通过十个问题助你彻底理解linux epoll工作原理
linux服务器开发相关视频解析:
支撑亿级io的底层基石 epoll实战揭秘
基于linux epoll原理剖析以及三握四挥的细节处理
c/c++ linux服务器开发学习地址:c/c++ linux后台服务器高级架构师
epoll 是 linux 特有的一个 I/O 事件通知机制。很久以来对 epoll 如何能够高效处理数以百万记的文件描述符很有兴趣。近期学习、研究了 epoll 源码,在这个过程中关于 epoll 数据结构和作者的实现思路产生出不少疑惑,在此总结为了 10 个问题并逐个加以解答和分析。
Question 1:是否所有的文件类型都可以被 epoll 监视?
答案:不是。看下面这个实验代码:
#include 编译、运行上面的代码,会打印出下列信息:
gcc epoll_test.c -o epdemo
./epdemo
target_fd 4
ret -1, errno 1
epoll_ctl: Operation not permitted
正常打开了"txt"文件 fd=4, 但调用 epoll_ctl 监视这个 fd 时却 ret=-1 失败了, 并且错误码为 1,错误信息为"Operation not permitted"。错误码指明这个 fd 不能够被 epoll 监视。
那什么样的 fd 才可以被 epoll 监视呢?
只有底层驱动实现了 file_operations 中 poll 函数的文件类型才可以被 epoll 监视!socket 类型的文件驱动是实现了 poll 函数的,因此才可以被 epoll 监视。struct file_operations 声明位置是在 include/linux/fs.h 中。
Question 2:ep->wq 的作用是什么?
答案:wq 是一个等待队列,用来保存对某一个 epoll 实例调用 epoll_wait()的所有进程。
一个进程调用 epoll_wait()后,如果当前还没有任何事件发生,需要让当前进程挂起等待(放到 ep->wq 里);当 epoll 实例监视的文件上有事件发生后,需要唤醒 ep->wq 上的进程去继续执行用户态的业务逻辑。之所以要用一个等待队列来维护关注这个 epoll 的进程,是因为有时候调用 epoll_wait()的不只一个进程,当多个进程都在关注同一个 epoll 实例时,休眠的进程们通过这个等待队列就可以逐个被唤醒了。
多个进程关注同一个 epoll 实例,那么有事件发生后先唤醒谁?后唤醒谁?还是一起全唤醒?这涉及到一个称为“惊群效应”的问题。
Question 3:什么是 epoll 惊群?
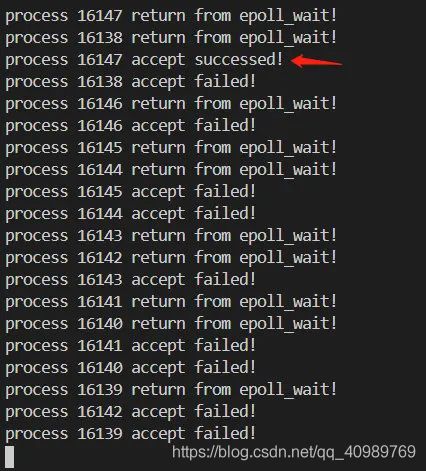
答案:多个进程等待在 ep->wq 上,事件触发后所有进程都被唤醒,但只有其中 1 个进程能够成功继续执行的现象。其他被白白唤起的进程等于做了无用功,可能会造成系统负载过高的问题。下面这段代码能够直观感受什么是 epoll 惊群:
#include 将服务端的监听 socket fd 加入到 epoll_wait 的监视集合中,这样当有客户端想要建立连接,就会事件触发 epoll_wait 返回。此时如果 10 个进程同时在 epoll_wait 同一个 epoll 实例就出现了惊群效应。所有 10 个进程都被唤起,但只有一个能成功 accept。
为了解决 epoll 惊群,内核后续的高版本又提供了 EPOLLEXCLUSIVE 选项和 SO_REUSEPORT 选项,我个人理解两种解决方案思路上的不同点在于:EPOLLEXCLUSIVE 是在唤起进程阶段起作用,只唤起排在队列最前面的 1 个进程;而 SO_REUSEPORT 是在分配连接时起作用,相当于每个进程自己都有一个独立的 epoll 实例,内核来决策把连接分配给哪个 epoll。
【文章福利】需要C/C++ Linux服务器架构师学习资料加群812855908(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等)

Question 4:ep->poll_wait 的作用是什么?
答案:ep->poll_wait 是 epoll 实例中另一个等待队列。当被监视的文件是一个 epoll 类型时,需要用这个等待队列来处理递归唤醒。
在阅读内核代码过程中,ep->wq 还算挺好理解,但我发现伴随着 ep->wq 唤醒, 还有一个 ep->poll_wait 的唤醒过程。比如下面这段代码,在 eventpoll.c 中出现了很多次:
/* If the file is already "ready" we drop it inside the ready list */
if ((revents & event->events) && !ep_is_linked(&epi->rdllink)) {
list_add_tail(&epi->rdllink, &ep->rdllist);
/* Notify waiting tasks that events are available */
if (waitqueue_active(&ep->wq))
wake_up_locked(&ep->wq);
if (waitqueue_active(&ep->poll_wait))
pwake++;
}
spin_unlock_irqrestore(&ep->lock, flags);
atomic_long_inc(&ep->user->epoll_watches);
/* We have to call this outside the lock */
if (pwake)
ep_poll_safewake(&ep->poll_wait);
查阅很多资料后才搞明白其实 epoll 也是一种文件类型,其底层驱动也实现了 file_operations 中的 poll 函数,因此一个 epoll 类型的 fd 可以被其他 epoll 实例监视。而 epoll 类型的 fd 只会有“读就绪”的事件。当 epoll 所监视的非 epoll 类型文件有“读就绪”事件时,当前 epoll 也会进入“读就绪”状态。
因此如果一个 epoll 实例监视了另一个 epoll 就会出现递归。举个例子,如图所示:
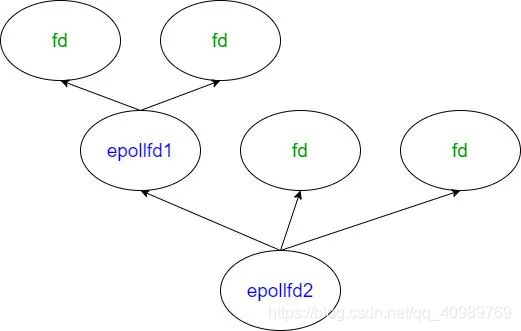
- epollfd1 监视了 2 个“非 epoll”类型的 fd
- epollfd2 监视了 epollfd1 和 2 个“非 epoll”类型的 fd
如果 epollfd1 所监视的 2 个 fd 中有可读事件触发,fd 的 ep_poll_callback 回调函数会触发将 fd 放到 epollfd1 的 rdllist 中。此时 epollfd1 本身的可读事件也会触发,就需要从 epollfd1 的 poll_wait 等待队列中找到 epollfd2,调用 epollfd1 的 ep_poll_callback(将 epollfd1 放到 epollfd2 的 rdllist 中)。因此 ep->poll_wait 是用来处理 epoll 间嵌套监视的情况的。
Question 5:ep->rdllist 的作用是什么?
答案:epoll 实例中包含就绪事件的 fd 组成的链表。
通过扫描 ep->rdllist 链表,内核可以轻松获取当前有事件触发的 fd。而不是像 select()/poll() 那样全量扫描所有被监视的 fd,再从中找出有事件就绪的。因此可以说这一点决定了 epoll 的性能是远高于 select/poll 的。
看到这里你可能又产生了一个小小的疑问:为什么 epoll 中事件就绪的 fd 会“主动”跑到 rdllist 中去,而不用全量扫描就能找到它们呢? 这是因为每当调用 epoll_ctl 新增一个被监视的 fd 时,都会注册一下这个 fd 的回调函数 ep_poll_callback, 当网卡收到数据包会触发一个中断,中断处理函数再回调 ep_poll_callback 将这个 fd 所属的“epitem”添加至 epoll 实例中的 rdllist 中。
Question 6:ep->ovflist 的作用是什么?
答案:在 rdllist 被占用时,用来在不持有 ep->lock 的情况下收集有就绪事件的 fd。
当 epoll 上已经有了一些就绪事件的时候,内核需要扫描 rdllist 将就绪的 fd 返回给用户态。这一步通过 ep_scan_ready_list 函数来实现。其中 sproc 是一个回调函数(也就是 ep_send_events_proc 函数),来处理数据从内核态到用户态的复制。
/**
* ep_scan_ready_list - Scans the ready list in a way that makes possible for the scan code, to call f_op->poll(). Also allows for O(NumReady) performance.
* @ep: Pointer to the epoll private data structure.
* @sproc: Pointer to the scan callback.
* @priv: Private opaque data passed to the @sproc callback.
* Returns: The same integer error code returned by the @sproc callback.
*/
static int ep_scan_ready_list(struct eventpoll *ep,
int (*sproc)(struct eventpoll *,
struct list_head *, void *),
void *priv)
由于 rdllist 链表业务非常繁忙(epoll 增加监视文件、修改监视文件、有事件触发…等情况都需要操作 rdllist),所以在复制数据到用户空间时,加了一个 ep->mtx 互斥锁来保护 epoll 自身数据结构线程安全,此时其他执行流程里有争抢 ep->mtx 的操作都会因命中 ep->mtx 进入休眠。
但加锁期间很可能有新事件源源不断地产生,进而调用 ep_poll_callback(ep_poll_callback 不用争抢 ep->mtx 所以不会休眠),新触发的事件需要一个地方来收集,不然就丢事件了。这个用来临时收集新事件的链表就是 ovflist。我的理解是:引入 ovflist 后新产生的事件就不用因为想向 rdllist 里写而去和 ep_send_events_proc 争抢自旋锁(ep->lock), 同时 ep_send_events_proc 也可以放心大胆地在无锁(不持有 ep->lock)的情况下修改 rdllist。
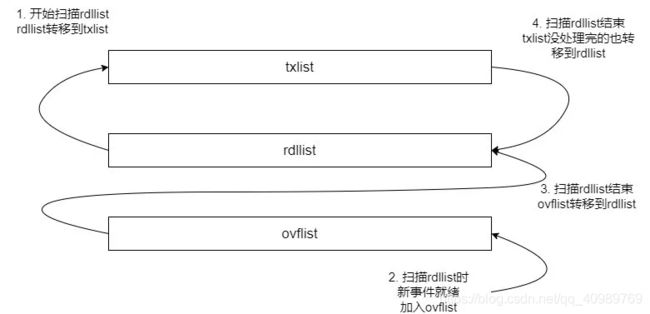
看代码时会发现,还有一个 txlist 链表,这个链表用来最后向用户态复制数据,rdllist 要先把自己的数据全部转移到 txlist,然后 rdllist 自己被清空。ep_send_events_proc 遍历 txlist 处理向用户空间复制,复制成功后如果是水平触发(LT)还要把这个事件还回 rdllist,等待下一次 epoll_wait 来获取它。
ovflist 上的 fd 会合入 rdllist 上等待下一次扫描;如果 txlist 上的 fd 没有处理完,最后也会合入 rdllist。这 3 个链表的关系是这样:
Question 7:epitem->pwqlist 队列的作用是什么?
答案:用来保存这个 epitem 的 poll 等待队列。
首先介绍下什么是 epitem。epitem 是 epoll 中很重要的一种数据结构, 是红黑树和 rdllist 的基本组成元素。需要监听的文件和事件信息,都被包装在 epitem 结构里。
struct epitem {
struct rb_node rbn; // 用于加入红黑树
struct list_head rdllink; // 用于加入rdllist
struct epoll_filefd ffd; // 包含被监视文件的文件指针和fd信息
struct list_head pwqlist; // poll等待队列
struct eventpoll *ep; // 所属的epoll实例
struct epoll_event event; // 关注的事件
/* 其他成员省略 */
};
回忆一下上文说到,每当用户调用 epoll_ctl()新增一个监视文件,都要给这个文件注册一个回调函数 ep_poll_callback, 当网卡收到数据后软中断会调用这个 ep_poll_callback 把这个 epitem 加入到 ep->rdllist 中。
pwdlist 就是跟 ep_poll_callback 注册相关的。
当调用 epoll_ctl()新增一个监视文件后,内核会为这个 epitem 创建一个 eppoll_entry 对象,通过 eppoll_entry->wait_queue_t->wait_queue_func_t 来设置 ep_poll_callback。pwdlist 为什么要做成一个队列呢,直接设置成 eppoll_entry 对象不就行了吗?实际上不同文件类型实现 file_operations->poll 用到等待队列数量可能不同。虽然大多数都是 1 个,但也有例外。比如“scullpipe”类型的文件就用到了 2 个等待队列。
pwqlist、epitem、fd、epoll_entry、ep_poll_callback 间的关系是这样:
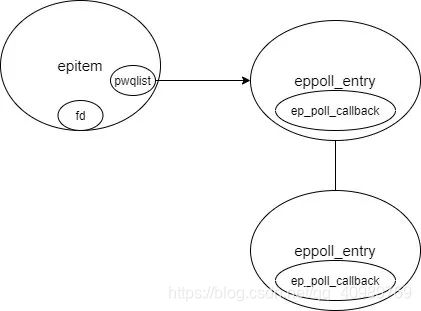
Question 8:epmutex、ep->mtx、ep->lock 3 把锁的区别是?
答案:锁的粒度和使用目的不同。
- epmutex 是一个全局互斥锁,epoll 中一共只有 3 个地方用到这把锁。分别是 ep_free() 销毁一个 epoll实例时、eventpoll_release_file() 清理从 epoll 中已经关闭的文件时、epoll_ctl() 时避免epoll 间嵌套调用时形成死锁。我的理解是 epmutex 的锁粒度最大,用来处理跨 epoll 实例级别的同步操作。
- ep->mtx 是一个 epoll 内部的互斥锁,在 ep_scan_ready_list()扫描就绪列表、eventpoll_release_file() 中执行ep_remove()删除一个被监视文件、ep_loop_check_proc()检查 epoll 是否有循环嵌套或过深嵌套、还有epoll_ctl() 操作被监视文件增删改等处有使用。可以看出上述的函数里都会涉及对 epoll 实例中 rdllist或红黑树的访问,因此我的理解是 ep->mtx 是一个 epoll 实例内的互斥锁,用来保护 epoll 实例内部的数据结构的线程安全。
- ep->lock 是一个 epoll 实例内部的自旋锁,用来保护 ep->rdllist的线程安全。自旋锁的特点是得不到锁时不会引起进程休眠,所以在 ep_poll_callback 中只能使用ep->lock,否则就会丢事件。
Question 9:epoll 使用红黑树的目的是什么?
答案:用来维护一个 epoll 实例中所有的 epitem。
用户态调用 epoll_ctl()来操作 epoll 的监视文件时,需要增、删、改、查等动作有着比较高的效率。尤其是当 epoll 监视的文件数量达到百万级的时候,选用不同的数据结构带来的效率差异可能非常大。

从时间(增、删、改、查、按序遍历)、空间(存储空间大小、扩展性)等方面考量,红黑树都是非常优秀的数据结构(当然这以红黑树比较高的实现复杂度作为代价)。epoll 红黑树中的 epitem 是按什么顺序组织的。阅读代码可以发现是先比较 2 个文件指针的地址大小,如果相同再比较文件 fd 的大小。
/* Compare RB tree keys */
static inline int ep_cmp_ffd(struct epoll_filefd *p1, struct epoll_filefd *p2)
{
return (p1->file > p2->file ? +1 : (p1->file < p2->file ? -1 : p1->fd - p2->fd));
}
epoll、epitem、和红黑树间的组织关系是这样:
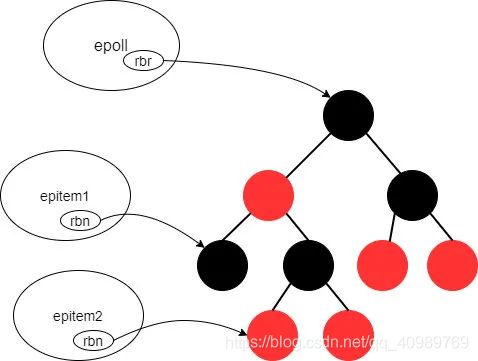
Question 10:什么是水平触发、边缘触发?
答案:水平触发(LT)和边缘触发(ET)是 epoll_wait 的 2 种工作模式。水平触发:关注点是数据(读操作缓冲区不为空,写操作缓冲区不为满),epoll_wait 总会返回就绪。LT 是 epoll 的默认工作模式。
边缘触发:关注点是变化,只有监视的文件上有数据变化发生(读操作关注有数据写进缓冲区,写操作关注数据从缓冲区取走),epoll_wait 才会返回。
看一个实验 ,直观感受下 2 种模式的区别, 客户端都是输入“abcdefgh” 8 个字符,服务端每次接收 2 个字符。
水平触发时,客户端输入 8 个字符触发了一次读就绪事件,由于被监视文件上还有数据可读故一直返回读就绪,服务端 4 次循环每次都能取到 2 个字符,直到 8 个字符全部读完。
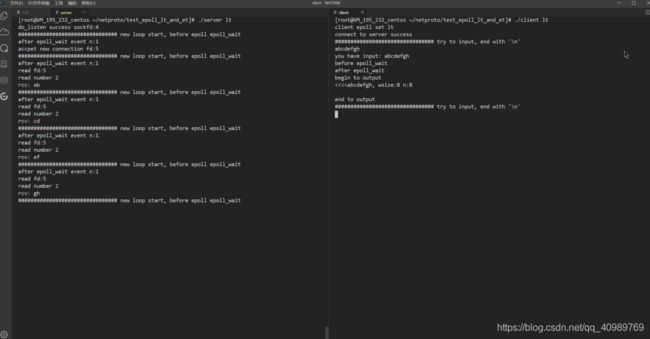
边缘触发时,客户端同样输入 8 个字符但服务端一次循环读到 2 个字符后这个读就绪事件就没有了。等客户端再输入一个字符串后,服务端关注到了数据的“变化”继续从缓冲区读接下来的 2 个字符“c”和”d”。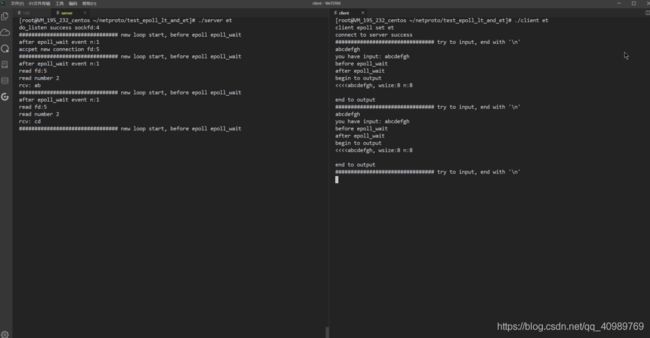
小结
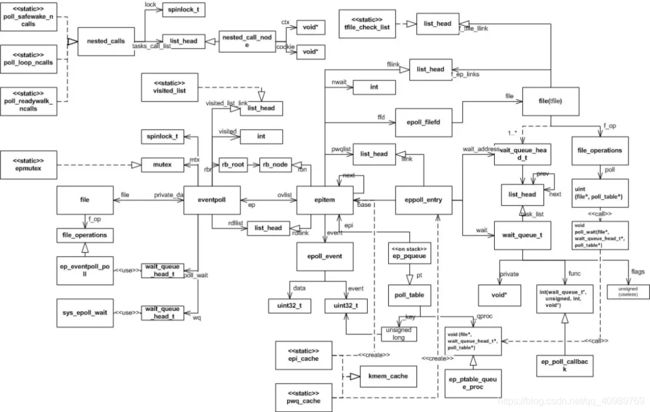
本文通过 10 个问题,其实也是从 10 个不同的视角去观察 epoll 这间宏伟的殿堂。至此也基本介绍完了 epoll 从监视事件,到内部数据结构组织、事件处理,最后到 epoll_wait 返回的整体工作过程。最后附上一张 epoll 相关数据结构间的关系图,在学习 epoll 过程中它曾解答了我心中不少的疑惑,我愿称之为灯塔~