【Java小白】不要再一味的堆积框架的基本使用了,快停下来分析几道面试题沉淀一下!
- 临近秋招,备战暑期实习,祝大家每天进步亿点点!Day20
- 每日10道题打卡,本篇总结 SSM 三大框架相关面试题~

1、什么是有状态登录和无状态登录?
内容参考自:有状态登录和无状态登录概念
- 有状态登录:
当客户端第一次请求服务器时(请求登录),服务器创建 Session ,然后将登录用户身份信息保存到 Session 中,并将用户身份信息作为 “门卡”,响应回客户端,客户端将服务器响应的 “门卡” 信息保存在本地 Cookie 中。
当下一次客户端再次请求服务器时,这时候就直接将客户端的 Cookie 中存放的 “门卡” 带到服务器端,服务器端从 Session 中拿出数据和 “门卡” 进行对比,判断是否可以同行。
-
无状态登录的缺点:
- 服务端保存大量用户身份标识,增加服务端压力。
- 客户端请求依赖服务端,多次请求必须访问同一台服务器(如果是集群,相当于启动了多个 Tomcat,这时候无法在多个 Tomcat 直接共享 Session 数据)。
-
无状态登录:
服务器不保存任何客户端用户的登录信息!
客户端的每次请求服务器必须自己具备身份信息标识(jwt),服务器端通过身份信息标识识别客户端身份。
- 无状态登录的好处:
- 客户端请求不依赖服务端的信息,任何多次请求不需要必须访问到同一台服务器。
- 减小服务端存储压力。
如何实现无状态登录?
如图所示:

- 当客户端第一次请求服务时,服务端对用户进行信息认证(登录)。
- 认证通过,将用户身份信息(不包含密码)进行加密形成
token,返回给客户端,作为登录凭证。 - 以后每次请求,客户端都携带认证的
token。 - 服务的对
token进行解密,判断是否有效。
2、过滤器,拦截器,Aop区别?
非常详细的参考文章:
- 过滤器 和 拦截器的 6个区别,别再傻傻分不清了
- 最详细的讲解过滤器,拦截器,AOP的区别
3、什么是SpringMvc,说一说它的几个核心组成?
- ① 前端控制器(DispatcherServlet):主要用于接收客户端发送的 HTTP 请求、响应结果给客户端。
- ② 处理器映射器(HandlerMapping):根据请求的 URL 来定位到对应的处理器(Handler)。
- ③ 处理器适配器(HandlerAdapter):在编写处理器(Handler)的时候要按照处理器适配器(HandlerAdapter) 要求的规则去编写,通过适配器可以正确的去执行 Handler。
- ④ 处理器(Handler):就是我们经常写的 Controller 层代码,例如:
UserController。 - ⑤ 视图解析器(ViewResolver):进行视图的解析,将 ModelAndView 对象解析成真正的视图(View)对象返回给前端控制器。
- ⑥ 视图(View):View 是一个接口, 它的实现类支持不同的视图类型(JSP,FreeMarker,Thymleaf 等)。
4、Springmvc执行流程?
- ① 首先,用户发送 HTTP 请求给 SpringMVC 前端控制器 DispatcherServlet。
- ② DispatcherServlet 收到请求后,调用HandlerMapping 处理器映射器,根据请求 URL 去定位到具体的处理器 Handler,并将该处理器对象返回给 DispatcherServlet 。
- ③ 接下来,DispatcherServlet 调用 HandlerAdapter 处理器适配器,通过处理器适配器调用对应的 Handler 处理器处理请求,并向前端控制器返回一个 ModelAndView 对象。
- ④ 然后,DispatcherServlet 将 ModelAndView 对象交给 ViewResoler 视图解析器去处理,并返回指定的视图 View 给前端控制器。
- ⑤ DispatcherServlet 对 View 进行渲染(即将模型数据填充至视图中)。View 是一个接口, 它的实现类支持不同的视图类型(JSP,FreeMarker,Thymleaf 等)。
- ⑥ DispatcherServlet 将页面响应给用户。
5、什么是MyBatis 一、二级缓存?
扩展文章:SpringBoot整合Redis作为Mybatis二级缓存
- 一级缓存:作用域是 SqlSession,同一个 SqlSession 中执行相同的 SQL 查询(相同的SQL和参数),第一次会去查询数据库并写在缓存中,第二次会直接从缓存中取。
- 一级缓存是基于 PerpetualCache 的 HashMap 本地缓存,默认打开一级缓存。
- 失效策略:当执行 SQL 时候两次查询中间发生了增删改的操作,即
insert、update、delete等操作commit后会清空该 SqlSession 缓存。
- 二级缓存:作用域是 NameSpace 级别,多个 SqlSession 去操作同一个 NameSpace 下的 Mapper 文件的 sql 语句,多个 SqlSession可以共用二级缓存,如果两个 Mapper 的 NameSpace 相同,(即使是两个 Mapper,那么这两个 Mapper 中执行 sql 查询到的数据也将存在相同的二级缓存区域中)
- 二级缓存也是基于 PerpetualCache 的 HashMap 本地缓存,可自定义存储源,如 Ehcache/Redis等。默认是没有开启二级缓存。
- 操作流程:第一次调用某个 NameSpace 下的 SQL 去查询信息,查询到的信息会存放该 Mapper对应的二级缓存区域。第二次调用同个 NameSpace 下的 Mapper 映射文件中的相同的 sql 去查询信息时,会去对应的二级缓存内取结果。
- 失效策略:执行同个 NameSpace 下的 Mapepr 映射文件中增删改 sql,并执行了
commit操作,会清空该二级缓存。
注意:实现二级缓存的时候,MyBatis 建议返回的 POJO 是可序列化的, 也就是建议实现 Serializable 接口。
如图所示:

当 Mybatis 调用 Dao 层查询数据库时,先查询二级缓存,二级缓存中无对应数据,再去查询一级缓存,一级缓存中也没有,最后去数据库查找。
6、为什么说 Mybatis 是半自动ORM映射工具?它与全自动的区别在哪里?
ORM 是什么?
ORM(Object Relational Mapping),对象关系映射,是一种为了解决关系型数据库数据与简单 Java 对象(POJO)建里映射关系的技术。
为什么说 Mybatis 是半自动ORM映射工具?它与全自动的区别在哪里?
- 首先,像 Hibernate、JPA 这种属于全自动 ORM 映射工具,使用 Hibernate 查询关联对象或者关联集合对象时,可以根据对象关系模型直接获取,所以它是全自动的。
- 而 Mybatis 在查询关联对象或关联集合对象时,需要手动编写 sql 来完成,所以,称之为半自动 ORM 映射工具。
- 换句话来解释就是说 MyBatis 是 半自动 ORM 最主要的一个原因是,它需要在 XML 或者注解里通过手动或插件生成 SQL,才能完成 SQL 执行结果与对象映射绑定。
7、能否简单说下Mybatis加载的流程?
- MyBatis 是以一个 SqlSessionFactory 实例为核心,SqlSessionFactory 的实例可以通过 SqlSessionFactoryBuilder 获得。
- SqlSessionFactoryBuilder 可以从 XML 配置文件或一个预先配置的 Configuration 实例来构建出 SqlSessionFactory 实例。
- SqlSessionFactory 实例工厂可以生产 SqlSession ,它里面提供了在数据库执行 SQL 命令所需的所有方法。
具体流程:
① 加载配置文件:需要加载的配置文件包括全局配置文件(mybatis-config.xml)和 SQL(Mapper.xml) 映射文件,其中全局配置文件配置了Mybatis 的运行环境信息(数据源、事务等),SQL映射文件中配置了与 SQL 执行相关的信息。
② 创建会话工厂:MyBatis通过读取配置文件的信息来构造出会话工厂(SqlSessionFactory),即通过SqlSessionFactoryBuilder 构建 SqlSessionFactory。
③ 创建会话:拥有了会话工厂,MyBatis就可以通过它来创建会话对象(SqlSession)。会话对象是一个接口,该接口中包含了对数据库操作的增删改查方法。
④ 创建执行器:因为会话对象本身不能直接操作数据库,所以它使用了一个叫做数据库执行器(Executor)的接口来帮它执行操作。
⑤ 封装SQL对象:执行器(Executor)将待处理的SQL信息封装到一个对象中(MappedStatement),该对象包括SQL语句、输入参数映射信息(Java简单类型、HashMap或POJO)和输出结果映射信息(Java简单类型、HashMap 或 POJO)。
⑥ 操作数据库:拥有了执行器和SQL信息封装对象就使用它们访问数据库了,最后再返回操作结果,结束流程。
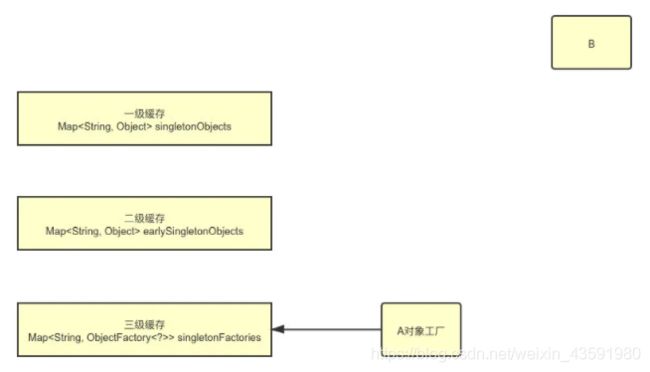
8、什么是 Spring 三级缓存?
所谓三级缓存,其实就是org.springframework.beans.factory包下DefaultSingletonBeanRegistry类中的三个成员属性:
// Spring一级缓存:用来保存实例化、初始化都完成的对象
// Key:beanName
// Value: Bean实例
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
// Spring二级缓存:用来保存实例化完成,但是未初始化完成的对象
// Key:beanName
// Value: Bean实例
// 和一级缓存一样也是保存BeanName和创建bean实例之间的关系,
// 与singletonObjects不同之处在于,当一个单例bean被放在里面后,
// 那么bean还在创建过程中,就可以通过getBean方法获取到了,其目的是用来循环检测引用!(后面会分析)
private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(16);
// Spring三级缓存:用来保存一个对象工厂,提供一个匿名内部类,用于创建二级缓存中的对象
// Key:beanName
// Value: Bean的工厂
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
如图所示,除了三级缓存是一个HashMap,其他两个都是ConcurrentHashMap:

Spring之所以引入三级缓存,目的就是为了解决循环依赖问题!
除了上面三个Map集合,还有另一个集合这里也说一下:
// 用来保存当前所有已注册的Bean
private final Set<String> registeredSingletons = new LinkedHashSet<>(256);
9、什么是 Spring循环依赖问题?如何解决?
首先,Spring 解决循环依赖有两个前提条件:
- Setter方式注入造成的循环依赖(构造器方式注入不可以)
- 必须是单例
本质上解决循环依赖的问题就是依靠三级缓存,通过三级缓存提前拿到未初始化的对象。下面我们来看一个循环依赖的例子:

A 对象的创建过程:
-
创建对象A,实例化的时候把A对象工厂放入三级缓存
-
A 注入属性时,发现依赖 B,转而去实例化 B
-
同样创建对象 B,注入属性时发现依赖 A,一次从一级到三级缓存查询 A,从三级缓存通过对象工厂拿到 A,把 A 放入二级缓存,同时删除三级缓存中的 A,此时,B 已经实例化并且初始化完成,把 B 放入一级缓存。

-
接着继续创建 A,顺利从一级缓存拿到实例化且初始化完成的 B 对象,A 对象创建也完成,删除二级缓存中的 A,同时把 A 放入一级缓存。
-
最后,一级缓存中保存着实例化、初始化都完成的A、B 对象。
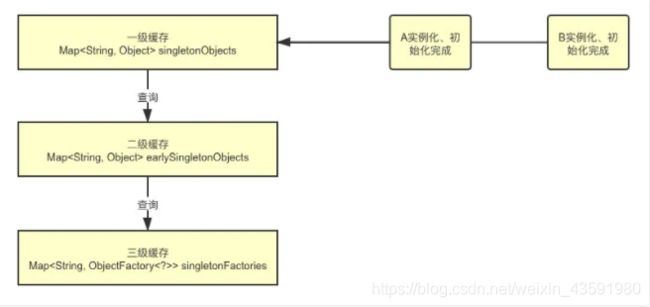
- 从上面5步骤的分析可以看出,三级缓存解决循环依赖是通过把实例化和初始化的流程分开了,所以如果都是用构造器的话,就没法分离这个操作(因为构造器注入实例化和初始是一起进行的)。因此构造器方式注入的话是无法解决循环依赖问题的。
解决循环依赖为什么必须要要三级缓存?二级不行吗?
答案:不可以!
使用三级缓存而非二级缓存并不是因为只有三级缓存才能解决循环引用问题,其实二级缓存同样也能很好解决循环引用问题。
使用三级而非二级缓存并非出于IOC的考虑,而是出于AOP的考虑,即若使用二级缓存,在AOP情形下,往二级缓存中放一个普通的Bean对象,BeanPostProcessor去生成代理对象之后,覆盖掉二级缓存中的普通Bean对象,那么多线程环境下可能取到的对象就不一致了。
- 一句话总结就是,在 AOP 代理增强 Bean 后,会对早期对象造成覆盖,如果多线程情况下可能造成取到的对象不一致~
10、说说Spring 里用到了哪些设计模式?
单例模式:Spring 中的 Bean 默认情况下都是单例的。无需多说。工厂模式:工厂模式主要是通过 BeanFactory 和 ApplicationContext 来生产 Bean 对象。代理模式:最常见的 AOP 的实现方式就是通过代理来实现,Spring主要是使用 JDK 动态代理和 CGLIB 代理。- …
这里给大家推荐三篇关于上面三种设计模式的文章:
【Java实习生】面试常问设计模式——单例模式
【Java实习生】面试常问设计模式——工厂模式
【Java实习生】面试常问设计模式——代理模式
总结的面试题也挺费时间的,文章会不定时更新,有时候一天多更新几篇,如果帮助您复习巩固了知识点,还请三连支持一下,后续会亿点点的更新!

为了帮助更多小白从零进阶 Java 工程师,从CSDN官方那边搞来了一套 《Java 工程师学习成长知识图谱》,尺寸 870mm x 560mm,展开后有一张办公桌大小,也可以折叠成一本书的尺寸,有兴趣的小伙伴可以了解一下,当然,不管怎样博主的文章一直都是免费的~
