一、概述
本篇文章主要介绍如何使用Storm + flume + Kafka 实现实时数据的计算,并且使用高德地图API实现热力图的展示。
背景知识:
在有些场合,我们需要了解当前人口的流动情况,比如,需要实时监控一些旅游景点旅客的密集程度,这时可以使用GPS定位系统将该区域内旅客的IP数据进行计算,但是GPS定位系统也有一定的缺点,不是每个旅客都会GPS功能,这时可以使用“信令”来获取个人定位信息。所谓“信令”就是每个手机会不是的向附近最近的基站发送定位信息,除非手机关机。相信每个人在做车旅游的时候每经过一个地方都会受到某个地区的短信,“某某城市欢迎你的来访”等信息,移动电信应用就是利用“信令”来监控每个的定位信息。(同时也可以看出大数据下个人隐私很难受到保护)。
1. 项目架构
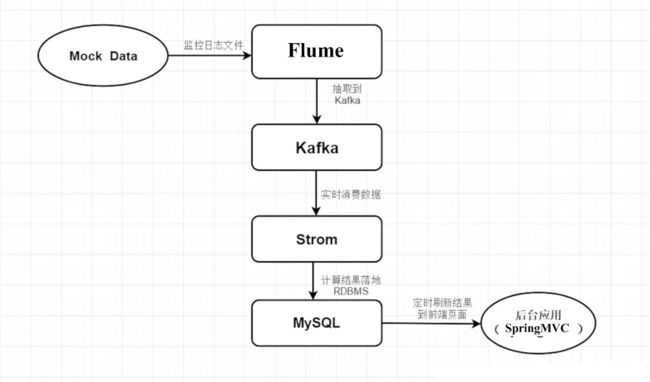
在这里我们使用了 flume来抽取日志数据,使用 Python 模拟数据。在经过 flume 将数据抽取到 Kafka 中,Strom 会实时消费数据,然后计算结果实时写入 MySQL数据库中,然后我们可以将结果送到后台应用中使用和可视化展示。
2. 环境以及软件说明
- storm-0.9.7
- zookeeper-3.4.5
- flume
- kafka_2.11-0.9.0.0
二、实战
1. 模拟数据
#coding=UTF-8
import random
import time
phone=[
"13869555210",
"18542360152",
"15422556663",
"18852487210",
"13993584664",
"18754366522",
"15222436542",
"13369568452",
"13893556666",
"15366698558"
]
location=[
"116.191031, 39.988585",
"116.389275, 39.925818",
"116.287444, 39.810742",
"116.481707, 39.940089",
"116.410588, 39.880172",
"116.394816, 39.91181",
"116.416002, 39.952917"
]
def sample_phone():
return random.sample(phone,1)[0]
def sample_location():
return random.sample(location, 1)[0]
def generator_log(count=10):
time_str=time.strftime("%Y-%m-%d %H:%M:%S",time.localtime())
f=open("/opt/log.txt","a+")
while count>=1:
query_log="{phone}\t{location}\t{date}".format(phone=sample_phone(),location=sample_location(),date=time_str)
f.write(query_log+"\n")
# print query_log
count=count-1
if __name__=='__main__':
generator_log(100)
2. Flume 配置
在Flume安装目录下添加配置文件 storm_pro.conf:
agent.sources = s1
agent.channels = c1
agent.sinks = k1
agent.sources.s1.type=exec
agent.sources.s1.command=tail -F /opt/log.txt
agent.sources.s1.channels=c1
agent.channels.c1.type=memory
agent.channels.c1.capacity=10000
agent.channels.c1.transactionCapacity=100
#设置Kafka接收器
agent.sinks.k1.type= org.apache.flume.sink.kafka.KafkaSink
#设置Kafka的broker地址和端口号
agent.sinks.k1.brokerList=hadoop01:9092,hadoop02:9092,hadoop03:9092
#设置Kafka的Topic
agent.sinks.k1.topic=storm_kafka
#设置序列化方式
agent.sinks.k1.serializer.class=kafka.serializer.StringEncoder
agent.sinks.k1.channel=c1
注意:上面配置中path指定读取数据的文件,可自行创建。topic_id 参数为下文kafka中需要创建的 topic主题。
bin/flume-ng agent -n agent -c conf -f conf/storm_pro.conf -Dflume.root.logger=INFO,console
maven
4.0.0
storm-kafka-mysql
storm-kafka-mysql
0.0.1-SNAPSHOT
jar
storm-kafka-mysql
UTF-8
javax
javaee-api
8.0
provided
org.glassfish.web
javax.servlet.jsp.jstl
1.2.2
org.apache.storm
storm-core
0.9.5
org.apache.storm
storm-kafka
0.9.5
org.apache.kafka
kafka_2.11
0.8.2.0
org.apache.zookeeper
zookeeper
log4j
log4j
mysql
mysql-connector-java
5.1.31
maven-compiler-plugin
2.3.2
1.7
1.7
4. Strom程序编写
package com.neusoft;
import java.util.Arrays;
import storm.kafka.BrokerHosts;
import storm.kafka.KafkaSpout;
import storm.kafka.SpoutConfig;
import storm.kafka.StringScheme;
import storm.kafka.ZkHosts;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.spout.SchemeAsMultiScheme;
import backtype.storm.topology.TopologyBuilder;
public class MyKafkaTopology {
public static void main(String[] args) throws AlreadyAliveException, InvalidTopologyException, InterruptedException {
String zks = "hadoop01:2181,hadoop02:2181,hadoop03:2181";
String topic = "storm_kafka";
// String zkRoot = "/opt/modules/app/zookeeper/zkdata"; // default zookeeper root configuration for storm
String id = "wordtest";
BrokerHosts brokerHosts = new ZkHosts(zks);
SpoutConfig spoutConf = new SpoutConfig(brokerHosts, topic, "", id);
spoutConf.scheme = new SchemeAsMultiScheme(new StringScheme());
spoutConf.forceFromStart = false;
spoutConf.zkServers = Arrays.asList(new String[] {"hadoop01", "hadoop02", "hadoop03"});
spoutConf.zkPort = 2181;
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("kafka-reader", new KafkaSpout(spoutConf), 2); // Kafka我们创建了一个2分区的Topic,这里并行度设置为2
builder.setBolt("print-bolt", new PrintBolt(), 2).shuffleGrouping("kafka-reader");
Config conf = new Config();
String name = MyKafkaTopology.class.getSimpleName();
if (args != null && args.length > 0) {
// Nimbus host name passed from command line
conf.put(Config.NIMBUS_HOST, args[0]);
conf.setNumWorkers(3);
StormSubmitter.submitTopologyWithProgressBar(name, conf, builder.createTopology());
}
else {
conf.setMaxTaskParallelism(1);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(name, conf, builder.createTopology());
// Thread.sleep(60000);
// cluster.killTopology(name);
// cluster.shutdown();
// StormSubmitter.submitTopology(name, conf, builder.createTopology());
}
}
}
package com.neusoft;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Date;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import com.mysql.jdbc.Connection;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class PrintBolt extends BaseBasicBolt {
public static final Log log = LogFactory.getLog(PrintBolt.class);
public static final long serialVersionUID = 1L;
public static int count = 0;
public static Connection con;
static {
try {
con = (Connection) DriverManager.getConnection("jdbc:mysql://192.168.47.244:3306/storm", "root", "root");
} catch (SQLException e) {
e.printStackTrace();
}
}
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
//获取上一个组件所声明的Field
//String print = input.getStringByField("print");
count++;
String print = input.getString(0);
// log.info("【print】: " + print);
String[] arr = print.split("\\t");
System.out.println("Name of input word is : " + print);
//保存到mysql
String driver = "com.mysql.jdbc.Driver";
try {
Class.forName(driver);
String sql = "insert into location (time,latitude,longitude) values(?,?,?)";
PreparedStatement pst = con.prepareStatement(sql);
System.out.println(pst);
//调用pst对象set方法,设置问号占位符上的参数
Date date = new Date();
pst.setLong(1, date.getTime());
pst.setDouble(2, Double.parseDouble(arr[1].split(",")[1]));
pst.setDouble(3, Double.parseDouble(arr[1].split(",")[0]));
pst.executeUpdate();
} catch (ClassNotFoundException | SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//进行传递给下一个bolt
//collector.emit(new Values(print));
System.out.println(count);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//declarer.declare(new Fields("write"));
}
}
5. 数据库的设计
create database storm;
use storm;
create table location(
time bigint,
latitude double,
longitude double
)charset utf8;
6. 集群的启动
首先启动kafka(注意:需要启动ZK)。
启动kafka:
nohup bin/kafka-server-start.sh config/server.properties &
创建topic:
bin/kafka-topics.sh --create --zookeeper hadoop-senior.shinelon.com:2181 --replication-factor 1 --partitions 1 --
topic storm_kafka
注意:topic名称和flume中配置的必须一致。
启动flume:
在启动kafka和flume之后就可以启动 Storm,接着可以运行python数据模拟器,就会看到数据库中存入了计算结果:

三、数据可视化展示
可视化结果如下图所示:
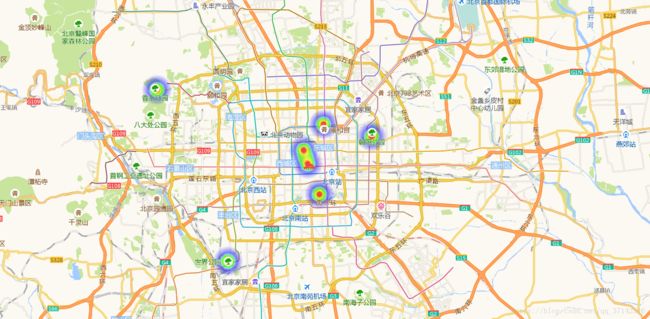
前端页面如下:
<%--
Created by IntelliJ IDEA.
User: ttc
Date: 2018/7/6
Time: 14:06
To change this template use File | Settings | File Templates.
--%>
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
高德地图
SpringMvc DAO层代码如下:
package com.neusoft.mapper;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.ArrayList;
import java.util.List;
import com.neusoft.util.MysqlUtil;
import org.springframework.stereotype.Component;
@Component
public class LocationDao {
private static MysqlUtil mysqlUtil;
public List map() throws Exception{
List list = new ArrayList();
Connection connection=null;
PreparedStatement psmt=null;
try {
connection = MysqlUtil.getConnection();
psmt = connection.prepareStatement("select latitude,longitude,count(*) from location where "
+ "time>unix_timestamp(date_sub(current_timestamp(),interval 10 minute))*1000 "
+ "group by longitude,latitude");
ResultSet resultSet = psmt.executeQuery();
while (resultSet.next()) {
Location location = new Location();
location.setLongitude(resultSet.getDouble(1));
location.setLatitude(resultSet.getDouble(2));
location.setCount(resultSet.getInt(3));
list.add(location);
}
}catch (Exception e){
e.printStackTrace();
}finally {
MysqlUtil.release();
}
return list;
}
}
实体类:
public class Location {
private Integer count;
private double latitude;
private double longitude;
public Integer getCount() {
return count;
}
public void setCount(Integer count) {
this.count = count;
}
public double getLatitude() {
return latitude;
}
public void setLatitude(double latitude) {
this.latitude = latitude;
}
public double getLongitude() {
return longitude;
}
public void setLongitude(double longitude) {
this.longitude = longitude;
}
}
工具类:
package com.neusoft.util;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class MysqlUtil {
private static final String DRIVER_NAME="jdbc:mysql://192.168.47.244:3306/storm?user=root&password=root";
private static Connection connection;
private static PreparedStatement pstm;
private static ResultSet resultSet;
public static Connection getConnection(){
try {
Class.forName("com.mysql.jdbc.Driver");
connection=DriverManager.getConnection(DRIVER_NAME);
}catch (Exception e){
e.printStackTrace();
}
return connection;
}
public static void release(){
try {
if(resultSet!=null) {
resultSet.close();
}
if (pstm != null) {
pstm.close();
}
if(connection!=null){
connection.close();
}
}catch (Exception e){
e.printStackTrace();
}finally {
if(connection!=null){
connection=null; //help GC
}
}
}
}
Controller层:
package com.neusoft.controller;
import com.alibaba.fastjson.JSON;
import com.neusoft.mapper.LocationDao;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.servlet.ModelAndView;
import javax.servlet.http.HttpServletResponse;
/**
* Created by ttc on 2018/8/7.
*/
@Controller
public class HomeController {
@RequestMapping("/")
public ModelAndView home()
{
ModelAndView modelAndView = new ModelAndView();
modelAndView.setViewName("index");
return modelAndView;
}
@RequestMapping("/get_map")
public void getMap(HttpServletResponse response) throws Exception{
LocationDao locationDao = new LocationDao();
String json = JSON.toJSONString(locationDao.map());
response.getWriter().print(json);
}
}
# centos6.9安装/升级到python2.7并安装pip
https://www.cnblogs.com/harrymore/p/9024287.html
记得同步centos和windows的时间。
python生成动态数据脚本
import random
import os
import sys
import time
import numpy as np
def genertor():
Point=[random.uniform(123.449169,123.458654),random.uniform(41.740567,41.743705)]
arr = []
for i in range(1, random.randint(0, 500)):
bias = np.random.randn() * pow(10,-4)
bias = round(bias,4)
X = Point[0] + bias
bias1 = np.random.randn() * pow(10,-4)
bias1 = round(bias,4)
Y = Point[1] + bias
time_str=time.strftime("%Y-%m-%d %H:%M:%S",time.localtime())
arr.append(['13888888888'+'\t',str(X)+',', str(Point[1])+'\t',time_str])
return arr
if __name__ == '__main__':
path = sys.argv[1]
if not os.path.isfile(path):
open(path, 'w')
with open(path,'a') as f:
while True:
arr = genertor()
for i in range(len(arr)):
f.writelines(arr[i])
f.write('\n')
time.sleep(5)
sql改成间隔20秒
psmt = connection.prepareStatement("select latitude,longitude,count(*) num from location where "
+ "time>unix_timestamp(date_sub(current_timestamp(),interval 20 second))*1000 "
+ "group by longitude,latitude");
index.jsp改成定时器版
<%--
Created by IntelliJ IDEA.
User: ttc
Date: 2018/7/6
Time: 14:06
To change this template use File | Settings | File Templates.
--%>
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
高德地图