王校长撩妹不成反被锤爆?再有钱的舔狗也只是舔狗【Python爬虫实战:微博评论采取】
大家好,我是辣条呀~
正如标题所示,想必这两天大家被王校长的瓜轰炸了吧,微博上都上了几轮热搜了,我也是吃的津津有味,难得看王校长在女生面前吃瘪呀。加上和一个朋友聊到了微博评论采集遇到的问题,有感而发写了这篇文章,话不多说直接进入主题吧。

Python爬虫实战,理性吃wsc的瓜
-
- 爬取目标
- 效果展示
- 工具使用
- 项目思路解析
- 简易源码分析
爬取目标
网址:[微博](https://m.weibo.cn/detai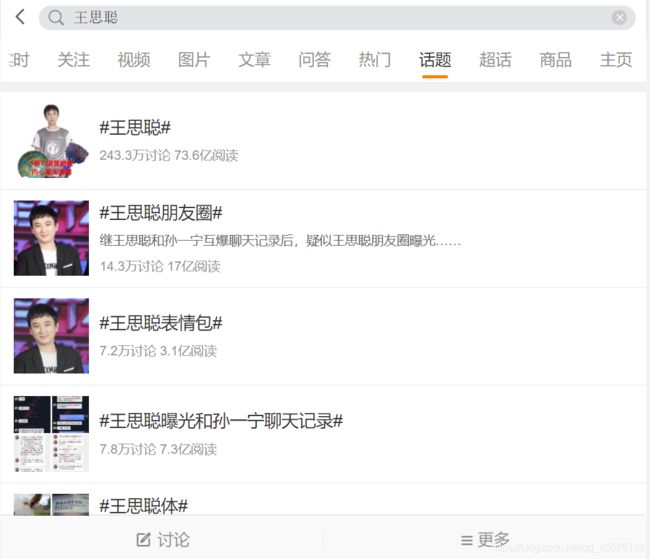
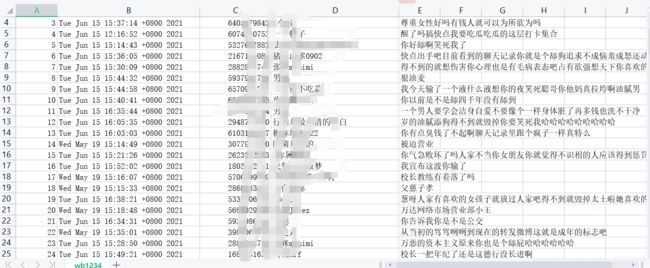
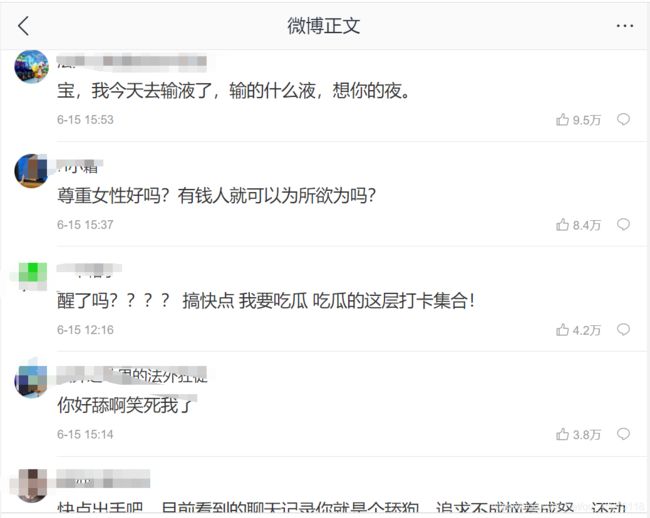
效果展示
工具使用
开发环境:win10、python3.7
开发工具:pycharm、Chrome
工具包:requests、re,csv
项目思路解析
找到需要吃瓜的文章
请求头需要带上的基本配置数据
headers = {
"referer": "",
"cookie":"",
"user-agent": ""
}
找到文章动态提交的评论数据
通过抓包工具找到对应的评论数据信息
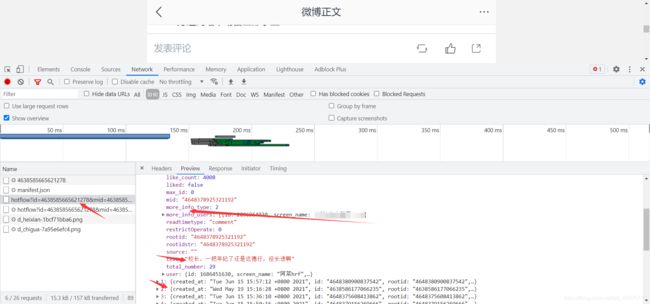
微博的url会有一个文章id,mid也是文章id, max_id是每个json数据里面的max_id,是没有规律得。
https://m.weibo.cn/comments/hotflow?id=4638585665621278&mid=4638585665621278&max_id=1190535179743975&max_id_type=0
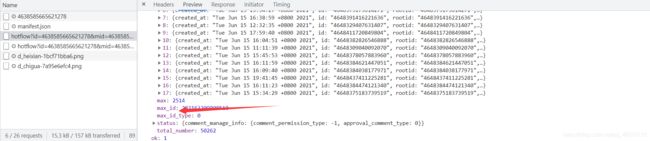
取出当前的max_id,就会获取到下个页面的请求接口
简易源码分析
import csv
import re
import requests
import time
start_url = "https://m.weibo.cn/comments/hotflow?id=4638585665621278&mid=4638585661278&max_id_type=0"
next_url = "https://m.weibo.cn/comments/hotflow?id=4638585665621278&mid=4638585661278&max_id={}&max_id_type=0"
continue_url = start_url
headers = {
"referer": "",
"cookie": "",
"user-agent": ""
}
count = 0
def csv_data(fileheader):
with open("wb1234.csv", "a", newline="")as f:
write = csv.writer(f)
write.writerow(fileheader)
def get_data(start_url):
print(start_url)
response = requests.get(start_url, headers=headers).json()
print(response)
max_id = response['data']['max_id']
print(max_id)
content_list = response.get("data").get('data')
for item in content_list:
global count
count += 1
create_time = item['created_at']
text = "".join(re.findall('[\u4e00-\u9fa5]', item["text"]))
user_id = item.get("user")["id"]
user_name = item.get("user")["screen_name"]
# print([count, create_time, user_id, user_name, text])
csv_data([count, create_time, user_id, user_name, text])
global next_url
continue_url = next_url.format(max_id)
print(continue_url)
time.sleep(2)
get_data(continue_url)
if __name__ == "__main__":
fileheader = ["id", "评论时间", "用户id", "user_name", "评论内容"]
csv_data(fileheader)
get_data(start_url)
PS:不占哪一方,也不做评价,希望能让大家吃瓜的同时又能学到技术,对你有帮助的话记得给辣条三连吧,最后祝大家感情都能顺顺利利,没有脱单的早日脱单啦,脱单的早日成眷属。