0. 树与查找
一棵有n个结点的平衡二叉树的高度为O(lg(n)),即使查找到叶子结点,花的时间为O(lg(n)),远胜过O(n),所以树在需要搜索优化的地方用得比较多。而我们的二叉搜索树呢,顾名思义,就是用来做搜索用的,本文将讲述它的原理。
另外树如果不平衡,则容易退化成链表,所以我们要想办法让树保持平衡。红黑树,就是其中一种非常高效,应用范围极广的一种类平衡树(为了优化性能,它并不要求绝对平衡)。本文集将详细讲述红黑树的原理以及代码实现。
1. 二叉搜索树的定义
二叉搜索树又叫二叉排序数,如果树不为空的话,对树上的任意一个结点x,具有如下性质:
- 如果x的左子树存在的话,则x左子树上所有的结点的值都小于x;
- 如果x的右子树存在的话,则x右子树上所有的结点的值都大于x。
Tips: 二叉搜索树不允许有重复值。拿我们常用的Map来说,如果插入重复的值,要么覆盖原来的值,要么插入失败。
本文中所提到的树默认都是二叉搜索树,设根为root,对结点x,它的左结点用x.left表示,右结点用x.right表示,父结点用x.parent表示。为了便于说明,对结点x,我们记它左结点为L, 右结点为R,父结点为P,祖父结点为PP,x附带的数据为x.data。

下面举例都针对:图1-二叉搜索树。建议把该图下下来查看,免得频繁找图来回切换。
2. 子树的最小结点与最大结点
对以x为根的子树:
- 最小值:为该树最左边的结点,即从L开始一路往左下方搜索;如果L不存在,则最小值即为x。如:找以结点3为根的子树的最小值,从1(L)开始,沿左下方搜索,直到0;结点13为根的子树,因为没有左结点,所以最小值即为13本身。
- 最大值:跟最小值对称,这里不做进一步说明。
private Node min(Node node) {
while (node.left != null) {
node = node.left;
}
return node;
}
private Node max(Node node) {
while (node.right != null) {
node = node.right;
}
return node;
}
3. 树结点的前驱与后继
3.1 前驱
结点的前驱是比它小的结点里面最大的结点。
- 若L存在,则x的前驱为x左子树最大的结点(即L开始一路往右下方搜索)。如:7的前驱为6(从7的左结点3开始一路往右),1的前驱为0(从0开始一路往右,因为右边没有了,所以停止在0的地方);
- 若L不存在:
- 如果
P.right == x,则P < x,又因为P大于P左子树里面的全部结点的值,所以P就是x的前驱,如:结点14的前驱为13。 - 否则,x的前驱为P的前驱,x指向P继续查找,如:结点11,
P.right != x,故设x = 12继续查找。因为对12有P.right == x,所以10即为12的前驱,所以11的前驱为10。
- 如果
public Node predecessor(Node node) {
if (node.left != null) {
return max(node.left);
}
Node p = node.parent;
while (p != null && p.left == node) {
node = p;
p = p.parent;
}
return p;
}
3.2 后继
后继是比它大的结点里面最小的结点。跟前驱对称,这里不做进一步的说明。记住一个现象,就是x左右子树都存在时,x的后继没有左结点(后继.left == null)。这一点在后面将会用到,有助于理解代码。
public Node successor(Node node) {
if (node.right != null) {
return min(node.right);
}
Node p = node.parent;
while (p != null && p.right == node) {
node = p;
p = p.parent;
}
return p;
}
3.3 前驱与后继示例
大家可以试着随便从上面的树上找一个结点,然后按上面的规则找一下它的前驱与后继(注意:不要从数字上直接得到答案,因为上面这棵树是从0到15的排序数,所以前驱-结点-后继就是3个连续的数。但反过来,可以用这个结论来验证你的答案是否正确)。
- 结点1的前驱为0,后继为2;
- 结点3的前驱为2,后继为4;
- 结点7的前驱为6,后继为8;
- 结点10的前驱为9,后继为11;
- 结点9只有前驱8,后继为10;
3.4 快速构造一个树,帮助回想起前驱后继的全部逻辑
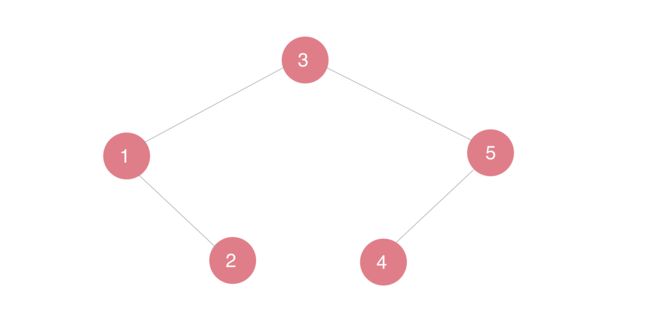
写代码的时候,如果万一忘记了前驱与后继的逻辑,3-1-5-2-4这样,前5个自然数构成的以3为根对称分布的树,能快速帮助回忆起相关细节来。
4. 数据的查找
搜索的算法比较简单,从根开始依次比较,设当前结点为x,待查找的数据为data,如果x.data == data,则找到了,返回结果;如果data < x.data,则继续查找x.left,否则继续查找x.right 。
public Node search(T data) {
if (data == null) {
return null;
}
Node node = root;
while (node != null) {
int compare = data.compareTo((T) node.data);
if (compare == 0) {
return node;
}
if (compare < 0) {
node = node.left;
} else {
node = node.right;
}
}
return null;
}
5. 插入
- 如果
root不存在,则将插入的结点设为根,插入结束; - 否则,从根开始依次比较,设p为待插入结点的父结点,设当前结点为x,待插入的数据为data。若
data < x.data,则需要插入到左边的某个位置:p = x; x = x.left,否则插入到右边的某个位置:p = x; x = x.right。当x == null时,将待插入的结点挂在p下面即可。
public void insert(T data) {
Node node = new Node();
node.data = data;
if (root == null) {
root = node;
return;
}
Node child = root;
Node p = null;
while (child != null) {
p = child;
if (data.compareTo((T) child.data) < 0) {
child = child.left;
} else {
child = child.right;
}
}
node.parent = p;
if (data.compareTo((T) p.data) < 0) {
p.left = node;
} else {
p.right = node;
}
}
6. 删除
- 如果L不存在,则用R替代x即可;
- 如果R不存在,则用L替代x即可;
- 如果L与R都存在,我们需要找到最接近x的且比它大的结点来替代x(这结点不就是上文提到的后继嘛,不妨设该后继结点为s)。另外特别注意,x的左右结点还需要在原来的地方,所以按下面的逻辑来处理:
- 处理左结点:根据上文提到的,s的左子树不存在,所以可放心地把
x.left挂在s下面:s.left = x.left; - 处理右结点:如果
x.right == s,则s就是x的右结点,所以x.right不需要处理。 - 否则,要想执行
s.right = x.right,需要把s.right先腾出来。怎么腾呢?因为s移走了,所以s的位置需要让s的右结点替代(为什么是右结点?前方提到过,这种情况下s没有左结点,所以只能是右结点来替代。另外注意了,右结点可能为null),这时候s的右结点就顺便腾出来了。然后将x.right挂在s下面。
- 处理左结点:根据上文提到的,s的左子树不存在,所以可放心地把
public boolean delete(T data) {
Node node = search(data);
if (node == null) {
return false;
}
if (node.left == null) {
replace(node, node.right);
return true;
}
if (node.right == null) {
replace(node, node.left);
return true;
}
Node successor = min(node.right);
// 步骤3没有特定顺序,你可以试着随意变换顺序。
// 3. 将node.left挂在successor下面。
successor.left = node.left;
node.left.parent = successor;
// 1. 处理右结点:步骤1必需在步骤2前面进行,否则successor移动,下面的if判断的结果会变化。
if (node.right != successor) {
replace(successor, successor.right);
node.right.parent = successor;
successor.right = node.right;
}
// 2. 将successor替代node。
replace(node, successor);
return true;
}
// replace只是把新的结点挂在老结点的父结点下面,老结点脱离了父结点而处于游离状态。
// 但新、老结点的左右孩子,都不在本方法中处理,请额外处理。
private void replace(Node oldNode, Node newNode) {
Node parent = oldNode.parent;
if (parent == null) {
root = newNode;
} else {
if (parent.left == oldNode) {
parent.left = newNode;
} else {
parent.right = newNode;
}
}
if (newNode != null) {
newNode.parent = oldNode.parent;
}
}
6.1 代码说明
有结点变动的方法(插入、删除、替换),各指针要不重不漏。
注意到原successor方法中
if (node.right != null) {
return min(node.right);
}
我们这里已经满足node.right != null,所以min(node.right)就是successor。
另外注意结点替代顺序,先用s的右结点替代s把s.right空出来(此时s可以理解为游离状态,没有父结点),然后把x.right挂在s.right的地方,最后再把s替代x。
源码
https://github.com/readyou/algorithm-introduction-code/blob/master/src/main/java/me/wxl/demo/data/struct/BinarySearchTree.java
转载声明
如果您需要转载,请注明转载来源。