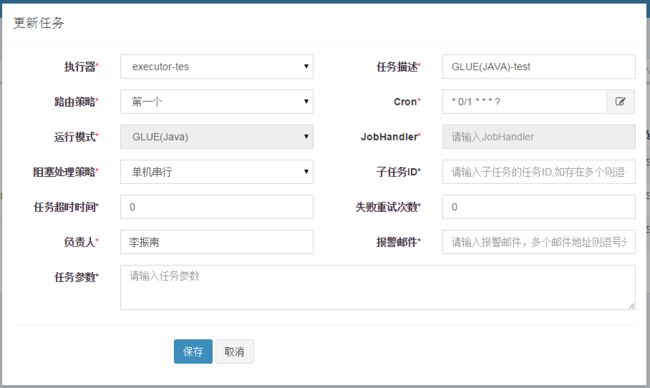
任务配置参数释义如下:
| 参数 | 说明 |
|---|---|
| 执行器 | 任务的绑定的执行器,任务触发调度时将会自动发现注册成功的执行器, 实现任务自动发现功能; 另一方面也可以方便的进行任务分组。每个任务必须绑定一个执行器, 可在 "执行器管理" 进行设置 |
| 任务描述 | 任务的描述信息,便于任务管理 |
| 路由策略 | FIRST(第一个):固定选择第一个机器; LAST(最后一个):固定选择最后一个机器; ROUND(轮询):轮询; RANDOM(随机):随机选择在线的机器; CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上; LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举; LEAST_RECENTLY_USED(最近最久未使用):最久未使用的机器优先被选举; FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度; BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度; SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务; |
| Cron | 触发任务执行的Cron表达式 |
| 运行模式 | BEAN模式:任务以JobHandler方式维护在执行器端;需要结合 "JobHandler" 属性匹配执行器中任务; GLUE模式(Java):任务以源码方式维护在调度中心;该模式的任务实际上是一段继承自IJobHandler的Java类代码并 "groovy" 源码方式维护,它在执行器项目中运行,可使用@Resource/@Autowire注入执行器里中的其他服务; GLUE模式(Shell):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "shell" 脚本; GLUE模式(Python):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "python" 脚本; GLUE模式(PHP):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "php" 脚本; GLUE模式(NodeJS):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "nodejs" 脚本; GLUE模式(PowerShell):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "PowerShell" 脚本; |
| JobHandler | 行模式为 "BEAN模式" 时生效,对应执行器中新开发的 JobHandler 类 “@JobHandler” 注解自定义的 value 值 |
| 阻塞处理策略 | 调度过于密集执行器来不及处理时的处理策略; 单机串行(默认):调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行; 丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败; 覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务; |
| 子任务 | 每个任务都拥有一个唯一的任务ID(任务ID可以从任务列表获取),当本任务执行结束并且执行成功时,将会触发子任务ID所对应的任务的一次主动调度 |
| 任务超时时间 | 支持自定义任务超时时间,任务运行超时将会主动中断任务 |
| 失败重试次数 | 支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试 |
| 报警邮件 | 任务调度失败时邮件通知的邮箱地址,支持配置多邮箱地址,配置多个邮箱地址时用逗号分隔 |
| 负责人 | 任务的负责人 |
| 任务参数 | 任务执行所需的参数 |
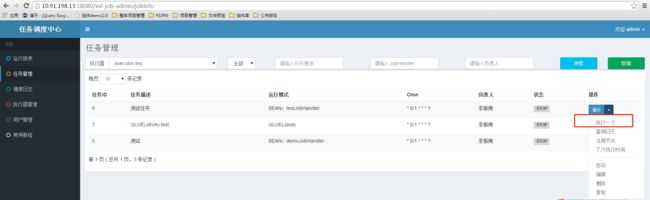
配置任务后,右击选择执行一次进行任务调度测试
任务执行后进入调度日志,可以查看任务执行日志
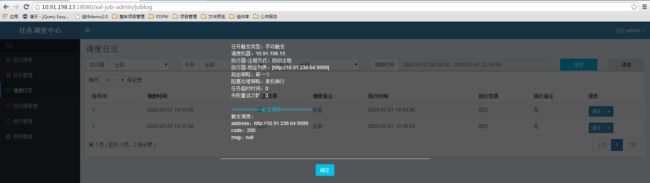

至此项目的任务配置完成
2.7 执行器集群
执行器集群部署时,几点要求和建议:
- 执行器回调地址(xxl.job.admin.addresses)需要保持一致;执行器根据该配置进行执行器自动注册等操作
- 同一个执行器集群内AppName(xxl.job.executor.appname)需要保持一致;调度中心根据该配置动态发现不同集群的在线执行器列表
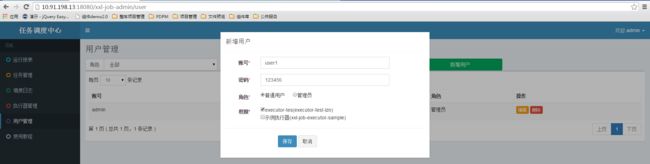
三、用户管理
进入 “用户管理” 界面,可查看和管理用户信息;
目前用户分为两种角色:
- 管理员:拥有全量权限,支持在线管理用户信息,为用户分配权限,权限分配粒度为执行器;
- 普通用户:仅拥有被分配权限的执行器,及相关任务的操作权限;

四、任务详解
4.1 BEAN模式(类形式)
Bean模式任务,支持基于方法的开发方式,每个任务对应一个方法。
- 优点:
- 每个任务只需要开发一个方法,并添加”@XxlJob”注解即可,更加方便、快速。
- 支持自动扫描任务并注入到执行器容器。
- 缺点:要求Spring容器环境;
4.1.1 开发方法详解
- 在Spring Bean实例中,开发Job方法,方式格式要求为 "public ReturnT
execute(String param)" - 为Job方法添加注解 "@XxlJob(value="自定义jobhandler名称", init = "JobHandler初始化方法", destroy = "JobHandler销毁方法")",注解value值对应的是调度中心新建任务的JobHandler属性的值
- 执行日志:需要通过 "XxlJobLogger.log" 打印执行日志
4.1.2 内置 Bean 模式任务
为方便用户参考与快速实用,示例执行器内原生提供多个Bean模式任务Handler,可以直接配置实用,如下:
shardingJobHandler:分片示例任务,任务内部模拟处理分片参数,可参考熟悉分片任务
-
httpJobHandler:通用HTTP任务Handler;业务方只需要提供HTTP链接等信息即可,不限制语言、平台。示例任务入参如下:
url: http://www.xxx.com method: get 或 post data: post-data commandJobHandler:通用命令行任务Handler;业务方只需要提供命令行即可;如 “pwd”命令
4.2 GLUE模式(Java)
任务以源码方式维护在调度中心,支持通过 Web IDE 在线更新,实时编译和生效,因此不需要指定 JobHandler
4.2.1 基本开发流程
调度中心,新建调度任务
参考新建的任务进行参数配置,运行模式选中 “GLUE模式(Java)”
开发任务代码
选中指定任务,点击该任务右侧“GLUE”按钮,将会前往GLUE任务的Web IDE界面,在该界面支持对任务代码进行开发(也可以在IDE中开发完成后,复制粘贴到编辑中)。
版本回溯功能(支持30个版本的版本回溯):在GLUE任务的Web IDE界面,选择右上角下拉框“版本回溯”,会列出该GLUE的更新历史,选择相应版本即可显示该版本代码,保存后GLUE代码即回退到对应的历史版本;
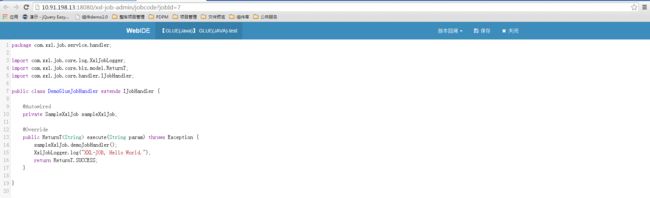
执行任务
在任务管理器中执行任务即可
4.2.2 注入执行器中的 Bean 实例
在线编辑的代码可以通过 @Autowired or @Resource 注解使用执行器中注册在 spring 容器中的 bean 实例,具体配置如下:
添加 SpringUtils 获取 IOC 容器
/**
* 获取 Spring IOC 容器
*
*/
public class SpringUtils implements ApplicationContextAware {
private static ApplicationContext applicationContext;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
SpringUtils.applicationContext = applicationContext;
}
public static ApplicationContext getApplicationContext() {
return applicationContext;
}
}
添加测试服务类
@Service
public class TestService {
@Value("lzn")
private String name;
public TestService() {
}
public TestService(String name) {
this.name = name;
}
public String testHello() {
return "testHello: " + name;
}
}
修改 XxlJobConfig 配置类
为 XxlJobSpringExecutor 设置 ApplicationContext
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
xxlJobSpringExecutor.setApplicationContext(SpringUtils.getApplicationContext());
return xxlJobSpringExecutor;
}
任务代码修改如下
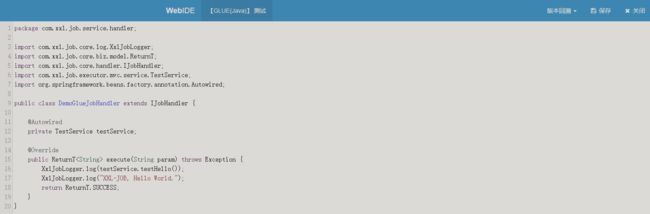
任务执行后,执行日志如下,可以看到 TestService#testHello() 方法成功注入并执行
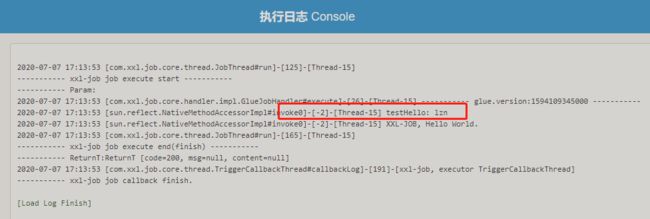
4.3 GLUE模式(Shell)
待补充
五、XXL-JOB VS. Kangaroo ETL
5.1 ETL
ETL(Extraction-Transformation-Loading)用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。ETL负责将分布的、异构数据源中的数据如关系数据、平面数据文件等抽取到临时中间层后进行清洗、转换、集成,最后加载到数据仓库或数据集市中,成为联机分析处理、数据挖掘的基础。
ETL 是数据仓库获取高质量数据的关键环节,也是BI(商业智能)项目最重要的一个环节,可以说,ETL设计的好坏直接关系到BI项目的成败。
ETL是一个长期的过程,通过对分散在各业务系统中相互关联的分布式异构数据进行提取(Extract)、清洗、转换(Transform)和加载(Load),使这些数据成为BI系统需要的有用数据。
5.2 ETL 流程
5.2.1. 数据提取(Data Extract)
数据提取指的是从不同的网络、操作平台、应用、数据库和数据格式中抽取数据的过程。
在这个过程中,首先需要根据实际业务需求进行抽取字段的确定,形成一张公共需求的清单,同时清单中的需求字段也应当和数据库中的字段形成一一映射关系,这样通过数据抽取得到的数据都能够整齐划一,为后续数据转换和加载提供基础。
具体实现过程中,将会涉及到如何解决从不同类型的数据库(如Oracle、MySQL、DB2)、不同类型的文件系统(如Linux、Windows)以何种方式(如数据库抽取、文件传输、流式)、何种频率(分钟、小时、天、周、月等)获取数据的问题。
5.2.2 数据转换(Data Transformation)
数据转换是指将数据从一种表现形式变为另一种表现形式的过程,即对数据进行整合、拆分和变换。
- 数据整合是指通过多表关联,将不同类型数据之间可能存在潜在关联关系的多条数据进行合并,通过数据的整合,丰富数据维度,有利于发现更多有价值的信息。
- 数据拆分是指按一定规则对数据进行拆分,将一条数据拆分为多条。
- 数据变换是指对数据进行行列转换、排序、修改序号、去除重复记录变换操作。
数据转换一般包括两类工作:
一种是对数据名称及格式进行统一,另一种则是数据仓库中可能会有源数据库中不存在的数据,因此需要进行字段的组合、分割或计算。
数据转换其实还包含了数据清洗的工作,根据业务规则对异常数据进行清洗,将不完整、错误或重复的数据进行相应处理,以保证后续分析结果的准确性。
5.2.3 数据加载(Data Loading)
数据加载的主要任务是将清洗过后的干净的数据集按物理数据模型定义的表结构装入目标数据仓库的数据表中,并允许人工干预,以及提供强大的错误报告、系统日志、数据备份与恢复功能。
数据加载的方式主要有:增量加载(时间戳方式、日志表方式、全表比对方式)、全量加载(全表删除再插入方式)。整个操作过程中往往要跨网络、跨操作平台。实际工作中,数据加载需要结合使用的数据库系统,确定最优的数据加载方案,节约CPU、硬盘IO和网络传输资源。
5.3 指标对比
| XXL-JOB | Kangaroo ETL | |
|---|---|---|
| 定位 | 面向系统定时任务的任务调度平台 | 面向数据服务的任务调度平台 |
| 任务类型 | 1 Bean模式:每个Bean模式任务都是一个Spring的Bean类实例,它被维护在“执行器”项目的Spring容器中 2 GLUE模式(Java):通过Groovy类加载器加载此代码,实例化成Java对象,执行任务逻辑 3 GLUE模式(Shell) + GLUE模式(Python) + GLUE模式(PHP) + GLUE模式(NodeJS) + GLUE模式(Powershell):脚本任务的源码托管在调度中心,脚本逻辑在执行器运行。通过Java代码调用脚本,在调度中心可以实时监控脚本运行情况 |
1 DX 任务:支持 Oracle、MySQL、SQL Server、Text 文件、HDFS(RCFile,TextFile,Orc 格式)5 种数据源之间的数据交换 2 Script 任务:支持 shell 脚本,通常用于执行 HiveSQL、SparkSQL、Jar 等 |
| 系统侵入性 | 有侵入 | 无侵入 |
| 系统兼容性 | 兼容 Spring、Dubbo等主流框架。针对非Java应用,可借助 XXL-JOB 的标准 RESTful API 方便的实现多语言支持 | - |
| 适用场景 | 将系统的定时任务和调度解耦,任务调度交给统一平台进行管理,提高系统可用性和稳定性 | 将分布的、异构的数据源中的数据通过合理的任务调度进行抽取、转换和加载,为后续的数据分析、数据挖掘做基础 |
六、总体设计
6.1 架构设计
6.1.1 系统组成
- 调度模块(调度中心)
负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度系统与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块;
支持可视化、简单且动态的管理调度信息,包括任务新建,更新,删除,GLUE开发和任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器Failover; - 执行模块(执行器)
负责接收调度请求并执行任务逻辑。任务模块专注于任务的执行等操作,开发和维护更加简单和高效;
接收“调度中心”的执行请求、终止请求和日志请求等;
6.1.2 架构图
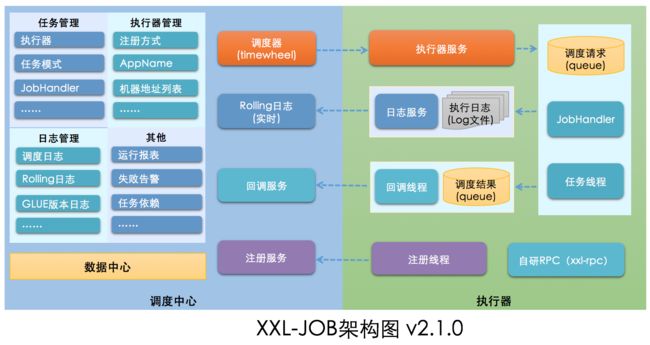
6.2 任务注册和自动发现
- AppName: 每个执行器机器集群的唯一标示, 任务注册以 "执行器" 为最小粒度进行注册; 每个任务通过其绑定的执行器可感知对应的执行器机器列表
- 注册表: 见"xxl_job_registry"表, "执行器" 在进行任务注册时将会周期性维护一条注册记录,即机器地址和AppName的绑定关系; "调度中心" 从而可以动态感知每个AppName在线的机器列表
- 执行器注册: 任务注册Beat周期默认30s; 执行器以一倍Beat进行执行器注册, 调度中心以一倍Beat进行动态任务发现; 注册信息的失效时间为三倍Beat
- 执行器注册摘除:执行器销毁时,将会主动上报调度中心并摘除对应的执行器机器信息,提高心跳注册的实时性
七 源码解析
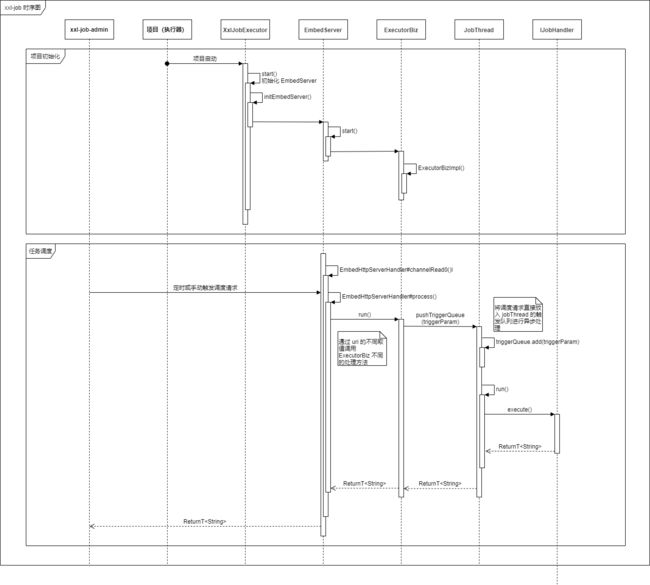
7.1 XxlJobSpringExecutor 启动
项目启动后获取配置文件中的属性值并实例化配置类 XxlJobSpringExecutor,XxlJobSpringExecutor 实现了 SmartInitializingSingleton 接口的 afterSingletonsInstantiated 方法,在实例化 XxlJobSpringExecutor 后触发执行,XxlJobSpringExecutor 在该方法里做了两件事:
调用 initJobHandlerMethodRepository 方法扫描项目中带 @XxlJob 注解的方法(即 jobHandler)并注册;
-
调用父类 XxlJobExecutor 的 start 方法启动 Executor,并初始化核心组件:
初始化 admin 控制台:initAdminBizList(adminAddresses, accessToken)
初始化日志清理进程 JobLogFileCleanThread:JobLogFileCleanThread.getInstance().start(logRetentionDays)
初始化触发回调进程 TriggerCallbackThread:TriggerCallbackThread.getInstance().start()
初始化内置服务 executor-server:initEmbedServer(address, ip, port, appname, accessToken)
7.1.1 jobHandler 注册
在项目启动时,执行器会通过 “@JobHandler” 识别 Spring 容器中 “Bean模式任务”,以注解的 value 属性为 key 管理起来,保存至 jobHandlerRepository。
1 initJobHandlerMethodRepository(ApplicationContext applicationContext)
该方法扫描项目中的类,将带有 @XxlJob 注解的 job 进行解析,并调用 registJobHandler(String name, IJobHandler jobHandler) 进行注册:
// ---------------------- job handler repository ----------------------
private static ConcurrentMap jobHandlerRepository = new ConcurrentHashMap();
// registry jobhandler
/**
* name: @XxlJob 的 value, jobHandler 的名字
* bean:带 @XxlJob 方法对应的类名
* method: 带 @XxlJob 注解的方法名
* initMethod: @XxlJob 的 init 值对应方法的全限定名,即 execute 方法调用前执行的方法
* destroyMethod: @XxlJob 的 destroy 值对应方法的全限定名,即 execute 方法调用后执行的方法
*/
registJobHandler(name, new MethodJobHandler(bean, method, initMethod, destroyMethod));
2 MethodJobHandler
public class MethodJobHandler extends IJobHandler {
private final Object target;
private final Method method;
private Method initMethod;
private Method destroyMethod;
public MethodJobHandler(Object target, Method method, Method initMethod, Method destroyMethod) {
this.target = target;
this.method = method;
this.initMethod =initMethod;
this.destroyMethod =destroyMethod;
}
@Override
public ReturnT execute(String param) throws Exception {
return (ReturnT) method.invoke(target, new Object[]{param});
}
@Override
public void init() throws InvocationTargetException, IllegalAccessException {
if(initMethod != null) {
initMethod.invoke(target);
}
}
@Override
public void destroy() throws InvocationTargetException, IllegalAccessException {
if(destroyMethod != null) {
destroyMethod.invoke(target);
}
}
}
7.1.2 XxlJobSpringExecutor 初始化
7.1.2.1 初始化 admin 控制台
initAdminBizList 实例化 AdminBizClient,并将其存在 adminBizList 中
private static List adminBizList;
private void initAdminBizList(String adminAddresses, String accessToken) throws Exception {
if (adminAddresses!=null && adminAddresses.trim().length()>0) {
// 多个 admin 控制台地址以 "," 分隔
for (String address: adminAddresses.trim().split(",")) {
if (address!=null && address.trim().length()>0) {
AdminBiz adminBiz = new AdminBizClient(address.trim(), accessToken);
if (adminBizList == null) {
adminBizList = new ArrayList();
}
adminBizList.add(adminBiz);
}
}
}
}
7.1.2.2 初始化日志清理进程
7.1.2.3 初始化触发回调进程
7.1.2.4 初始化内置服务
private void initEmbedServer(String address, String ip, int port, String appname, String accessToken) throws Exception {
// start
embedServer = new EmbedServer();
embedServer.start(address, port, appname, accessToken);
}
initEmbedServer 方法内部直接调用 EmbedServer#start 方法
public void start(final String address, final int port, final String appname, final String accessToken) {
// 1 初始化 executorBiz 执行单元和线程池
executorBiz = new ExecutorBizImpl();
ThreadPoolExecutor bizThreadPool = new ThreadPoolExecutor(
0,
200,
60L,
TimeUnit.SECONDS,
new LinkedBlockingQueue(2000),
new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "xxl-rpc, EmbedServer bizThreadPool-" + r.hashCode());
}
},
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
throw new RuntimeException("xxl-job, EmbedServer bizThreadPool is EXHAUSTED!");
}
});
// 2 启动 ServerBootstrap 并绑定端口号
ServerBootstrap bootstrap = new ServerBootstrap();
bootstrap.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer() {
@Override
public void initChannel(SocketChannel channel) throws Exception {
channel.pipeline()
.addLast(new IdleStateHandler(0, 0, 30 * 3, TimeUnit.SECONDS)) // beat 3N, close if idle
.addLast(new HttpServerCodec())
.addLast(new HttpObjectAggregator(5 * 1024 * 1024)) // merge request & reponse to FULL
.addLast(new EmbedHttpServerHandler(executorBiz, accessToken, bizThreadPool));
}
})
.childOption(ChannelOption.SO_KEEPALIVE, true);
ChannelFuture future = bootstrap.bind(port).sync();
// 3 将执行器信息注册到调度中心(admin 控制台)
startRegistry(appname, address);
// 4 wait util stop
future.channel().closeFuture().sync();
}
EmbedServer 的 start 方法主要处理以下几件事:
初始化 executorBiz 和线程池 bizThreadPool
-
启动 ServerBootstrap 并绑定端口号
调度中心实际的调度请求由 EmbedHttpServerHandler 处理
-
将执行器信息注册到调度中心(admin 控制台)
public void startRegistry(final String appname, final String address) { // start registry ExecutorRegistryThread.getInstance().start(appname, address); }ExecutorRegistryThread#start 方法封装执行器信息,并调用 AdminBizClient#registry 方法将执行器信息注册于调度中心,核心代码如下:
RegistryParam registryParam = new RegistryParam(RegistryConfig.RegistType.EXECUTOR.name(), appname, address); for (AdminBiz adminBiz: XxlJobExecutor.getAdminBizList()) { try { // AdminBizClient 实现 AdminBiz 接口,将执行器信息进行注册 ReturnTregistryResult = adminBiz.registry(registryParam); if (registryResult!=null && ReturnT.SUCCESS_CODE == registryResult.getCode()) { registryResult = ReturnT.SUCCESS; logger.debug(">>>>>>>>>>> xxl-job registry success, registryParam:{}, registryResult:{}", new Object[]{registryParam, registryResult}); break; } else { logger.info(">>>>>>>>>>> xxl-job registry fail, registryParam:{}, registryResult:{}", new Object[]{registryParam, registryResult}); } } catch (Exception e) { logger.info(">>>>>>>>>>> xxl-job registry error, registryParam:{}", registryParam, e); } }
7.2 调度平台发布任务
前端页面处罚具体任务后,转发至 JobInfoController 的 triggerJob 方法
/**
* 处理触发请求
*
* @param id 任务 id
* @param executorParam 执行器参数
* @param addressList 执行器地址
* @return
*/
@RequestMapping("/trigger")
@ResponseBody
public ReturnT triggerJob(int id, String executorParam, String addressList) {
JobTriggerPoolHelper.trigger(id, TriggerTypeEnum.MANUAL, -1, null, executorParam, addressList);
return ReturnT.SUCCESS;
}
JobTriggerPoolHelper 的 trigger 方法调用 addTrigger 方法,addTrigger 方法将调度请求交给线程池处理,线程池中通过 XxlJobTrigger 的 trigger 方法处理实际请求
public static void trigger(int jobId, TriggerTypeEnum triggerType, int failRetryCount, String executorShardingParam, String executorParam, String addressList) {
// 获取任务详细信息
XxlJobInfo jobInfo = XxlJobAdminConfig.getAdminConfig().getXxlJobInfoDao().loadById(jobId);
if (jobInfo == null) {
logger.warn(">>>>>>>>>>>> trigger fail, jobId invalid,jobId={}", jobId);
return;
}
// 设置任务执行参数
if (executorParam != null) {
jobInfo.setExecutorParam(executorParam);
}
int finalFailRetryCount = failRetryCount>=0?failRetryCount:jobInfo.getExecutorFailRetryCount();
// 获取执行器详细信息
XxlJobGroup group = XxlJobAdminConfig.getAdminConfig().getXxlJobGroupDao().load(jobInfo.getJobGroup());
// 如果手动设置执行任务机器的地址,则覆盖执行器原有的地址(即新增执行器时自动注册或手动录入的地址)
if (addressList!=null && addressList.trim().length()>0) {
group.setAddressType(1);
group.setAddressList(addressList.trim());
}
// sharding param
int[] shardingParam = null;
if (executorShardingParam!=null){
String[] shardingArr = executorShardingParam.split("/");
if (shardingArr.length==2 && isNumeric(shardingArr[0]) && isNumeric(shardingArr[1])) {
shardingParam = new int[2];
shardingParam[0] = Integer.valueOf(shardingArr[0]);
shardingParam[1] = Integer.valueOf(shardingArr[1]);
}
}
// 如果是分片广播任务,则根据执行器数量将任务发布至各个机器地址
if (ExecutorRouteStrategyEnum.SHARDING_BROADCAST==ExecutorRouteStrategyEnum.match(jobInfo.getExecutorRouteStrategy(), null)
&& group.getRegistryList()!=null && !group.getRegistryList().isEmpty()
&& shardingParam==null) {
for (int i = 0; i < group.getRegistryList().size(); i++) {
processTrigger(group, jobInfo, finalFailRetryCount, triggerType, i, group.getRegistryList().size());
}
} else { // 其他路由策略的任务发布一条即可
if (shardingParam == null) {
shardingParam = new int[]{0, 1};
}
processTrigger(group, jobInfo, finalFailRetryCount, triggerType, shardingParam[0], shardingParam[1]);
}
}
processTrigger 方法主要处理以下几件事:
初始化触发参数:TriggerParam
-
根据不同路由策略获取执行器地址
根据不同的 executorRouteStrategy 策略获取 ExecutorRouter,并调用 ExecutorRouter 的 route 方法选择一个执行器地址
// 根据不同路由策略获取执行器 ip 地址 routeAddressResult = executorRouteStrategyEnum.getRouter().route(triggerParam, group.getRegistryList()); -
发送调度请求至远程执行器
runExecutor 方法根据执行器地址获取执行单元 ExecutorBizClient,并调用 ExecutorBizClient 的 run 方法将调度请求以 HTTP POST 形式发送,由执行器的 EmbedServer 接受
public ReturnTrun(TriggerParam triggerParam) { return XxlJobRemotingUtil.postBody(addressUrl + "run", accessToken, timeout, triggerParam, String.class); } 保存任务执行信息
private static void processTrigger(XxlJobGroup group, XxlJobInfo jobInfo, int finalFailRetryCount, TriggerTypeEnum triggerType, int index, int total){
// param
ExecutorBlockStrategyEnum blockStrategy = ExecutorBlockStrategyEnum.match(jobInfo.getExecutorBlockStrategy(), ExecutorBlockStrategyEnum.SERIAL_EXECUTION); // block strategy
ExecutorRouteStrategyEnum executorRouteStrategyEnum = ExecutorRouteStrategyEnum.match(jobInfo.getExecutorRouteStrategy(), null); // route strategy
String shardingParam = (ExecutorRouteStrategyEnum.SHARDING_BROADCAST==executorRouteStrategyEnum)?String.valueOf(index).concat("/").concat(String.valueOf(total)):null;
// 1、save log-id
XxlJobLog jobLog = new XxlJobLog();
jobLog.setJobGroup(jobInfo.getJobGroup());
jobLog.setJobId(jobInfo.getId());
jobLog.setTriggerTime(new Date());
XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().save(jobLog);
logger.debug(">>>>>>>>>>> xxl-job trigger start, jobId:{}", jobLog.getId());
// 2、init trigger-param
TriggerParam triggerParam = new TriggerParam();
triggerParam.setJobId(jobInfo.getId());
triggerParam.setExecutorHandler(jobInfo.getExecutorHandler());
triggerParam.setExecutorParams(jobInfo.getExecutorParam());
triggerParam.setExecutorBlockStrategy(jobInfo.getExecutorBlockStrategy());
triggerParam.setExecutorTimeout(jobInfo.getExecutorTimeout());
triggerParam.setLogId(jobLog.getId());
triggerParam.setLogDateTime(jobLog.getTriggerTime().getTime());
triggerParam.setGlueType(jobInfo.getGlueType());
triggerParam.setGlueSource(jobInfo.getGlueSource());
triggerParam.setGlueUpdatetime(jobInfo.getGlueUpdatetime().getTime());
triggerParam.setBroadcastIndex(index);
triggerParam.setBroadcastTotal(total);
// 3、init address
String address = null;
ReturnT routeAddressResult = null;
if (group.getRegistryList()!=null && !group.getRegistryList().isEmpty()) {
if (ExecutorRouteStrategyEnum.SHARDING_BROADCAST == executorRouteStrategyEnum) {
if (index < group.getRegistryList().size()) {
address = group.getRegistryList().get(index);
} else {
address = group.getRegistryList().get(0);
}
} else {
// 根据不同路由策略获取执行器 ip 地址
routeAddressResult = executorRouteStrategyEnum.getRouter().route(triggerParam, group.getRegistryList());
if (routeAddressResult.getCode() == ReturnT.SUCCESS_CODE) {
address = routeAddressResult.getContent();
}
}
} else {
routeAddressResult = new ReturnT(ReturnT.FAIL_CODE, I18nUtil.getString("jobconf_trigger_address_empty"));
}
// 4、trigger remote executor
ReturnT triggerResult = null;
if (address != null) {
triggerResult = runExecutor(triggerParam, address);
} else {
triggerResult = new ReturnT(ReturnT.FAIL_CODE, null);
}
// 5、collection trigger info
StringBuffer triggerMsgSb = new StringBuffer();
triggerMsgSb.append(I18nUtil.getString("jobconf_trigger_type")).append(":").append(triggerType.getTitle());
triggerMsgSb.append("
").append(I18nUtil.getString("jobconf_trigger_admin_adress")).append(":").append(IpUtil.getIp());
triggerMsgSb.append("
").append(I18nUtil.getString("jobconf_trigger_exe_regtype")).append(":")
.append( (group.getAddressType() == 0)?I18nUtil.getString("jobgroup_field_addressType_0"):I18nUtil.getString("jobgroup_field_addressType_1") );
triggerMsgSb.append("
").append(I18nUtil.getString("jobconf_trigger_exe_regaddress")).append(":").append(group.getRegistryList());
triggerMsgSb.append("
").append(I18nUtil.getString("jobinfo_field_executorRouteStrategy")).append(":").append(executorRouteStrategyEnum.getTitle());
if (shardingParam != null) {
triggerMsgSb.append("("+shardingParam+")");
}
triggerMsgSb.append("
").append(I18nUtil.getString("jobinfo_field_executorBlockStrategy")).append(":").append(blockStrategy.getTitle());
triggerMsgSb.append("
").append(I18nUtil.getString("jobinfo_field_timeout")).append(":").append(jobInfo.getExecutorTimeout());
triggerMsgSb.append("
").append(I18nUtil.getString("jobinfo_field_executorFailRetryCount")).append(":").append(finalFailRetryCount);
triggerMsgSb.append("
>>>>>>>>>>>"+ I18nUtil.getString("jobconf_trigger_run") +"<<<<<<<<<<<
")
.append((routeAddressResult!=null&&routeAddressResult.getMsg()!=null)?routeAddressResult.getMsg()+"
":"").append(triggerResult.getMsg()!=null?triggerResult.getMsg():"");
// 6、save log trigger-info
jobLog.setExecutorAddress(address);
jobLog.setExecutorHandler(jobInfo.getExecutorHandler());
jobLog.setExecutorParam(jobInfo.getExecutorParam());
jobLog.setExecutorShardingParam(shardingParam);
jobLog.setExecutorFailRetryCount(finalFailRetryCount);
//jobLog.setTriggerTime();
jobLog.setTriggerCode(triggerResult.getCode());
jobLog.setTriggerMsg(triggerMsgSb.toString());
XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().updateTriggerInfo(jobLog);
logger.debug(">>>>>>>>>>> xxl-job trigger end, jobId:{}", jobLog.getId());
}
7.3 执行器接收并处理任务
执行器接收到调度中心的调度请求时,如果任务类型为 “Bean模式”,将会匹配 Spring 容器中的 “Bean模式任务”,然后调用其 execute 方法,执行任务逻辑。如果任务类型为 “GLUE模式”,将会加载 GLue 代码,实例化 Java 对象,注入依赖的 Spring 服务(注意:Glue代码中注入的Spring服务,必须存在与该“执行器”项目的Spring容器中),然后调用execute方法,执行任务逻辑。
7.3.1 EmbedServer 接收调度请求
EmbedHttpServerHandler 调用 channelRead0 方法处理任务调度请求,每个请求通过线程池 bizThreadPool 新开一个线程进行处理
@Override
protected void channelRead0(final ChannelHandlerContext ctx, FullHttpRequest msg) throws Exception {
// invoke
bizThreadPool.execute(new Runnable() {
@Override
public void run() {
// do invoke
Object responseObj = process(httpMethod, uri, requestData, accessTokenReq);
// to json
String responseJson = GsonTool.toJson(responseObj);
// write response
writeResponse(ctx, keepAlive, responseJson);
}
});
}
process 方法根据 uri 的不同取值调用 ExecutorBiz 不同的处理方法:
if ("/beat".equals(uri)) {
return executorBiz.beat();
} else if ("/idleBeat".equals(uri)) {
IdleBeatParam idleBeatParam = GsonTool.fromJson(requestData, IdleBeatParam.class);
return executorBiz.idleBeat(idleBeatParam);
} else if ("/run".equals(uri)) {
TriggerParam triggerParam = GsonTool.fromJson(requestData, TriggerParam.class);
return executorBiz.run(triggerParam);
} else if ("/kill".equals(uri)) {
KillParam killParam = GsonTool.fromJson(requestData, KillParam.class);
return executorBiz.kill(killParam);
} else if ("/log".equals(uri)) {
LogParam logParam = GsonTool.fromJson(requestData, LogParam.class);
return executorBiz.log(logParam);
} else {
return new ReturnT(ReturnT.FAIL_CODE, "invalid request, uri-mapping(" + uri + ") not found.");
}
7.3.2 ExecutorBiz(执行器单元)
ExecutorBiz#run(TriggerParam triggerParam) 方法处理任务请求,源码如下
public ReturnT run(TriggerParam triggerParam) {
// load old:jobHandler + jobThread
JobThread jobThread = XxlJobExecutor.loadJobThread(triggerParam.getJobId());
IJobHandler jobHandler = jobThread!=null?jobThread.getHandler():null;
String removeOldReason = null;
// valid:jobHandler + jobThread
// 1 根据任务模式(GlueTypeEnum)的不同进行不同的任务处理逻辑
GlueTypeEnum glueTypeEnum = GlueTypeEnum.match(triggerParam.getGlueType());
if (GlueTypeEnum.BEAN == glueTypeEnum) { // “Bean模式” 任务
// 根据 triggerParam.getExecutorHandler() 加载任务处理器,此处 triggerParam.getExecutorHandler() 等于 @XxlJob 注解中的 value 值
IJobHandler newJobHandler = XxlJobExecutor.loadJobHandler(triggerParam.getExecutorHandler());
// valid old jobThread
if (jobThread!=null && jobHandler != newJobHandler) {
// change handler, need kill old thread
removeOldReason = "change jobhandler or glue type, and terminate the old job thread.";
jobThread = null;
jobHandler = null;
}
// valid handler
if (jobHandler == null) {
jobHandler = newJobHandler;
if (jobHandler == null) {
return new ReturnT(ReturnT.FAIL_CODE, "job handler [" + triggerParam.getExecutorHandler() + "] not found.");
}
}
} else if (GlueTypeEnum.GLUE_GROOVY == glueTypeEnum) { // “GLUE模式(Java)” 任务
// valid old jobThread
if (jobThread != null &&
!(jobThread.getHandler() instanceof GlueJobHandler
&& ((GlueJobHandler) jobThread.getHandler()).getGlueUpdatetime()==triggerParam.getGlueUpdatetime() )) {
// change handler or gluesource updated, need kill old thread
removeOldReason = "change job source or glue type, and terminate the old job thread.";
jobThread = null;
jobHandler = null;
}
// valid handler
if (jobHandler == null) {
try {
IJobHandler originJobHandler = GlueFactory.getInstance().loadNewInstance(triggerParam.getGlueSource());
jobHandler = new GlueJobHandler(originJobHandler, triggerParam.getGlueUpdatetime());
} catch (Exception e) {
logger.error(e.getMessage(), e);
return new ReturnT(ReturnT.FAIL_CODE, e.getMessage());
}
}
} else if (glueTypeEnum!=null && glueTypeEnum.isScript()) { // 其他脚本模式任务
// valid old jobThread
if (jobThread != null &&
!(jobThread.getHandler() instanceof ScriptJobHandler
&& ((ScriptJobHandler) jobThread.getHandler()).getGlueUpdatetime()==triggerParam.getGlueUpdatetime() )) {
// change script or gluesource updated, need kill old thread
removeOldReason = "change job source or glue type, and terminate the old job thread.";
jobThread = null;
jobHandler = null;
}
// valid handler
if (jobHandler == null) {
jobHandler = new ScriptJobHandler(triggerParam.getJobId(), triggerParam.getGlueUpdatetime(), triggerParam.getGlueSource(), GlueTypeEnum.match(triggerParam.getGlueType()));
}
} else {
return new ReturnT(ReturnT.FAIL_CODE, "glueType[" + triggerParam.getGlueType() + "] is not valid.");
}
// 2 处理不同的阻塞策略
if (jobThread != null) {
ExecutorBlockStrategyEnum blockStrategy = ExecutorBlockStrategyEnum.match(triggerParam.getExecutorBlockStrategy(), null);
// 丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败
if (ExecutorBlockStrategyEnum.DISCARD_LATER == blockStrategy) {
// discard when running
if (jobThread.isRunningOrHasQueue()) {
return new ReturnT(ReturnT.FAIL_CODE, "block strategy effect:"+ExecutorBlockStrategyEnum.DISCARD_LATER.getTitle());
}
} else if (ExecutorBlockStrategyEnum.COVER_EARLY == blockStrategy) { // 覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务
// kill running jobThread
if (jobThread.isRunningOrHasQueue()) {
removeOldReason = "block strategy effect:" + ExecutorBlockStrategyEnum.COVER_EARLY.getTitle();
jobThread = null;
}
} else {
// just queue trigger
}
}
// 新建或替换任务已有的 jobHandler
if (jobThread == null) {
jobThread = XxlJobExecutor.registJobThread(triggerParam.getJobId(), jobHandler, removeOldReason);
}
// 3 将调度请求直接放入 jobThread 的触发队列进行异步处理
ReturnT pushResult = jobThread.pushTriggerQueue(triggerParam);
return pushResult;
}
run() 方法主要做了以下几件事:
-
根据任务模式(GlueTypeEnum)的不同进行不同的任务处理逻辑
-
Bean模式
每个Bean模式任务都是一个Spring的Bean类实例,它被维护在“执行器”项目的Spring容器中。任务类需要加“@JobHandler(value=”名称”)”注解,因为“执行器”会根据该注解识别Spring容器中的任务。任务类需要继承统一接口“IJobHandler”,任务逻辑在execute方法中开发,因为“执行器”在接收到调度中心的调度请求时,将会调用“IJobHandler”的execute方法,执行任务逻辑
-
GLUE模式(Java)
每个 “GLUE模式(Java)” 任务的代码,实际上是“一个继承自“IJobHandler”的实现类的类代码”,“执行器”接收到“调度中心”的调度请求时,会通过Groovy类加载器加载此代码,实例化成Java对象,同时注入此代码中声明的Spring服务(请确保Glue代码中的服务和类引用在“执行器”项目中存在),然后调用该对象的execute方法,执行任务逻辑
-
其他脚本任务
脚本任务的源码托管在调度中心,脚本逻辑在执行器运行。当触发脚本任务时,执行器会加载脚本源码在执行器机器上生成一份脚本文件,然后通过Java代码调用该脚本;并且实时将脚本输出日志写到任务日志文件中,从而在调度中心可以实时监控脚本运行情况
-
-
根据 blockStrategy 处理不同的阻塞策略
- 丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败
- 覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务
if (ExecutorBlockStrategyEnum.DISCARD_LATER == blockStrategy) { /* 丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败 */ if (jobThread.isRunningOrHasQueue()) { return new ReturnT(ReturnT.FAIL_CODE, "block strategy effect:"+ExecutorBlockStrategyEnum.DISCARD_LATER.getTitle()); } } else if (ExecutorBlockStrategyEnum.COVER_EARLY == blockStrategy) { /* 覆盖之前调度:若当前任务的处理线程(jobThread)有正在运行的任务或调度请求队列不为空,则清空当前任务处理线程 然后创建一个新的 jobThread 处理当前调度请求 */ if (jobThread.isRunningOrHasQueue()) { removeOldReason = "block strategy effect:" + ExecutorBlockStrategyEnum.COVER_EARLY.getTitle(); jobThread = null; } } else { // just queue trigger } if (jobThread == null) { // registJobThread 创建新的任务处理进程并将已存在的任务处理进程清除 jobThread = XxlJobExecutor.registJobThread(triggerParam.getJobId(), jobHandler, removeOldReason); } -
将调度请求放入 JobThread 的阻塞队列 triggerQueue,等待后续处理
ReturnTpushResult = jobThread.pushTriggerQueue(triggerParam); LinkedBlockingQueue triggerQueue public ReturnT pushTriggerQueue(TriggerParam triggerParam) { // avoid repeat if (triggerLogIdSet.contains(triggerParam.getLogId())) { logger.info(">>>>>>>>>>> repeate trigger job, logId:{}", triggerParam.getLogId()); return new ReturnT (ReturnT.FAIL_CODE, "repeate trigger job, logId:" + triggerParam.getLogId()); } // avoid repeat trigger for the same TRIGGER_LOG_ID triggerLogIdSet.add(triggerParam.getLogId()); triggerQueue.add(triggerParam); return ReturnT.SUCCESS; } JobThread 通过 run() 方法循环处理请求,具体处理细节参见下节 7.3.4 JobThread:任务处理线程
7.3.4 JobThread(任务处理线程)
public void run() {
// init
handler.init();
// 1 从阻塞队列获取调度请求并处理
while(!toStop){
// to check toStop signal, we need cycle, so wo cannot use queue.take(), instand of poll(timeout)
TriggerParam triggerParam = triggerQueue.poll(3L, TimeUnit.SECONDS);
// execute
XxlJobLogger.log("
----------- xxl-job job execute start -----------
----------- Param:" + triggerParam.getExecutorParams());
// 若任务设置超时时间,则在限定时间内异步获取执行结果
if (triggerParam.getExecutorTimeout() > 0) {
// limit timeout
final TriggerParam triggerParamTmp = triggerParam;
FutureTask> futureTask = new FutureTask>(new Callable>() {
@Override
public ReturnT call() throws Exception {
return handler.execute(triggerParamTmp.getExecutorParams());
}
});
futureThread = new Thread(futureTask);
futureThread.start();
// 异步获取执行结果
executeResult = futureTask.get(triggerParam.getExecutorTimeout(), TimeUnit.SECONDS);
} else {
// 若没有设置超时时间,则同步获取任务执行结果
executeResult = handler.execute(triggerParam.getExecutorParams());
}
if (executeResult == null) {
executeResult = IJobHandler.FAIL;
} else {
executeResult.setMsg(
(executeResult!=null&&executeResult.getMsg()!=null&&executeResult.getMsg().length()>50000)
?executeResult.getMsg().substring(0, 50000).concat("...")
:executeResult.getMsg());
executeResult.setContent(null); // limit obj size
}
XxlJobLogger.log("
----------- xxl-job job execute end(finish) -----------
----------- ReturnT:" + executeResult);
// 2 任务处理结果回调
if(triggerParam != null) {
// callback handler info
if (!toStop) {
// commonm
TriggerCallbackThread.pushCallBack(new HandleCallbackParam(triggerParam.getLogId(), triggerParam.getLogDateTime(), executeResult));
} else {
// is killed
ReturnT stopResult = new ReturnT(ReturnT.FAIL_CODE, stopReason + " [job running, killed]");
TriggerCallbackThread.pushCallBack(new HandleCallbackParam(triggerParam.getLogId(), triggerParam.getLogDateTime(), stopResult));
}
}
}
// 3 任务处理进行被杀死,队列中剩余的调度请求进行失败处理,并回调任务处理结果
while(triggerQueue !=null && triggerQueue.size()>0){
TriggerParam triggerParam = triggerQueue.poll();
if (triggerParam!=null) {
// is killed
ReturnT stopResult = new ReturnT(ReturnT.FAIL_CODE, stopReason + " [job not executed, in the job queue, killed.]");
TriggerCallbackThread.pushCallBack(new HandleCallbackParam(triggerParam.getLogId(), triggerParam.getLogDateTime(), stopResult));
}
}
// destroy
handler.destroy();
}
run() 方法主要做了以下几件事:
-
从阻塞队列获取调度请求并处理
// to check toStop signal, we need cycle, so wo cannot use queue.take(), instand of poll(timeout) TriggerParam triggerParam = triggerQueue.poll(3L, TimeUnit.SECONDS); // 若任务设置超时时间,则在限定时间内异步获取执行结果 if (triggerParam.getExecutorTimeout() > 0) { // limit timeout final TriggerParam triggerParamTmp = triggerParam; FutureTaskcall() throws Exception { return handler.execute(triggerParamTmp.getExecutorParams()); } }); futureThread = new Thread(futureTask); futureThread.start(); // 异步获取执行结果 executeResult = futureTask.get(triggerParam.getExecutorTimeout(), TimeUnit.SECONDS); } else { // 若没有设置超时时间,则同步获取任务执行结果 executeResult = handler.execute(triggerParam.getExecutorParams()); } -
任务处理结果回调
if (!toStop) { // commonm TriggerCallbackThread.pushCallBack(new HandleCallbackParam(triggerParam.getLogId(), triggerParam.getLogDateTime(), executeResult)); } else { // is killed ReturnTstopResult = new ReturnT (ReturnT.FAIL_CODE, stopReason + " [job running, killed]"); TriggerCallbackThread.pushCallBack(new HandleCallbackParam(triggerParam.getLogId(), triggerParam.getLogDateTime(), stopResult)); } 将任务执行结果 executeResult 放入 TriggerCallbackThread 的任务结果队列 callBackQueue
/** * job results callback queue */ private LinkedBlockingQueuecallBackQueue = new LinkedBlockingQueue (); public static void pushCallBack(HandleCallbackParam callback){ getInstance().callBackQueue.add(callback); } TriggerCallbackThread 创建 triggerCallbackThread 线程从 callBackQueue 中获取 executeResult 并将其以 HTTP POST 形式发送给调度中心,核心处理方法见 doCallback()
private void doCallback(ListcallbackParamList){ // callback, will retry if error for (AdminBiz adminBiz: XxlJobExecutor.getAdminBizList()) { ReturnT callbackResult = adminBiz.callback(callbackParamList); } } public ReturnT callback(List callbackParamList) { return XxlJobRemotingUtil.postBody(addressUrl+"api/callback", accessToken, timeout, callbackParamList, String.class); } 调度中心获取任务结果参数后,调用AdminBizImpl#callback(com.xxl.job.core.biz.model.HandleCallbackParam) 方法进行处理
private ReturnTcallback(HandleCallbackParam handleCallbackParam) { // valid log item XxlJobLog log = xxlJobLogDao.load(handleCallbackParam.getLogId()); } // trigger success, to trigger child job String callbackMsg = null; if (IJobHandler.SUCCESS.getCode() == handleCallbackParam.getExecuteResult().getCode()) { XxlJobInfo xxlJobInfo = xxlJobInfoDao.loadById(log.getJobId()); if (xxlJobInfo!=null && xxlJobInfo.getChildJobId()!=null && xxlJobInfo.getChildJobId().trim().length()>0) { callbackMsg = "
>>>>>>>>>>>"+ I18nUtil.getString("jobconf_trigger_child_run") +"<<<<<<<<<<<
"; String[] childJobIds = xxlJobInfo.getChildJobId().split(","); for (int i = 0; i < childJobIds.length; i++) { int childJobId = (childJobIds[i]!=null && childJobIds[i].trim().length()>0 && isNumeric(childJobIds[i]))?Integer.valueOf(childJobIds[i]):-1; if (childJobId > 0) { JobTriggerPoolHelper.trigger(childJobId, TriggerTypeEnum.PARENT, -1, null, null, null); ReturnTtriggerChildResult = ReturnT.SUCCESS; // add msg callbackMsg += MessageFormat.format(I18nUtil.getString("jobconf_callback_child_msg1"), (i+1), childJobIds.length, childJobIds[i], (triggerChildResult.getCode()==ReturnT.SUCCESS_CODE?I18nUtil.getString("system_success"):I18nUtil.getString("system_fail")), triggerChildResult.getMsg()); } else { callbackMsg += MessageFormat.format(I18nUtil.getString("jobconf_callback_child_msg2"), (i+1), childJobIds.length, childJobIds[i]); } } } } // handle msg StringBuffer handleMsg = new StringBuffer(); if (log.getHandleMsg()!=null) { handleMsg.append(log.getHandleMsg()).append("
"); } if (handleCallbackParam.getExecuteResult().getMsg() != null) { handleMsg.append(handleCallbackParam.getExecuteResult().getMsg()); } if (callbackMsg != null) { handleMsg.append(callbackMsg); } if (handleMsg.length() > 15000) { handleMsg = new StringBuffer(handleMsg.substring(0, 15000)); // text最大64kb 避免长度过长 } // success, save log log.setHandleTime(new Date()); log.setHandleCode(handleCallbackParam.getExecuteResult().getCode()); log.setHandleMsg(handleMsg.toString()); xxlJobLogDao.updateHandleInfo(log); return ReturnT.SUCCESS; } -
JobThread 停止后处理队列遗留调度请求
while(triggerQueue !=null && triggerQueue.size()>0){ TriggerParam triggerParam = triggerQueue.poll(); if (triggerParam!=null) { // is killed ReturnTstopResult = new ReturnT (ReturnT.FAIL_CODE, stopReason + " [job not executed, in the job queue, killed.]"); TriggerCallbackThread.pushCallBack(new HandleCallbackParam(triggerParam.getLogId(), triggerParam.getLogDateTime(), stopResult)); } }
7.3.5 IJobHandler(任务单元)
public abstract class IJobHandler {
/** success */
public static final ReturnT SUCCESS = new ReturnT(200, null);
/** fail */
public static final ReturnT FAIL = new ReturnT(500, null);
/** fail timeout */
public static final ReturnT FAIL_TIMEOUT = new ReturnT(502, null);
/**
* execute handler, invoked when executor receives a scheduling request
*
* @param param
* @return
* @throws Exception
*/
public abstract ReturnT execute(String param) throws Exception;
/**
* init handler, invoked when JobThread init
*/
public void init() throws InvocationTargetException, IllegalAccessException {
// do something
}
/**
* destroy handler, invoked when JobThread destroy
*/
public void destroy() throws InvocationTargetException, IllegalAccessException {
// do something
}
}
IJobHandler 有四个实现类:
MethodJobHandler:负责处理 BEAN 模式的任务
GlueJobHandler:负责处理 Glue 模式的任务
ScriptJobHandler:负责处理脚本模式的任务
CommandJobHandler:负责处理命令行任务
7.4 心跳检测
任务注册 Beat 周期默认30s
执行器以一倍 Beat 进行执行器注册
调度中心以一倍 Beat 进行动态任务发现
执行器注册信息的失效时间为三倍 Beat
执行器销毁,主动上报调度中心并摘除对应的执行器机器信息
八 XXL-JOB 改造
8.1 自动装配
8.1.1 XxlJobAutoConfigure
XxlJobAutoConfigure 自动装配 XxlJobSpringExecutor 到项目的 Spring 容器中
/**
* matchIfMissing 属性为true时,配置文件中缺少对应的value或name的对应的属性值,也会注入成功
*/
@Configuration
@EnableConfigurationProperties(XxlJobSpringExecutorProperties.class)
@ConditionalOnClass(XxlJobSpringExecutor.class)
@ConditionalOnProperty(prefix = "xxl-job", value = "enabled", matchIfMissing = true)
public class XxlJobAutoConfigure {
private static Logger LOGGER = LoggerFactory.getLogger(XxlJobAutoConfigure.class);
@Autowired
private XxlJobSpringExecutorProperties properties;
@Bean
@ConditionalOnMissingBean(XxlJobSpringExecutor.class)
public XxlJobSpringExecutor xxlJobExecutor() {
LOGGER.info(">>>>>>>>>>> xxl-job config auto init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(properties.getAdmin().getAddresses());
xxlJobSpringExecutor.setAppname(properties.getExecutor().getAppname());
xxlJobSpringExecutor.setAddress(properties.getExecutor().getAddress());
xxlJobSpringExecutor.setIp(properties.getExecutor().getIp());
xxlJobSpringExecutor.setPort(properties.getExecutor().getPort());
xxlJobSpringExecutor.setAccessToken(properties.getAccessToken());
xxlJobSpringExecutor.setLogPath(properties.getExecutor().getLogPath());
xxlJobSpringExecutor.setLogRetentionDays(properties.getExecutor().getLogRetentionDays());
xxlJobSpringExecutor.setApplicationContext(SpringUtils.getApplicationContext());
LOGGER.info(">>>>>>>>>>> XxlJobSpringExecutor: {}", xxlJobSpringExecutor.toString());
LOGGER.info(">>>>>>>>>>> xxl-job config auto init end.");
return xxlJobSpringExecutor;
}
}
8.1.2 XxlJobSpringExecutorProperties
XxlJobSpringExecutor 的属性全部放在 XxlJobSpringExecutorProperties 中
@ConfigurationProperties(prefix = "xxl-job")
public class XxlJobSpringExecutorProperties {
private String accessToken;
@NestedConfigurationProperty
private Admin admin = new Admin();
@NestedConfigurationProperty
private Executor executor = new Executor();
public String getAccessToken() {
return accessToken;
}
public void setAccessToken(String accessToken) {
this.accessToken = accessToken;
}
public Admin getAdmin() {
return admin;
}
public void setAdmin(Admin admin) {
this.admin = admin;
}
public Executor getExecutor() {
return executor;
}
public void setExecutor(Executor executor) {
this.executor = executor;
}
public static class Admin {
private String addresses;
public String getAddresses() {
return addresses;
}
public void setAddresses(String addresses) {
this.addresses = addresses;
}
}
public static class Executor {
private String appname;
private String address;
private String ip;
private int port;
private String logPath;
private int logRetentionDays;
public String getAppname() {
return appname;
}
public void setAppname(String appname) {
this.appname = appname;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public String getIp() {
return ip;
}
public void setIp(String ip) {
this.ip = ip;
}
public int getPort() {
return port;
}
public void setPort(int port) {
this.port = port;
}
public String getLogPath() {
return logPath;
}
public void setLogPath(String logPath) {
this.logPath = logPath;
}
public int getLogRetentionDays() {
return logRetentionDays;
}
public void setLogRetentionDays(int logRetentionDays) {
this.logRetentionDays = logRetentionDays;
}
}
}
8.1.3 配置 spring.factories
在项目的 resources\META-INF 目录新建 spring.factories 文件,并配置自动配置类 XxlJobAutoConfigure
org.springframework.boot.autoconfigure.EnableAutoConfiguration = com.xxl.job.core.properties.auto.configure.XxlJobAutoConfigure
8.2 集成 spring-session
8.2.1 引入 spring-session 相关依赖
org.springframework.session
spring-session-bom
Corn-SR2
pom
import
org.springframework.session
spring-session-core
org.springframework.session
spring-session-data-redis
org.springframework.boot
spring-boot-starter-data-redis
2.3.1.RELEASE
8.2.2 添加相关配置
在 application.properties 文件中添加一下配置
# spring session
## equivalent to manually adding @EnableRedisHttpSession annotation
spring.session.store-type=redis
## flush-mode 有两个参数:ON_SAVE(表示在response commit前刷新缓存),IMMEDIATE(表示只要有更新,就刷新缓存)
spring.session.redis.flush-mode=on_save
## 添加后,redis中的key为spring:session:xxl-job
spring.session.redis.namespace=xxl-job
# redis config
## Redis server host.
## Redis 要开启事件通知 redis-cli config set notify-keyspace-events Egx
spring.redis.host=192.168.99.100
## Login password of the redis server.
spring.redis.password=
## Redis server port.
spring.redis.port=16379
8.2.3 使用 HttpSession 进行逻辑处理
略
九 XXL-JOB 部署
| 环境 | QA | PP | P |
|---|---|---|---|
| 基础设施 | Linux 服务器(内置 Java 环境)—— 1 台,金桥 k8s | Linux 服务器(内置 Java 环境)—— 1 台 金桥 k8s | Linux 服务器(内置 Java 环境)—— 2 台 金桥 k8s |
| 中间件 | MySQL(主从) Redis 集群(单例) |
MySQL(主从) Redis 集群(单例) |
MySQL 主从 Redis 集群 |
| 其他 | 内网域名 | 内网域名 | 内网域名 |
附录
Cron 表达式
Cron表达式是一个字符串,字符串以5或6个空格隔开,分为6或7个域,每一个域代表一个含义,Cron有如下两种语法格式:
- Seconds Minutes Hours DayofMonth Month DayofWeek Year
- Seconds Minutes Hours DayofMonth Month DayofWeek
结构
corn 从左到右(用空格隔开):秒 分 小时 月份中的日期 月份 星期中的日期 年份
字段含义
| 字段 | 允许值 | 允许的特殊字符 |
|---|---|---|
| 秒(Seconds) | 0~59的整数 | , - * / 四个字符 |
| 分(Minutes) | 0~59的整数 | , - * / 四个字符 |
| 小时(Hours) | 0~23的整数 | , - * / 四个字符 |
| 日期(DayofMonth) | 1~31的整数(但是你需要考虑你月的天数) | ,- * ? / L W C 八个字符 |
| 月份(Month) | 1~12的整数或者 JAN-DEC | , - * / 四个字符 |
| 星期(DayofWeek) | 1~7的整数或者 SUN-SAT (1=SUN) | , - * ? / L C # 八个字符 |
| 年(可选,留空)(Year) | 1970~2099 | , - * / 四个字符 |
每一个域都使用数字,但还可以出现如下特殊字符,它们的含义是:
* :表示匹配该域的任意值。假如在Minutes域使用*, 即表示每分钟都会触发事件
? :只能用在DayofMonth和DayofWeek两个域。它也匹配域的任意值,但实际不会。因为DayofMonth和DayofWeek会相互影响。例如想在每月的20日触发调度,不管20日到底是星期几,则只能使用如下写法: 13 13 15 20 * ?, 其中最后一位只能用?,而不能使用*,如果使用*表示不管星期几都会触发,实际上并不是这样
- :表示范围。例如在Minutes域使用5-20,表示从5分到20分钟每分钟触发一次
/ :表示起始时间开始触发,然后每隔固定时间触发一次。例如在Minutes域使用5/20,则意味着5分钟触发一次,而25,45等分别触发一次
, :表示列出枚举值。例如:在Minutes域使用5,20,则意味着在5和20分每分钟触发一次
L :表示最后,只能出现在DayofWeek和DayofMonth域。如果在DayofWeek域使用5L,意味着在最后的一个星期四触发
W :表示有效工作日(周一到周五),只能出现在DayofMonth域,系统将在离指定日期的最近的有效工作日触发事件。例如:在 DayofMonth使用5W,如果5日是星期六,则将在最近的工作日:星期五,即4日触发。如果5日是星期天,则在6日(周一)触发;如果5日在星期一到星期五中的一天,则就在5日触发。另外一点,W的最近寻找不会跨过月份
LW :这两个字符可以连用,表示在某个月最后一个工作日,即最后一个星期五
# :用于确定每个月第几个星期几,只能出现在DayofMonth域。例如在4#2,表示某月的第二个星期三