1. 基础概念
- 什么叫序列化——将原本的字典、列表等内容转换成一个字符串的过程就叫做序列化。
- 序列化的目的:
- 以某种存储形式使自定义对象持久化
- 将对象从一个地方传递到另一个地方
-
使程序更具维护性
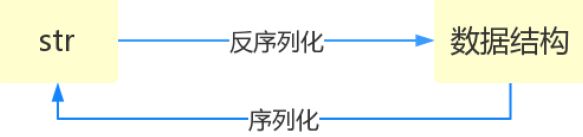 image.png
image.png
- 常用的模块
- json
- pickle
- shelve
2. json
- 通用的序列化格式
- 只有很少一部分数据类型能够通过json转化成字符串
- 数字, 字符串, 列表, 字典, 元组(转为列表)可以序列化,集合不可以序列化。
Json模块提供了四个功能:dumps、dump、loads、load -
- loads(内存序列化)和dumps(内存反序列化)
import json
dic = {'k1':'v1','k2':'v2','k3':'v3'}
str_dic = json.dumps(dic) #序列化:将一个字典转换成一个字符串
print(type(str_dic),str_dic) # {"k3": "v3", "k1": "v1", "k2": "v2"}
#注意,json转换完的字符串类型的字典中的字符串是由""表示的
dic2 = json.loads(str_dic) #反序列化:将一个字符串格式的字典转换成一个字典
#注意,要用json的loads功能处理的字符串类型的字典中的字符串必须由""表示
print(type(dic2),dic2) # {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
list_dic = [1,['a','b','c'],3,{'k1':'v1','k2':'v2'}]
str_dic = json.dumps(list_dic) #也可以处理嵌套的数据类型
print(type(str_dic),str_dic)
# [1, ["a", "b", "c"], 3, {"k1": "v1", "k2": "v2"}]
list_dic2 = json.loads(str_dic)
print(type(list_dic2),list_dic2)
# [1, ['a', 'b', 'c'], 3, {'k1': 'v1', 'k2': 'v2'}]
-
- dump(文件)和load(文件)
import json
f = open('json_file','w')
dic = {'k1':'v1','k2':'v2','k3':'v3'}
json.dump(dic,f) #dump方法接收一个文件句柄,直接将字典转换成json字符串写入文件
f.close()
f = open('json_file')
dic2 = json.load(f) #load方法接收一个文件句柄,直接将文件中的json字符串转换成数据结构返回
f.close()
print(type(dic2),dic2)
-
- ensure_ascii关键字参数
import json
f = open('file','w')
json.dump({'国籍':'中国'},f)
ret = json.dumps({'国籍':'中国'})
f.write(ret+'\n')
json.dump({'国籍':'美国'},f,ensure_ascii=False)
ret = json.dumps({'国籍':'美国'},ensure_ascii=False)
f.write(ret+'\n')
f.close()
-
- 其他参数
Skipkeys:默认值是False,如果dict的keys内的数据不是python的基本类型(str,unicode,int,long,float,bool,None),设置为False时,就会报TypeError的错误。此时设置成True,则会跳过这类key
ensure_ascii: 当它为True的时候,所有非ASCII码字符显示为\uXXXX序列,只需在dump时将ensure_ascii设置为False即可,此时存入json的中文即可正常显示。)
check_circular: If check_circular is false, then the circular reference check for container types will be skipped and a circular reference will result in an OverflowError (or worse).
allow_nan: If allow_nan is false, then it will be a ValueError to serialize out of range float values (nan, inf, -inf) in strict compliance of the JSON specification, instead of using the JavaScript equivalents (NaN, Infinity, -Infinity).
indent:应该是一个非负的整型,如果是0就是顶格分行显示,如果为空就是一行最紧凑显示,否则会换行且按照indent的数值显示前面的空白分行显示,这样打印出来的json数据也叫pretty-printed json
separators:分隔符,实际上是(item_separator, dict_separator)的一个元组,默认的就是(‘,’,’:’);这表示dictionary内keys之间用“,”隔开,而KEY和value之间用“:”隔开。
default(obj) is a function that should return a serializable version of obj or raise TypeError. The default simply raises TypeError.
sort_keys:将数据根据keys的值进行排序。
To use a custom JSON Encoder subclass (e.g. one that overrides the .default() method to serialize additional types), specify it with the cls kwarg; otherwise JSONEncoder is used.
-
- json格式化输出
import json
data = {'username':['李华','二愣子'],'sex':'male','age':16}
json_dic2 = json.dumps(data,sort_keys=True,indent=2,separators=(',',':'),ensure_ascii=False)
print(json_dic2)
3. pickle
- 所有的python中的数据类型都可以转化成字符串形式;
- pickle序列化的内容只有python能理解;
- 且部分反序列化依赖代码。
- pickle模块提供了四个功能:dumps、dump(序列化,存)、loads(反序列化,读)、load (不仅可以序列化字典,列表...可以把python中任意的数据类型序列化)
- pickle可以分步dump和load
import pickle
dic = {'k1':'v1','k2':'v2','k3':'v3'}
str_dic = pickle.dumps(dic)
print(str_dic) #一串二进制内容
dic2 = pickle.loads(str_dic)
print(dic2) #字典
import time
struct_time1 = time.localtime(1000000000)
struct_time2 = time.localtime(2000000000)
print(struct_time1)
print(struct_time2)
f = open('pickle_file','wb')
pickle.dump(struct_time1,f)
pickle.dump(struct_time2,f)
f.close()
f = open('pickle_file','rb')
struct_time1 = pickle.load(f)
struct_time2 = pickle.load(f)
print(struct_time1.tm_year)
print(struct_time2.tm_year)
f.close()
4. shelve
shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式,是pickle 更上一层的封装.
shelve不支持多个应用同时往同一个DB中进行写操作,所以当我们知道我们的应用如果只进行读操作,我们可以让shelve通过只读方式打开DB.
shelve 有一个open函数,使用序列化句柄直接操作,非常方便
Shelve模块提供了基本的存储操作,Shelve中的open函数在调用的时候返回一个shelf对象,通过该对象可以存储内容,即像操作字典一样进行存储操作。当在该对象中查找元素时,对象会根据已经存储的版本进行重新构建,当给某个键赋值的时候,元素会被存储。
windows下shelve文件是生成三个,两个可读一个不可读,linux下生成一个二进制文件,不可读
-
- 序列化
import shelve
def member_info(name, age):
print('Member info:', name, age)
name = ['Jack', 'Pumpkin', 'Tom']
info = {'name': 'Pumpkin', 'age': 20}
with shelve.open('shelve_demo') as data:
data['name'] = name
data['info'] = info
data['func'] = member_info
-
- 反序列化
def member_info(name, age):
print('Member info:', name, age)
with shelve.open('shelve_demo') as data:
print(data['name'])
print(data['info'])
print(data['func']('Alex', 22))
# 结果输出:
['Jack', 'Pumpkin', 'Tom']
{'name': 'Pumpkin', 'age': 20}
Member info: Alex 22
None
-
- value值的修改
一般情况下,我们通过shelve来open一个对象后,只能进行一次赋值处理,赋值后不能再次更新处理。
- value值的修改
def member_info(name, age):
print("Member info:", name, age)
name = ['Jack', 'Pumpkin', 'Tom']
info = {'name':'Pumpkin', 'age':18}
with shelve.open('shelve_demo') as data:
data['name'] = name
data['info'] = info
data['name'].append('Alex')
print(data['name'])
输出:
['Jack', 'Pumpkin', 'Tom'] # 第一次赋值后apend的元素并没有生效
再次open打开结果也是这样:
import shelve
def member_info(name, age):
print("Member info:", name, age)
name = ['Jack', 'Pumpkin', 'Tom']
info = {'name':'Pumpkin', 'age':18}
with shelve.open('shelve_demo') as data:
print(data['name'])
造成上述情况的原因是:我们只是修改了shelve对象的副本,而它并木有被最终保存。此时我们除了下文要讲述的update方法外,还有以下两种方法:
方法一: shelve open一个对象后,先用临时变量指向对象副本,在临时变量上修改后让对象副本再次指向临时变量,从而覆盖保存对象副本。这种方法的本质是对open后的对象重新赋新值,并非在原有基础上进行update,也就是open后的对象内存指向地址发生了变化。
import shelve
def member_info(name, age):
print("Member info:", name, age)
name = ['Jack', 'Pumpkin', 'Tom']
info = {'name':'Pumpkin', 'age':18}
with shelve.open('shelve_demo') as data:
data['name'] = name
data['info'] = info
temp = data['name'] # 这里的关键点在于对临时变量的使用
temp.append('Alex')
data['name'] = temp
print(data['name'])
输出:
['Jack', 'Pumpkin', 'Tom', 'Alex']
方法二:借助open的writeback=True参数来实现,默认情况下该参数的值为False。
import shelve
def member_info(name, age):
print("Member info:", name, age)
name = ['Jack', 'Pumpkin', 'Tom']
info = {'name':'Pumpkin', 'age':18}
with shelve.open('shelve_demo', writeback=True) as data:
data['name'] = name
data['info'] = info
data['name'].append('Alex')
print(data['name'])
输出:
['Jack', 'Pumpkin', 'Tom', 'Alex']
-
- update方法
value值的更新还有一个update方法,使用起来也比较方便
- update方法
import shelve
def member_info(name, age):
print("Member info:", name, age)
name = ['Jack', 'Pumpkin', 'Tom']
info = {'name':'Pumpkin', 'age':18}
with shelve.open('shelve_demo', writeback=True) as data:
data['name'] = name
data['info'] = info
data.update({'name':['Jack', 'Pumpkin', 'Tom', 'Alex']}) # 这里也是重新赋值
print(data['name'])
输出:
['Jack', 'Pumpkin', 'Tom', 'Alex']
重新load一下看看结果:
import shelve
def member_info(name, age):
print("Member info:", name, age)
name = ['Jack', 'Pumpkin', 'Tom']
info = {'name':'Pumpkin', 'age':18}
with shelve.open('shelve_demo') as data:
print(data['name'])
输出:
['Jack', 'Pumpkin', 'Tom', 'Alex']
-
- get方法
通过shelve.open反序列化load对象到内存后,可以通过get方法来获取key对应的value:
- get方法
import shelve
def member_info(name, age):
print("Member info:", name, age)
name = ['Jack', 'Pumpkin', 'Tom']
info = {'name':'Pumpkin', 'age':18}
with shelve.open('shelve_demo') as data:
print(data.get('name'))
输出:
['Jack', 'Pumpkin', 'Tom', 'Alex']
5. 总结
1、需要与外部系统交互时用json模块;
2、需要将少量、简单Python数据持久化到本地磁盘文件时可以考虑用pickle模块;
3、需要将大量Python数据持久化到本地磁盘文件或需要一些简单的类似数据库的增删改查功能时,可以考虑用shelve模块。