我的第一个python程序是在杜老师和曹老师的帮助下完成的。杜老师是这个问题的主要指导,曹老师主要是指导程序书写的可读性、规范性、鲁棒性。下面我就来说说我完成第一个python程序都经历了什么。
1.初始阶段
杜老师在2019.1.17那天下午给了我一份test.txt文件,程序的任务是:解析出该文本中的公司代码和段落内容,然后以表头“公司代码”,“正文”来存储到excel表格中。test.txt文件如下图

test.PNG
拿到题目的时候,我很蒙,花了好长时间才搜索到关于文本解析和存储的代码,如下所示:
#!/usr/bin/env python3
#-*-coding:utf-8-*-
import xlwt
'''
import sys
if sys.getdefaultencoding() != 'ascii':
reload(sys)
sys.setdefaultencoding('ascii')
'''
'''
获取文件信息
'''
fi = open(r"E:\Desktop\test1.txt")
lines = fi.readlines()
#lines = fi.readline()
#lines=fi.read()
print lines
# 读取身高大于170cm
data = []
for human in lines:
hinfo = human.split()
if hinfo:
if int(hinfo[1][:3]) >= 170:
data.append(tuple(hinfo))
print data
'''
写入excel
'''
# 创建workbook和sheet对象
workbook = xlwt.Workbook(encoding='utf-8') # Workbook的开头W 大写
sheet1 = workbook.add_sheet('sheet1')
# 向sheet页中写入数据
sheet1.write(0, 0, '姓名')
sheet1.write(0, 1, '身高cm')
row = 1
for i in data:
sheet1.write(row, 0, i[0]) # i0 姓名
sheet1.write(row, 1, i[1]) # i1 身高
row += 1
workbook.save('c.xls') # 写入excel
但该代码执行时一直出现如下错误,如下图:
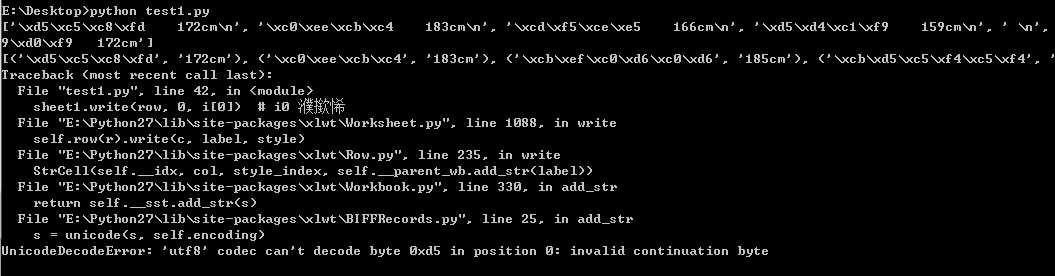
错误.png
图中显示的是代码的字符编码问题。通过网上搜索答案,对代码进行修改,修改部分如下图所示:
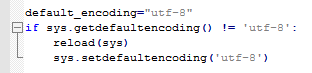
字符错误问题解决代码.PNG

字符转换问题解决.PNG
得到第一份可执行的代码,程序如下所示:
#!/usr/bin/env python
#-*-coding:utf-8-*-
import xlwt
import sys
default_encoding="utf-8"
if sys.getdefaultencoding() != 'utf-8':
reload(sys)
sys.setdefaultencoding('utf-8')
'''
获取文件信息
'''
fi = open(r"E:\Desktop\py_practice\test1\test.txt")
lines = fi.readlines()
#print len(lines)
data = []
for human in lines:
hinfo = human.split()#对human进行切片
#print type(hinfo)#hinfo是list类型
data.append(tuple(hinfo))
'''
写入excel
'''
# 创建workbook和sheet对象
workbook = xlwt.Workbook(encoding='utf-8') # Workbook的开头W 大写
sheet1 = workbook.add_sheet('sheet1')
# 向sheet页中写入数据
sheet1.write(0, 0, '公司代码')
sheet1.write(0, 1, '正文')
row = 1
for i in data:
sheet1.write(row, 0, i[0]) # i0 姓名
sheet1.write(row, 1, i[1].decode()) # i1 身高
row += 1
workbook.save('c.xls') # 写入excel
2.代码优化阶段
初始阶段的程序完全是冲着解题的思路写的,代码整体性较差,可重用性亦不足,总而言之就是可读性差。在曹老师的指导下,我修改了程序的格式和几处增加可读性的代码,修改过的代码如下所示:
#usr/bin/env python
#-*-coding:utf-8-*-
import chardet
import codecs
import xlwt
def encoding_type(pathway):
with open(pathway,'r') as f:
data=f.read()
return chardet.detect(data)['encoding']
def data_input(pathway,encode_name):
with codecs.open(pathway,'r',encode_name) as f:
lines=f.readlines()
data=[]
for num in lines:
record=num.split()
data.append(tuple(record))
return data
def data_into_excel(data):
workbook = xlwt.Workbook(encoding='utf-8')#建立一个excel工作簿
sheet1 = workbook.add_sheet('公司代码与名称')#建立一个excel工作表
sheet1.write(0, 0, '公司代码')
sheet1.write(0, 1, '正文')
row = 1
for i in data:
sheet1.write(row, 0, i[0]) # i0 公司代码
sheet1.write(row, 1, i[1]) # i1 正文
row += 1
workbook.save(r'E:\Desktop\py_practice\test1\c.xls') #默认是在执行该文件的路径下
return
if __name__=='__main__':#两边是双下划线
path=r'E:\Desktop\py_practice\test1\test.txt'
encode_name=encoding_type(path)
data=data_input(path,encode_name)
data_into_excel(data)
该代码增加了层次感,在可读性上得到了很大的提高。但该程序存在一个问题,就是鲁棒性不足,因此进一步添加了错误警告部分,修改后的代码如下所示:
#usr/bin/env python
#-*-coding:utf-8-*-
import chardet
import codecs
import xlwt
import os
def encoding_type(pathway):
if os.path.exists(pathway):
with open(pathway, "rb") as k:
dd = chardet.detect(k.read())
print(dd['encoding'])
return dd['encoding']
else:
print(pathway+'不存在')
exit()
def data_input(pathway):
with codecs.open(pathway,'r',encoding=encoding_type(pathway)) as f:
lines=f.readlines()
data=[]
for num in lines:
record=num.split()
if len(record) != 0:
pass
else:
print('文件 '+pathway+'参数错误,自动跳过,请检查')
print(len(record))
continue
data.append(tuple(record))
return data
def data_into_excel(data):
workbook = xlwt.Workbook(encoding='utf-8')#建立一个excel工作簿
sheet1 = workbook.add_sheet('公司代码与名称')#建立一个excel工作表
sheet1.write(0, 0, '公司代码')
sheet1.write(0, 1, '正文')
row = 1
for i in data:
if len(i) != 0:
sheet1.write(row, 0, i[0]) # i0 公司代码
sheet1.write(row, 1, i[1]) # i1 正文
row += 1
else:
print('数据输入错误,请检查')
continue
workbook.save(r'E:\Desktop\py_practice\test1\c1.xls') #默认是在执行该文件的路径下
def main():
path = r'E:\Desktop\py_practice\test1\test.txt'
data=data_input(path)
data_into_excel(data)
if __name__=='__main__': #两边是双下划线
main()
至此,程序基本满足要求。
3.问题进阶
程序的任务是:解析出该文本中的公司代码和段落内容,然后以表头“公司代码”,“正文”来存储到excel表格中。要求进行正则表达式,问题内容在第一个问题基础上更改的,具体内容如下:

问题文档.PNG
初次调试成功的代码如下:
# usr/bin/env python
# -*-coding:utf-8-*-
import chardet
import codecs
import xlwt
import os
import re
def encoding_type(pathway):
if os.path.exists(pathway):
with open(pathway, "rb") as k:
dd = chardet.detect(k.read())
print(dd['encoding'])
return dd['encoding']
else:
print(pathway+'不存在')
exit()
def data_input(pathway):
with codecs.open(pathway,'r',encoding=encoding_type(pathway)) as f:
lines=f.readlines()
data=[]
for num in lines:
record=[]
record.append(re.findall(r'\"\d+\"', num))
num_tmp = re.sub("\d{6}", "", num) # 匹配6位数字,并用空字符串替换
record.append(re.findall(r'[\u4e00-\u9fa5\\sAA-Za-z0-9]+\D', num_tmp))
if len(record) != 0:
pass
else:
print('文件 '+pathway+'参数错误,自动跳过,请检查')
print(len(record))
continue
data.append(tuple(record))
return data
def data_into_excel(data):
workbook = xlwt.Workbook(encoding='utf-8')#建立一个excel工作簿
sheet1 = workbook.add_sheet('公司代码与名称')#建立一个excel工作表
sheet1.write(0, 0, '公司代码')
sheet1.write(0, 1, '正文')
row = 1
for i in data:
if len(i) != 0:
sheet1.write(row, 0, i[0]) # i0 公司代码
sheet1.write(row, 1, i[1]) # i1 正文
row += 1
else:
print('数据输入错误,请检查')
continue
workbook.save(r'E:\Desktop\py_practice\test2\c1.xls') #默认是在执行该文件的路径下
def main():
path = r'E:\Desktop\py_practice\test2\test.txt'
data=data_input(path)
data_into_excel(data)
if __name__=='__main__': #两边是双下划线
main()
解释一下关于正则表达式的三句话:

正则表达式.PNG
第一句:匹配序列中的连续数字
第二句 : 匹配6位数字,并用空字符串替换
第三句:匹配序列中的包括空格的汉字,字母,数字,以及匹配任意非数字
关于正则表达式的一些模式表达如下网址内容所示
https://www.cnblogs.com/dreamer-fish/p/5282679.html
正则表达式笔记:
匹配汉字
r'[\u4E00-\u9FA5\s]+' 匹配多个汉字,包括空格
r'[\u4E00-\u9FA5]+' 匹配多个汉字,不包括空格
r'[\u4E00-\u9FA5]' 匹配一个汉字
r'[\u4E00-\u9FA5AA-Za-z0-9]+' 匹配多个汉字+数字+字母