Plist图集批量拆解工具大全
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、为什么需要图集打包?
- 二、使用python批量拆解plist格式文件
-
- 1.引入库
- 2.具体实现代码
- 三、使用python批量拆解laya引擎图集文件
- 四、使用python批量拆解Egret引擎图集文件
- 附Gitee传送地址
- Creator拆图工具
- 总结
前言
因为学习需要制作游戏,经常会在网上寻找一些资源进行学习,而一般资源分积分下载源资源或者线上扒取别人的图集资源。所以很多时候需要对一张合集图进行拆分,今天主要讲解有描述文件的图集拆分。
我常接触的图集格式一般是
CocosCreator TexturePacker .plst 格式的图集
LayaBox .json ,atlas引擎自带贴图合集格式
Egret 引擎的.json图集格式
一、为什么需要图集打包?
做过游戏开发的童靴都知道纹理打包,用于下载节约流量减少io操作。也能让渲染合批提升性能。市面上常用打包工具TexturePacker,还有一些引擎自带图集打包的工具。
二、使用python批量拆解plist格式文件
1.引入库
代码如下(示例):
Python库主要依赖PIL下Image模板对图片的操作
import os,sys
from xml.etree import ElementTree
from PIL import Image
reload(sys)
sys.setdefaultencoding('utf8')
2.具体实现代码
代码如下(示例):
#!python
# coding: utf-8
import os,sys
from xml.etree import ElementTree
from PIL import Image
reload(sys)
sys.setdefaultencoding('utf8')
def tree_to_dict(tree):
d = {
}
for index, item in enumerate(tree):
if item.tag == 'key':
if tree[index+1].tag == 'string':
d[item.text] = tree[index + 1].text
elif tree[index + 1].tag == 'true':
d[item.text] = True
elif tree[index + 1].tag == 'false':
d[item.text] = False
elif tree[index + 1].tag == 'integer':
d[item.text] = int(tree[index + 1].text)
elif tree[index+1].tag == 'dict':
d[item.text] = tree_to_dict(tree[index+1])
return d
def read_rect(dict):
return [dict['x'],dict['y'],dict['width'],dict['height']];
def gen_png_from_plist(filename, outPath):
plist_filename = filename + '.plist'
png_filename = filename + '.png'
if checkPath(plist_filename) == False or checkPath(png_filename) ==False:
print("don't find %s png or plist"%filename)
return
#获取大图
big_image = Image.open(png_filename)
#读取plist
root = ElementTree.fromstring(open(plist_filename, 'r').read())
plist_dict = tree_to_dict(root[0])
to_list = lambda x: x.replace('{','').replace('}','').split(',')
to_int = lambda x:int(x)
for k,v in plist_dict['frames'].items():
if v.has_key('textureRect'):
textureRect = to_list(v['textureRect'])
elif v.has_key('frame'):
textureRect = to_list(v['frame'])
else:
textureRect = read_rect(v)
#获得图像尺寸
if v.has_key('spriteSize'):
spriteSize = v['spriteSize']
elif v.has_key('sourceSize'):
spriteSize = v['sourceSize']
elif v.has_key('spriteSourceSize'):
spriteSize = v['spriteSourceSize']
elif v.has_key("width"):
spriteSize = str(v['width']) + ',' + str(v['height'])
spriteSize = to_list(spriteSize)
spriteSize = map(to_int, spriteSize)
result_box = textureRect
#防止宽高小于0导致错误
if spriteSize[0] <= 0 or spriteSize[1]<0 :
print "< 0"
continue
result_image = Image.new('RGBA', spriteSize, (0,0,0,0))
if (v.has_key('textureRotated') and v['textureRotated']) or (v.has_key('rotated') and v['rotated']):
result_box[0] = int(textureRect[0])
result_box[1] = int(textureRect[1])
result_box[2] = int(textureRect[0] + spriteSize[1])
result_box[3] = int(textureRect[1] + spriteSize[0])
else:
result_box[0] = int(textureRect[0])
result_box[1] = int(textureRect[1])
result_box[2] = int(textureRect[0] + spriteSize[0])
result_box[3] = int(textureRect[1] + spriteSize[1])
#获得小图
rect_on_big = big_image.crop(result_box)
# 有旋转
if (v.has_key('textureRotated') and v['textureRotated']) or (v.has_key('rotated') and v['rotated']):
rect_on_big = rect_on_big.transpose(Image.ROTATE_90)
result_image.paste(rect_on_big)
if not os.path.isdir(outPath):
os.mkdir(outPath)
k = k.replace('/', '_')
outfile = (outPath+'/' + k).replace('gift_', '')
#print k
if outfile.find('.png') == -1:
outfile = outfile + '.png'
print outfile, "generated"
result_image.save(outfile)
def read_dir( path, outPath):
for name in os.listdir( path ):
if os.path.isdir( os.path.join(path, name) ):
find_file(os.path.join(path, name),outPath )
else:
portion = os.path.splitext(name)
if portion[1] == '.plist':
fileName = os.path.join(path, portion[0])
outDir = os.path.join(outPath, portion[0]);
gen_png_from_plist(fileName , outDir)
def checkPath(path):
if not os.path.exists( path ):
print "not find 1 %s"%path
return False
return True
if __name__ == '__main__':
if len( sys.argv ) < 2:
dirName = raw_input("Enter your DirName: ")
else:
dirName = sys.argv[1]
if len( sys.argv ) < 3:
outPath = raw_input("Enter your outPath: ")
else:
outPath = sys.argv[2]
outPath = os.path.join( os.getcwd(), outPath )
if not os.path.isdir( outPath ):
os.mkdir( outPath )
path = os.path.join(os.getcwd(),dirName)
if checkPath(path):
read_dir(path,outPath)
三、使用python批量拆解laya引擎图集文件
# coding: utf-8
import os
import sys
import json
import time
from PIL import Image
def checkPath(path):
if not os.path.exists( path ):
print "not find 1 %s"%path
return False
return True
def splitImage(path, fileName, outPath ):
# 检查JSON文件
jsonPath = os.path.join(path, "%s.json"%fileName )
if not os.path.exists( jsonPath ):
jsonPath = os.path.join( path, "%s.atlas"%(fileName ))
if not os.path.exists( jsonPath ):
print "not find 0 {}".format(jsonPath)
return
# 检查PNG文件
pngPath = os.path.join( path, "%s.png"%fileName )
if checkPath(pngPath) == False:
return
# 检查输出目录
outPath = os.path.join( path, outPath )
if not os.path.isdir( outPath ):
os.mkdir( outPath )
# 取JSON文件
f = open( jsonPath, 'r' )
fileStr = f.read()
f.close()
jsonData = json.loads( fileStr )
#检查image集合
meta = jsonData.get( "meta" )
imageStr = meta.get( "image" )
#拆分文件名
images = imageStr.split(",")
#拆分文件名
images = imageStr.split(",")
imgList = []
#打开多个文件准备切割
for img in images:
pngPath = os.path.join( path, img )
pngPath = pngPath.replace("~","-")
if not os.path.exists( pngPath ):
print "not find 2 %s"%pngPath
break;
imgList.append(Image.open( pngPath, 'r' ))
# 开始切图
lastIdx = 0
frames = jsonData.get( "frames" )
for fn in frames.keys():
data = frames.get( fn )
frame = data.get( "frame" )
idx = frame.get( "idx" )
x = frame.get("x")
y = frame.get("y")
w = frame.get("w")
h = frame.get("h")
box = ( x, y, x+w, y+h )
outFile = os.path.join( outPath, fn )
imgData = imgList[idx].crop( box )
imgData.save( outFile, 'png' )
#读取指定目录
def find_file( path, outPath):
for name in os.listdir( path ):
if os.path.isdir( os.path.join(path, name) ):
find_file(os.path.join(path, name),outPath )
else:
portion = os.path.splitext(name)
if portion[1] == '.atlas' or portion[1] == '.json':
fileName = os.path.join(path, portion[0])
outDir = os.path.join(outPath, portion[0]);
splitImage(path,fileName , outDir)
if __name__=='__main__':
# 取得参数
if len( sys.argv ) < 2:
target = raw_input("Enter your DirName: ")
else:
target = sys.argv[1]
if len( sys.argv ) < 3:
outPath = raw_input("Enter your outPath: ")
else:
outPath = sys.argv[2]
outPath = os.path.join( os.getcwd(), outPath )
if not os.path.isdir( outPath ):
os.mkdir( outPath )
path = os.path.join(os.getcwd(),target)
if checkPath(path):
find_file(path,outPath)
四、使用python批量拆解Egret引擎图集文件
# coding: utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf8')
import os
import json
import time
from PIL import Image
def checkPath(path):
if not os.path.exists( path ):
print "not find 1 %s"%path
return False
return True
def splitImage(path, fileName, outPath ):
# 检查JSON文件
jsonPath = os.path.join( path, "%s.json"%fileName )
if not os.path.exists( jsonPath ):
print "not find %s"%jsonPath
return
# 检查PNG文件
pngPath = os.path.join( path, "%s.png"%fileName )
if not os.path.exists( pngPath ):
print "not find %s"%pngPath
return
# 检查输出目录
if not os.path.isdir( outPath ):
os.mkdir( outPath )
# 取JSON文件
f = open( jsonPath, 'r' )
fileStr = f.read()
f.close()
jsonData = json.loads( fileStr )
#检查image集合
imgList = []
imageStr = jsonData.get( "file" )
img = Image.open(os.path.join(path,imageStr),'r')
imgList.append(img)
# 开始切图
frames = jsonData.get( "frames" )
for fn in frames.keys():
data = frames.get( fn )
x = data.get("x")
y = data.get("y")
w = data.get("w")
h = data.get("h")
box = ( x, y, x+w, y+h )
outFile = os.path.join( outPath, fn )
imgData = imgList[0].crop( box )
# if imgData.mode == "P":
# imgData = imgData.convert('RGB')
outFile = outFile + ".png"
imgData.save( outFile )
#读取指定目录
def find_file( path, outPath):
for name in os.listdir( path ):
if os.path.isdir( os.path.join(path, name) ):
find_file(os.path.join(path, name),outPath )
else:
portion = os.path.splitext(name)
if portion[1] == '.json':
fileName = portion[0]
outDir = os.path.join(outPath, portion[0]);
splitImage( path ,fileName, outDir )
if __name__=='__main__':
# 取得参数
if len( sys.argv ) < 2:
dirName = raw_input("Enter your dirName: ")
else:
dirName = sys.argv[1]
if len( sys.argv ) < 3:
outPath = raw_input("Enter your outPath: ")
else:
outPath = sys.argv[2]
outPath = os.path.join( os.getcwd(), outPath )
if not os.path.isdir( outPath ):
os.mkdir( outPath )
path = os.path.join(os.getcwd(),dirName)
if checkPath(path):
# 开始切图
find_file(path, outPath)
附Gitee传送地址
仓库传送门
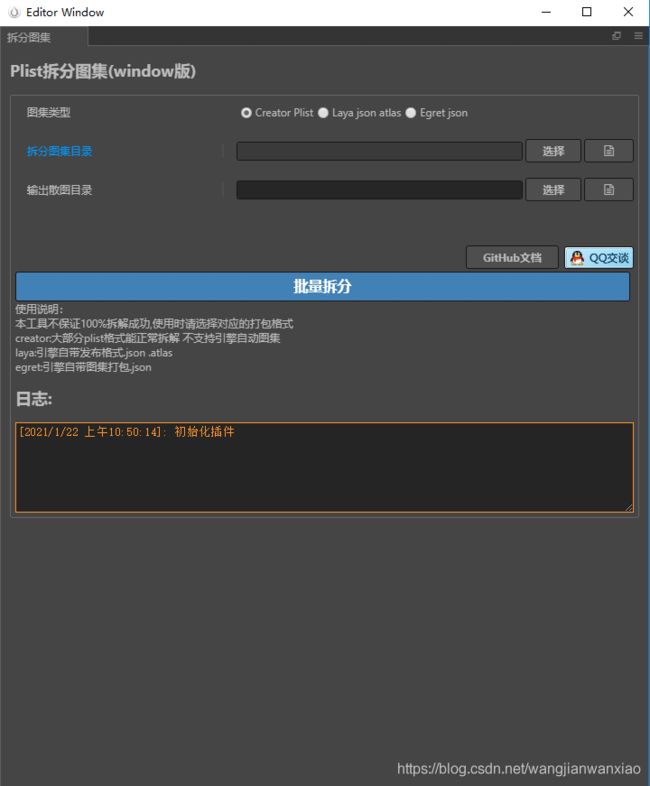
Creator拆图工具
小弟因为平时使用creator开发比较多,所以在creator扩展商店上架了一个免费的插件工具目前只做了windows系统的,欢迎各位下载使用
总结
希望能帮到有需要的人。谢谢