使用工具
爬虫:
Python 3.6
requests
pyquery
pymongo
csv
可视化:
BDP
爬取目标
链家网站的租房信息
步骤
先来看下页面长什么样子
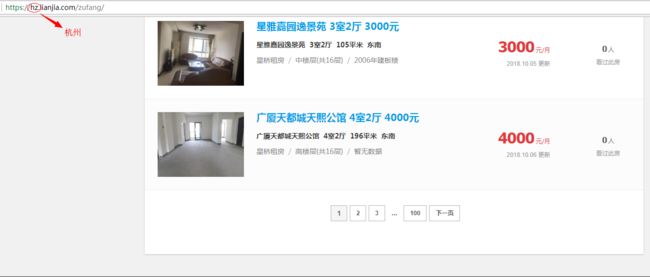

为了以防万一,登录一下看看是不是能看到1w页的数据...
这里我自己登录试了一下,依然只有100页,列表页信息与未登录状态无异,这样就省去了模拟登陆
同时可以看到列表页的url比较简单,hz就是杭州,如果想要爬取北京的租房信息,只需将hz改为bj即可,pg后面的数字即是页数,所以我们可以很简单的构造url来访问各个市所有页的租房信息


这里我只准备简单地爬取这些数据,放代码吧。
settings.py(用于配置mongodb的参数)
MONGO_URL = 'localhost'
MONGO_DB = 'Lianjia'
为了方便根据不同城市生成不同的collection,这里我将collection的配置放进了spider.py文件
spider.py
定义初始化函数:
class ZufangSpider():
def __init__(self):
self.city = 'hz' #要爬取的市
self.district = 'binjiang' #要爬取的区,如果不用,无视就行
self.hourse_info = [] #租房信息列表,后面将数据存入csv文件会用到
client = pymongo.MongoClient(MONGO_URL)
self.db = client[MONGO_DB]
# 根据爬取城市的不同动态生成不同的mongodb表名
self.mongo_collection = 'tenement-{}'.format(self.city)
获取列表页方法:
def get_index(self, url):
try:
response = requests.get(url)
# 当进入没有租房信息的页面时,将已爬取的数据存入csv并退出程序
if '没有找到' in response.text:
print('No more hourse')
self.save_csv()
sys.exit()
elif response.status_code == 200:
print('Get url:', url)
return response.text
return None
except ConnectionError:
return None


解析列表页方法(通过解析html文本获取需要的数据)
def parse_index(self, html):
doc = pq(html)
hourse_list = doc('.house-lst li').items()
for hourse in hourse_list:
title = hourse('.info-panel h2').text().replace(" ", "-").replace(",", "-")
desc_initial = hourse('.where').text().split()
desc = "-".join(desc_initial) # 格式处理
tags = hourse('.con').text()
location = '杭州' + desc_initial[0] # 用于转换经纬度
price = hourse('.price span').text()
update_time = hourse('.price-pre').text()[0:-3]
hourse_url = hourse('.pic-panel a').attr('href')
img_url = hourse('.pic-panel img').attr('data-img')
self.hourse_info.append([title, desc, tags, location, price, update_time, hourse_url, img_url])
self.hourse_dict = {
'title': title,
'desc': desc,
'tags': tags,
'location': location,
'price': price,
'update_time': update_time,
'hourse_url': hourse_url,
'img_url': img_url,
}
location = '杭州' + desc_initial[0] # 用于转换经纬度
这一步是因为后面做数据可视化的时候需要用到经纬度,在地名前面加上杭州是为了能够准确获取我们想要的经纬度

存储方法(csv,mongodb):
def save_csv(self):
# 将结果存入csv文件
with open('zufang-{}2.csv'.format(self.city), 'w', encoding='utf8', newline='') as f:
writer = csv.writer(f)
writer.writerow(['租房标题', '描述', '标签', '位置', '价格/月', '更新日期', '房屋详情页', '图片url'])
for row in self.hourse_info:
writer.writerow(row)
def save_to_mongo(self, result):
"""
保存至MongoDB
:param result: 结果
"""
try:
if self.db[self.mongo_collection].insert(result):
pass
except Exception:
print('Failed to save to Mongo')
main函数:
def main(self):
start_time = datetime.datetime.now()
for page in range(1, 101):
# 爬取xx市的url
url = 'https://{0}.lianjia.com/zufang/pg{1}'.format(self.city, page)
# 爬取xx市xx区的url
# url = 'https://{0}.lianjia.com/zufang/{1}/pg{2}'.format(self.city, self.district, page)
html = self.get_index(url)
self.parse_index(html)
crawl_time = datetime.datetime.now() - start_time
print(crawl_time)
可以根据自己需求选择爬取市的租房信息或者是市-区的租房信息

爬取结果:

mongodb:
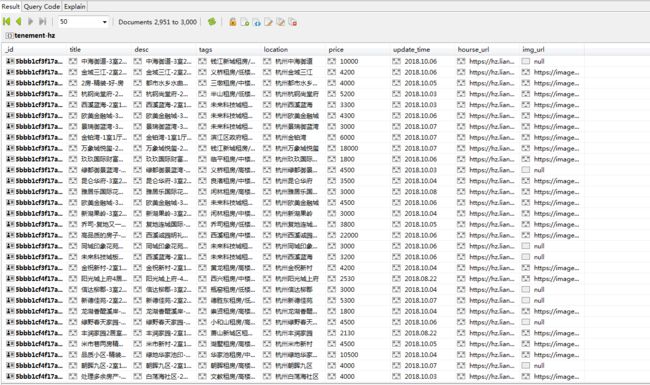
一页30个租房数据,一共100页,应该是爬全了。
到这里还没有完全结束,因为后面结合地图的可视化需要地址的经纬度(或许只需要地址名?反正我是老老实实地将地址转换成了经纬度),因此需要添加将地址转换为经纬度的代码,另外还需要添加经纬度的字段,代码如下:
# 根据地址获取对应经纬度,通过百度的api接口来进行
api_url = 'http://api.map.baidu.com/geocoder/v2/?address={}&output=json&ak=***你的密钥***'.format(location)
data = requests.get(api_url)
result = json.loads(data.text)
print(result)
try:
longitude = result['result']['location']['lng']
latitude = result['result']['location']['lat']
except Exception as e:
print('Error:这个地点没有查到对应的经纬度---- %s' % str(e))
longitude = [0]
latitude = [0]
这里我们可以看到,我们只需要将location(地址)动态填充到api_url里的address参数即可,如何获取密钥,百度一下即可
数据爬到了,接下来结合百度地图做一下简单的可视化吧
除了毕业设计做过一次数据可视化以外...就再也没有整过,看着自己爬下来那干瘪的数据,再看看大佬们爬数据,分析,炫酷的可视化一气呵成,难免有点想东施效颦一下,自己也整一下试试看吧
这里我选的是工具是BDP(tableau太贵),自己捣鼓了下,感觉还可以,分享一下捣鼓的过程,希望能有所帮助
BDP官方网站链接:https://me.bdp.cn/home.html
我没有下载客户端,注册了用户之后就开始了免费使用,找到数据源-添加数据源
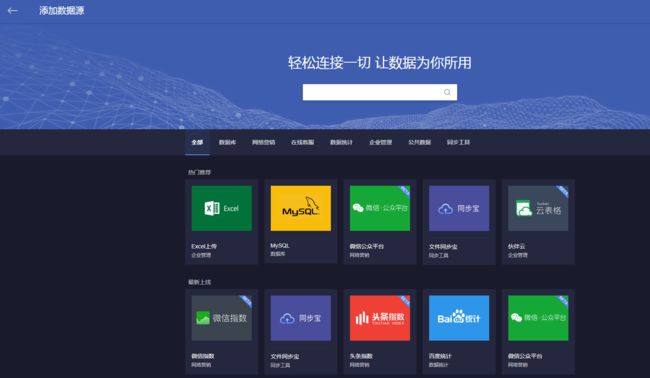
选择excel上传,将之前存放爬取结果的csv文件上传,会生成一个工作表

会进入这么一个页面

将工作表里的“链家租房”拖入图层”,字段就会出来,我们将字段中的经纬度拖拽到“维度”上(这里我选择的图表类型是热力图)

放大看一下


出租房的位置我们已经看的比较清楚了,那么如果想根据自己的需求筛选一下,缩小范围,怎么做?比如我,刚来杭州不久,房子的租金不能太贵是吧,于是我将字段里的“价格/月”拖入'筛选器'

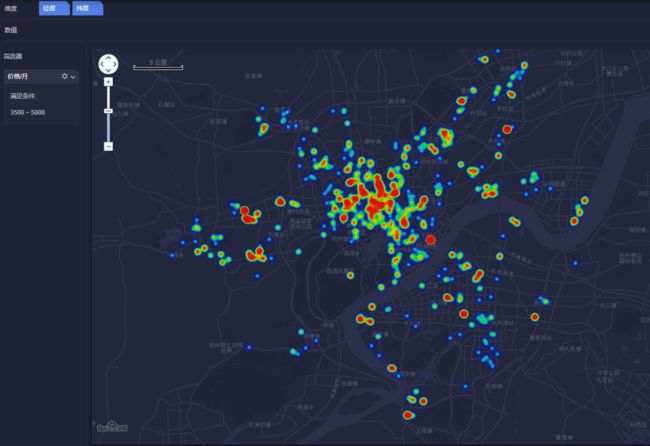
可以看到世界稍微清净了一点,但是因为我穷,我想在这堆3500~5000的房子中尽可能去找便宜的,那就将字段里的"价格/月"再拖拽到'数值'里去

整完了价格,那么再接下来,因为我有个女朋友,想找个2室的,好吧...假如你有个女朋友,想找个2室的房子,再筛选一下“描述”


我大致就捣鼓了这么些操作,比较基础,下面是所有代码:
spider.py
import requests
from pyquery import PyQuery as pq
import csv
import sys
import pymongo
import json
from settings import *
import datetime
class ZufangSpider():
def __init__(self):
self.city = 'hz'
self.district = 'binjiang'
self.hourse_info = []
client = pymongo.MongoClient(MONGO_URL)
self.db = client[MONGO_DB]
# 根据爬取城市的不同动态生成不同的mongodb表名
self.mongo_collection = 'tenement-{}'.format(self.city)
def get_index(self, url):
try:
response = requests.get(url)
# 当进入没有租房信息的页面时,将已爬取的数据存入csv并退出程序
if '没有找到' in response.text:
print('No more hourse')
self.save_csv()
sys.exit()
elif response.status_code == 200:
print('Get url:', url)
return response.text
return None
except ConnectionError:
return None
def parse_index(self, html):
doc = pq(html)
hourse_list = doc('.house-lst li').items()
for hourse in hourse_list:
title = hourse('.info-panel h2').text().replace(" ", "-").replace(",", "-")
desc_initial = hourse('.where').text().split()
desc = "-".join(desc_initial) # 格式处理
tags = hourse('.con').text()
location = '杭州' + desc_initial[0]
price = hourse('.price span').text()
update_time = hourse('.price-pre').text()[0:-3]
hourse_url = hourse('.pic-panel a').attr('href')
img_url = hourse('.pic-panel img').attr('data-img')
# 根据地址获取对应经纬度,通过百度的api接口来进行
api_url = 'http://api.map.baidu.com/geocoder/v2/?address={}&output=json&ak=***你的密钥***'.format(location)
data = requests.get(api_url)
result = json.loads(data.text)
print(result)
try:
longitude = result['result']['location']['lng']
latitude = result['result']['location']['lat']
except Exception as e:
print('Error:这个地点没有查到对应的经纬度---- %s' % str(e))
longitude = [0]
latitude = [0]
self.hourse_info.append([title, desc, tags, location, longitude, latitude, price, update_time, hourse_url, img_url])
self.hourse_dict = {
'title': title,
'desc': desc,
'tags': tags,
'location': location,
'longitude': longitude,
'latitude': latitude,
'price': price,
'update_time': update_time,
'hourse_url': hourse_url,
'img_url': img_url,
}
self.save_csv()
self.save_to_mongo(self.hourse_dict)
def save_csv(self):
# 将结果存入csv文件
with open('zufang-{}.csv'.format(self.city), 'w', encoding='utf8', newline='') as f:
writer = csv.writer(f)
writer.writerow(['租房标题', '描述', '标签', '位置', '经度', '纬度', '价格/月', '更新日期', '房屋详情页', '图片url'])
for row in self.hourse_info:
writer.writerow(row)
def save_to_mongo(self, result):
"""
保存至MongoDB
:param result: 结果
"""
try:
if self.db[self.mongo_collection].insert(result):
pass
except Exception:
print('Failed to save to Mongo')
def main(self):
start_time = datetime.datetime.now()
for page in range(1, 101):
# 爬取xx市的url
url = 'https://{0}.lianjia.com/zufang/pg{1}'.format(self.city, page)
# 爬取xx市xx区的url
# url = 'https://{0}.lianjia.com/zufang/{1}/pg{2}'.format(self.city, self.district, page)
html = self.get_index(url)
self.parse_index(html)
crawl_time = datetime.datetime.now() - start_time
print(crawl_time)
if __name__ == "__main__":
zf = ZufangSpider()
zf.main()
settings.py
MONGO_URL = 'localhost'
# MONGO_PASSWORD = ''
MONGO_DB = 'Lianjia'
使用
只需要修改settings里的配置,以及根据需要修改city和district即可
class ZufangSpider():
def __init__(self):
self.city = 'hz'
self.district = 'binjiang'
...
爬取市或者市-区,对应的url
def main(self):
start_time = datetime.datetime.now()
for page in range(1, 101):
# 爬取xx市的url
url = 'https://{0}.lianjia.com/zufang/pg{1}'.format(self.city, page)
# 爬取xx市xx区的url
# url = 'https://{0}.lianjia.com/zufang/{1}/pg{2}'.format(self.city, self.district, page)
html = self.get_index(url)
self.parse_index(html)
crawl_time = datetime.datetime.now() - start_time
print(crawl_time)
总体而言,爬虫方面代码比较粗糙,也没有进行数据清洗,还有很多可以完善的地方
可视化方面也只是整了下比较基础的部分,可以尝试在地图上添加地铁的行驶路线,再标记出站点,或许可以发现距离站点近的房子租金会贵一些(个人猜测),总的来说,应该还是有很多可以操作的地方,我这里就不折腾了,毕竟我只是为了感受下BDP经纬度图表的视觉效果如何...感觉不错,个人倾向黑色主题...