通过PL/SQL Developer查看查询的执行计划
1 什么是执行计划
执行计划是一条查询语句在 Oracle 中的执行过程或访问路径的描述。
2 配置执行计划需要显示的项
1.objiect owner 2.object name 3. cast 4. bytes 5. cardinality
3 执行计划的常用列字段解释
基数(Cardinality):Oracle 估计的当前操作的返回结果集行数
字节(Bytes):执行该步骤后返回的字节数
耗费(COST)、CPU 耗费:Oracle 估计的该步骤的执行成本,用于说明 SQL 执行的
代价,理论上越小越好(该值可能与实际有出入)
时间(Time):Oracle 估计的当前操作所需的时间:
4 使用执行计划
通过工具启动执行计划。选中需要查看执行计划的查询语句,在工具栏中选择
5 查看执行计划
F5 或者 tools菜单栏 explan window
5.1执行顺序
缩进最多的最先执行;(缩进相同时,最上面的最先执行)。
5.2表访问的几种方式(非全部):
• TABLE ACCESS FULL(全表扫描)
• TABLE ACCESS BY INDEX ROWID(通过 ROWID 的表存取)
• TABLE ACCESS BY INDEX SCAN(索引扫描)
5.2.1TABLE ACCESS FULL(全表扫描)
Oracle 会读取表中所有的行,并检查每一行是否满足 SQL 语句中的 Where 限制条件;
使用建议:数据量太大的表不建议使用全表扫描,除非本身需要取出的数据较多,占到
表数据总量的 5% ~ 10% 或以上
5.2.2TABLE ACCESS BY INDEX ROWID(通过 ROWID 的
表存取)
5.2.2.1 什么是 ROWID
ROWID 是由 Oracle 自动加在表中每行最后的一列伪列,既然是伪列,就说明表中并不
会物理存储 ROWID 的值。
你可以像使用其它列一样使用它,只是不能对该列的值进行增、删、改操作。
一旦一行数据插入后,则其对应的 ROWID 在该行的生命周期内是唯一的,即使发生行
迁移,该行的 ROWID 值也不变。
5.2.2.2 TABLE ACCESS BY INDEX ROWID
行的 ROWID 指出了该行所在的数据文件、数据块以及行在该块中的位置,所以通过
ROWID 可以快速定位到目标数据上,这也是 Oracle 中存取单行数据最快的方法;
5.2.3TABLE ACCESS BY INDEX SCAN(索引扫描)
在索引块中,既存储每个索引的键值,也存储具有该键值的行的 ROWID。
5.2.3.1 索引扫描其实分为两步
1扫描索引得到对应的 ROWID。
2通过 ROWID 定位到具体的行读取数据。
5.2.3.2 五种索引扫描
• INDEX UNIQUE SCAN(索引唯一扫描)
• INDEX RANGE SCAN(索引范围扫描)
• INDEX FULL SCAN(索引全扫描)
• INDEX FAST FULL SCAN(索引快速扫描)
• INDEX SKIP SCAN(索引跳跃扫描)
5.2.3.2.1 INDEX UNIQUE SCAN(索引唯一扫描)
针对唯一性索引(UNIQUE INDEX)的扫描,每次至多只返回一条记录;
表中某字段存在 UNIQUE、PRIMARY KEY 约束时,Oracle 常实现唯一性扫描;
5.2.3.2.2INDEX RANGE SCAN(索引范围扫描)
使用一个索引存取多行数据;
发生索引范围扫描的三种情况:
1在唯一索引列上使用了范围操作符(如:> < <> >= <= between);
2在组合索引上, 只使用部分列进行查询 (查询时必须包含前导列, 否则会走全表扫描) ;
3对非唯一索引列上进行的任何查询;
5.2.3.2.3INDEX FULL SCAN(索引全扫描)
进行全索引扫描时,查询出的数据都必须从索引中可以直接得到;
5.2.3.2.4INDEX FAST FULL SCAN(索引快速扫描)
扫描索引中的所有的数据块,与 INDEX FULL SCAN 类似,但是一个显著的区别是它
不对查询出的数据进行排序(即数据不是以排序顺序被返回);
5.2.3.2.5INDEX SKIP SCAN(索引跳跃扫描)
表有一个复合索引,且在查询时有除了前导列(索引中第一列)外的其他列作为条件;
5.2.4Oracle的优化器
5.2.4.1 Oracle的优化器种类
• RBO(Rule-Based Optimization) 基于规则的优化器
• CBO(Cost-Based Optimization) 基于代价的优化器
5.2.4.2 RBO优化器
RBO 有严格的使用规则, 只要按照这套规则去写 SQL 语句, 无论数据表中的内容怎样,
也不会影响到你的执行计划。换句话说,RBO 对数据“不敏感”,它要求 SQL 编写人员必
须要了解各项细则。RBO 一直沿用至 ORACLE 9i,从 ORACLE 10g 开始,RBO 已经彻底
被抛弃。
5.2.4.3 CBO 优化器
CBO 是一种比 RBO 更加合理、 可靠的优化器, 在 ORACLE 10g中完全取代 RBO。 CBO
通过计算各种可能的执行计划的“代价”,即 COST,从中选用 COST 最低的执行方案作为实
际运行方案。
数据库查询优化四原则:
1.尽量避免是*代替所有列,编写查询语句时使用具体列名代替*,
2.可以防止全表扫描尽可能少的使用like关键字进行模糊查询
3.建立适当的索引可以提高查询效率
4.等值链接的查询效率高于子查的执行效率
Oracle的数据导入与导出
1 数据库导入导出需要注意
1.目标数据库要与源数据库有着名称相同的表空间。
2.目标数据在进行导入时,用户名尽量相同(这样保证用户的权限级别相同)。
3.目标数据库每次在进行数据导入前,应做好数据备份,以防数据丢失。
4.弄清是导入导出到相同版本还是不同版本(oracle10g版本与 oracle11g版本)。
5.目标数据导入前,弄清楚是数据覆盖(替换),还是仅插入新数据或替换部分数据表。
6.确定目标数据库磁盘空间是否足够容纳新数据,是否需要扩充表空间。
7.导入导出时注意字符集是否相同,一般 Oracle 数据库的字符集只有一个,并且固定,
一般不改变。
8.确定操作者的账号权限。
2 导出数据格式介绍
Dmp 格式:.dmp 是二进制文件,可跨平台,还能包含权限,效率好。
Sql 格式:.sql 格式的文件,可用文本编辑器查看,通用性比较好,效率不如第一种,
适合小数据量导入导出。尤其注意的是表中不能有大字段 (blob,clob,long),如果有,会
报错。
Pde 格式: .pde格式的文件, .pde 为 PL/SQL Developer 自有的文件格式, 只能用 PL/SQL
Developer 工具导入导出,不能用文本编辑器查看。
3 传统方式exp(导出)和(imp)导入:
3.1命令执行方式
该命令需要在操作系统的命令窗口执行,而非 sql/plus
在使用导出或导入命令时,在命令的后侧不要添加分号。
3.2命令格式
exp|imp 用 户 名 / 密 码 @ 连 接 地 址 : 端 口 / 服 务 名 file= 路 径 / 文 件 名 .dmp
full=y|tabels(tablename,tablename...)|owner(username1,username2,username3)
exp:导出命令,导出时必写。
imp:导入命令,导入时必写,每次操作,二者只能选择一个执行。
username:导出数据的用户名,必写;
password:导出数据的密码,必写;
@:地址符号,必写;
SERVICENAME:Oracle 的服务名,必写;
1521:端口号,1521是默认的可以不写,非默认要写;
file="文件名.dmp" : 文件存放路径地址,必写;
full=y :表示全库导出。可以不写,则默认为 no,则只导出用户下的对象;
tables:表示只导出哪些表;
owner:导出该用户下对象;
full|tables|owner:只能使用一种;
3.3导出数据
exp 用户名/密码@oracle 的连接地址:端口/需要导出的服务名 file=路径/文件名.dmp
3.4导入数据
imp 用户名/密码@oracle的连接地址:端口/需要导出的服务名 file=路径/文件名.dmp
一:MySQL 简介
1 什么是MySQL
MySQL 是一个关系型数据库管理系统,由瑞典 MySQL AB 公司开发,目前属于
Oracle 公司。MySQL 是一种关系型数据库管理系统,关系型数据库将数据保存在不同的表
中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
2 MySQL特点
MySQL 是开源的,所以你不需要支付额外的费用。
MySQL 支持大型系统的数据库。可以处理拥有上千万条记录的大型数据库。
MySQL 使用标准的 SQL 数据语言形式。
MySQL 可以运行于多个系统上,并且支持多种语言。这些编程语言包括 C、C++、
Python、Java、Perl、PHP、Eiffel、Ruby 和 Tcl 等。
MySQL 存储数据量较大,32 位系统表文件最大可支持 4GB,64 位系统支持最大的
表文件为 8TB。
MySQL 是可以定制的,采用了 GPL 协议,你可以修改源码来开发自己的 MySQL 系
统。
二、 MySQL与Oracle的区别
1 实例区别
MySQL 是轻量型数据库,开源免费。Oracle 是收费的而且价格非常高。
MySQL 一个实例可以操作多个库,而 Oracle 一个实例只能对应一个库。
MySQL 安装完后 300M而 Oracle 有 3G 左右。
2 操作区别
主键: MySQL 一般使用自动增长类型,而 Oracle 则需要使用序列对象。
单引号的处理: MySQL 里可以用双引号包起字符串,ORACLE 里只可以用单引号包
起字符串。
分页的 SQL 语句: MYSQL 用 LIMIT,而 Oracle 需要使用内建视图和 rownum伪列。
事务处理:MySQL 默认是自动提交,而 Oracle 默认不自动提交,需要用户 CTL 语言
进行事务提交。
三、 操作MySQL
1 创建与删除数据库
1.1创建数据库
1.1.1使用命令创建数据库
CREATE DATABASE 数据库名 DEFAULT CHARACTER SET 字符编码;
1.2删除数据库
1.2.1使用命令删除数据库
Drop database 数据库名称
2 选择数据库
需要在哪个库中创建表需要先选择该数据库。
Use 需要选择的库的名称。
3 MySQL中的数据类型
3.1数值类型
MySQL 支持所有标准 SQL 数值数据类型。
作为 SQL 标准的扩展,MySQL 也支持整数类型 TINYINT、MEDIUMINT 和 BIGINT。
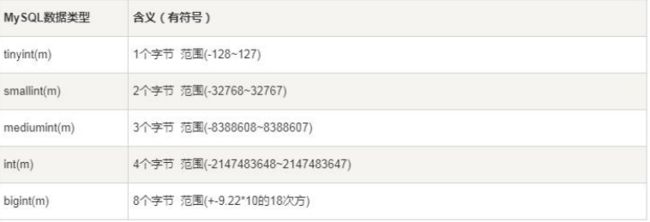
数值类型中的长度 m 是指显示长度,并不表示存储长度,只有字段指定 zerofill 时有用
例如:int(3),如果实际值是 2,如果列指定了 zerofill,查询结果就是 002,左边用 0 来
填充
3.2浮点型

3.3字符串型
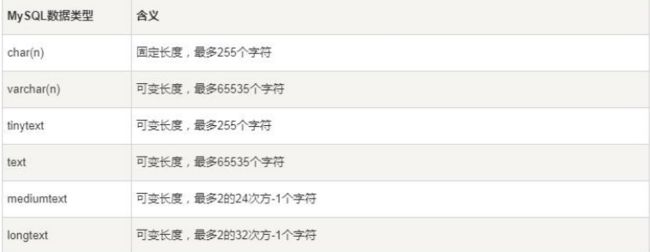
3.3.1char 和 varchar
1)char(n) 若存入字符数小于 n,则以空格补于其后,查询之时再将空格去掉。所以 char
类型存储的字符串末尾不能有空格,varchar 不限于此。
2)char 类型的字符串检索速度要比 varchar 类型的快。
3.3.2varchar 和 text
1)varchar 可指定 n,text 不能指定,内部存储 varchar 是存入的实际字符数 +1 个字
节(n<=255)或 2 个字节(n>255),text 是实际字符数 +2 个字节。
2)text 类型不能有默认值。
3)varchar 可直接创建索引,text 创建索引要指定前多少个字符。varchar 查询速度快
于 text, 在都创建索引的情况下,text 的索引似乎不起作用。
3.4日期类型
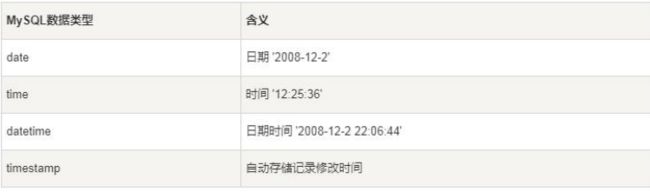
3.5二进制数据(BLOB)
1)BLOB 和 TEXT 存储方式不同, TEXT 以文本方式存储, 英文存储区分大小写, 而 Blob
是以二进制方式存储,不分大小写。
2)BLOB 存储的数据只能整体读出。
3)TEXT 可以指定字符集,BLOB 不用指定字符集。
4 创建表与删除表
4.1创建表
create table 表名(列名1,类型1,列名2,类型2,。。。);
4.2删除表
4.2.1通过DDL 语句删除表
drop table 表名;
4.3修改表名
Alter table旧表名 rename新表名
4.4修改列名
Alter table 表名 change column 旧表名新表名 类型
4.5修改列类型
Alter table 表名 modify 列名 新类型
4.6添加列
Alter table 表名 add column 列名 类型、
4.7删除列
ALTER TABLE 表名 DROP COLUMN 列名