(学习笔记,待补充)
本文目录如下:
- 1.卷积神经网络基础
- 1.1 二维互相关运算
- 1.2 二维卷积层
- 1.3 填充和步幅
- 1.4 多通道输入和输出
- 1.5 池化层
-
- 几个经典的卷积神经网络
- 2.1 LeNet
- 2.2 AlexNet
- 2.3 VGG-16
- 2.4 NiN
- 2.5 GoogleNet
1.卷积神经网络基础
1.1 二维互相关运算
def corr2d(X, K):
H, W = X.shape
h, w = K.shape
Y = torch.zeros(H - h + 1, W - w + 1)
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i: i + h, j: j + w] * K).sum()
return Y
其中,X是指输入,K是指核。
X = torch.tensor([[0, 1, 2], [3, 4, 5], [6, 7, 8]])
K = torch.tensor([[0, 1], [2, 3]])
print(X, '\n')
print(K, '\n')
Y = corr2d(X, K)
print(Y)
结果为:

1.2 二维卷积层
二维卷积层将输入和卷积核做互相关运算,并加上bias
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super(Conv2D, self).__init__()
self.weight = nn.Parameter(torch.randn(kernel_size))
self.bias = nn.Parameter(torch.randn(1))
def forward(self, x):
return corr2d(x, self.weight) + self.bias
# 通常,我们如果想在模型中维护一些可学习的参数,就会将它们定义为nn.Parameter.
# 首先,Parameter本身是tensor的子类,所以会自动地给参数附上梯度;其次,nn.Module的一个子类,会维护参数的一个集合,用nn.Parameter会自动将参数注册进去。
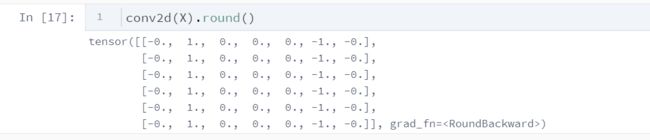
下面用一个边缘检测的例子。
我们构造一张的图像,中间4列为黑(0),其余为白(1),希望检测到颜色边缘。我们的标签是一个的二维数组,第2列是1(从1到0的边缘),第6列是-1(从0到1的边缘)。
X = torch.ones(6, 8)
Y = torch.zeros(6, 7)
X[:, 2: 6] = 0
Y[:, 1] = 1
Y[:, 5] = -1
print(X)
print(Y)

我们希望学习一个卷积层,通过卷积层来检测颜色边缘。
为什么是呢?
因为在我们构造的这个例子里,我们其实关注的是同一行相邻两个元素的变化,所以我们每次关注的是输入当中一个一行二列的区域。
conv2d = Conv2D(kernel_size=(1,2))
step = 30
lr = 0.01
for i in range(step):
Y_hat = conv2d(X)
l = ((Y_hat - Y) ** 2).sum()
l.backward()
# 梯度下降
conv2d.weight.data -= lr * conv2d.weight.grad
conv2d.bias.data -= lr * conv2d.bias.grad
# 梯度清零
conv2d.weight.grad.zero_()
conv2d.bias.grad.zero_()
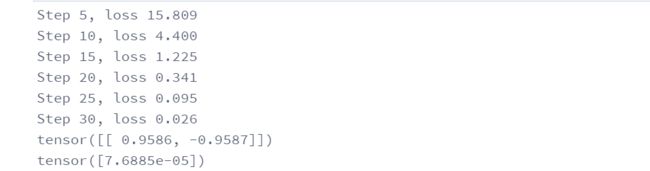
# 每隔5个训练步输出一下
if (i + 1) % 5 == 0:
print('Step %d, loss %.3f' % (i + 1, l.item()))
print(conv2d.weight.data)
print(conv2d.bias.data)
1.3 填充和步幅
填充
上一节我们知道,如果我们用的输入,的核做卷积,那么输出则应该是,当神经网络的层数越来越多时,这会带来两个问题:
第一,做了几次卷积之后,我们的图像就会变得很小。第二,我们会损失掉一些边缘信息。
为了解决这个问题,我们可以在卷积操作之前填充这幅图像。
填充(padding)是指在输入高和宽的两侧填充元素,通常填充的是0元素。
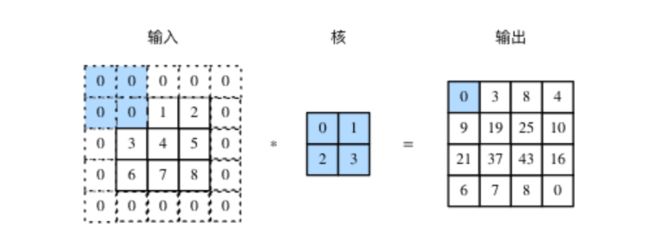
如果原输入的高和宽是和,卷积核的高和宽是和,在高的两侧一共填充行,在宽的两侧一共填充列,则输出形状为:
我们在卷积神经网络中使用奇数高宽的核,比如,的卷积核,对于高度(或宽度)为大小为的核,令步幅为1,在高(或宽)两侧选择大小为的填充,便可保持输入与输出尺寸相同。
步幅
在互相关运算当中,每次滑动的行数1就是步幅(stride)。
一般来说,当高上步幅为,宽上步幅为时,输出形状为:
如果,,那么输出形状将简化为。更进一步,如果输入的高和宽能分别被高和宽上的步幅整除,那么输出形状将是。
当时,我们称填充为;当时,我们称步幅为。
1.4 多通道输入和输出
多通道输入
之前的输入和输出都是二维数组,但真实数据的维度经常更高。例如,彩色图像在高和宽2个维度外还有RGB(红、绿、蓝)3个颜色通道。假设彩色图像的高和宽分别是和(像素),那么它可以表示为一个的多维数组,我们将大小为3的这一维称为通道(channel)维。

多通道输出
卷积层的输出也可以包含多个通道,设卷积核输入通道数和输出通道数分别为和,高和宽分别为和。如果希望得到含多个通道的输出,我们可以为每个输出通道分别创建形状为的核数组,将它们在输出通道维上连结,卷积核的形状即。
对于输出通道的卷积核,我们提供这样一种理解,一个的核数组可以提取某种局部特征,但是输入可能具有相当丰富的特征,我们需要有多个这样的的核数组,不同的核数组提取的是不同的特征。
1.5 池化层(pooling layers)
除了卷积层,卷积神经网络通常也使用池化层来缩减模型大小,提高计算速度。
(1)怎么缩减规模呢?
以最大池化层为例,每个区域只保留最大值,则模型规模减小了。

(2)池化层输出的大小计算与卷积层一样
其中,p为padding,s为stride
(3)值得注意的是,与卷积层不同,池化层的每个通道是分别计算的,输入个通道,就输出个通道,而卷积层则是输出1个通道(除非多个过滤器/核)。
(4)通常使用最大池化层,而平均池化层很少用。
(5)池化过程中没有需要学习的参数。
(6)最大池化层很少用padding。
2. 几个经典的卷积神经网络
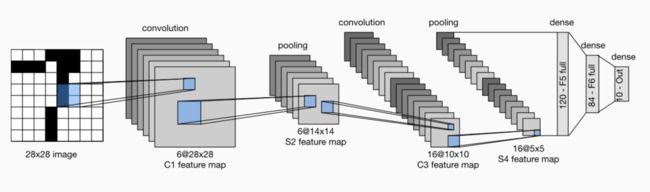
2.1 LeNet
LeNet的结构就是:
卷积-池化-卷积-池化-卷积-池化.......卷积-池化-sigmoid函数
#net
class Flatten(torch.nn.Module): #展平操作
def forward(self, x):
return x.view(x.shape[0], -1)
class Reshape(torch.nn.Module): #将图像大小重定型
def forward(self, x):
return x.view(-1,1,28,28) #(B x C x H x W)
net = torch.nn.Sequential( #Lelet
Reshape(),
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2), #b*1*28*28 =>b*6*28*28
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), #b*6*28*28 =>b*6*14*14
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5), #b*6*14*14 =>b*16*10*10
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), #b*16*10*10 => b*16*5*5
Flatten(), #b*16*5*5 => b*400
nn.Linear(in_features=16*5*5, out_features=120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10)
)
接下来构造一个高和宽均为28的单通道数据样本,并逐层进行向前计算查看每个层的输出情况
X = torch.randn(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape: \t',X.shape)
输出结果为:

#计算准确率
'''
(1). net.train()
启用 BatchNormalization 和 Dropout,将BatchNormalization和Dropout置为True
(2). net.eval()
不启用 BatchNormalization 和 Dropout,将BatchNormalization和Dropout置为False
'''
def evaluate_accuracy(data_iter, net,device=torch.device('cpu')):
"""Evaluate accuracy of a model on the given data set."""
acc_sum,n = torch.tensor([0],dtype=torch.float32,device=device),0
for X,y in data_iter:
# If device is the GPU, copy the data to the GPU.
X,y = X.to(device),y.to(device)
net.eval()
with torch.no_grad():
y = y.long()
acc_sum += torch.sum((torch.argmax(net(X), dim=1) == y)) #[[0.2 ,0.4 ,0.5 ,0.6 ,0.8] ,[ 0.1,0.2 ,0.4 ,0.3 ,0.1]] => [ 4 , 2 ]
n += y.shape[0]
return acc_sum.item()/n
#训练函数
def train_ch5(net, train_iter, test_iter,criterion, num_epochs, batch_size, device,lr=None):
"""Train and evaluate a model with CPU or GPU."""
print('training on', device)
net.to(device)
optimizer = optim.SGD(net.parameters(), lr=lr)
for epoch in range(num_epochs):
train_l_sum = torch.tensor([0.0],dtype=torch.float32,device=device)
train_acc_sum = torch.tensor([0.0],dtype=torch.float32,device=device)
n, start = 0, time.time()
for X, y in train_iter:
net.train()
optimizer.zero_grad()
X,y = X.to(device),y.to(device)
y_hat = net(X)
loss = criterion(y_hat, y)
loss.backward()
optimizer.step()
with torch.no_grad():
y = y.long()
train_l_sum += loss.float()
train_acc_sum += (torch.sum((torch.argmax(y_hat, dim=1) == y))).float()
n += y.shape[0]
test_acc = evaluate_accuracy(test_iter, net,device)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, '
'time %.1f sec'
% (epoch + 1, train_l_sum/n, train_acc_sum/n, test_acc,
time.time() - start))
# 训练
lr, num_epochs = 0.9, 10
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
torch.nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
net = net.to(device)
criterion = nn.CrossEntropyLoss() #交叉熵描述了两个概率分布之间的距离,交叉熵越小说明两者之间越接近
train_ch5(net, train_iter, test_iter, criterion,num_epochs, batch_size,device, lr)
# test
for testdata,testlabe in test_iter:
testdata,testlabe = testdata.to(device),testlabe.to(device)
break
print(testdata.shape,testlabe.shape)
net.eval()
y_pre = net(testdata)
print(torch.argmax(y_pre,dim=1)[:10])
print(testlabe[:10])
2.2 AlexNet
AlexNet的结构其实和LeNet非常类似。二者的区别在于:
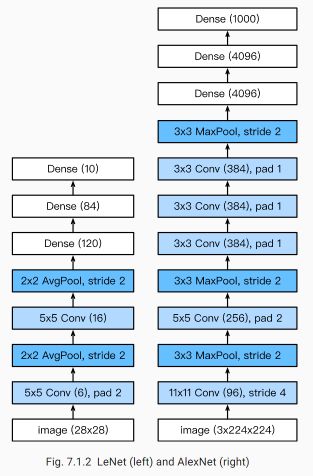
(1)层数:LeNet经过了5层变换,而AlexNet则有8层变换,其中有5层卷积层和2层全连接隐藏层,和1层全连接输出层。其对比如下图所示。
(2)LeNet使用的是sigmoid激活函数,而AlexNet使用的是ReLU激活函数。两个激活函数的区别在前面多层感知机的时候提到了,简单来说sigmoid函数训练模型更慢,也容易出现梯度消失。
(3)LeNet使用的是平均池化层,而AlexNet使用的是最大池化层,说明后者抓住的是最重要的特征,在模型的训练过程中会有参数稀疏的作用。
(4)AlexNet的通道数是LeNet通道数的数十倍,代表更多的特征。
(5)AlexNet用dropout来控制模型的复杂度,使得模型的泛化能力更强。
(6)最早的LeNet和AlexNet使用的数据集不同,前者使用的是MNIST,后者使用的是IMAGENET。
- MNIST
深度学习领域的“Hello World!”,入门必备!MNIST是一个手写数字数据库,它有60000个训练样本集和10000个测试样本集,每个样本图像的宽高为28*28。此数据集是以二进制存储的,不能直接以图像格式查看,不过很容易找到将其转换成图像格式的工具。
最早的深度卷积网络LeNet便是针对此数据集的,当前主流深度学习框架几乎无一例外将MNIST数据集的处理作为介绍及入门第一教程,其中Tensorflow关于MNIST的教程非常详细。数据集下载~12MB
2. ImageNet
ImageNet数据集有1400多万幅图片,涵盖2万多个类别。其中有超过百万的图片有明确的类别标注和图像中物体位置的标注,相关信息如下:
1)非空的同义词集总数:21841
2)图像总数:14,197,122
3)边界框注释的图像数:1,034,908
4)具有SIFT特征的同义词集数:1000
5)具有SIFT特征的图像数:120万
Imagenet数据集是目前深度学习图像领域应用得非常多的一个领域,关于图像分类、定位、检测等研究工作大多基于此数据集展开。Imagenet数据集文档详细,有专门的团队维护,使用非常方便,在计算机视觉领域研究论文中应用非常广,几乎成为了目前深度学习图像领域算法性能检验的“标准”数据集。
AlexNet的代码与LeNet的区别不大,只不过在中间网络的部分,即net()函数的书写要按照AlexNet的结构去写。
#目前GPU算力资源预计17日上线,在此之前本代码只能使用CPU运行。
#考虑到本代码中的模型过大,CPU训练较慢,
#我们还将代码上传了一份到 https://www.kaggle.com/boyuai/boyu-d2l-modernconvolutionalnetwork
#如希望提前使用gpu运行请至kaggle。
import time
import torch
from torch import nn, optim
import torchvision
import numpy as np
import sys
sys.path.append("/home/kesci/input/")
import d2lzh1981 as d2l
import os
import torch.nn.functional as F
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 96, 11, 4), # in_channels, out_channels, kernel_size, stride, padding
nn.ReLU(),
nn.MaxPool2d(3, 2), # kernel_size, stride
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(3, 2),
# 连续3个卷积层,且使用更小的卷积窗口。除了最后的卷积层外,进一步增大了输出通道数。
# 前两个卷积层后不使用池化层来减小输入的高和宽
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(3, 2)
)
# 这里全连接层的输出个数比LeNet中的大数倍。使用丢弃层来缓解过拟合
self.fc = nn.Sequential(
nn.Linear(256*5*5, 4096),
nn.ReLU(),
nn.Dropout(0.5),
#由于使用CPU镜像,精简网络,若为GPU镜像可添加该层
#nn.Linear(4096, 4096),
#nn.ReLU(),
#nn.Dropout(0.5),
# 输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10),
)
# 这一步的目的是将batch_size*channels*height*width转化为batch_size*hiddens然后传入全连接层
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output
在执行的过程中,可以验证自己是否写错了:
net = AlexNet()
print(net)
2.3 VGG-16
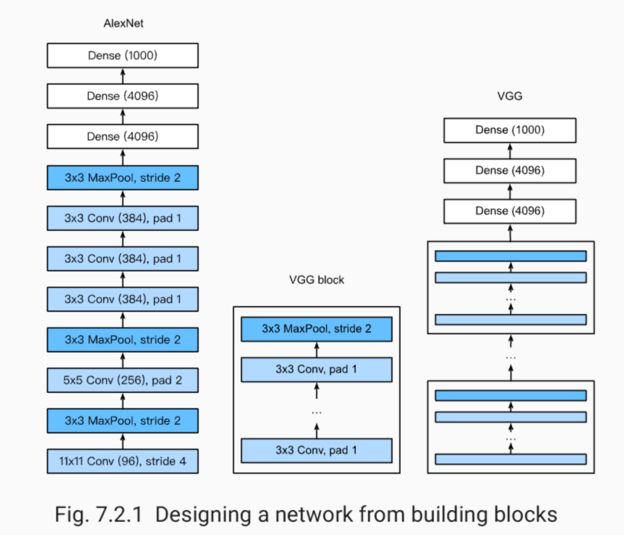
VGG最大的特点是可以通过重复使用简单的基础块来构建深层模型。因此参数较多。
每个VGG块的结构为多个卷积层加上一个池化层。
2.4 NiN
(1)前面将的三种网络,其结构基本上都是类似的,大致都是由卷积层和全连接层两个大块组成。而NiN(网络中的网络)则是串联了多个由卷积层和“全连接层”构成的小网络来构建深层网络的。
为什么这里打引号呢?
因为我们知道卷积层的输出应该是:样本数通道数高宽,而全连接层的输入则应该是:样本数神经元个数,二者的转换需要有一个展平的操作,不但不方便且影响了这个结构,因此这里使用了一个1x1的卷积层来代替全连接层,不需要进行展平操作了。
(2)前三者通过全连接层来调整输出,使得输出等于类别数,而NiN则是通过调整通道数来控制输出的类别数。
(3)补充知识点:的卷积核的作用
- a. 代替全连接层
- b. 通过控制卷积核数量来达到通道数的放缩。
- c. 增加非线性
- d. 卷积层和全连接层相比,计算参数少

2.5 GoogleNet
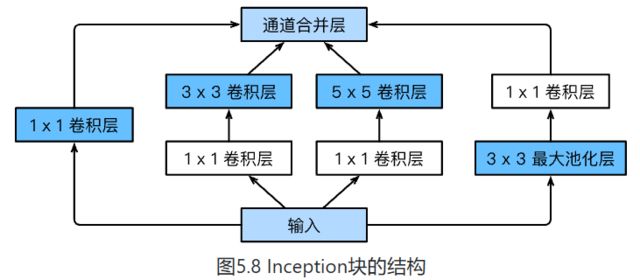
GoogleNet吸收了NiN串联网络的思想
-
- 由Inception基础块组成
-
- 每个基础块都有4条线路并行
-
-
可以自定义的超参数是每一层的输出 通道数,用于控制模型的复杂度。
 GoogleNet
GoogleNet
-
class Inception(nn.Module):
# c1 - c4为每条线路里的层的输出通道数
def __init__(self, in_c, c1, c2, c3, c4):
super(Inception, self).__init__()
# 线路1,单1 x 1卷积层
self.p1_1 = nn.Conv2d(in_c, c1, kernel_size=1)
# 线路2,1 x 1卷积层后接3 x 3卷积层
self.p2_1 = nn.Conv2d(in_c, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1 x 1卷积层后接5 x 5卷积层
self.p3_1 = nn.Conv2d(in_c, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3 x 3最大池化层后接1 x 1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_c, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
return torch.cat((p1, p2, p3, p4), dim=1) # 在通道维上连结输出