金融领域一直是计算机算法革新发展的前沿领域,机器学习正在对金融服务业产生重大影响,但前提是了解机器学习算法的优势和局限性,以及适合在金融领域发挥作用的场景。当我们在金融业务中使用机器学习算法,期望通过可度量的方法对模型结果进行分析,以对算法进行优化,以及对业务进行方向性的指导,确保模型与要解决的业务问题保持一致。即模型解释性分析。模型的解释性分析可帮助模型开发人员了解并解释模型中包含和未包含的特征因素,以及特征如何影响模型结果。
本文以跨境交易中的交易类型监测为例,通过分析交易样本数据,选择适当模型,并多维度对模型的结果进行解释性分析。
模型解释性
广义上,模型的解释性分析目的是全局定义特征对模型的影响,同时定义单个特征对模型的个性化影响;更好的理解模型行为,更好的进行相应的业务决策;
通常对机器学习模型分为以下两大类:
“白盒”模型:
如线性、Logistic 回归模型,预测能力较弱,但是简单易理解,例如,线性关系如房价与房屋面积、位置、城市的相关性;
如决策树是目前业内公认可解释性最好的非线性机器学习算法,模型每作出一个决策都会通过一个决策序列来向我们展示模型的决策依据,决策树模型自带的基于信息理论的筛选变量标准也有助于帮助我们理解在模型决策产生的过程中哪些变量起到了显著的作用;
白盒模型特征明确,逻辑简单,本身具备可解释性。
“黑盒”模型:
使用‘复杂’的机器学习算法训练数据,输入特征进过组合变换,维度上升等特征工程步骤,需要分析及调整数据与模型,确保模型结果与要解决的问题保持一致;然而这些模型的内部机制难以理解,也无法估计每个特征对模型预测结果的重要性以解释模型结果与输入的特征属性潜在的关联关系,更无法直接理解不同特征之间如何相互工作(数据的相关性不等价于因果关系);
针对本例中的交易数据,通过分析数据样本,并对比多组算法(训练& 预测结果分析),以实现有效的交易类型判别;
交易监测数据集
跨境交易中,用户需填报当笔交易的交易类型(BOP 国标分类),但在很多场景,客户可能将交易类型填报错误,已达到非法获利的可能,业务上,可以通过大量的历史交易数据进行机器学习模型拟合,判别交易类型,结合业务经验及历史风险事件的总结(规则),形成交易监测规则引擎,实现完备的风险管控。
数据分析
基本特征选取
分析跨境交易相关数据,分析数据潜在关联,数据源为交易及客户信息表,列数合计约220 ,分析数据潜在关联,去除其中客户信息标识列(如客户号,账户及账户关联标识列)、去除空值率过高列、系统相关记录列、重复列、及与明显与交易无业务相关列,人工(根据业务经验)挑选出有业务意义的特征,约 45 列。
统计特征
为更好的拟合交易类型模型预测,进一步扩充时间与空间维度交易统计特征,如:相应period (年 / 半年 / 季度 / 月 / 周)内客户交易数及交易金额总数。
特征选择
根据人工选择及统计特征,通过算法模型自动选择最优特征数,如交易渠道、客户经营范围、对公客户所属行业、客户类型等等。进一步分析人工初选的特征属性后可知:离散型特征占比约90% ;预测分类类别存在严重不平衡情况。

横轴1-9 分别为国标交易类别 BOP 的 9 大类,依次代表: 货物贸易、服务贸易、初次收入-收益、二次收入-经常转移、资本账户、直接投资、证券投资及金融衍生工具、其他投资、境内外汇收支交易 ;纵轴为相应类别样本个数;由图可知,训练样本~85%集中在2类,~95%只集中在4类,样本类型的不平衡,将导致量少的分类所包含的特征过少,很难从中提取规律,容易产生过度依赖,有限的样本数据导致过拟合问题,当训练好的模型应用到新的数据中,模型的准确性将很差。
样本不平衡的解决办法有欠采样和过采样,欠采样通过减少多数样本的数量来实现样本均衡,但可能会丢失掉很多用户的交易消息,并且客户的交易数据量不够巨大,因此采用过采样解决样本的不平衡。SMOTE(Synthetic Minority Over-sampling Technique)(扩充小类,产生新数据)即该算法构造的数据是新样本,原数据集中不存在的。该基于距离度量选择小类别下两个或者更多的相似样本,然后选择其中一个样本,并随机选择一定数量的邻居样本对选择的那个样本的一个属性增加噪声,每次处理一个属性。这样就构造了更多的新生数据。
(优点是相当于合理地对小样本的分类平面进行的一定程度的外扩;也相当于对小类错分进行加权惩罚)采用过采样Over-Samping算法SMOTE平衡训练样本。
如下图:

注:已有数据的类别个数严重不平衡,将继续考察生产线数据,以提高模型拟合优化
模型分析对比:LR vs XGBoost vs LightGBM
模型选择与业务数据特点息息相关,通过以上的数据分析,本文尝试使用不同种模型对交易数据样本进行训练分析,从模型的准确率,召回率等评估指标,以及模型训练性能等方面选择最终上线模型。
LR (具备可解释性)
LR 是一种对数线性模型,通常作为分类模型的 Benchmark ,容易使用,同时具备数据快速拟合和模型解释度,但是准确率不高。特征在正负类出现概率的比值满足线性条件(线性拟合比值率),特征的权重可以看到不同的特征对最后结果的影响,某个特征的权重值比较高,那么这个特征最后对结果的影响会比较大。
交易数据Samples 的运行结果:

上图为LR 训练评估结果 metrics ,两行分别为 SMOTE 过采样数据和原始样本数据的评估度量结果,可知 SMOTE 过采样至样本平衡后,样本拟合的准确率和其他评估参数均有一定提升。
XGBoost
多分类算法主要有Boosting, 提升 Boosting 算法是一种基于一些基础分类器的组合分类模型算法, XGBoost是最活跃的 Boosting 提升算法,LightGBM 是个快速,高性能的基于决策树算法的梯度提升框架。通过交易及客户基本信息数据学习模型,预测一条交易数据中的交易类型可信度,作为 交易预警的重要依据;对比常见分类模型算法,并结合实践数据适配模型并对训练参数进行优化。

针对XGBoost模型,对离散型特征使用 OneHot 编码后特征稀疏,每个样本的特征信息都不太全,同时类别维度高,可能会导致切分不平衡,树模型更擅长有序连续性特征拟合;XGBoost训练时:
1 )每轮迭代时,都需要遍历整个训练数据多次。如果把整个训练数据装进内存则会限制训练数据的大小;如果不装进内存,反复地读写训练数据又会消耗非常大的时间;
2 )预排序方法的时间和空间的消耗都很大;
本项目中90% 的特征是离散值特征,在 XGBoost模型训练中,对离散型特征均进行了 One-Hot 编码,使得样本特征出现一定程度的稀疏。xgboost建树方式对当前层的所有叶子节点一视同仁,有些叶子节点分裂收益非常小,对结果没影响,但还是要分裂,加重了计算代价,这也是稀疏性带来的问题之一。
引自xgboost原作者:
xgboost treat every input feature as numerical, with support for missing values and sparsity. The decision is at the user So if you want ordered variables, you can transform the variables into numerical levels(say age). Or if you prefer treat it as categorical variable, do one hot encoding.
One-hot encoding could be helpful when the number of categories are small( in level of 10 to 100). In such case one-hot encoding can discover interesting interactions like (gender=male) AND (job = teacher).
While ordering them makes it harder to be discovered(need two split on job). However, indeed there is not a unified way handling categorical features in trees, and usually what tree was really good at was ordered continuous features anyway.. .
得出结论:
a) 将类别特征做成有序类别型特征将会增加模型学习难度;
b) 树模型并没有统一的规则来解决类别型特征,更擅长有序的连续型特征;
XGBoost模型训练评估结果如下:

分析xgboost算法及训练结果可知,在样本量不充足,离散特征居多的情况,模型预测准确率不够,同时内存使用较高,迭代时间也相对耗时(单机),进一步尝试其他改进算法训练已有的业务样本数据。
LightGBM 的优势
LightGBM 是XGBoost的改进版,包括在效率和内存上的提升,LightGBM 支持直接输入离散特征,无需 OneHot 处理,避免特征稀疏导致决策节点切分不平衡;按直方图统计算法分裂,可根据类别特征寻找最优切分。(低内存,高效率)
通过特征工程:特征转换,特征组合,特征选择,特征降维抽取,通过GridSearchCV 窗口优化模型参数, LightGBM 评估结果 Metrics :

同样的样本数据,LightGBM 训练时间缩短了近 10 倍,同时内存使用量减少了 7 倍左右,评分结果也更高,拟合度更好。本案将以 LightGBM 模型训练交易数据,以对交易类型进行拟合分类,并从不同维度解释分析模型结果。
交易检测模型的解释方法
对LightGBM 模型结果解释将分以下几个方法来分析,通过不同算法各个维度计算并判定特征如何影响模型。
特征重要度(训练模型)
从两个角度分析LightGBM模型训练结果特征重要度,分别为“特征收益重要性”和“特征分裂重要性”;特征收益重要性指特征分类的平均训练损失的减少量,意味着相应的特征对模型的相对贡献值;特征分裂重要性是指训练样本决策分裂的次数,两者从不同维度度量不同特征在模型训练中的重要性;
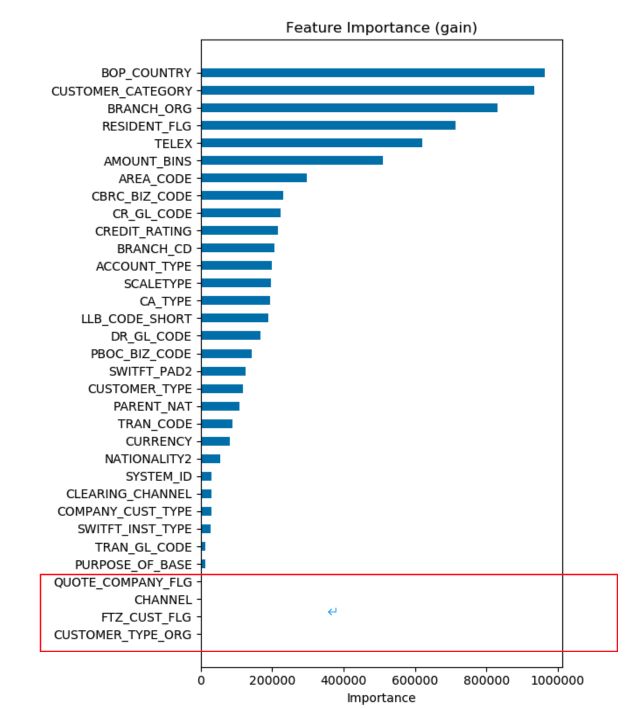

结论:由以上两个特征重要度图可知,树决策模型不同指标的特征重要性并不一致,可以大体看出哪些维度的数据影响到交易类型的预测,但是这些因素与交易类型是正相关,负相关,还是其他复杂相关性,从特征重要性图中并不清晰,因此还需其他分析方法。
注: 图中红色框中有部分特征在模型中特征重要值为0 ,将根据上线数据进行调整为准。
SHAP 解释分析
简述:( 针对特征重要度的不一致性问题提出 )
模型训练结果的特征重要度分析无法解读每个特征对每个个体的预测值的影响,同时,SHAP value 最大的优势是 SHAP 能对于反映出每一个样本中的特征的影响力,而且还表现出影响的正负性。
全局性分析 :保证全局一致性(全局一致性表示每当我们更改模型以使其更依赖于某个特征时,该特征的归因重要性不降低)
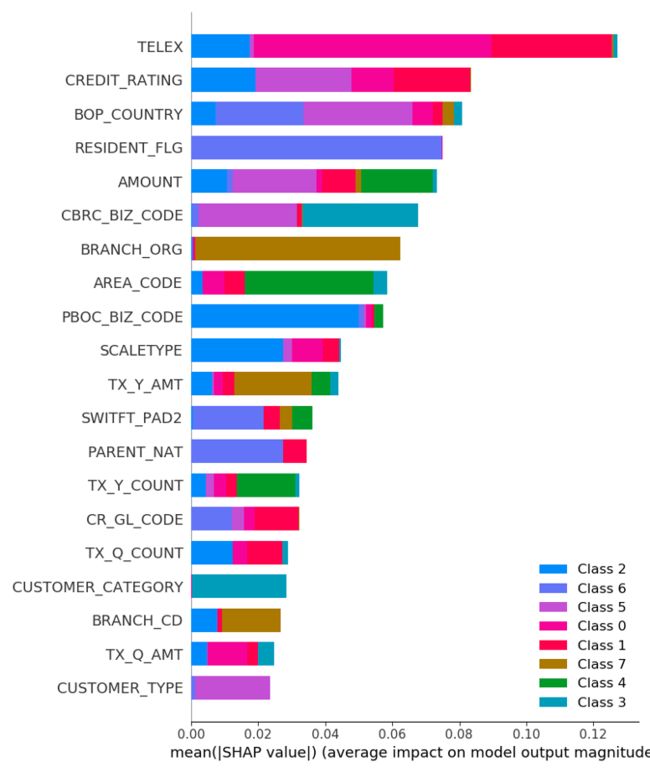
全局统计图:由于SHAP 值保证了一致性,因此我们无需担心在使用增益或拆分计数方法时发现的各种矛盾;各个分类的解释如下:

上图为密度散点图:散点聚集越密集表示样本表现力越大,散点集中在右侧代表对模型预测贡献越大(颜色变化代表特征值变化- 特征值进过编码),如上文所述,当前模型为多分类,本文散点图以其中一个分类为例进行分析。
图中每个散点代表一条样本数据,TELEX,CREDIT_RATING等均为离散型分类特征,模型训练前经过标签编码-LabelEncoder,散点图中,不同颜色代表不同的特征标签编码值。
由图可知,TELEX在增益特征值与分裂特征影响力均非最高影响力,但在SHAP分析中,确是全局最重要的特征。TELEX特征值越低,对当前分类的影响越大,即增加了模型判定样本为当前分类的机会;CREDIT_RATING特征值越高,则降低了判定为当前样本类别的机会(推测:当前贸易类型的CREDIT_RATING值较小)。
注意:图中的特征值是LabelEncoder的值,并非原始样本特征的数值。
Partial Dependency Plots(PDP)
独立特征分析
我们通过特征重要度得知某个特征对模型的影响度,以及用SHAP来评估 全局特征重要性;但如何评估某个单独的特征,尝试通过 PDP 来评估独立特征,展示单个特征对于模型预测的边际效益,单个特征是如何影响预测的,通过绘制特征和预测目标之间的一维关系图或二维关系图来了解特征与目标之间的关系。多个特征的复杂性,通过单个特征分析,进一步验证单个特征对模型的影响度。


上图以分析特征“TELEX”和“CREDIT_RATING”为例(注意这里是2个PDP,PDP假定每一个特征都是独立的,每一个图都是假定其它特征不变的情况下的趋势),对第一个贸易类型类别(如本文中编码class 0),TELEX编码值越靠后,交易为class 0类别的可能性越高,可以查找对应的TELEX,看是否本类别的交易倾向于TELEX为中间值;CREDIT_RATING编码值为中间值域时,贸易类别为class 0的几率会更高,同时值域越大,为class 0贸易类别的概率小,虽然蓝色区域越大,代表这种可能性不太准确,但依然有这种趋势。
LIME
简述:局部特征信息,通过检测局部输入对模型结果的影响以确定哪些对模型有影响,可以适配任何模型,不深入模型,而是打乱输入,将输入值在其周围做微小的扰动来检测预测行为变化(生成局部线性模型,线性模型具备良好的解释性),通过一个简单的模型局部地(在我们想要解释的预测的附近)逼近一个黑箱模型比全局地逼近这个模型要容易得多,LIME通过线性模型结果来解释高复杂度模型结果;
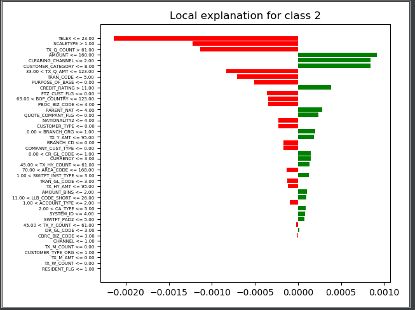
上图中,TELEX,SCALETYPE,TX_Q_COUNT的局部特征值,对当前分类是负相关影响。
注:模型上线前,还需对线上的交易数据进行进一步清洗,确认线上数据的完整性,特征的有效性等。
经验教训和结论
机器学习相关的业务案例中,根据业务经验人工粗选的特征可能会存在大量的冗余性和非相关性,通过卡方统计值进行初步的特征提取,也无法定性定量的确认引入模型的特征是如何影响模型结果。
在本文业务实践中,针对贸易类型的分类预测,前期结合业务经验抽取预选样本数据,还需分析各个特征属性,通过特征工程选择相应合适的模型,同时从模型的解释性报告中,进一步确认各维度特征是如何影响模型分类。
模型开发人员也可以根据模型的解释报告,扩充更多的特征维度,并可以通过解释报告明确特征的有效性,依次验证,充分地拟合需要的业务模型。
本期作者
汪兰 资深后端开发工程师
联系方式:[email protected]
如您有任何疑问欢迎交流和留言