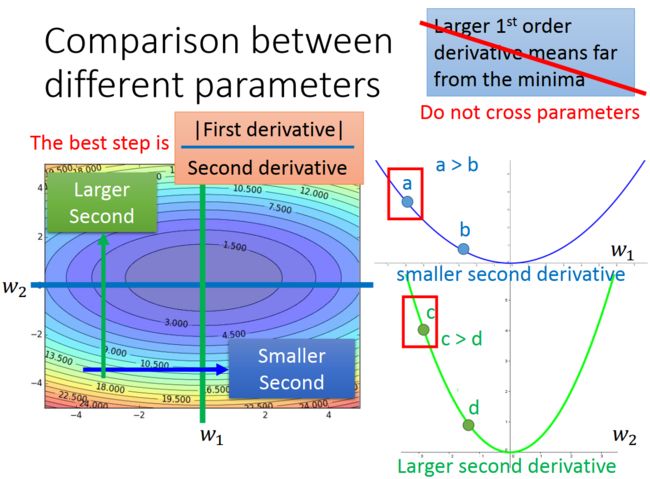
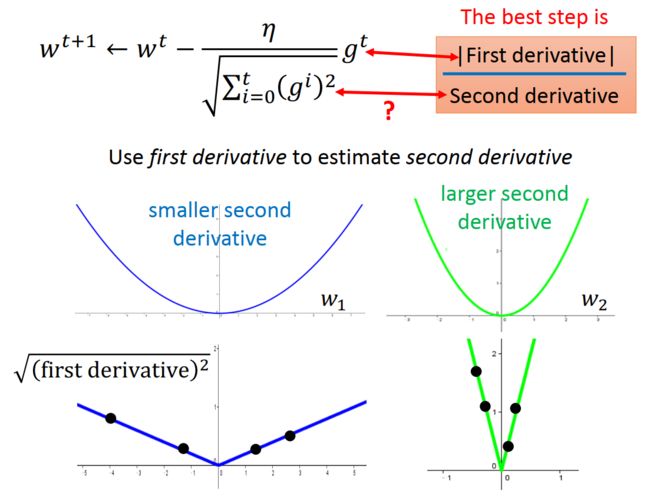
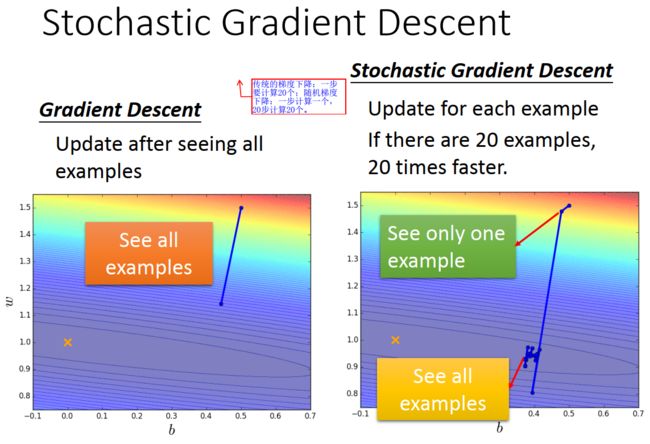
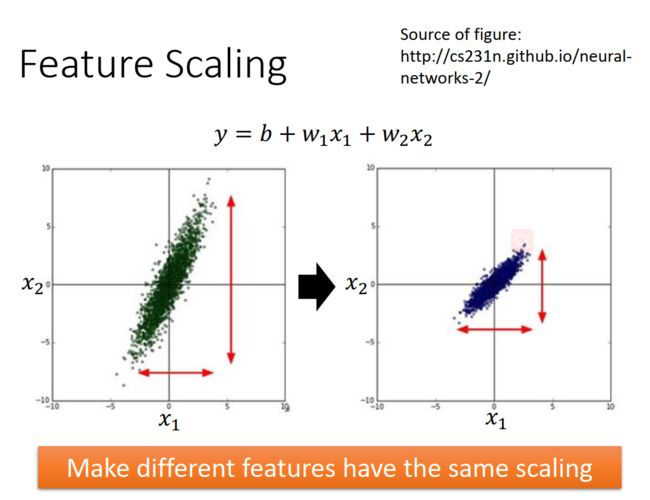
- 基于Transformer的YOLOv8检测头架构改进:提升目标检测精度的全新突破(YOLOv8)
步入烟尘
transformerYOLO目标检测
本专栏专为AI视觉领域的爱好者和从业者打造。涵盖分类、检测、分割、追踪等多项技术,带你从入门到精通!后续更有实战项目,助你轻松应对面试挑战!立即订阅,开启你的YOLOv8之旅!专栏订阅地址:https://blog.csdn.net/mrdeam/category_12804295.html文章目录基于Transformer的YOLOv8检测头架构改进:提升目标检测精度的全新突破什么是DAtten
- @AllArgsConstructor等lombok注解不生效以及idea的plugins加载不出来的解决方案
CodeYello
Javaideamavenjavaspringboot
@AllArgsConstructor等lombok注解不生效的特点:被这个注解修饰的类并没有被准备好的无参构造器、有参构造器(不是指没有相关的代码,而是没有这些功能)不生效原因:idea里没有配备或配备完全lombox在网上搜了很多解决方案,但有些只适合老版本的idea,还有些根本解决不了。在这里给出亲身解决的方案。解决方式:一开始我们需要在pom.xml里引入lombox的依赖(引入后别忘了刷
- 图片粘贴上传实现
SarinaDu
javascripthtml5
图片上传htmldemo直接粘贴本地运行查看效果即可,有看不懂的直接喂给deepseek会解释的很清晰粘贴图片上传示例-使用场景,粘贴桌面图片上传、粘贴word文档中图片上传、直接截图上传等body{font-family:Arial,sans-serif;padding:20px;}.upload-area{width:100%;height:200px;border:2pxdashed#ccc
- AJAX使用和固定格式
乐多_L
ajax前端javascript
ajax的全称AsynchronousJavaScriptandXML(异步JavaScript和XML)。ajax是一种创建交互式网页应用的网页开发技术。其中最核心的依赖是浏览器提供的XMLHttpRequest对象,是这个对象使得浏览器可以发出HTTP请求与接收HTTP响应。实现了在页面不刷新的情况下和服务器进行交互。方法描述newXMLHttpRequest()生成一个XMLHttpRequ
- 详细介绍:封装简易的 Axios 函数获取省份列表
还是鼠鼠
javascriptvscodeajax前端前端框架
目录关键步骤:完整代码(html):代码解析:程序运行结果:本示例展示了如何通过封装一个简易的myAxios函数来模拟axios的功能,使用原生的XMLHttpRequest(XHR)对象来发起HTTP请求。我们将实现一个简单的功能,通过该封装函数从服务器获取省份列表数据,并在网页上显示这些省份。关键步骤:封装myAxios函数:myAxios函数接收一个配置对象(如请求的URL和方法),并返回一
- 快速提升网站收录率的10个步骤
百度网站快速收录
百度网站快速收录百度快速收录网站快速收录百度收录网站收录
快速提升网站收录率需要综合考虑多个方面,以下是10个具体步骤,旨在帮助网站更快地获得搜索引擎的收录:1.提交网站地图制作并提交XML站点地图:站点地图是一个包含网站所有页面链接的文件,有助于搜索引擎快速发现和抓取网站内容。通过提交站点地图给搜索引擎,可以显著提高网站的收录速度。2.保持内容更新定期发布高质量内容:搜索引擎喜欢更新频繁的网站,因此保持网站内容的定期更新是提高收录率的关键。确保内容原创
- python 自动化数据提取之正则表达式_python 正则提取(2)
m0_60607245
程序员python学习面试
一、Python所有方向的学习路线Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。二、Python必备开发工具工具都帮大家整理好了,安装就可直接上手!三、最新Python学习笔记当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理
- Mysql学习笔记-Mysql基础进阶
少年无为
MysqlMysql数据库多表查询数据库备份Mysql查询
#知识点1.DQL:查询语句1.排序查询2.聚合函数3.分组查询4.分页查询2.约束3.多表之间的关系4.范式5.数据库的备份和还原#DQL:查询语句1.排序查询*语法:orderby子句*orderby排序字段1排序方式1,排序字段2排序方式2...*排序方式:*ASC:升序,默认的。*DESC:降序。*注意:*如果有多个排序条件,则当前边的条件值一样时,才会判断第二条件。2.聚合函数:将一列数
- 嵌入式学习DAY28 --- 线程、同步和互斥问题、如何实现同步和互斥?
楼台的春风
嵌入式学习多线程c语言嵌入式linuxubuntu
嵌入式入门学习笔记,遇到的问题以及心得体会!DAY28概述:一、线程二、同步和互斥问题三、如何实现同步四、如何实现互斥笔记:一、线程1、什么是线程:(1)线程是轻量级的进程(2)线程存在于进程内,不能独立存在(3)线程参与CPU调度,进程是系统资源分配最小单位,线程是系统调度的最小单位(4)在单核CPU中,多线程并发属于伪并发,但是不牵扯虚拟地址空间的切换,所以开销比进程间切换要小很多(5)在多核
- Android arcgis加载在线底图
Angie洛林
androidarcgis
我整理的一些关于【信息系统】的项目学习资料(附讲解~~)和大家一起分享、学习一下:https://edu.51cto.com/mic-position/757.html在Android中使用ArcGIS加载在线底图ArcGIS是Esri提供的一套强大的地理信息系统(GIS)解决方案,支持多种平台,包括Android。本文将介绍如何在Android应用中使用ArcGIS加载在线底图,并配有相关代码示
- (九万字)面向2025年BOSS直聘人工智能算法工程师高频面试题解析
快撑死的鱼
人工智能回归pythonpytorch
面向2025年BOSS直聘人工智能算法工程师高频面试题解析1.机器学习(ML)理论解析机器学习是让计算机从数据中学习规律的一套方法论,包含监督学习、无监督学习和强化学习等范式。在监督学习中,给定带标签的数据,算法尝试学习从输入到输出的映射关系;无监督学习则在缺乏标签的情况下挖掘数据内在结构;强化学习则让智能体通过与环境交互、依据奖赏反馈来改进策略(Q-learning-Wikipedia)。机器学
- ArcGIS二次开发之WPF中控件的使用
ShirmyMao
ArcGIS二次开发wpfc#arcgis
WPF中ArcGIS控件的使用WPF中插入ArcGIS控件Winform控件上嵌套使用WPF控件WPF中插入ArcGIS控件在WPF中引用ArcGIS的控件需要使用WindowsFromsHost,具体用法如下:添加引用:WindowsFormsIntegration和system.windows.formWpf.xaml中后台代码中:publicAxMapControlMapControl=ne
- CSS中五种定位方式(position)对比分析
七公子77
csscss前端
在CSS中,定位方式(position)决定了元素如何相对于其参照物进行定位,同时影响文档流的布局。以下是五种定位方式的对比、参照物说明及代码示例:1.position:static(默认定位)参照物:无,元素位于默认文档流中。文档流:元素按照HTML顺序自然排列。特点:top、right、bottom、left和z-index属性无效。示例:Box1Box2.box{width:100px;he
- 欧*雅WCS项目总结
十五001
项目归档后端java程序人生
项目介绍使用系统APRISO下发任务与wcs交互,wcs包含与海康agv对接,以及APRISO不纳入管理的库位(包括线边库位、码头库位、暂存区库位、空栈板库位)。wcs的主要定位就是高度定制化贴合生产业务,可以说wcs成为了agv和APRISO之间的桥梁。APRISO下发任务时候,通过生成xml文件实现的,这时候wcs会监听该文件目录新建的xml文件来生成任务。刚开始部署后不到一周出现了监听失效问
- 深度学习之目标检测的常用标注工具
铭瑾熙
人工智能机器学习深度学习深度学习目标检测目标跟踪
1LabelImgLabelImg是一款开源的图像标注工具,标签可用于分类和目标检测,它是用Python编写的,并使用Qt作为其图形界面,简单好用。注释以PASCALVOC格式保存为XML文件,这是ImageNet使用的格式。此外,它还支持COCO数据集格式。2labelmelabelme是一款开源的图像/视频标注工具,标签可用于目标检测、分割和分类。灵感是来自于MIT开源的一款标注工具Label
- 【vue】Mammoth.js的使用:将.docx转换成HTML
暴富暴富暴富啦啦啦
1024程序员节
mammoth.convertToHtml(input,options):把源文档转换为HTML文档mammoth.convertToMarkdown(input,options):把源文档转换为Markdown文档。mammoth.extractRawText(input):提取文档的原始文本。这将忽略文档中的所有格式。每个段落后跟两个换行符。npminstallelement-uimammot
- 单细胞轨迹分析-monocle包的使用
探序基因
r语言
探序基因肿瘤研究院整理安装:monocle源码下载:https://www.bioconductor.org/packages/release/bioc/html/monocle.htmlR版本,4.2.0BiocManager::install("monocle")不过在安装过程中还是报错了:Warning:无法在https://bioconductor.org/packages/3.15/bi
- 前端导出word文件—包含canvas(echarts图表)
Liuer_Qin
jscanvasechartsecharts前端javascript
一、使用的插件html-docx-js二、整体思路因为canvas是运行在内存中的,所以不能简单的通过dom获取canvas图片,需要手动的先将canvas转为image。三、实现先克隆要下载的DOM的副本。因为canvas是运行在内存中的,所以也不能通过cloneNode方法克隆下来(克隆下来是空的)。我们这里将原DOM中的canvas转成图片,然后插入到副本的对应位置,这样操作不会影响原DOM
- 侯捷 C++ 课程学习笔记:C++ 面向对象开发的艺术
孤寂大仙v
c++c++学习笔记
在侯捷老师的C++系列课程中,《C++面向对象开发》这门课程让我对面向对象编程有了更深入的理解。面向对象编程(OOP)是现代软件开发中最重要的编程范式之一,而C++作为支持OOP的语言,提供了强大的工具和特性。侯捷老师通过系统的讲解和实战案例,帮助我掌握了如何在C++中高效地使用面向对象技术。以下是我对这门课程的学习笔记和心得体会。一、课程核心内容:C++面向对象开发的关键特性![侯捷老师的课程详
- 动态蛇形卷积(DySnakeConv)在YOLOv8检测头中的应用与优化-分割性能的提升【YOLOv8】
步入烟尘
YOLO动态蛇形卷积DySnakeConv
本专栏专为AI视觉领域的爱好者和从业者打造。涵盖分类、检测、分割、追踪等多项技术,带你从入门到精通!后续更有实战项目,助你轻松应对面试挑战!立即订阅,开启你的YOLOv8之旅!专栏订阅地址:https://blog.csdn.net/mrdeam/category_12804295.html文章目录动态蛇形卷积(DySnakeConv)在YOLOv8检测头中的应用与优化-分割性能的提升【YOLOv
- Docker Compose部署大语言模型LLaMa3+可视化UI界面Open WebUI
m0_74824877
docker语言模型ui
一、介绍Ollama:部署+运行大语言模型的软件LLaMa3:史上最强开源AI大模型—Meta公司新发布的大语言模型OpenWebUI:AI用户界面,可通过浏览器访问二、Docker部署docker-compose.yml文件如下:version:'3'services:ollama:container_name:bruce-ollamaimage:ollama/ollamavolumes:-./
- 微信支付-扫码支付全流程
自娱自乐22
thinkphpphp微信扫码支付
微信支付官方文档:`https://pay.weixin.qq.com/wiki/doc/api/index.html`微信支付分为2种模式:【模式一】:商户后台系统根据微信支付规则链接生成二维码,链接中带固定参数productid(可定义为产品标识或订单号)。用户扫码后,微信支付系统将productid和用户唯一标识(openid)回调商户后台系统(需要设置支付回调URL),商户后台系统根据pr
- mac+php5.3的docker-compose.yml分享
自娱自乐22
docker
version:'3'services:nginx:image:nginx:latestcontainer_name:nginx-composevolumes:-./wwwroot:/usr/share/nginx/html:rw-./nginx/nginx/:/etc/nginx/:rw-./log/nginx:/var/log/nginx:rwrestart:alwayslinks:-phpp
- Python+Playwright常用元素定位方法
HAMYHF
python功能测试
CSSselector选择器在CSS中,定位元素主要通过选择器完成,以下是几种常见的CSS选择器定位方法:标签选择器(element):直接使用HTML元素名称来定位,例如p会选择所有段落元素。属性选择器(attribute):选择所有具有指定属性的元素,无论该属性的值是什么。例如,[title]会选择所有包含title属性的元素。选择具有指定属性,并且该属性值完全等于给定值的元素。例如,[typ
- JavaScript网页设计案例:打造交互式个人简历网站
程序媛小果
前端javascript开发语言ecmascript
在当今数字化时代,个人简历不再局限于纸质文档,而是越来越多地以网页形式呈现。JavaScript作为一种强大的客户端脚本语言,为网页设计提供了无限可能,使得网页不仅仅是静态的信息展示,而是具有丰富交互性的平台。本文将通过一个案例,展示如何使用HTML、CSS和JavaScript来设计一个交互式的个人简历网站。1.项目概述本案例的目标是创建一个个人简历网站,它不仅展示个人信息、工作经历、教育背景和
- 【学习笔记】Elasticsearch之环境搭建
聪明马的博客
elasticsearch学习笔记elasticsearch
Elasticsearch官网本文是自己在学习Elasticsearch的过程中,记下的觉得非常有用的笔记,希望对大家认识Elasticsearch有一点点帮助。1.什么是Elasticsearch官网上是这么介绍的:Elasticsearchisadistributeddocumentstore.Insteadofstoringinformationasrowsofcolumnardata,El
- Maven学习总结(15)——Maven 项目中pom.xml详解
一杯甜酒
Maven
<ver
- FreeRTOS-rust 编译分析
路西法Lux
FreeRTOS-rustrustFreeRTOSFreeRTOS-rustcargo
目录介绍FreeRTOS-rust├──.cargo#对cargo本身的配置│└──config.toml├──Cargo.toml#对当前工作空间的配置├──freertos-cargo-build#负责对freertos源码进行编译│├──Cargo.toml#对当前package进行配置│└──src│└──lib.rs├──freertos-rust#负责编译freertos的rust接口
- React学习笔记(组件通信)_千峰教育 react
m0_54846402
程序员react.js学习笔记
reduxprinciple-+//定义一个dispatch的方法,接收到动作之后,自动调用constdispatch=(action)=>{changeState(action)renderCount(countState)}```创建createStore方法Reduxprinciple02reduxprinciple-+//定义一个方法,用于集中管理state和dispatchconstcr
- 2025年全国CTF夺旗赛-从零基础入门到竞赛,看这一篇就稳了!
白帽安全-黑客4148
安全web安全网络网络安全CTF
目录一、CTF简介二、CTF竞赛模式三、CTF各大题型简介四、CTF学习路线4.1、初期1、html+css+js(2-3天)2、apache+php(4-5天)3、mysql(2-3天)4、python(2-3天)5、burpsuite(1-2天)4.2、中期1、SQL注入(7-8天)2、文件上传(7-8天)3、其他漏洞(14-15天)4.3、后期五、CTF学习资源5.1、CTF赛题复现平台5.
- [星球大战]阿纳金的背叛
comsci
本来杰迪圣殿的长老是不同意让阿纳金接受训练的.........
但是由于政治原因,长老会妥协了...这给邪恶的力量带来了机会
所以......现代的地球联邦接受了这个教训...绝对不让某些年轻人进入学院
- 看懂它,你就可以任性的玩耍了!
aijuans
JavaScript
javascript作为前端开发的标配技能,如果不掌握好它的三大特点:1.原型 2.作用域 3. 闭包 ,又怎么可以说你学好了这门语言呢?如果标配的技能都没有撑握好,怎么可以任性的玩耍呢?怎么验证自己学好了以上三个基本点呢,我找到一段不错的代码,稍加改动,如果能够读懂它,那么你就可以任性了。
function jClass(b
- Java常用工具包 Jodd
Kai_Ge
javajodd
Jodd 是一个开源的 Java 工具集, 包含一些实用的工具类和小型框架。简单,却很强大! 写道 Jodd = Tools + IoC + MVC + DB + AOP + TX + JSON + HTML < 1.5 Mb
Jodd 被分成众多模块,按需选择,其中
工具类模块有:
jodd-core &nb
- SpringMvc下载
120153216
springMVC
@RequestMapping(value = WebUrlConstant.DOWNLOAD)
public void download(HttpServletRequest request,HttpServletResponse response,String fileName) {
OutputStream os = null;
InputStream is = null;
- Python 标准异常总结
2002wmj
python
Python标准异常总结
AssertionError 断言语句(assert)失败 AttributeError 尝试访问未知的对象属性 EOFError 用户输入文件末尾标志EOF(Ctrl+d) FloatingPointError 浮点计算错误 GeneratorExit generator.close()方法被调用的时候 ImportError 导入模块失
- SQL函数返回临时表结构的数据用于查询
357029540
SQL Server
这两天在做一个查询的SQL,这个SQL的一个条件是通过游标实现另外两张表查询出一个多条数据,这些数据都是INT类型,然后用IN条件进行查询,并且查询这两张表需要通过外部传入参数才能查询出所需数据,于是想到了用SQL函数返回值,并且也这样做了,由于是返回多条数据,所以把查询出来的INT类型值都拼接为了字符串,这时就遇到问题了,在查询SQL中因为条件是INT值,SQL函数的CAST和CONVERST都
- java 时间格式化 | 比较大小| 时区 个人笔记
7454103
javaeclipsetomcatcMyEclipse
个人总结! 不当之处多多包含!
引用 1.0 如何设置 tomcat 的时区:
位置:(catalina.bat---JAVA_OPTS 下面加上)
set JAVA_OPT
- 时间获取Clander的用法
adminjun
Clander时间
/**
* 得到几天前的时间
* @param d
* @param day
* @return
*/
public static Date getDateBefore(Date d,int day){
Calend
- JVM初探与设置
aijuans
java
JVM是Java Virtual Machine(Java虚拟机)的缩写,JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。Java虚拟机包括一套字节码指令集、一组寄存器、一个栈、一个垃圾回收堆和一个存储方法域。 JVM屏蔽了与具体操作系统平台相关的信息,使Java程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台
- SQL中ON和WHERE的区别
avords
SQL中ON和WHERE的区别
数据库在通过连接两张或多张表来返回记录时,都会生成一张中间的临时表,然后再将这张临时表返回给用户。 www.2cto.com 在使用left jion时,on和where条件的区别如下: 1、 on条件是在生成临时表时使用的条件,它不管on中的条件是否为真,都会返回左边表中的记录。
- 说说自信
houxinyou
工作生活
自信的来源分为两种,一种是源于实力,一种源于头脑.实力是一个综合的评定,有自身的能力,能利用的资源等.比如我想去月亮上,要身体素质过硬,还要有飞船等等一系列的东西.这些都属于实力的一部分.而头脑不同,只要你头脑够简单就可以了!同样要上月亮上,你想,我一跳,1米,我多跳几下,跳个几年,应该就到了!什么?你说我会往下掉?你笨呀你!找个东西踩一下不就行了吗?
无论工作还
- WEBLOGIC事务超时设置
bijian1013
weblogicjta事务超时
系统中统计数据,由于调用统计过程,执行时间超过了weblogic设置的时间,提示如下错误:
统计数据出错!
原因:The transaction is no longer active - status: 'Rolling Back. [Reason=weblogic.transaction.internal
- 两年已过去,再看该如何快速融入新团队
bingyingao
java互联网融入架构新团队
偶得的空闲,翻到了两年前的帖子
该如何快速融入一个新团队,有所感触,就记下来,为下一个两年后的今天做参考。
时隔两年半之后的今天,再来看当初的这个博客,别有一番滋味。而我已经于今年三月份离开了当初所在的团队,加入另外的一个项目组,2011年的这篇博客之后的时光,我很好的融入了那个团队,而直到现在和同事们关系都特别好。大家在短短一年半的时间离一起经历了一
- 【Spark七十七】Spark分析Nginx和Apache的access.log
bit1129
apache
Spark分析Nginx和Apache的access.log,第一个问题是要对Nginx和Apache的access.log文件进行按行解析,按行解析就的方法是正则表达式:
Nginx的access.log解析正则表达式
val PATTERN = """([^ ]*) ([^ ]*) ([^ ]*) (\\[.*\\]) (\&q
- Erlang patch
bookjovi
erlang
Totally five patchs committed to erlang otp, just small patchs.
IMO, erlang really is a interesting programming language, I really like its concurrency feature.
but the functional programming style
- log4j日志路径中加入日期
bro_feng
javalog4j
要用log4j使用记录日志,日志路径有每日的日期,文件大小5M新增文件。
实现方式
log4j:
<appender name="serviceLog"
class="org.apache.log4j.RollingFileAppender">
<param name="Encoding" v
- 读《研磨设计模式》-代码笔记-桥接模式
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
/**
* 个人觉得关于桥接模式的例子,蜡笔和毛笔这个例子是最贴切的:http://www.cnblogs.com/zhenyulu/articles/67016.html
* 笔和颜色是可分离的,蜡笔把两者耦合在一起了:一支蜡笔只有一种
- windows7下SVN和Eclipse插件安装
chenyu19891124
eclipse插件
今天花了一天时间弄SVN和Eclipse插件的安装,今天弄好了。svn插件和Eclipse整合有两种方式,一种是直接下载插件包,二种是通过Eclipse在线更新。由于之前Eclipse版本和svn插件版本有差别,始终是没装上。最后在网上找到了适合的版本。所用的环境系统:windows7JDK:1.7svn插件包版本:1.8.16Eclipse:3.7.2工具下载地址:Eclipse下在地址:htt
- [转帖]工作流引擎设计思路
comsci
设计模式工作应用服务器workflow企业应用
作为国内的同行,我非常希望在流程设计方面和大家交流,刚发现篇好文(那么好的文章,现在才发现,可惜),关于流程设计的一些原理,个人觉得本文站得高,看得远,比俺的文章有深度,转载如下
=================================================================================
自开博以来不断有朋友来探讨工作流引擎该如何
- Linux 查看内存,CPU及硬盘大小的方法
daizj
linuxcpu内存硬盘大小
一、查看CPU信息的命令
[root@R4 ~]# cat /proc/cpuinfo |grep "model name" && cat /proc/cpuinfo |grep "physical id"
model name : Intel(R) Xeon(R) CPU X5450 @ 3.00GHz
model name :
- linux 踢出在线用户
dongwei_6688
linux
两个步骤:
1.用w命令找到要踢出的用户,比如下面:
[root@localhost ~]# w
18:16:55 up 39 days, 8:27, 3 users, load average: 0.03, 0.03, 0.00
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
- 放手吧,就像不曾拥有过一样
dcj3sjt126com
内容提要:
静悠悠编著的《放手吧就像不曾拥有过一样》集结“全球华语世界最舒缓心灵”的精华故事,触碰生命最深层次的感动,献给全世界亿万读者。《放手吧就像不曾拥有过一样》的作者衷心地祝愿每一位读者都给自己一个重新出发的理由,将那些令你痛苦的、扛起的、背负的,一并都放下吧!把憔悴的面容换做一种清淡的微笑,把沉重的步伐调节成春天五线谱上的音符,让自己踏着轻快的节奏,在人生的海面上悠然漂荡,享受宁静与
- php二进制安全的含义
dcj3sjt126com
PHP
PHP里,有string的概念。
string里,每个字符的大小为byte(与PHP相比,Java的每个字符为Character,是UTF8字符,C语言的每个字符可以在编译时选择)。
byte里,有ASCII代码的字符,例如ABC,123,abc,也有一些特殊字符,例如回车,退格之类的。
特殊字符很多是不能显示的。或者说,他们的显示方式没有标准,例如编码65到哪儿都是字母A,编码97到哪儿都是字符
- Linux下禁用T440s,X240的一体化触摸板(touchpad)
gashero
linuxThinkPad触摸板
自打1月买了Thinkpad T440s就一直很火大,其中最让人恼火的莫过于触摸板。
Thinkpad的经典就包括用了小红点(TrackPoint)。但是小红点只能定位,还是需要鼠标的左右键的。但是自打T440s等开始启用了一体化触摸板,不再有实体的按键了。问题是要是好用也行。
实际使用中,触摸板一堆问题,比如定位有抖动,以及按键时会有飘逸。这就导致了单击经常就
- graph_dfs
hcx2013
Graph
package edu.xidian.graph;
class MyStack {
private final int SIZE = 20;
private int[] st;
private int top;
public MyStack() {
st = new int[SIZE];
top = -1;
}
public void push(i
- Spring4.1新特性——Spring核心部分及其他
jinnianshilongnian
spring 4.1
目录
Spring4.1新特性——综述
Spring4.1新特性——Spring核心部分及其他
Spring4.1新特性——Spring缓存框架增强
Spring4.1新特性——异步调用和事件机制的异常处理
Spring4.1新特性——数据库集成测试脚本初始化
Spring4.1新特性——Spring MVC增强
Spring4.1新特性——页面自动化测试框架Spring MVC T
- 配置HiveServer2的安全策略之自定义用户名密码验证
liyonghui160com
具体从网上看
http://doc.mapr.com/display/MapR/Using+HiveServer2#UsingHiveServer2-ConfiguringCustomAuthentication
LDAP Authentication using OpenLDAP
Setting
- 一位30多的程序员生涯经验总结
pda158
编程工作生活咨询
1.客户在接触到产品之后,才会真正明白自己的需求。
这是我在我的第一份工作上面学来的。只有当我们给客户展示产品的时候,他们才会意识到哪些是必须的。给出一个功能性原型设计远远比一张长长的文字表格要好。 2.只要有充足的时间,所有安全防御系统都将失败。
安全防御现如今是全世界都在关注的大课题、大挑战。我们必须时时刻刻积极完善它,因为黑客只要有一次成功,就可以彻底打败你。 3.
- 分布式web服务架构的演变
自由的奴隶
linuxWeb应用服务器互联网
最开始,由于某些想法,于是在互联网上搭建了一个网站,这个时候甚至有可能主机都是租借的,但由于这篇文章我们只关注架构的演变历程,因此就假设这个时候已经是托管了一台主机,并且有一定的带宽了,这个时候由于网站具备了一定的特色,吸引了部分人访问,逐渐你发现系统的压力越来越高,响应速度越来越慢,而这个时候比较明显的是数据库和应用互相影响,应用出问题了,数据库也很容易出现问题,而数据库出问题的时候,应用也容易
- 初探Druid连接池之二——慢SQL日志记录
xingsan_zhang
日志连接池druid慢SQL
由于工作原因,这里先不说连接数据库部分的配置,后面会补上,直接进入慢SQL日志记录。
1.applicationContext.xml中增加如下配置:
<bean abstract="true" id="mysql_database" class="com.alibaba.druid.pool.DruidDataSourc