1. 堆、栈、队列
堆栈都是一种数据项按序排列的数据结构,栈只能在一端对数据项进行插入或删除
- 栈的特点:后进先出
- 堆的特点:堆是一块内存区域,存入和移除时顺序随意
- 队列的特点:是一种特殊的线性表,先进先出
堆的理解
堆通常是一个可以被看做一棵树的数组对象。堆总是满足下列性质:
·堆中某个节点的值总是不大于或不小于其父节点的值;
·堆总是一棵完全二叉树。
将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、斐波那契堆等。堆是在程序运行时,而不是在程序编译时,申请某个大小的内存空间。即动态分配内存,对其访问和对一般内存的访问没有区别。
堆是应用程序在运行的时候请求操作系统分配给自己内存,一般是申请/给予的过程。
堆是指程序运行时申请的动态内存,而栈只是指一种使用堆的方法(即先进后出)。
栈的理解
栈(stack)又名堆栈,它是一种运算受限的线性表。其限制是仅允许在表的一端进行插入和删除运算。这一端被称为栈顶,相对地,把另一端称为栈底。
栈就是一个桶,后放进去的先拿出来,它下面本来有的东西要等它出来之后才能出来(先进后出)
队列的理解
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。
队列中没有元素时,称为空队列。
区别点:
栈只允许在表尾一端进行插入和删除,队列只允许在表尾一端进行插入,在表头一端进行删除。
- 堆栈空间分配角度
栈(操作系统):由操作系统自动分配释放 ,存放函数的参数值,局部变量的值等(基本类型值)
堆(操作系统): 被调用完毕不会立即被清理掉,由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收(引用类型值),分配方式倒是类似于链表 - 堆栈缓存方式角度
栈 使用的是一级缓存, 他们通常都是被调用时处于存储空间中,调用完毕立即释放
堆 则是存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定(并不是一旦成为孤儿对象就能被回收)。所以调用这些对象的速度要相对来得低一些 - 堆栈数据结构区别
堆(数据结构):堆可以被看成是一棵树,如:堆排序
栈(数据结构):一种先进后出的数据结构
常用于:
队列常用于做一个固定顺序的任务系统
栈常用语做 UIManager管理系统 后进先出的原则,最后打开的界面,优先取出关闭。
具体代码中使用:
栈
//定义一个栈
private StackmyStack=new Stack();
//push是入栈
myStack.Push(gameobject01);
//pop是取栈顶元素,并删除,还有一个方法是peek也是取栈顶元素,但是不删除
GameObject gameobject01= Stack.Pop();
队列
//new一个int类型的队列
Queue queue=new Queue ();
//属性Count,获取 Queue 中包含的元素个数。
if(queue.Count==0)
//从 Queue 中移除所有的元素
queue.Clear();
//判断某个元素是否在 queue 中
queue.Contains( 5);
//移除并返回在 Queue 的开头的对象
int number=queue.Dequeue()
//向 Queue 的末尾添加一个对象
queue.Enqueue( 5 );
//复制 Queue 到一个新的数组中
public virtual object[] ToArray();
//设置容量为 Queue 中元素的实际个数
queue.TrimToSize();
2. 值类型、引用类型
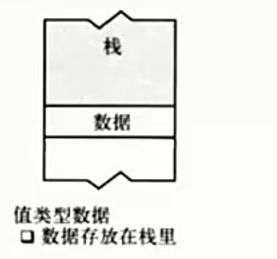
值类型:在C#中,继承自System.ValueType的类型被称为值类型,主要有以下几种(CLR2.0中支持类型有增加): * bool * byte * char * decimal * double * enum * float * int * long * sbyte * short * struct * uint * ulong * ushort
-
单独定义(作为变量)的时候放在栈中,值类型总是分配在它声明的地方:作为字段时,跟随其所属的变量(实例)存储
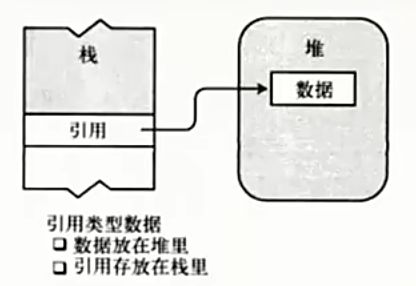
引用类型:继承自System.Object: * class * interface * delegate * object * string *StringBuilder
- 第一段存储实际的数据,总是位于堆中
-
第二段是一个引用,指向数据中堆中的存放位置
混淆点
- 经常混淆的是string。有人说String变量比string变量效率高;还听说String是引用类型,string是值类型,等等。例如:
string s1 = "Hello, " ;
string s2 = "world!" ;
string s3 = s1 + s2;//s3 is "Hello, world!"
这确实看起来像一个值类型的赋值,再比如改变s1的值对s2没有影响。这更使string看起来像值类型。实际上,这是运算符重载的结果,当s1被改变时,.NET在托管堆上为s1重新分配了内存。这样的目的,是为了将做为引用类型的string实现为通常语义下的字符串。
string s1 = "a" ;
string s2 = s1 ;
s1 = "b";//s2 is still "a"
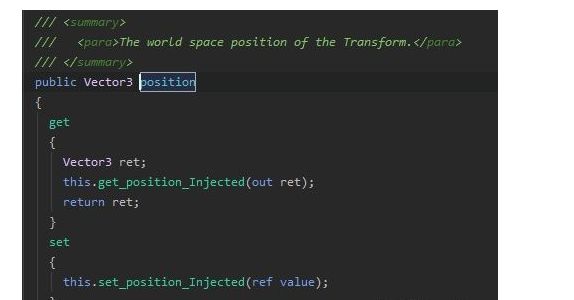
2.Unity对transform.position.x/y/z直接赋值时就会报错
因为transform.position是结构体,结构体是值类型。当我们写出形如 transform.position.x = 1 这样的代码时,是在通过get方法得到position,然后修改position的x字段的值。但是由于position是结构体类型的,get得到的也只是position的一个副本,而对这个副本所作出的任何修改,都对原positon没有任何影响,因此这样的修改是毫无意义的。编译器会禁止这样的修改操作
通过查看源码,可以看到position不是一个共有字段,是一个属性。要对结构体的共有字段进行修改是不会有问题的。这里我觉得修改transform.position没问题是因为set时传递了ref参数,也就是引用,所以是有意义的
总结
相同点:
- 引用类型可以实现接口,值类型当中的结构体也可以实现接口;
- 引用类型和值类型都继承自System.Object类。
不同点:
- 引用类型总是存放在堆中;
- 值类型和指针总是存放在它们本声明的地方;
- 栈有1个特点,就是空间较小,但是访问速度较快
- 堆空间较大,但是访问速度相对较慢
堆:我们声明的游戏对象都存放在堆中,当堆中的内存不够分配时会触发GC,如果GC之后内存还是不够,会扩大堆得内存,所以当堆的内存分配越来越大就会影响游戏的性能。
栈:主要负责存放代码运行的路径,
比如我们debug的时候就会输出堆栈回溯,在调试时能够很方便的查看代码的运行的路径,即栈回溯信息
3. string、StringBuffer、StringBuilder
string:一旦赋值或实例化后就不可更改,如果赋予新值将会重新开辟内存地址进行存储
StringBuilder:如果我们对字符串进行拼接,每次拼接都会创建一个String对象,消耗时间和资源,而StringBuilder是一个可变的字符串,用append和insert等方法改变字符串值时只是在原有对象存储的内存地址上进行连续操作,减少了资源的开销
区别:
执行速度方面的比较: StringBuilder >StringBuffer > String
字符串拼接时,String 对象的速度并不会比 StringBuffer对象慢
- String的内容是固定的,StringBuilder的内容是可变的
- StringBuffer和StringBuilder是一样的,后者速度比前者快,但是前者是线程安全的,适合在多线程下使用,后者是线程非安全的,比较适合在单线程下使用
4. ref、out、parpms
- ref:就是C#的参数引用传递,在方法中对参数所做的任何更改都将反映在该变量中,像C语言的指针变量。ref的参数需要先初始化才能使用。若要使用 ref 参数,则方法定义和调用方法都必须显式使用 ref 关键字
public class NewBehaviourScript : MonoBehaviour
{
void Start()
{
int testRef01 = 1;
int testRef02 = 2;
TestRef(ref testRef01 , ref testRef02);
Debug.Log(testRef01);
Debug.Log(testRef02);
}
public void TestRef(ref int param1 , ref int param2)
{
param1 = 111;
Debug.Log(param1);
param2 = 222;
Debug.Log(param2);
}
}

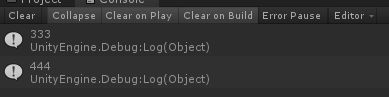
- out:out 和 ref 在运行时的处理方式不同,但是 out 跟 ref 编译原理是一样。out 不需要初始化值就可以使用,而且即便你把数值传递进去方法中,方法会将参数的数值设置为空,所以必须初始化一次才能使用,这就是只出不进的含义(如截图所示)
public class NewBehaviourScript : MonoBehaviour
{
void Start()
{
int testRef03;
int testRef04;
TestOut(out testRef03, out testRef04);
Debug.Log(testRef03);
Debug.Log(testRef04);
}
public void TestOut(out int param1, out int param2)
{
param1 = 333;
param2 = 444;
}
}

- params:params是为动态数组而准备的,我们直接输入数组的元素就可以
public class NewBehaviourScript : MonoBehaviour
{
void Start()
{
TestParams(1,2,3);
}
public void TestParams(params int[] param)
{
foreach (var p in param)
{
Debug.Log(p);
}
}
}
- ref和out使用场景:
ref :当我们不需要执行完这个方法就可以改变参数值时,或者我们要改变的参数比较多如案例所示
out:用在返回值为void的方法时可以有返回值,还有就是希望函数存在多返回值时,out可以返回多个值如案例所示 - ref和out区别:
两者都是按地址传递的,使用后都将改变原来参数的数值
ref 需要先初始化值 , ref 在使用时属于有进有出
out 不需要先初始化值,out在使用时属于只出不进
5. Struct 和 Class
区别
Struct 是值类型
Class 是引用类型
何时使用
Struct :
- 当我们描述1个轻量级对象的时候,可以将其定义为结构来提高效率.比如点,矩形,颜色,这些对象是轻量级的对象,因为描述他们,只需要少量的字段
- 我们在变量传值的时候,我就是希望传递对象的拷贝,而不是对象的引用地址,那么这个时候也可以使用结构了
Class : 当描述1个重量级对象的时候,我们知道类的对象是存储在堆空间中的,我们就将重量级对象定义为类. 他们都表示可以包含数据成员和函数成员的数据结构