爬虫界的启蒙老师,python超爽爬取豆瓣并用Flask、Echarts、词云展示入门案例分享
爬虫,就是授权的或公开数据的自动采集。百度,就是一只爬虫,一条百足之虫。学会爬虫,会让你以为自己离超越百度指日可待。人有多大胆,地有多大产,梦想还是要有的,万一实现了呢。人不怕有梦想,就怕不知道,不敢想。
大数据这么火,核心是各种应用场景的开发,基础还是数据采集,比如天眼查APP,其实就是一条爬虫,爬取各种数据然后整合应用。
想学爬虫,不得不提的一个神奇网站,他是每一个爬虫小白的启蒙老师,每一个懵懂少年都是从这里开始了对互联网各个未知领域的探索,通过这位启蒙老师,初尝乐趣,欲罢不能,熟悉并掌握了各项技能,并沉迷其中,难以自拔,一发不可收拾。这位老师,善解人意,来者不拒,对各处来爬取数据的小虫子十分友善,没什么反爬机制,让爬虫小白初尝白嫖乐趣,体验异常畅快。
铺垫是不是有点过分了?好了,这个网站就是——豆瓣。
今天就对豆瓣电影Top250相关信息的爬取过程、数据分析、展示应用进行无私分享,具体会涉及到beautifulsoup模块、SQLite数据库、Flask后端框架、echarts前端模块、wordcloud词云模块。
一、爬虫数据采集
简单爬虫基本就三个步骤搞定:
第一步:发送请求。自动采集要构造好url地址。
第二步:解析数据。获得请求的响应后对网页进行解析,提取想要的数据。
第三步:保存和展示。将提取的数据保存到excel或者数据库,再通过GUI或者网站进行展示。
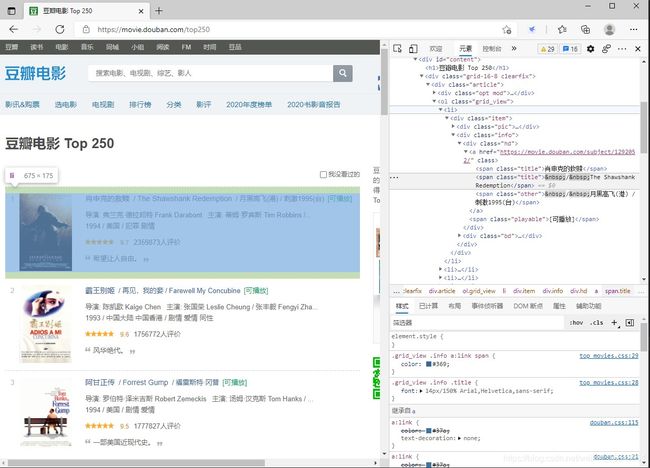
具体来说,先分析我们要爬取的目标网站:https://movie.douban.com/top250,分析目标数据所在的位置。我么要提取电影的详情链接、名称、主演、评分、评价人数、简介,这些数据基本都在当前页面下,不需要再进入电影的详情页进行提取。然后分析页面规律,Top250页面每页只包含25部电影,也就是说要自动爬取10页,点击后页,发现每个页码地址是按规律递增的,就是在https://movie.douban.com/top250?start=i(i是页数)。找到页面后就是想办法解析页面,获取我们想要的信息。具体如下:
1.发送请求:
request = urllib.request.Request(url, headers=headers)
try:
response = urllib.request.urlopen(request)
html = response.read()
except urllib.error.URLError as e:
if hasattr(e, 'code'):
print(e.code)
if hasattr(e, 'reason'):
print(e.reason)
return html
2.解析网页:
soup = BeautifulSoup(html, 'html.parser')
temp = soup.find_all('div', class_='item')
3.定义正则表达式:
pat_link = re.compile(r'a href="(.*?)">')
pat_img = re.compile(r')
pat_title = re.compile('(.*?)')
pat_info = re.compile(r'(.*?)
', re.S)
pat_rating = re.compile(r'')
pat_judge = re.compile(r'(\d*)人评价')
pat_inq = re.compile(r'(.*?)')
4.提取数据
for item in temp:
data = []
item = str(item)
movie_link = re.findall(pat_link, item)[0]
data.append(movie_link)
仅以提取电影链接为例,其他内容提取方式类似。
这样就提取到了250部电影的所需信息了。
二、数据存储
简单数据可以保存到excel,复杂数据可以存到数据库。学习数据库建议从SQLite开始,SQLite是一款轻型的数据库,python自带了sqlite3模块。
数据库的语言相对较为简单,就是插入语句稍显麻烦,SQLite里的字段都是字符串,python封装的sqlite语句也是字符串,要保证python封装的字符串传递给SQLite时符合SQLite语言规范。这里简单介绍一下保存数据的代码。
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
for data in data_list:
for index in range(len(data)):
data[index] = '"' + data[index] + '"'
sql = '''
insert into movie250(
info_link,
img_link,
cn_name,
fn_name,
info,
rating,
judge_num,
instruction
)
values(%s)
''' % ",".join(data)
cursor.execute(sql)
conn.commit()
cursor.close()
conn.close()
三、数据展示
1.首页
在网上找个网站模板,删繁取简,找到想要的表现形式,其余部分的html代码都删掉,把采集的数据进行总体展示。
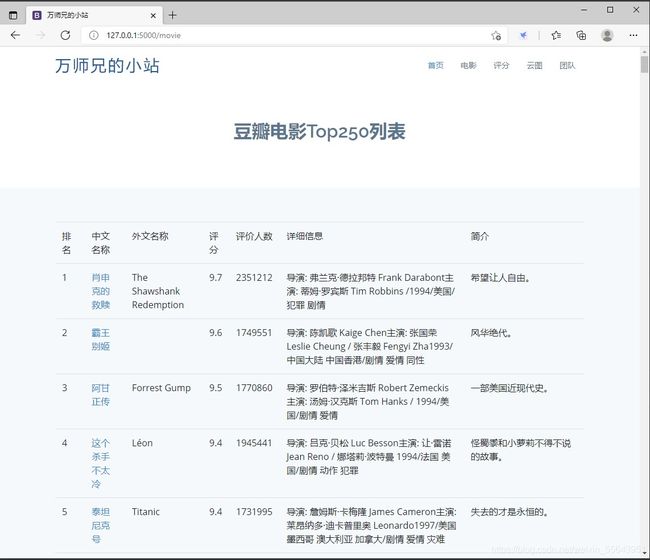
2.列表
在Flask框架中,读取数据库,塞到前端页面,把所有采集的信息进行列表展示。
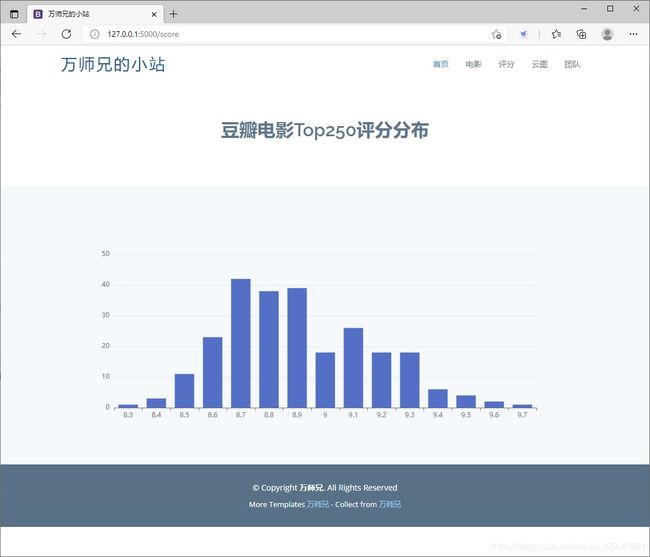
3.Echarts
Echarts里面各种酷炫的图标都有,选择自己喜欢的,拷贝源码,把自己的数据替换进去即可。
4.词云
安装wordcloud库,在数据库中取出电影简介,用jieba分词进行分词,然后用wordcloud进行展示。
四、小结
这相当于一个非常小型的完整数据采集与数据展示的项目,篇幅有限,只能简单介绍。各个部分流程走通之后,再逐步拓展selenium、scrapy框架,再去爬取各类复杂、大型网站,成为爬虫高手,指日可待。