1. 背景
Apache Calcite 是面向 Hadoop 新的查询引擎,它提供了标准的 SQL 语言、多种查询优化和连接各种数据源的能力,除此之外,Calcite 还提供了 OLAP 和流处理的查询引擎。正是有了这些诸多特性,Calcite 项目在 Hadoop 中越来越引入注目,并被众多项目集成。
Calcite 之前的名称叫做 optiq ,optiq 起初在 Hive 项目中,为 Hive 提供基于成本模型的优化,即 CBO(Cost Based Optimizatio)。2014 年 5 月 optiq 独立出来,成为 Apache 社区的孵化项目,2014 年 9 月正式更名为 Calcite。Calcite 项目的创建者是 Julian Hyde ,他在数据平台上有非常多的工作经历,曾经是 Oracle、 Broadbase 公司 SQL 引擎的主要开发者、SQLStream 公司的创始人和主架构师、Pentaho BI 套件中 OLAP 部分的架构师和主要开发者。现在他在 Hortonworks 公司负责 Calcite 项目,其工作经历对 Calcite 项目有很大的帮助。除了 Hortonworks,该项目的代码提交者还有 MapR 、Salesforce 等公司,并且还在不断壮大。
关于 Apache Calcite 的简单介绍可以参考 Apache Calcite:Hadoop 中新型大数据查询引擎 这篇文章,Calcite 一开始设计的目标就是 one size fits all,它希望能为不同计算存储引擎提供统一的 SQL 查询引擎,当然 Calcite 并不仅仅是一个简单的 SQL 查询引擎,在论文 Apache Calcite: A Foundational Framework for Optimized Query Processing Over Heterogeneous Data Sources 的摘要部分,关于 Calcite 的核心点有简单的介绍,Calcite 的架构有三个特点:flexible, embeddable, and extensible,就是灵活性、组件可插拔、可扩展,它的 SQL Parser 层、Optimizer 层等都可以单独使用,这也是 Calcite 受总多开源框架欢迎的原因之一。Apache Calcite包含了许多组成典型数据管理系统的经典模块,但省略了一些关键性的功能: 数据存储,数据处理算法和元数据存储库。
2 Calcite架构
关于 Calcite 的架构,它与传统数据库管理系统有一些相似之处,相比而言,它将数据存储、数据处理算法和元数据存储这些部分忽略掉了,这样设计带来的好处是:对于涉及多种数据源和多种计算引擎的应用而言,Calcite 因为可以兼容多种存储和计算引擎,使得 Calcite 可以提供统一查询服务,Calcite 将会是这些应用的最佳选择。
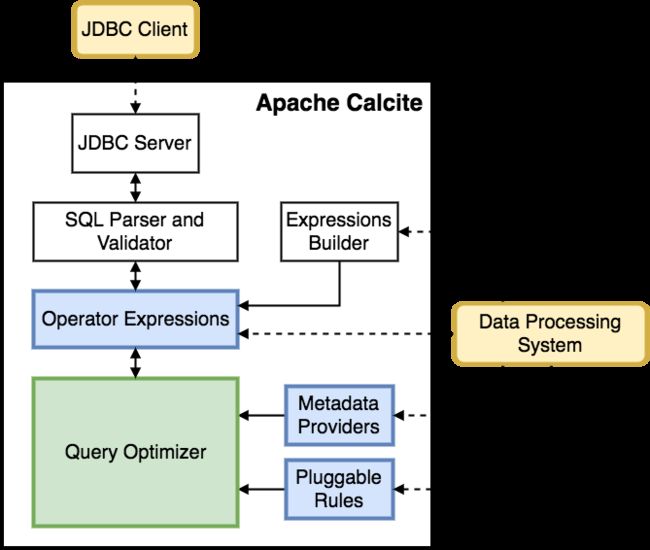
在 Calcite 架构中,最核心地方就是 Optimizer,也就是优化器,一个 Optimization Engine 包含三个组成部分:
- rules:也就是匹配规则,Calcite 内置上百种 Rules 来优化 relational expression,当然也支持自定义 rules;
- metadata providers:主要是向优化器提供信息,这些信息会有助于指导优化器向着目标(减少整体 cost)进行优化,信息可以包括行数、table 哪一列是唯一列等,也包括计算 RelNode 树中执行 subexpression cost 的函数;
- planner engines:它的主要目标是进行触发 rules 来达到指定目标,比如像 cost-based optimizer(CBO)的目标是减少cost(Cost 包括处理的数据行数、CPU cost、IO cost 等)。
对SQL执行完整的流程,分为四个步骤:

- Parser. 此步中Calcite通过Java CC将SQL解析成未经校验的AST(Abstract Syntax Tree,抽象语法树)
- Validate. 该步骤主要作用是校证Parser步骤中的AST是否合法,如验证SQL schema、字段、函数等是否存在; SQL语句是否合法等. 此步完成之后就生成了RelNode树
- Optimize. 该步骤主要的作用优化RelNode树, 并将其转化成物理执行计划。主要涉及SQL规则优化如:基于规则优化(RBO)及基于代价(CBO)优化; Optimze 这一步原则上来说是可选的, 通过Validate后的RelNode树已经可以直接转化物理执行计划,但现代的SQL解析器基本上都包括有这一步,目的是优化SQL执行计划。此步得到的结果为物理执行计划。
- Execute,即执行阶段。此阶段主要做的是:将物理执行计划转化成可在特定的平台执行的程序。如Hive与Flink都在在此阶段将物理执行计划CodeGen生成相应的可执行代码。
3 Calcite相关概念
3.1 Catalog
主要定义被SQL访问的命名空间,主要包括以下几点:
- schema: 主要定义schema与表的集合,schema 并不是强制一定需要的,比如说有两张同名的表T1, T2,就需要schema要区分这两张表,如A.T1, B.T1
- table:对应关系数据库的表,代表一类数据,在calcite中由RelDataType定义
- RelDataType: 代表表的数据定义,如表的数据列名称、类型等。
Schema:
public interface Schema {
Table getTable(String name);
Set getTableNames();
RelProtoDataType getType(String name);
Set getTypeNames();
Collection getFunctions(String name);
Set getFunctionNames();
Schema getSubSchema(String name);
Set getSubSchemaNames();
Expression getExpression(SchemaPlus parentSchema, String name);
boolean isMutable();
Schema snapshot(SchemaVersion version);
/** Table type. */
enum TableType {}
}
Table:
public interface Table {
RelDataType getRowType(RelDataTypeFactory typeFactory);
Statistic getStatistic();
Schema.TableType getJdbcTableType();
boolean isRolledUp(String column);
boolean rolledUpColumnValidInsideAgg(String column, SqlCall call,
SqlNode parent, CalciteConnectionConfig config);
}
其中RelDataType代表Row的数据类型, Statistic 用于统计表的相关数据、特别是在CBO用于计表计算表的代价。
selcct id, name, cast(age as bigint) from A.INFO
其中,
id, name为data type field
bigint为 data type
A 为schema
INFO 为table
3.2 SQL Parser(SQL -> SqlNode)
Calcite 使用 JavaCC 做 SQL 解析,JavaCC 根据 Calcite 中定义的 Parser.jj 文件,生成一系列的 java 代码,生成的 Java 代码会把 SQL 转换成 AST 的数据结构(这里是 SqlNode 类型)。
与 Javacc 相似的工具还有 ANTLR,JavaCC 中的 jj 文件也跟 ANTLR 中的 G4文件类似,Apache Spark 中使用这个工具做类似的事情。
Javacc
关于 Javacc 内容可以参考下面这几篇文章,这里就不再详细展开,可以通过下面文章的例子把 JavaCC 的语法了解一下,这样我们也可以自己设计一个 DSL(Domain Specific Language)。
- JavaCC 研究与应用( 8000字 心得 源程序);
- JavaCC、解析树和 XQuery 语法,第 1 部分;
- JavaCC、解析树和 XQuery 语法,第 2 部分;
- 编译原理之Javacc使用;
- javacc tutorial;
回到 Calcite,Javacc 这里要实现一个 SQL Parser,它的功能有以下两个,这里都是需要在 jj 文件中定义的。
- 设计词法和语义,定义 SQL 中具体的元素;
- 实现词法分析器(Lexer)和语法分析器(Parser),完成对 SQL 的解析,完成相应的转换。
//org.apache.calcite.prepare.CalcitePrepareImpl
//...
//解析sql->SqlNode
SqlParser parser = createParser(query.sql, parserConfig);
SqlNode sqlNode;
try {
sqlNode = parser.parseStmt();
statementType = getStatementType(sqlNode.getKind());
} catch (SqlParseException e) {
throw new RuntimeException(
"parse failed: " + e.getMessage(), e);
}
//...
上述代码中 SQL 经过parser.parseStmt()的解析之后,会生成一个 SqlNode,DEBUG 后的 对象如下图所示。

3.3 验证与转换 (SqlNode -> RelNode)
经过上面的sql 解析,会生成一个 SqlNode 对象,SqlNode 是抽象语法树AST(Abstract Syntax Tree)的节点, 而 Rel 代表关系表达式(Relation Expression), 所以从 AST 转换为 Rel 的过程中即是一个转换有是一个校验关联的过程。
//org.apache.calcite.prepare. Prepare
//function prepareSql
RelRoot root =
sqlToRelConverter.convertQuery(sqlQuery, needsValidation, true);
我们先讲下校验。
3.3.1 Validate
语法检查前需要知道元数据信息,这个检查会包括表名、字段名、函数名、数据类型的检查。进行语法检查的实现如下:
//org.apache.calcite.sql.validate.SqlValidatorImpl
public SqlNode validate(SqlNode topNode) {
SqlValidatorScope scope = new EmptyScope(this);
scope = new CatalogScope(scope, ImmutableList.of("CATALOG"));
final SqlNode topNode2 = validateScopedExpression(topNode, scope);
final RelDataType type = getValidatedNodeType(topNode2);
Util.discard(type);
return topNode2;
}
在对SqlNode校验的过程中,还会根据元数据对AST进行一些语义信息的补充,例如:
//校验前
select province,avg(cast(age as double)) from t_user group by province
//校验后
SELECT `T_USER`.`PROVINCE`, AVG(CAST(`T_USER`.`AGE` AS DOUBLE))
FROM `TEST_PRO`.`T_USER` AS `T_USER`
GROUP BY `T_USER`.`PROVINCE`
3.3.2 SqlNode to RelNode
在获取了合法且补充了"一定"语义信息的 AST 树后, 且 validator 中已经准备好各种映射信息后就开始具体到 RelNode 的转换了。
//org.apache.calcite.sql2rel.SqlToRelConverter
protected RelRoot convertQueryRecursive(SqlNode query, boolean top,
RelDataType targetRowType) {
final SqlKind kind = query.getKind();
switch (kind) {
case SELECT:
return RelRoot.of(convertSelect((SqlSelect) query, top), kind);
case INSERT:
return RelRoot.of(convertInsert((SqlInsert) query), kind);
case DELETE:
return RelRoot.of(convertDelete((SqlDelete) query), kind);
case UPDATE:
return RelRoot.of(convertUpdate((SqlUpdate) query), kind);
case MERGE:
return RelRoot.of(convertMerge((SqlMerge) query), kind);
case UNION:
case INTERSECT:
case EXCEPT:
return RelRoot.of(convertSetOp((SqlCall) query), kind);
case WITH:
return convertWith((SqlWith) query, top);
case VALUES:
return RelRoot.of(convertValues((SqlCall) query, targetRowType), kind);
default:
throw new AssertionError("not a query: " + query);
}
}
测试sql:
select province,avg(cast(age as double)) from t_user group by province
Plan after converting SqlNode to RelNode
LogicalAggregate(group=[{0}], EXPR$1=[AVG($1)])
LogicalProject(PROVINCE=[$3], $f1=[CAST($2):DOUBLE])
LogicalTableScan(table=[[TEST_PRO, T_USER]])
3.4 优化Optimization
在calcite中主要采用两种优化器,分别是:
- HepPlanner(RBO):它是一个启发式的优化器,按照规则进行匹配,直到达到次数限制(match 次数限制)或者遍历一遍后不再出现 rule match 的情况才算完成;
- VolcanoPlanner(RBO+CBO):它会一直迭代 rules,直到找到 cost 最小的 paln。
这里来看下 Calcite 中优化器的实现,RelOptPlanner 是 Calcite 中优化器的基类,其子类实现如下图所示:

3.4.1 基于规则优化(RBO)
基于规则的优化器(Rule-Based Optimizer,RBO):根据优化规则对关系表达式进行转换,这里的转换是说一个关系表达式经过优化规则后会变成另外一个关系表达式,同时原有表达式会被裁剪掉,经过一系列转换后生成最终的执行计划。
RBO 中包含了一套有着严格顺序的优化规则,同样一条 SQL,无论读取的表中数据是怎么样的,最后生成的执行计划都是一样的。同时,在 RBO 中 SQL 写法的不同很有可能影响最终的执行计划,从而影响执行计划的性能。
3.4.2 基于成本优化(CBO)
基于代价的优化器(Cost-Based Optimizer,CBO):根据优化规则对关系表达式进行转换,这里的转换是说一个关系表达式经过优化规则后会生成另外一个关系表达式,同时原有表达式也会保留,经过一系列转换后会生成多个执行计划,然后 CBO 会根据统计信息和代价模型 (Cost Model) 计算每个执行计划的 Cost,从中挑选 Cost 最小的执行计划。
由上可知,CBO 中有两个依赖:统计信息和代价模型。统计信息的准确与否、代价模型的合理与否都会影响 CBO 选择最优计划。 从上述描述可知,CBO 是优于 RBO 的,原因是 RBO 是一种只认规则,对数据不敏感的呆板的优化器,而在实际过程中,数据往往是有变化的,通过 RBO 生成的执行计划很有可能不是最优的。事实上目前各大数据库和大数据计算引擎都倾向于使用 CBO,但是对于流式计算引擎来说,使用 CBO 还是有很大难度的,因为并不能提前预知数据量等信息,这会极大地影响优化效果,CBO 主要还是应用在离线的场景。
常见的优化规则介绍可参考:
https://www.cnblogs.com/wcgstudy/p/11795952.html
参考资料:
https://www.infoq.cn/article/new-big-data-hadoop-query-engine-apache-calcite
https://matt33.com/2019/03/07/apache-calcite-process-flow/
https://zhuanlan.zhihu.com/p/65345536
https://www.jianshu.com/p/83e88fdc04ec
https://www.cnblogs.com/wcgstudy/p/11795952.html