SVD-NET
(raise the idea of feature correlation and orthogonality in reID,ICCV2017 spotlight)
论文关键词:正交正则化
个人总结:本文大篇幅论证了目前常用的训练方法,由于样本的不均匀性FC层会变得高度correlation,大大降低了模型的表达能力。详细地证明了为什么要用SVD分解步骤,以及SVD何有效。作为ABD-NET中对正交正则化的补充阅读文献,很详细的阐述了正交正则化的相关动机、作用、与具体实现方法。
本文着重考虑了reid中行人retrieval的优化问题,motivation是发现CNN后特征接的FC层是高度correlation的,这个问题可以分为两个主要原因:
1、训练样本的非均匀性分布non-uniform,这个问题在最后一个FC层最明显,最后FC层的每个神经元的输出代表了输入图片与每个可能ID的相似度,在训练后关于相似外表的人的FC层的比重也会有高度的关联性,如图所示。

简单解释就是如上图二维情况理解,CNN提取的feature是黑线,FC层相当于一个descriptor,黑线到对应方向的投影就是FC对每个ID的预测情况,可以看到ID1,ID2的人体是相似的,因此他们的投影方向也是相近的。
2、CNN的训练阶段,几乎没有正交化的约束,这样训练出来的w向量必然是高度correlation的。
FC层权重的高度关联性使得descriptor的性能达不到预期,从而使得用欧氏距离的检索任务效果也下降。实际上,我们通常用欧氏距离做检索的原因在于,特征向量的输出期望都是独立的,然而由于样本的不均匀性,相似表外表的人有着高度相似的descriptor,导致某一些输出会占据主导地位,从而导致了retival阶段的不理想排序结果。
举例来说,如图一,测试集里有绿衣和黑衣的人,训练集的FC层描述器就相当于w1,w2两个向量,特征在向量上的投影长度就是预测值,可以看到,在粉色与红色向量的投影距离是相近的,而不像蓝色的descriptor一样,离得很远。因此减小FC层的descriptor的冗余是很重要的。
本文的提出了一种能减小FC层关联度的SVD-NET,做法主要分三步:
1、将FC层的W矩阵做SVD分解,并用左矩阵来代替
2、固定正交化后的W矩阵,只对剩余层做FINE-TUNE
3、迭代估算正交化后的矩阵。
SVDNET与其他相似工作的区别
PCANET:PCANET是在图像分类中提出的,是用PCA过滤。它与SVDNET的相似之处在于,它也是学到一个正交投影方向去实现过滤,与SVDNET区别主要在两点:
1、SVDNET的SVD是在CNN的比重矩阵进行SVD分解的,PCANET是在直接的数据与特征上实施PCA算法。
2、PCA算法的filter是用无监督算法学习的,不依赖任何的BP,然而SVDNET要BP训练学习参数。
Truncated SVD :截断SVD广泛地由于CNN模型压缩
1、首先截断SVD分解FC层的权重矩阵,然后利用几个主要的非奇异向量与特征值重构矩阵。然而SVDNET不重构矩阵,只是用分解得到的其中一个正交矩阵来代替,即左矩阵与特征值矩阵的乘积。
2、截断SVD在可接受的精度下降内减小了模型的尺寸,然而SVDNET显著增大了检索效果,却并不增大模型尺寸。
权重矩阵的正交正则化:
前人已有关于CNN filter的正交正则化的研究,前人的工作使用正交正则化是为了在深度网络的BP优化,进而提高分类效果,所提出的正则化不直接有益于embedding learning。
然而本文的正交化是为了得到低correlated descriptor,以得到更好的retrival效果,然而可能不利于提高训练过程的分类效果。
方法详解
网络结构
如下图所示SVDNET不改变backbone,仅是把倒数第二层FC改为了eigenlayer,这层含有一个正交化的权重矩阵,且是个线性层无bias,因为若加了bias会破坏学到的正交性。(另外本文也预先做了实验,如果使用了relu激活并加了bias,会微微降低效果)。
把eigenlayer层放在倒数第二层是因为,如果放到倒数第一层,模型就会因为被强行正交化而无法收敛。

在testing阶段,本文也尝试使用了eigenlayer输入和输出分别作为embedding,发现两种feature得到了相似的结果,说明eigenlayer不但优化了输出层的特征,也优化了输入层的特征。
SVDNET训练流程
Step 0:
先在网络中加一个线性层,fine tune直到收敛,此时线性层的比重矩阵仍然高度相关
STEP 1-3:****Restraint and Relaxation Iteration (RRI)****,训练SVD的关键步骤
1、对训练好的线性层作SVD分解,将左矩阵与特征值的乘积作为W,将WWT的全部特征向量作为比重向量,并命名为特征层
2、Restraint.固定特征层,继续finetune backbone until converge.
3、Relaxation.解除固定,继续finetune几个epoch。
在步骤1、2后,比重向量是正则化的。但是步骤3后,特征层的比重从特征值有所松动,发生了偏移,因此训练过程叫做约束与放松。

背后机制的研究
为什么要用SVD?本文的核心思想在于基于CNN已经从训练集学习到的特征中,找到一系列的正交投影方向。然而,可以找到大量的正交基本向量(如线性层权重矩阵的一系列子向量),我们选择SVD分解作为结果的原因在于,这样能保留特征的判别能力,证明流程如下:
f代表特征层输出特征,h代表特征层输入特征,计算两个图片的fearure距离:

由于V是正交矩阵,因此VVT=1,得到
可见用我们的方法得到的正交矩阵,能100%保留原模型的判别能力。
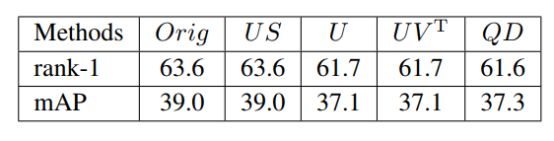
论文还通过实验的形式比较了其他几种正交分解形式(仅用U替代,US替代,QR分解等方法)是否可行,结果发现仅有目前这种替代方案,能够完全保留原模型的判别能力
为什么这么做效果就会提升?
正如上节所述,用新的正交矩阵替代线性层权重,不会带来立即的性能提升,而是会保持不变。然而在替代后,模型会远离原本的fine-tune结果,并且softmax loss在训练集上会有一定升高,因此训练中的2与3就是为了解决这个问题,那么当loss进一步下降后,模型的判别能力也会进一步提高。
简单来说,就是模型原本已经收敛了,但是正交化后,在不改变模型retrival的结果的前提下,把loss又拉离了收敛点,因此就可以进一步训练模型,优化判别能力,从而使得有更好的表现。(不过存疑点在于,LOSS降低并不完全意味着模型判别能力上升,参考early-stop的做法,因此这种说法是否不严谨)
矩阵关联性的诊断
本文目前一直在讲矩阵关联性的相关内容,然而还没有给出如何判定矩阵的关联程度,因此在此给出。
矩阵间的关联性可以用关联系数表征,然而目前尚未有人提出对一连串的向量计算关联度的方法,因此本文将提出这种算法。首先定义关联性矩阵如下(gram matrix)

其中K是权重向量的数量,(比如K=4096 in FC7),计算得到关联系数如下

可见该系数在1/k,1区间内,当矩阵正交时,S值达到最大为1.当所有向量极端关联都一样时,S值最小为1/k。我们baseline得到的FC7层的correlation=0.0072,说明矩阵关联度极大。
RRI阶段的收敛准则
几时判定RRI收敛是一个难以说清楚的难题,我们采用的方法是,计算该层的关联性因子,每当S(W)上升时,说明关联度下降了,就继续迭代,当S(W)保持稳定时,则停止迭代。
实验部分
数据集:market,duke,cuhk backbone:resnet50
实验结果如下:

可视化结果:

说明此方法是有效的,大幅提升了baseline的效果,且对比了目前的sota方法,发现本文在一个poor baseline上,仍旧取得了可与sota有一战之力的结果。
后续内容则是一些调参的实验结果与训练加速的技巧,暂略。