Kafka是什么?
Kafka是一个分布式,有分区的,有副本的日志服务系统,由LinkedIn公司开发,并于2011年开源。从本质上来说,Kafka拥有一套可扩展的发布/订阅消息队列架构,并组成了一套分布式的日志系统,这套系统的创建,是为任何一家大公司搭建一套可处理实时数据的统一平台。
和许多其他消息队列系统相比(RabbitMQ,ActiveMQ,Redis),Kafka有一些主要的区别:
- 如上面提到的,Kafka底层是一个多副本的日志系统
- Kafka并不使用AMQP或其他已经存在的通信协议,而是使用他自己特有的基于TCP的二进制格式的协议
- Kafka很快,即便只使用很小的集群
- Kafka有强大的机制保证消息语义的顺序和持久化
不考虑1.0之前的版本(当前版本是0.9.0.1),kafka已经是产品化了,且被大量著名的企业在使用,包括LinkedIn, Yahoo, Netflix, 和Datadog。
整体架构
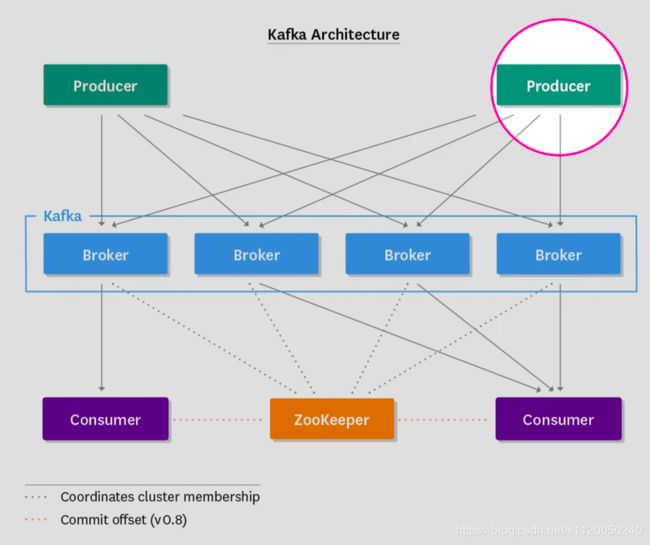
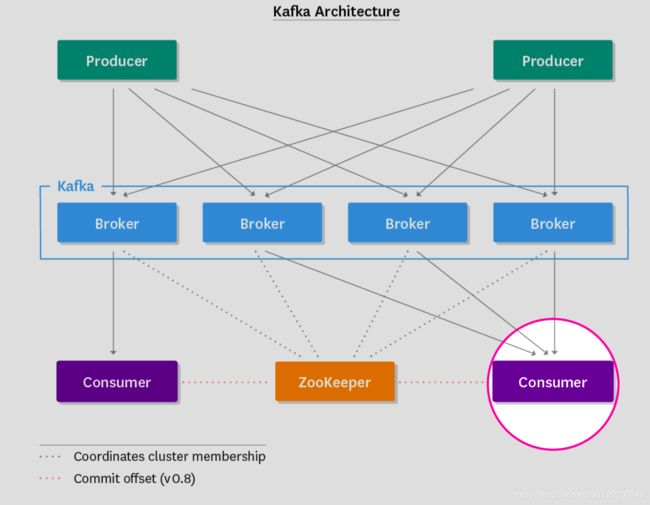
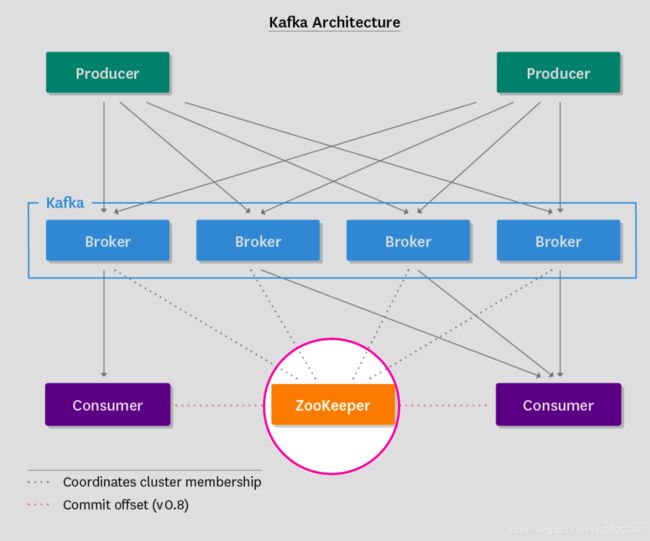
在深入kafka之前,我们有必要了解一下kafka的整体架构,每一个版本都有以下这些组件组成,如图所示:
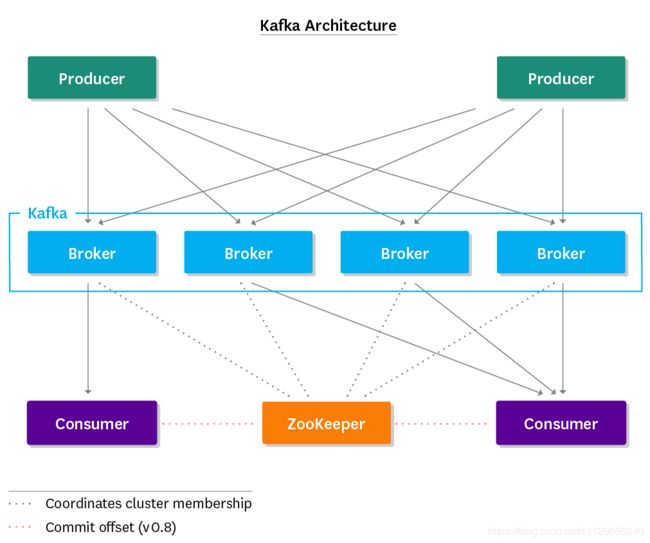
生产者(producer)把消息发布到topic上,然后消费者(consumer)把消息再从topic上消费出来,生产者和消费者采取了一种推/拉(push/pull)的模式,生产者讲消息推到topic上,而消费者把消息从topic上拉下来。Broker作为kafka集群的节点,扮演着一个中间协调者的角色,它存储着生产者发布上去的消息,并让消费者按照自己的速率来拉取。这意味着,broker是无状态的,他们不用跟踪消费的状态,然后会根据配置的保留策略(retention policy)来删除消息。
消息本身是由最原始的二进制字节数组(bytes)组成的,包含了topic和partition的信息。kafka将消息以topic为单位区分,消费者只订阅他们需要的topic。kafka中的消息是按照时间戳排序且不可变,对消费者而言,只有读这一种操作。
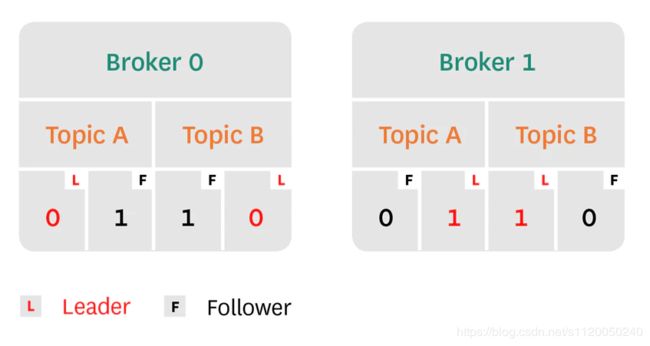
topic被切分成多个分组(paritition),而partition又被分配到多个broker上面,这样,topic就可以按照broker进行数据分片。如果分区数越大,那对于同一个topic而言,就可以同时支持多个消费者的消费。
当第一次设置kafka的时候,需要同时关注两点:给每一个topic分配足够的parition和将parition平均第分配到各个broker上。如果在第一次部署kafka的时候就这样做,可以减轻由于数据量增长带来的痛苦。如果想了解更多关于设置合理的topic数和parition数,可以阅读kafka作者Jun Rao的这篇优秀的文章。
Kafka具有副本的功能,不同的broker上保存了每个parition的不同副本,具体存在几台broker上,是由配置的副本因子所决定的。尽管有大量副本的存在,但kafka只会在最初把数据写入partition的leader(一个leader多个follower),leader是随机的在ISR(in-sync replicas)池(所有处于同步状态的partition副本)中选举出来的。另外,消费者只会读取partition leader,这样follower副本将作为备份存在,以保证kafka的高可用性,从而防某个broker挂掉。
还有很重要的一点,没有任何一个kafka版本是完全脱离zookeeper的,zookeeper就像胶水一样把kafka的所有组件粘连在一起,他的职责是:
- 选举controller(其中某一台kafka broker,用来管理所有的partition leader)
- 记录集群的成员
- topic配置信息
- 磁盘分配(0.9+)
- 安全认证管理 (0.9+)
- 消费组成员管理(从0.9+以后删除)
主要度量指标
一个功能健全的kafka集群可以处理相当大的数据量,由于消息系统是很多大型应用的基石,因此broker集群在性能上的缺陷,都会引起整个应用栈的各种问题。
kafka的度量指标主要有以下三类:
- kafka服务器(broker)指标
- 生产者指标
- 消费者指标
另外,由于kafka的状态靠zookeeper来维护,对于zookeeper性能的监控也成为了整个kafka监控计划中一个必不可少的组成部分。了解更多请看后续的系列文章。
下面分别介绍上面提到的这三个方面的度量指标。
Broker度量指标
kafka的服务端度量指标是为了监控broker,也是整个消息系统的核心。因为所有消息都通过kafka broker传递,然后被消费,所以对于broker集群上出现的问题的监控和告警就尤为重要。broker性能指标有以下三类
- kafka本身的指标
- 主机层面的指标
- JVM垃圾回收指标
kafka本身的指标
| Name | MBean Name | Description | Metric Type |
|---|---|---|---|
| UnderReplicatedPartitions | kafka.server:type=ReplicaManager, name=UnderReplicatedPartitions | Number of unreplicated partitions | Resource: Availability |
| IsrShrinksPerSec IsrExpandsPerSec | kafka.server:type=ReplicaManager, name=IsrShrinksPerSec kafka.server:type=ReplicaManager,name=IsrExpandsPerSec | Rate at which the pool of in-sync replicas (ISRs) shrinks/expands | Resource: Availability |
| ActiveControllerCount | kafka.controller:type=KafkaController, name=ActiveControllerCount | Number of active controllers in cluster | Resource: Error |
| OfflinePartitionsCount | kafka.controller:type=KafkaController, name=OfflinePartitionsCount | Number of offline partitions | Resource: Availability |
| LeaderElectionRateAndTimeMs | kafka.controller:type=ControllerStats, name=LeaderElectionRateAndTimeMs | Leader election rate and latency | Other |
| UncleanLeaderElectionsPerSec | kafka.controller:type=ControllerStats, name=UncleanLeaderElectionsPerSec | Number of "unclean" elections per second | Resource: Error |
| TotalTimeMs | kafka.network:type=RequestMetrics,name=TotalTimeMs,request={Produce-FetchConsumer-FetchFollower} | Total time (in ms) to serve the specified request (Produce/Fetch) | Work: Performance |
| PurgatorySize | kafka.server:type=ProducerRequestPurgatory,name=PurgatorySize kafka.server:type=FetchRequestPurgatory,name=PurgatorySize | Number of requests waiting in producer purgatory ; Number of requests waiting in fetch purgatory | Other |
| BytesInPerSec BytesOutPerSec | kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec | Aggregate incoming/outgoing byte rate | Work: Throughput |
UnderReplicatedPartitions: 在一个运行健康的集群中,处于同步状态的副本数(ISR)应该与总副本数(简称AR:Assigned Repllicas)完全相等,如果分区的副本远远落后于leader,那这个follower将被ISR池删除,随之而来的是IsrShrinksPerSec(可理解为isr的缩水情况,后面会讲)的增加。由于kafka的高可用性必须通过副本来满足,所有有必要重点关注这个指标,让它长期处于大于0的状态。
IsrShrinksPerSec/IsrExpandsPerSec: 任意一个分区的处于同步状态的副本数(ISR)应该保持稳定,只有一种例外,就是当你扩展broker节点或者删除某个partition的时候。为了保证高可用性,健康的kafka集群必须要保证最小ISR数,以防在某个partiton的leader挂掉时它的follower可以接管。一个副本从ISR池中移走有以下一些原因:follower的offset远远落后于leader(改变replica.lag.max.messages 配置项),或者某个follower已经与leader失去联系了某一段时间(改变replica.socket.timeout.ms 配置项),不管是什么原因,如果IsrShrinksPerSec(ISR缩水) 增加了,但并没有随之而来的IsrExpandsPerSec(ISR扩展)的增加,就将引起重视并人工介入,kafka官方文档提供了大量关于broker的用户可配置参数。
ActiveControllerCount: kafka集群中第一个启动的节点自动成为了controller,有且只能有一个这样的节点。controller的职责是维护partitio leader的列表,和协调leader的变更(当遇到某个partiton leader不可用时)。如果有必要更换controller,一个新的controller将会被zookeeper从broker池中随机的选取出来,通常来说,这个值(ActiveControllerCount)不可能大于1,但是当遇到这个值等于0且持续了一小段时间(<1秒)的时候,必须发出明确的告警。
OfflinePartitionsCount (只有controller有): 这个指标报告了没有活跃leader的partition数,由于所有的读写操作都只在partition leader上进行,因此非0的这个值需要被告警出来,从而防止服务中断。任何没有活跃leader的partition都会彻底不可用,且该parition上的消费者和生产者都将被阻塞,直到leader变成可用。
LeaderElectionRateAndTimeMs: 当parition leader挂了以后,新leader的选举就被触发。当partition leader与zookeeper失去连接以后,它就被人为是“死了”,不像zookeeper zab,kafka没有专门对leader选举采用majority-consensus算法。是kafka的broker集群所有的机器列表,是由每一个parition的ISR所包含的机器这个子集,加起来的并集组成的,怎么说,假设一共有3个parition,第一个parition的ISR包含broker1、2、3,第二个parition包含broker2、3、4,第三个parition包含broker3、4、5,那么这三个parition的ISR所在broker节点加起来的并集就是整个kafka集群的所有broker全集1、2、3、4、5。当副本可以被leader捕获到的时候,我们就人为它处于同步状态(in-sync),这意味着任何在ISR池中的节点,都有可能被选举为leader。
LeaderElectionRateAndTimeMs 报告了两点:leader选举的频率(每秒钟多少次)和集群中无leader状态的时长(以毫秒为单位),尽管不像UncleanLeaderElectionsPerSec这个指标那么严重,但你也需要时长关注它,就像上文提到的,leader选举是在与当前leader通信失败时才会触发的,所以这种情况可以理解为存在一个挂掉的broker。
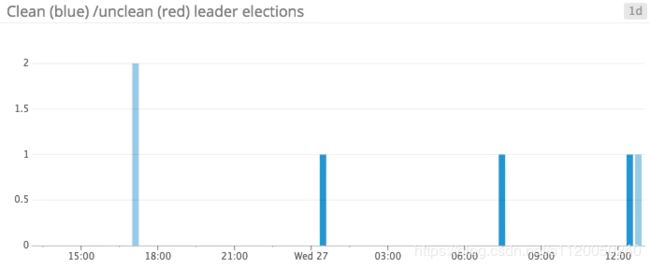
UncleanLeaderElectionsPerSec: 这个指标如果存在的话很糟糕,这说明kafka集群在寻找partition leader节点上出现了故障,通常,如果某个作为partition leader的broker挂了以后,一个新的leader会被从ISR集合中选举出来,不干净的leader选举(Unclean leader elections )是一种特殊的情况,这种情况是副本池中没有存活的副本。基于每个topic必须拥有一个leader,而如果首领是从处于不同步状态的副本中选举出来的话,意味着那些与之前的leader没有被同步的消息,将会永久性丢失。事实上,不干净的leader选举将牺牲持久性(consistency)来保证可用性(availability)。所以,我们必须明确地得到这个指标的告警,从而告知数据的丢失。
TotalTimeMs: The TotalTimeMs metric family measures the total time taken to service a request (be it a produce, fetch-consumer, or fetch-follower request):
这个指标族(很多地方都涉及到它)衡量了各种服务请求的时间(包括produce,fetch-consumer,fetch-follower)
produce:从producer发起请求发送数据
fetch-consumer: 从consumer发起请求获取数据
fetch-follower:follower节点向leader节点发起请求,同步数据
TotalTimeMs 这个指标是由4个其他指标的总和构成的:
queue:处于请求队列中的等待时间
local:leader节点处理的时间
remote:等待follower节点响应的时间(只有当
requests.required.acks=-1时)response:发送响应的时间
通常情况下,这个指标值是比较稳定的,只有很小的波动。当你看到不规则的数据波动,你必须检查每一个queue,local,remote和response的值,从而定位处造成延迟的原因到底处于哪个segment。

PurgatorySize: 请求炼狱(request purgatory)作为一个临时存放的区域,使得生产(produce)和消费(fetch)的请求在那里等待直到被需要的时候。每个类型的请求都有各自的参数配置,从而决定是否(将消息)添加到炼狱中:
fetch:当
fetch.wait.max.ms定义的时间已到,还没有足够的数据来填充(congsumer的fetch.min.bytes)请求的时候,获取消息的请求就会被扔到炼狱中。produce:当
request.required.acks=-1,所有的生产请求都会被暂时放到炼狱中,直到partition leader收到follower的确认消息。
关注炼狱的大小有助于判断导致延迟的原因是什么,比如说,导致fetch时间的增加,很显然可以认为是由于炼狱中fetch的请求增加了。
BytesInPerSec/BytesOutPerSec: 通常,磁盘的吞吐量往往是决定kafka性能的瓶颈,但也不是说网络就不会成为瓶颈。根据你实际的使用场景,硬件和配置,网络将很快会成为消息传输过程中最慢的一个环节,尤其是当你的消息跨数据中心传输的时候。跟踪节点之间的网络吞吐量,可以帮助你找到潜在的瓶颈在哪里,而且可以帮助决策是否需要把端到端的消息做压缩处理。
主机层面的broker性能指标
| Name | Description | Metric Type |
|---|---|---|
| Page cache reads ratio | Ratio of reads from page cache vs reads from disk | Resource: Saturation |
| Disk usage | Disk space currently consumed vs available | Resource: Utilization |
| CPU usage | CPU use | Resource: Utilization |
| Network bytes sent/received | Network traffic in/out | Resource: Utilization |
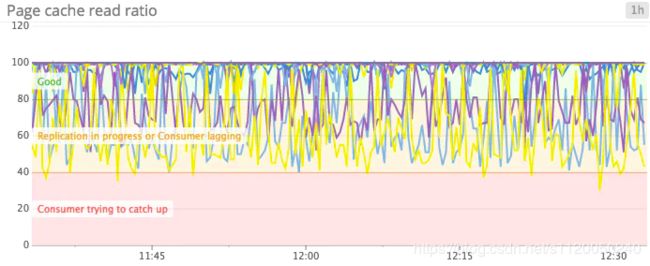
Page cache read ratio: kafka在设计最初的时候,通过内核中的页缓存,来达到沟通可靠性(基于磁盘)和高效性(基于内存)之间的桥梁。page cache read ratio(可理解为页缓存读取率),和数据库中的cache-hit ratio(缓存命中率)比较相似,如果这个值比较大,则等价于更快的读取速度,从而有更好的性能。如果发现页缓存读取率<80%,则说明需要增加broker了。
Disk usage: 由于kafka将所有数据持久化到磁盘上,很有必要监控一下kafka的剩余磁盘空间。当磁盘占满时,kafka会失败,所以,随着时间的推移,跟踪磁盘的增长率是很有必要的。一旦你了解了磁盘的增长速率,你就可以在磁盘将要占满之前选择一个合适的时间通知管理员。

CPU usage: 尽管kafka主要的瓶颈通常是内存,但并不妨碍观察一下cpu的使用率。虽然即便在使用gzip压缩的场景下,cpu都不太可能对性能产生影响,但是,如果发现cpu使用率突然增高,那肯定要引起重视了。
Network bytes sent/received: 如果你只是在监控kafka的网络in/out指标,那你只会了解到跟kafka相关的信息。如果要全面了解主机的网络使用情况,你必须监控主机层面的网络吞吐量,尤其是当你的kafka主机还承载了其他与网络有关的服务。高网络使用率是性能下降的一种表现,此时需要联系TCP重传和丢包错误,来决定性能的问题是否是网络相关的。
JVM垃圾回收指标
由于kafka是由scala编写的,且运行在java虚拟机上,需要依赖java的垃圾回收机制来释放内存,如果kafka集群越活跃,则垃圾回收的频率也就越高。
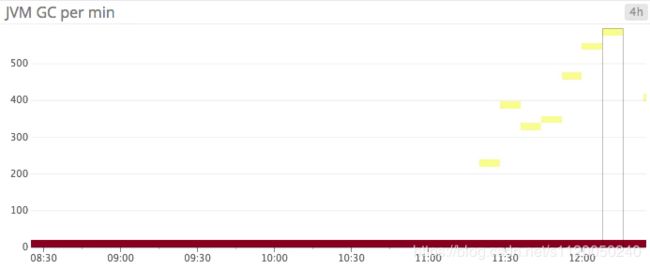
只要对java有些了解的人都应该知道垃圾回收会产生很大的性能开销,(垃圾回收造成的)暂停对kafka最大的影响就是会造成大量废弃的zookeeper session(因为session超时了)。
垃圾回收的类型是基于回收的是年轻代(新的对象)还是老年代(长期存活的对象),初学者可以看这篇关于垃圾回收的文章:
当发现垃圾回收造成了过度的暂停,你可以考虑升级JDK版本或者垃圾回收器(或者增加zookeeper.session.timeout.ms来防止time out)。另外,可以调节java runtime参数来最小化垃圾回收。LInkedin的工程师写了这么一篇深入介绍优化垃圾回收的文章,供参考。当然,也可以直接参考kafka官方文档中给出的推荐配置。
| Name | MBean Name | Description | Type |
|---|---|---|---|
| ParNew count | java.lang:type=GarbageCollector,name=ParNew | Number of young-generation collections | Other |
| ParNew time | java.lang:type=GarbageCollector,name=ParNew | Elapsed time of young-generation collections, in milliseconds | Other |
| ConcurrentMarkSweep count | java.lang:type=GarbageCollector,name=ConcurrentMarkSweep | Number of old-generation collections | Other |
| ConcurrentMarkSweep time | java.lang:type=GarbageCollector,name=ConcurrentMarkSweep | Elapsed time of old-generation collections, in milliseconds | Other |
ParNew:可以理解成年轻代,这部分的垃圾回收会相当频繁,ParNew是一个stop-the-world的垃圾回收,意味着所有应用线程都将被暂停,知道垃圾回收完成,所以ParNew延迟的任何增加都会对kafka的性能造成严重影响。
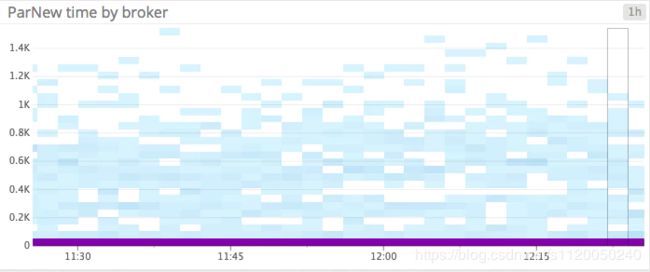
ConcurrentMarkSweep (CMS) :这种垃圾回收清理了堆上的老年代不用的内存,CMS是一个短暂暂停的垃圾回收算法,尽管会造成应用线程的短暂停顿,但这只是间歇性的,如果CMS需要几秒钟才能完成,或者发生的频次增加,那么集群就没有足够的内存来满足基本功能。
kafka生产者指标
kafka的生产者是专门把消息推送到broker的topic上供别人消费的,如果producer失败了,那consumer也将无法消费到新的消息,下面是生产者的几个有用的重要监控指标,保证数据流的稳定性。
| Name | v0.8.2.x MBean Name | v0.9.0.x MBean Name | Description | Metric Type |
|---|---|---|---|---|
| Response rate | N/A | kafka.producer:type=producer-metrics,client-id=([-.w]+) | Average number of responses received per second | Work: Throughput |
| Request rate | kafka.producer:type=ProducerRequestMetrics, name=ProducerRequestRateAndTimeMs,clientId=([-.w]+) | kafka.producer:type=producer-metrics,client-id=([-.w]+) | Average number of requests sent per second | Work: Throughput |
| Request latency avg | kafka.producer:type=ProducerRequestMetrics, name=ProducerRequestRateAndTimeMs,clientId=([-.w]+) | kafka.producer:type=producer-metrics,client-id=([-.w]+) | Average request latency (in ms) | Work: Throughput |
| Outgoing byte rate | kafka.producer:type=ProducerTopicMetrics, name=BytesPerSec,clientId=([-.w]+) | kafka.producer:type=producer-metrics,client-id=([-.w]+) | Average number of outgoing/incoming bytes per second | Work: Throughput |
| IO wait time ns avg | N/A | kafka.producer:type=producer-metrics,client-id=([-.w]+) | Average length of time the I/O thread spent waiting for a socket (in ns) | Work: Throughput |
对生产者来说,响应速率表示从broker上得到响应的速率,当broker接收到producer的数据时会给出响应,根据配置,“接收到”包含三层意思:
- 消息已接收到,但并未确认(
request.required.acks == 0) - leader已经把数据写入磁盘(
request.required.acks == 1) - leader节点已经从其他follower节点上接收到了数据已写入磁盘的确认消息(
request.required.acks == -1)
这看上去很完美,但是对消费者而言,只有当上述的这些确认步骤都准确无误以后,才能读取到producer生产的数据。
如果你发现响应速率很低,那是因为在这个过程中需要牵扯太多因素,一个很简单的办法就是检查broker上配置的request.required.acks参数,根据你的使用场景来选择合适的值,到底是更看中可用性(availability)还是持久性(consistency),前者强调消费者是否能尽快读取到可用的消息,而后者强调消息是否准确无误地持久化写入某个topic的某个partition的所有副本的磁盘中。
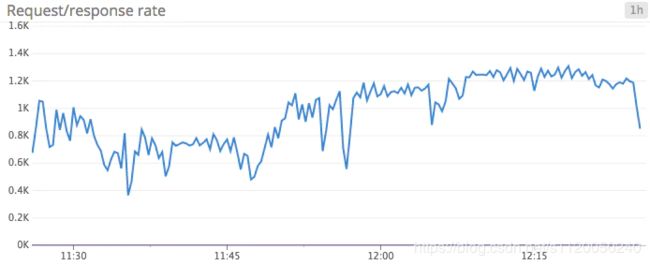
Request rate:请求的速率是指数据从producer发送到broker的速率,很显然,请求的速率变化是否健康,也是由使用的场景所决定的。关注速率走势的上和下,对于保证服务的可用性非常关键,如果不开启速率限制(rate-limiting)(0.9+版本才有),那么当流量高峰来临时,broker就将变得很慢,因为他要忙于处理大量涌入的数据。
Request latency average: 平均请求延迟,这是用来衡量从producer调用KafkaProducer.send()方法到接收到broker响应的时长。“接收到”包含很多层意思,可参考response rate那一块。
有多种途径可以减少延迟,主要的途径是producer的linger.ms 配置项,这个配置项告诉producer,在累积够一个消息批次之前,需要等待多久才能发送。默认地,producer只要接收到上一次发送的确认消息后,就立即发送新的消息,但并非所有场景都适用,为了累积消息而等待一点时间会提高吞吐量。
由于延迟和吞吐量有着必然的联系,就很有必要关注batch.size这个producer配置项,从而达到更完美的吞吐量。并不是只要配置一个合适的值就可以一劳永逸了,要视情况决定如何选择一个更优的批大小。要记住,你所配置的批大小是一个上限值,意思是说,如果数据满了,就立即发送,但如果没满的话,最多只等linger.ms 毫秒,小的批量将会导致更多次数的网络通信,然后降低吞吐量,反之亦然。
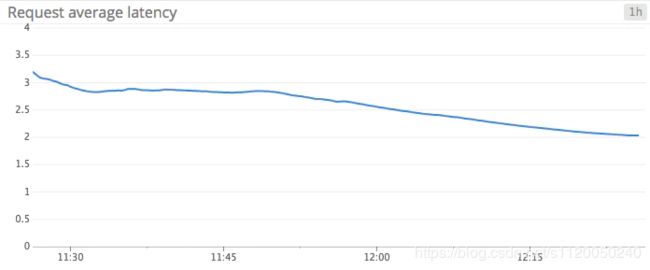
Outgoing byte rate: 在kafka的broker中,肯定需要监控producer的网络吞吐量,随着时间的变化观察网络上的数据传输量是很有必要的,从而决定是否有必要调整网络设备。另外,也很有必要知道producer是否以一个恒定的速率发送数据,从而让consumer获取到。监控producer的网络传输情况,除了可以决定是否需要调整网络设备,也可以了解producer的生产效率,以及定位传输延迟的原因。
IO wait time: Producer通常做了这么一些事:等待数据和发送数据。当producer产生了超越他发送能力的数据量,那结果就是只能等待网络资源。当如果producer没有发送速度限制,或者尽可能增加带宽,就很难说这(网络延迟)是个瓶颈了。因为磁盘的读写速率往往是最耗时的一个环节,所以对producer而言,最好检查一下I/O等待的时间。请记住,I/O等待表示当CPU停下来等待I/O的时间,如果你发现了过分的等待时间,这说明producer无法足够快地获取他需要的数据,如果你还在使用传统的机械磁盘作为存储,那请考虑采用SSD。
Kafka消费者指标
0.8.2.2版本
在0.8.2.2版本中,消费者指标分成两类:简单消费者指标和高阶消费者指标。
所有简单消费者指标都被高阶消费者采纳,但反过来并非如此。这两者之间最主要的区别就是开发者对于消费者的掌控程度不同。
简单消费者,事实上就是那些被明确地告知连接哪个broker,哪个partition。简单消费者也可以自行管理offset和进行parition leader的选举。尽管为了保证消费者可以真正运行起来,需要做很多工作,但简单消费者也是相对更灵活的。
高阶消费者(也被称为消费者组)忽略了大量实施过程中的细节,那些细节包括offset的位置,broker leader,和zookeeper管理的分区可用性,消费者组只做他最擅长的事,就是消费数据。然而,其实简单消费者更强大,高阶消费者更灵活。
0.9.0.0+版本
kafka0.9.0.0版本包括了很多新特性,包括了对consumer api的很多大调整。在0.9+以上版本中,专门定义了一类消费者指标,可以通过调用新api得到,这些消费者指标把0.8.2.2中的普通消费者和高阶消费者结合到了一起,而且使用了完全不同的MBean命名空间。
| Name | v0.8.2.x MBean Name | v0.9.0.x MBean Name | Description | Metric Type | v0.8.2.x Consumer Type |
|---|---|---|---|---|---|
| ConsumerLag MaxLag | broker offset - consumer offset kafka.consumer:type= ConsumerFetcherManager, name=MaxLag, clientId=([-.\w]+) | broker offset - consumer offset Attribute: records-lag-max, kafka.consumer:type=consumer-fetch-manager-metrics,client-id=([-.w]+) | Number of messages consumer is behind producer / Maximum number of messages consumer is behind producer | Work: Performance | Simple Consumer |
| BytesPerSec | kafka.consumer:type= ConsumerTopicMetrics, name=BytesPerSec, clientId=([-.\w]+) | kafka.consumer:type=consumer-fetch-manager-metrics,client-id=([-.\w]+) | Bytes consumed per second | Work: Throughput | Simple Consumer |
| MessagesPerSec | kafka.consumer:type= ConsumerTopicMetrics, name=MessagesPerSec, clientId=([-.\w]+) | kafka.consumer:type=consumer-fetch-manager-metrics,client-id=([-.\w]+) | Messages consumed per second | Work: Throughput | Simple Consumer |
| ZooKeeperCommitsPerSec | kafka.consumer:type= ZookeeperConsumerConnector, name=ZooKeeperCommitsPerSec, clientId=([-.\w]+) | N/A | Rate of consumer offset commits to ZooKeeper | Work: Throughput | High-level Consumer |
| MinFetchRate | kafka.consumer:type= ConsumerFetcherManager, name=MinFetchRate, clientId=([-.\w]+) | Attribute: fetch-rate, kafka.consumer:type=consumer-fetch-manager-metrics,client-id=([-.w]+) | Minimum rate a consumer fetches requests to the broker | Work: Throughput |
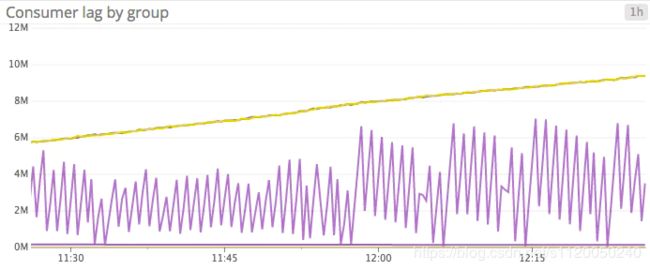
ConsumerLag/MaxLag:这是所有人都很中意的kafka指标,ConsumerLag是指consumer当前的日志偏移量相对生产者的日志偏移量,MaxLag和ConsumerLag的关系很紧密,相当于是观察到的ConsumerLag的最大值,这两个度量指标的重要性在于,可以决定你的消费者在做什么。如果采用一个消费者组在存储设备上存储大量老的消息,你就需要重点关注消费者的延迟。当然,如果你的消费者处理的是实时消息,如果lag值一直居高不下,那就说明消费者有些过载(overloaded)了,遇到这种情况,就需要采用更多的消费者,和把topic切分成多个parition,从而可以提高吞吐量和降低延迟。
注意:ConsumerLag 是kafka之中过载的表现,正如上面的定义中所描述的额一样,但它也可被用来表示partition leader和follower之间的offset差异。
BytesPerSec:正如前文提到的生产者和broker的关系,也需要监控消费者的网络吞吐量。比如,MessagesPerSec的突然下降可能会导致消费失败,但如果BytesPerSec还保持不变,那如果消费少批次大体量的消息问题还不大。不断观察网络的流量,就像其他度量指标中提到的一样,诊断不正常的网络使用情况是很重要的。
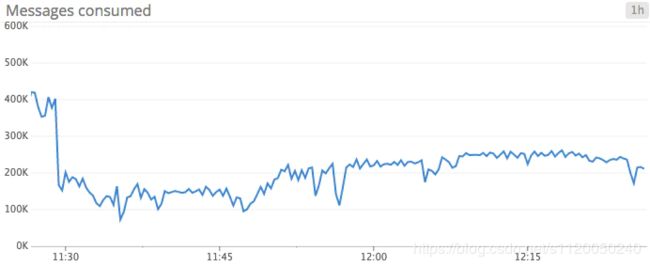
MessagesPerSec: 消息的消费速度并不完全等同于比特的消费速度,因为消息本身可能有不同大小。依赖生产者和工作负载量,在典型的部署环境中,往往希望这个值是相当稳定的。通过随着时间的推移监控这个指标,可以观察出消费数据的趋势,然后定出一个基线,从而确定告警的阈值。这个曲线的走势取决于你的使用场景,但不管怎样,在很多情况下,定出一条基线然后对于异常情况做出告警是很有必要的。
ZooKeeperCommitsPerSec:只有0.8x版本有,如果把zookeeper作为offset的存储(在0.8x版本中是默认的,0.9+版本必须显式地在配置中定义offsets.storage=zookeeper),那你肯定需要监控这个值。注意到如果想要在0.9+版本中明确使用zookeeper作为offset存储,这个指标并没有被开放。当zookeeper处于高写负载的时候,将会遇到成为性能瓶颈,从而导致从kafka管道抓取数据变得缓慢。随着时间推移跟踪这个指标,可以帮助定位到zookeeper的性能问题,如果发现有大量发往zookeeper的commit请求,你需要考虑的是,要不对zookeeper集群进行扩展,要不直接把offset的存储变为kafka(offsets.storage=kafka)。记住,这个指标只对高阶消费者有用,简单消费者自行管理offset。
MinFetchRate: 消费者拉取的速率很好反映了消费者的整体健康状况,如果最小拉取速率接近0的话,就可能说明消费者出现问题了,对一个健康的消费者来说,最小拉取速率通常都是非0的,所以如果发现这个值在下降,往往就是消费者失败的标志。
为什么要用zookeeper?
zookeeper在kafka的集群中扮演了非常重要的角色,他的职责是:维护消费者的offset和topic列表,leader选举,以及某些常用的状态信息。在kafka0.8版本中,broker和consumer的协作都是通过zookeeper来进行的,在0.9版本中,zookeeper只是被broker用到(默认是这样的,除非你有其他配置),这样会大大地降低zookeeper的负载,尤其是在大集群中。
Zookeeper度量指标
可以通过MBean和命令行接口来获取zookeeper的度量指标,
| Name | Description | Metric Type |
|---|---|---|
zk_outstanding_requests |
Number of requests queued | Resource: Saturation |
zk_avg_latency |
Amount of time it takes to respond to a client request (in ms) | Work: Throughput |
zk_num_alive_connections |
Number of clients connected to ZooKeeper | Resource: Availability |
zk_followers |
Number of active followers | Resource: Availability |
zk_pending_syncs |
Number of pending syncs from followers | Other |
zk_open_file_descriptor_count |
Number of file descriptors in use | Resource: Utilization |
Bytes sent/received:在0.8x版本中,broker和consumer都要和zookeeper通信,大规模部署的集群中,有很多consumer和partition,这种和zookeeper连续不断地通信将会成为zookeeper的瓶颈,因为zookeeper是串行处理请求的。根据时间变化跟踪发送和接受数据比特大小可以帮助诊断性能问题。如果zookeeper集群需要连续不断处理大流量,那么就需要为集群提供更多节点,来适应更大数据量。
Usable memory: zookeeper需要加载大量数据到内存中,当需要page到磁盘上的时候是最痛苦的。所以,为了使zookeeper的性能更优,跟踪内存使用率是很有必要的。记住,因为zookeeper是用来保存状态的,所以zookeeper的性能下降将会导致整个kafka集群的性能下降。因此,所有作为zookeeper节点的主机都需要拥有较大的内存,来应对负载的高峰。
Swap usage: 如果发现内存不够了,将会用到swap,如上文提到的那样,这样是不好的,所以你必须知道它。
Disk latency:尽管zookeeper主要是使用内存,但也会用到文件系统,用来有规律地对当前状态做快照,和保存所有事务的日志。由于在update发生以后,zookeeper必须要把事务写到非易失的存储设备上,这是的磁盘的读写存在潜在瓶颈,磁盘延迟的突增,会导致所有与zookeeper通信的服务器响应变慢,所以除了把zookeeper服务器的磁盘换成SSD,还需要时刻关注磁盘延迟。