Lambda表达式的作用就相当于一个回调方法,Stream API中大量使用Lambda表达式作为回调方法。
再谈流水线
其实在平时的编码中,在没有出现Stream之前,我们写的普通的for循环就可以看做是流水线,只是这个流水线是知道了用户行为的情况下写出来的。但是在编写通用类库时,是不知道用户行为的。那么在此情况下怎么了实现流水线?
解决:应该记录用户每一步的中间操作,当调用结束操作时将之前的操作叠加到一起,在一次迭代中全部执行。
中间操作如何记录?
中间操作如何叠加?
叠加后的中间操作如何执行?
执行后的结果如何展示?
中间操作:中间操作只是一种标记,只有结束操作才会触发实际计算。中间操作被分为无状态和有状态的。无状态中间操作:元素的处理不受前面元素的影响。有状态中间操作:必须等到所有元素处理之后操知道最终结果(排序是有状态的,在读取所有元素之前并不能确定排序结果)。
结束操作:结束操作分为短路操作和非短路操作。短路操作:不用处理完全部元素就可以返回结果。
中间操作如何记录
Stream相关的类图
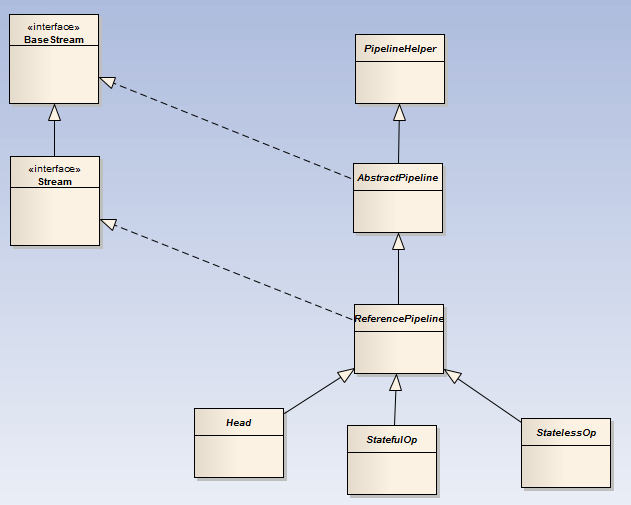
要形成流水线,在Java里面是采用链表的形式来处理。而Head就是此链表的头。
Head
Collection.stream()--->StreamSupport.stream()--->new ReferencePipeline.Head<>():当集合类调用stream方法时会产生一个Head,Head是AbstractPipeline的实例对象,最终构造方法如下:previousStage为空,sourceStage保持对Head的实例引用。
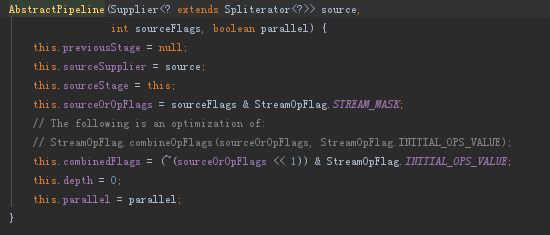
StatelessOp
无状态中间操作对象。调用流水线map,peek,filter等方法会产生StatelessOp对象,此StatelessOp实例对象中。

调用stream方法后返回Head,再Head上调用filter方法是设置以上参数。
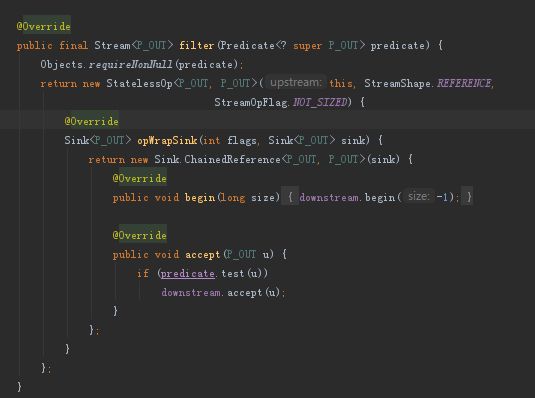
this:是head实例。
previousStage.nextStage:新创建的StatelessOp实例对象。
previousStage:head实例。
sourceStage:head实例。
返回一个无状态中间操作对象StatelessOp实例。
下一步再调用StatelessOp实例的filter。方法一样,只是里面的参数不一样。
this:调用filter方法的AbstractPipeline实例对象。
previousStage.nextStage:新创建的StatelessOp实例对象。
previousStage:调用filter方法的AbstractPipeline实例对象。
sourceStage:head实例。
如果下一步还是调用StatelessOp类型的方法(filter,map等),方法一样,里面的参数实例不同而已(StatefulOp类型和StatelessOp类似)。
流水线的操作最后都会以结束操作来结束。
通过上面的流程可以看出,中间操作(有状态操作和无状态操作)都会持有前一个中间操作的实例,并且也会让前一个中间操作的实例持有它后面的中间操作的实例。这样就形成了一个双向链表的流水线了。

第一次调用中间操作都会返回一个新的Stream,而这些Stream组成了双向链表,这个双向链表就是对数据源的所有操作。
中间操作如何叠加和如何执行
中间操作记录好了后,下一步就是如何让这些中间操作叠加在一起。或许会有疑问:上面的链式结构已经将中间操作链接在一起了,那么从链接的头开始一步步往下执行就好了。但是这里有个问题,虽然已经链接到一起了,中间操作也持有前后的引用。但是中间操作只知道本身应该执行什么操作,并不知道它后面的中间操作执行的操作时什么。所以并不能按照这种流程来执行流水线。
这时需要把所有中间操作的执行都封装成同一个接口,实现同一个方法。这样前一个中间操作并不需要知道后面操作执行什么。直接调用接口方法,把本次的操作结果传到下一个中间操作即可。
这个思路是由Sink接口来完成。
default void begin(long size):开始遍历元素之前调用的方法。
default void end():所有元素遍历完成之后调用。
default boolean cancellationRequested():是否可以结束操作。让短路操作尽快结束。
default void accept(long value):遍历元素时调用,接受一个待处理元素,并对元素进行处理。
所有的中间操作都通过了Sink接口关联在一起。就像机器中的齿轮一样,所有的齿轮已经全部咬合在一起了,就差最后通电启动了。在流水线上的通电操作就是最后的结束操作。一旦调用结束操作,就启动了流水线上所有的操作执行。
通过以下流水操作来具体看看操作的叠加和执行:Stream.of()-->map()-->filter()-->sorted()-->limit()--reduce()。
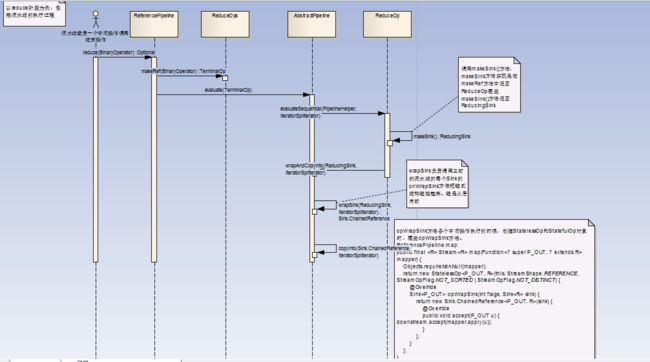
opWrapSink():
每个中间操作都覆盖此方法,得到一个Sink对象,Sink对象中:downstream变量保存了此中间操作的下一个操作的Sink对象(调用此中间操作的accept方法后,就会把此中间操作处理的结果传递给下一个中间操作:downstream.accept())。
AbstractPipeline.wrapSink():
调用所有操作的opWrapSink方法,把流水线上的操作封装成Sink对象,并且让Sink实例中的downstream变量持有下一个操作的Sink对象的应用。
wrapSink返回流水线上最开始的操作的Sink(此操作是Head的下一个操作,不是Head,因为Head代表数据源,不代表操作)。
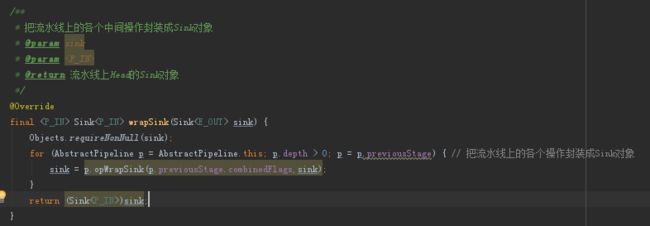
流水线现在已经被封装成了Sink流水线,执行Sink就等于执行整个流水线。
AbstractPipeline.copyInto():

手动画了一下流水线上执行过程:

一个双向链表+统一的调用接口就可以实现Stream的流水线。
参考:
深入理解Java Stream流水线 - CarpenterLee - 博客园