2021年大数据Hive(一):Hive基本概念
全网最详细的Hive文章系列,强烈建议收藏加关注!
后面更新文章都会列出历史文章目录,帮助大家回顾知识重点。
目录
历史文章
前言
Hive基本概念
一、Hive介绍
1、什么是Hive
2、为什么使用Hive
3、Hive的特点
二、Hive架构
1、架构图
2、基本组成
3、Hive与传统数据库对比
历史文章
深夜凌晨女朋友问什么是数据仓库,我的回答让她惊讶,然后发现。。。
百度、阿里、腾讯平台架构都熟悉,小米大数据平台架构OLAP架构演进是否了解
女朋友问阿里双十一实时大屏如何实现,我惊呆一会,马上手把手教她背后的大数据技术
前言
2021年全网最详细的大数据笔记,轻松带你从入门到精通,该栏目每天更新,汇总知识分享

Hive基本概念
一、Hive介绍
1、什么是Hive
Hive是一个构建在Hadoop上的数据仓库框架。最初,Hive是由Facebook开发,后来移交由Apache软件基金会开发,并作为一个Apache开源项目。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
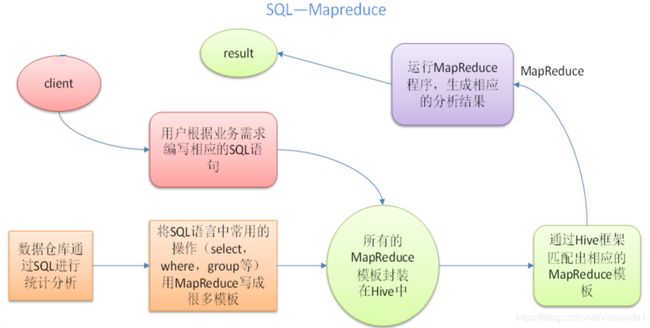
其本质是将SQL转换为MapReduce的任务进行运算,底层由HDFS来提供数据的存储,说白了hive可以理解为一个将SQL转换为MapReduce的任务的工具,甚至更进一步可以说hive就是一个MapReduce的客户端。
2、为什么使用Hive
- 直接使用hadoop所面临的问题
- 人员学习成本太高
- 项目周期要求太短
- MapReduce实现复杂查询逻辑开发难度太大
- 为什么要使用Hive
- 操作接口采用类SQL语法,提供快速开发的能力
- 避免了去写MapReduce,减少开发人员的学习成本
- 功能扩展很方便
3、Hive的特点
- Hive最大的特点是通过类SQL来分析大数据,而避免了写MapReduce程序来分析数据,这样使得分析数据更容易。
- 数据是存储在HDFS上的,Hive本身并不提供数据的存储功能,它可以使已经存储的数据结构化。
- Hive是将数据映射成数据库和一张张的表,库和表的元数据信息一般存在关系型数据库上(比如MySQL)。
- 数据存储方面:它能够存储很大的数据集,可以直接访问存储在Apache HDFS或其他数据存储系统(如Apache HBase)中的文件。
- 数据处理方面:因为Hive语句最终会生成MapReduce任务去计算,所以不适用于实时计算的场景,它适用于离线分析。
- Hive除了支持MapReduce计算引擎,还支持Spark和Tez这两种分布式计算引擎;
- 数据的存储格式有多种,比如数据源是二进制格式,普通文本格式等等;
二、Hive架构
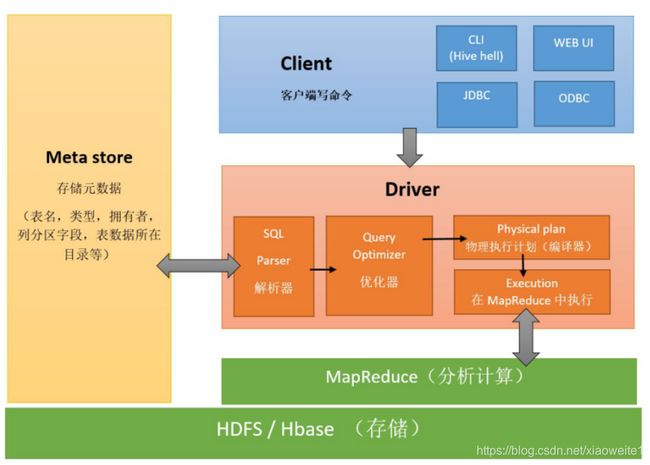
1、架构图
2、基本组成
客户端:Client CLI(hive shell 命令行),JDBC/ODBC(java访问hive),WEBUI(浏览器访问hive)
元数据:Metastore:本质上只是用来存储hive中有哪些数据库,哪些表,表的字段,,表所属数据库(默认是default) ,分区,表的数据所在目录等,元数据默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore。
驱动器:Driver
(1)解析器(SQL Parser):将SQL字符转换成抽象语法树AST,这一步一般使用都是第三方工具库完成,比如antlr,对AST进行语法分析,比如表是否存在,字段是否存在,SQL语句是否有误
(2)编译器(Physical Plan):将AST编译生成逻辑执行计划
(3)优化器(Query Optimizer):对逻辑执行计划进行优化
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划,对于Hive来说,就是MR/Spark
存储和执行:Hive使用HDFS进行存储,使用MapReduce进行计算
3、Hive与传统数据库对比
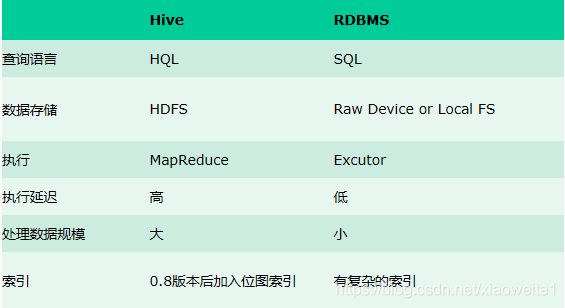
总结:hive具有sql数据库的外表,但应用场景完全不同,hive只适合用来做批量数据统计分析
本博客大数据系列文章会一直每天更新,记得收藏加关注喔~