ZAB 协议是为分布式协调服务ZooKeeper专门设计的一种支持崩溃恢复的一致性协议。基于该协议,ZooKeeper 实现了一种主从模式的系统架构来保持集群中各个副本之间的数据一致性。今天主要看看这个zab协议的工作原理。
一、什么是ZAB协议
话说在分布式系统中一般都要使用主从系统架构模型,指的是一台leader服务器负责外部客户端的写请求。然后其他的都是follower服务器
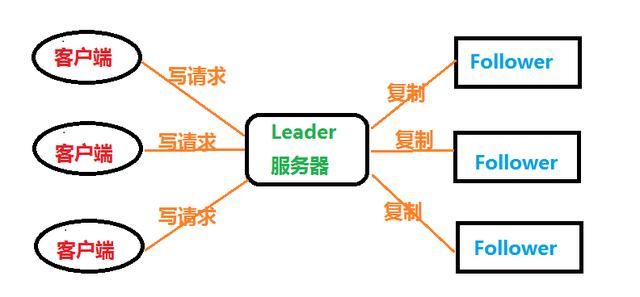
就这样,客户端发送来的写请求,全部给Leader,然后leader再转给Follower。这时候需要解决两个问题:
(1)leader服务器是如何把数据更新到所有的Follower的。
(2)Leader服务器突然间失效了,怎么办?
因此ZAB协议为了解决上面两个问题,设计了两种模式:
(1)消息广播模式:把数据更新到所有的Follower
(2)崩溃恢复模式:Leader发生崩溃时,如何恢复
OK。现在带着这两个问题,我们来详细的看一下:
二、ZAB协议工作原理
1、消息广播模式:
如果你了解过2PC协议的话,理解起来就简单很多了,消息广播的过程实际上是一个简化版本的二阶段提交过程。我们来看一下这个过程:
(1)Leader将客户端的request转化成一个Proposal(提议)
(2)Leader为每一个Follower准备了一个FIFO队列,并把Proposal发送到队列上。‘
(3)leader若收到follower的半数以上ACK反馈
(4)Leader向所有的follower发送commit。
其实通俗的理解就比较简单了,我是领导,我要向各位传达指令,不过传达之前我先问一下大家支不支持我,若有一半以上的人支持我,那我就向各位传达指令了。
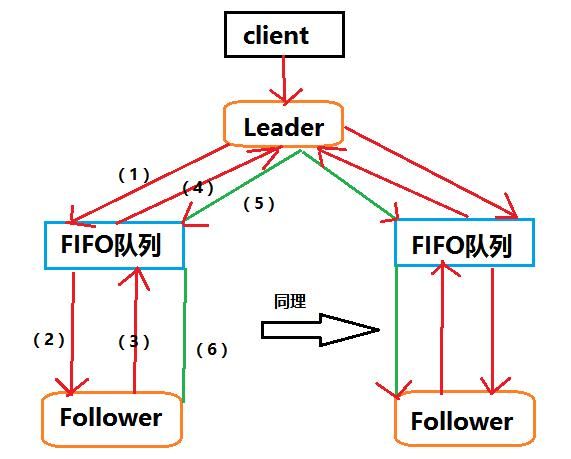
(1)leader首先把proposal发送到FIFO队列里
(2)FIFO取出队头proposal给Follower
(3)Follower反馈一个ACK给队列
(4)队列把ACK交给leader
(5)leader收到半数以上ACK,就会发送commit指令给FIFO队列
(6)FIFO队列把commit给Follower。
这就是整个消息广播模式。下面我们开始看一下,如果这个leader节点崩溃了,怎么办?也就是第二种模式:崩溃回复模式。
2、崩溃恢复模式
leader就是一个领导,既然领导挂了,整个组织肯定不会散架,毕竟离开谁都能活下去是不是,这时候我们只需要选举一个新的领导即可,而且还要把前leader还未完成的工作做完,也就是说不仅要进行leader服务器选取,而且还要进行崩溃恢复。我们一个一个来解决。
(1)leader服务器选取
话说江湖上有一个神秘组织,这个组织分工明确,各司其职,平时这个组织的成员有三种状态:
looking状态:也就是观望状态,这时候是由于组织出现内部问题,那就停下来,做一些其他的事。
following状态:自身是一个组织成员,做自己的事。
leading状态:自身是一个组织老大,做自己的事。
但是这个组织只有一个老大。突然有一天,老大挂掉了,于是每一个成员的状态变成了looking状态。于是成员宣布要选举新的leader。

既然是选老大,每个人都想做,于是成员ABC开始了公平选举的过程。但是为了方便,每个人都有一个记录表,来记录当前的信息。
第一步:成员A告诉BC说我要成为老大,BC记录下来。(A成员广播)
第二步:B回复可以,C回复不可以。(B成员广播)
第三步:A和C收到B的消息,更新自己的记录表。
此时A:2票,B:0票,C:0票。
第四步:C这时候不满意了,也要选举成为老大。而且还给自己投了一票。
第五步:A回复可以,B回复可以。更新自己的记录表。
第六步:C收到AB的回复,更新。
此时A:0票,B:0,C:3票。于是确定C就是下一届组织老大了。
这就是整个选举的过程。并且每个人的选举,都代表了一个事件,为了保证分布式系统的时间有序性,因此给每一个事件都分配了一个Zxid。相当于编了一个号。
每当选举出一个新的leader时,新的leader就从本地事物日志中取出ZXID,然后解析出高32位的epoch编号,进行加1,再将

OK,老大选举完了,这时候前老大遗留下来的事还没完成呢,此时就要开始恢复了。
(2)崩溃恢复
既然要恢复,有些场景是不能恢复的,ZAB协议崩溃恢复要求满足如下2个要求: 第一: 确保已经被leader提交的proposal必须最终被所有的follower服务器提交。 第二:确保丢弃已经被leader出的但是没有被提交的proposal。
好了,现在开始进行恢复。
第一步:选取当前取出最大的ZXID,代表当前的事件是最新的。
第二步:新leader把这个事件proposal提交给其他的follower节点
第三步:follower节点会根据leader的消息进行回退或者是数据同步操作。最终目的要保证集群中所有节点的数据副本保持一致。
这就是整个恢复的过程,其实就是相当于有个日志一样的东西,记录每一次操作,然后把出事前的最新操作恢复,然后进行同步即可。
OK。这个就是ZAB协议的整个过程。
向上的路不拥挤 拥挤是因为大多数人选择舒适!我是愚公,要移山。
 微信图片_20200105134941.jpg
微信图片_20200105134941.jpg