有道 Kubernetes 容器API监控系统设计和实践
有道 Kubernetes 容器API监控系统设计和实践
-
- 1.背景
- 2.技术选型
-
-
- 方案分析
-
- 3.整体设计思路
- 4.具体实践操作
-
- 4.1 添加service 级别API监控告警
- 4.2 自动生成pod API监控
- 5.难点和重点问题解决
-
- 5.1 误报消减
- 5.2策略优化
- 5.3易用性
- 5.4业务适配
- 6.上线效果
- 7.总结与展望
-
- 7.1总结
- 7.2展望
- 8.结语
本期文章,我们将给大家分享有道容器服务API监控方案,这个方案同时具有轻量级和灵活性的特点,很好地体现了k8s集群化管理的优势,解决了静态配置的监控不满足容器服务监控的需求。并做了易用性和误报消减、可视化面板等一系列优化,目前已经超过80%的容器服务已经接入了该监控系统。
来源/ 有道技术团队微信公众号
作者/ 郭超容 王伟静
编辑/ hjy
1.背景
Kubernetes 已经成为事实上的编排平台的领导者、下一代分布式架构的代表,其在自动化部署、监控、扩展性、以及管理容器化的应用中已经体现出独特的优势。
在k8s容器相关的监控上, 我们主要做了几块工作,分别是基于prometheus的node、pod、k8s资源对象监控,容器服务API监控以及基于grafana的业务流量等指标监控。
在物理机时代,我们做了分级的接口功能监控——域名级别接口监控和机器级别监控,以便在某个机器出现问题时,我们就能快速发现问题。
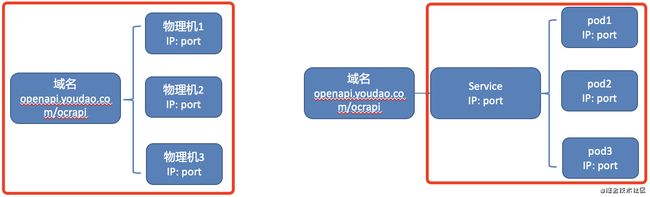
上图中,左边是物理机时代对应的功能监控,包括域名级别接口监控和3台物理机器监控。右边是对应的k8s环境,一个service的流量会由k8s负载均衡到pod1,pod2,pod3中,我们分别需要添加的是service和各个pod的监控。
由于K8s中的一切资源都是动态的,随着服务版本升级,生成的都是全新的pod,并且pod的ip和原来是不一样的。
综上所述,传统的物理机API不能满足容器服务的监控需求,并且物理机功能监控需要手动运维管理,为此我们期望设计一套适配容器的接口功能监控系统,并且能够高度自动化管理监控信息,实现pod API自动监控。
2.技术选型
为了满足以上需求,我们初期考虑了以下几个方案。
1. 手动维护各个service 和pod 监控到目前物理机使用的podmonitor开源监控系统。
2. 重新制定一个包含k8s目录树结构的系统,在这个系统里面看到的所有信息都是最新的, 在这个系统里面,可以做我们的目录树中指定服务的发布、功能监控、测试演练等。
3. 沿用podmonitor框架,支持动态获取k8s集群中最新的服务和pod信息,并更新到监控系统中。
方案分析
针对方案一,考虑我们服务上线的频率比较高,并且k8s设计思想便是可随时自动用新生成的pod(环境)顶替原来不好用的pod,手动维护pod监控效率太低,该方案不可行。
第二个方案应该是比较系统的解决办法,但需要的工作量会比较大,这种思路基本全自己开发,不能很好的利用已有的功能监控系统,迁移成本大。
于是我们选择了方案三,既能兼容我们物理机的接口功能监控方案,又能动态生成和维护pod监控。
3.整体设计思路
k8s监控包括以下几个部分:
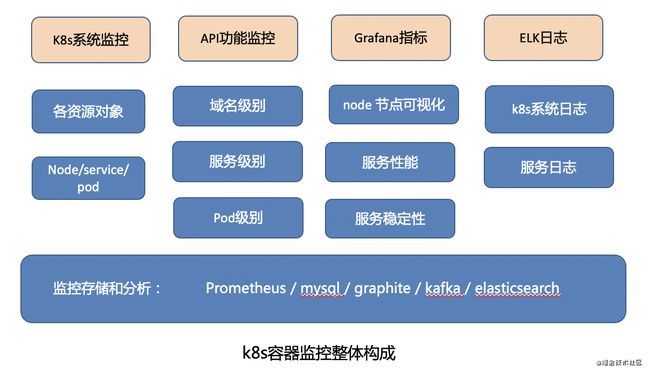
其中API功能监控,是我们保证业务功能正确性的重要监控手段。
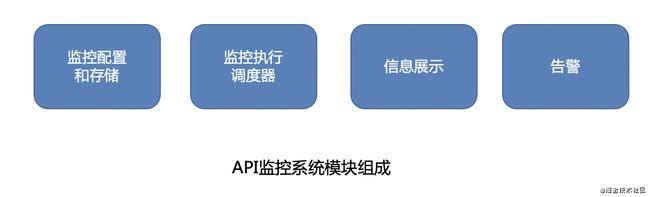
通常业务监控系统都会包含监控配置、数据存储、信息展示,告警这几个模块,我们的API功能监控系统也不例外。
我们沿用apimonitor框架功能,并结合了容器服务功能监控特点,和已有的告警体系,形成了我们容器API功能监控系统结构:
首先介绍下目前我们物理机使用的apimonitor监控:一个开源的框架
https://gitee.com/ecar_team/apimonitor
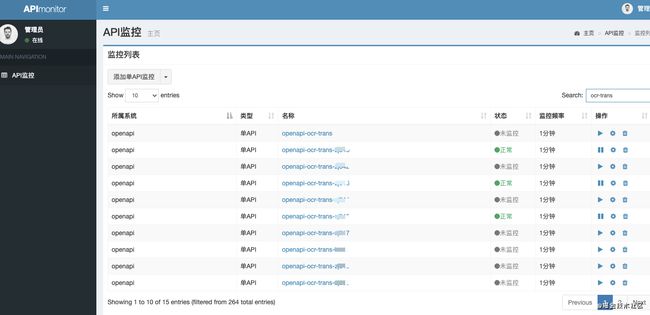
可以模拟探测http接口、http页面,通过请求耗时和响应结果来判断系统接口的可用性和正确性。支持单个API和多个API调用链的探测。
如下图所示,第一行监控里面监控的是图片翻译服务域名的地址,后边的是各台物理机的ip:端口。
点开每条监控
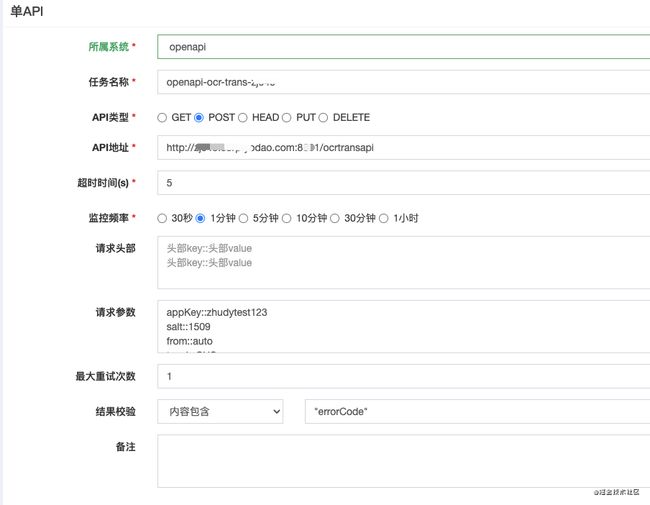
我们沿用apimonitor框架的大部分功能,其中主要的适配和优化包括:
1. 监控配置和存储部分:一是制定容器服务service级别监控命名规则:集群.项目.命名空间.服务;(和k8s集群目录树保持一致,方便根据service生成pod监控),二是根据service监控和k8s集群信息动态生成pod级别监控,
2. 监控执行调度器部分不用改动
3. 信息展示部分,增加了趋势图和错误汇总图表
4. 告警部分,和其它告警使用统一告警组。
4.具体实践操作
4.1 添加service 级别API监控告警
需要为待监控服务,配置一个固定的容service级别监控。
service级别监控命名规则:集群.项目.命名空间.服务
以词典查词服务为例,我们配置一条service级别的多API监控(也可以是单API监控)
· 单API:一个服务只需要加一条case用
· 多API:如果一个服务需要加多条功能case
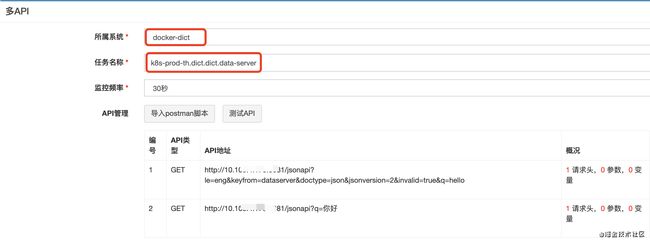
其中“所属系统” 是服务所属的告警组,支持电话、短信、popo群、邮件等告警方式(和其它监控告警通用)
任务名称:取名规则,rancher中k8s集群名字.项目名字.命名空间名字.service名字(一共四段)
告警消息的字段含义:
docker-dict:告警组,订阅后会收到告警消息
k8s-prod-th:集群
dict: 项目
dict:命名空间
data-server:workload名字
data-server-5b7d996f94-sfjwn:pod名字
{} :接口返回内容, 即:response.content
http://dockermonitor.xxx.youdao.com/monitorLog?guid=61bbe71eadf849558344ad57d843409c&name=k8s-prod-th.dict.dict.data-server.data-server-5b7d996f94-sfjwn : 告警详细链接
4.2 自动生成pod API监控
自动生成下面三行监控任务:(第一行监控是按上面方法配置的容器service ip监控,后边三行是自动生成pod监控任务 )

监控service级别是单API,则自动生成的是单API,service级别是多API,则自动生成的是多API监控。
自动生成的pod级别监控,除了最后两行标红处(ip: port)和service级别不一样,其他都一样。

实现pod自动生成的方法
1.给podmonitor(改框架是java语言编写的),增加一个java模块,用来同步k8s信息到podmonitor中。考虑到修改podmonitor中数据这个行为,本身是可以独立于框架的,可以不修改框架任何一行代码就能实现数据动态更新。
2.对比podmonitor数据库和k8s集群中的信息,不一致的数据,通过增删改查db,增加pod的监控。由于数据之间存在关联性,有些任务添加完没有例行运行,故采用了方法三。
3.对比podmonitor数据库和k8s集群中的信息,不一致的数据,通过调用podmonitor内部接口添加/删除一项监控,然后调接口enable /disable job等。按照可操作性难易, 我们选择了方法三
针对于k8s集群中查到的一条pod信息:总共有三种情况:
1.对于表中存在要插入pod的监控信息记录,并且enable状态为1。则认为该pod的监控不需要改变
2.对于表中存在要插入pod的监控信息记录(删除操作并不会删除源数据信息),并且enable状态为0。则认为该pod的监控已被删除或者被停止。调用删除操作, 清空QRTZ (例行任务插件)表中的响应内容, 调用delete db操作清出监控信息相关表中的内容(使得监控记录不至于一直在增长)
3.对于表中不存在pod相关信息记录, 则需要新增加的一个pod。调用post 创建监控任务接口(根据service 监控配置), 并调用get请求设置接口为监控enabled状态。
另外对于已经在物理机podmonitor中添加了监控的服务,提供了一个小脚本,用于导出物理机podmonitor域名级别监控到docker monitor监控中。
5.难点和重点问题解决
5.1 误报消减
5.1.1上线告警抑制
由于服务重启期间,会有removing状态和未ready状态的pod,在dockermonitor系统中存在记录,会引起误报。
我们的解决方法是提供一个通用脚本,根据k8s服务的存活检查时间,计算容器服务的发布更新时间,确定再自动开启服务监控的时机。实现在服务重启时间段,停止该服务的接口功能告警;存活检查时间过了之后,自动开启监控。
如下如所示,即Health Check中的Liveness Check检查时间。
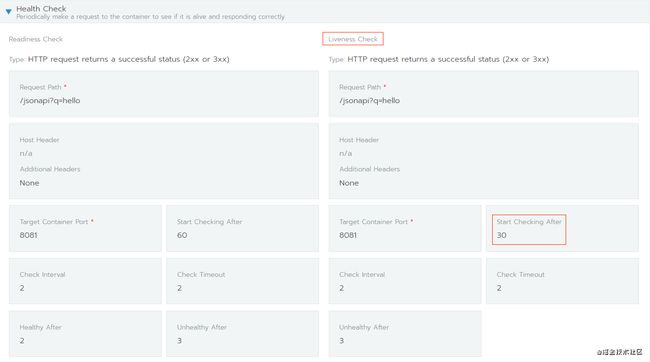
在我们上线发布平台上衔接了该告警抑制功能。
5.1.2弹性扩缩容告警抑制
原来我们通过查询rancher的 API接口得到集群中全量信息,在我们服务越来越多之后, 查询一次全量信息需要的时间越来越长,基本需要5min左右。在这个过程中,存在docker-monitor和k8s集群中的信息不一致的情况。一开始试图通过按照业务分组,并行调用rancher接口得到业务k8s集群信息。时间从5min缩短到1min多钟。误报有一定的减少, 但从高峰期到低谷期时间段, 仍然会有若干pod在k8s集群中缩掉了, 但docker-monitor中仍有相应的告警。
在调研了一些方案之后,我们通过k8s增量事件(如pod增加、删除)的机制,拿到集群中最新的信息,pod的任何变更,3s钟之内就能拿到。
通过es的查询接口,使用 filebeat-system索引的日志, 把pod带有关键字Releasing address using workloadID (更及时),或kube-system索引的日志: Deleted pod: xx delete 。
通过这个方案,已经基本没有误报。
5.2策略优化
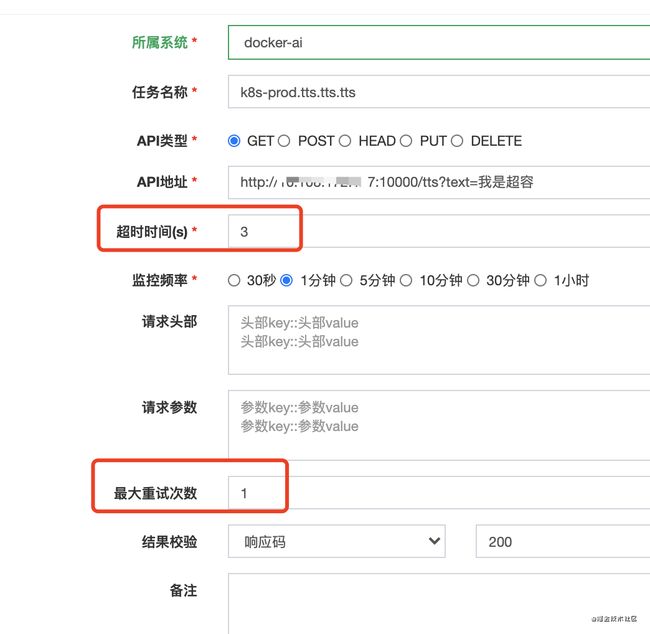
为了适配一些API允许一定的容错率,我们在apimonitor框架中增加了重试策略(单API和多API方式均增加该功能)
为了适配各类不同业务,允许设置自定义超时时间
5.3易用性
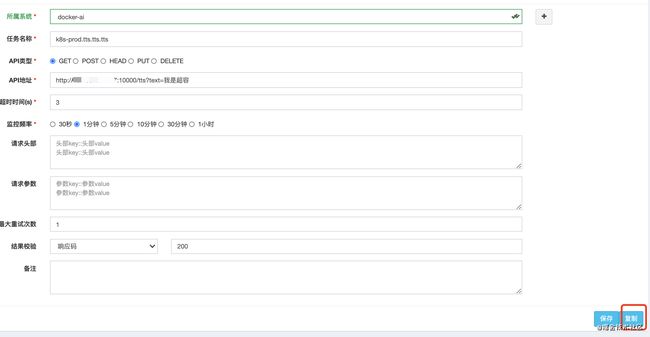
增加复制等功能,打开一个已有的告警配置,修改后点击复制, 则可创建一个新的告警项
使用场景: 在多套环境(预发、灰度和全量)监控,以及从一个相似API接口微调得到新API监控
5.4业务适配
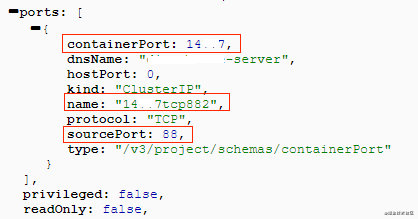
精品课对服务的容器化部署中使用了接口映射机制,使用自定义的监听端口来映射源端口,将service的监听端口作为服务的入口port供外部访问,如下图所示。当service的监听端口收到请求时,会将请求报文分发到pod的源端口,因此对pod级别的监控,需要找到pod的源端口。

我们分析了rancher提供的服务API文件后发现,在端口的配置信息中,port.containerPort为服务的监听端口,port.sourcePort为pod的监听端口,port.name包含port.containerPo
-rt和port.sourcePort的信息,由此找到了pod的源端口与service监听端口的关键联系,从而实现了对精品课服务接入本平台的支持。
6.上线效果
1.容器服务API监控统一,形成一定的规范,帮助快速发现和定位问题。
通过该容器API监控系统,拦截的典型线上问题有:
· xx上线误操作
· 依赖服务xxxlib版本库问题
· dns server解析问题
· xxx服务OOM问题
· xxx服务堆内存分配不足问题
· xx线上压测问题
· 多个业务服务日志写满磁盘问题
· 各类功能不可用问题
·…
2.同时增加了API延时趋势图标方便评估服务性能:
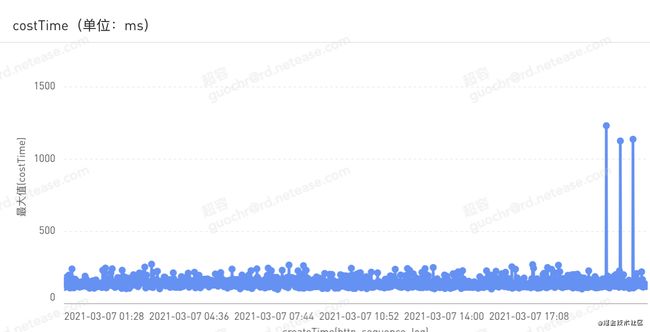
错误统计表方便排查问题:

结合我们k8s资源对象监控,和grafana的业务流量等指标监控,线上故障率显著减少,几个业务的容器服务0故障。
7.总结与展望
7.1总结
本期文章中我们介绍了基于静态API监控和K8s集群化管理方案,设计了实时的自动容器API监控系统。
通过上述方案,我们能够在业务迁移容器后,很快地从物理机监控迁移到容器监控。统一的监控系统,使得我们线上服务问题暴露更及时、故障率也明显减少
7.2展望
1.自动同步k8s服务健康检查到docker-monitor系统,保证每一个服务都有监控。
2.集成到容器监控大盘中,可以利用大盘中k8s资源目录树,更快查找指定服务,以及关联服务的grafana指标等监控。
3.自动恢复服务,比如在上线指定时间内,发生API监控告警,则自动回滚到上一版本,我们希望监控不仅能发现问题,还能解决问题。
监只是手段,控才是目标。
8.结语
Docker技术将部署过程代码化和持续集成,能保持跨环境的一致性,在应用开发运维的世界中具有极大的吸引力。
而k8s做了docker的集群化管理技术,它从诞生时就自带的平台属性,以及良好的架构设计,使得基于K8s容器可以构建起一整套可以解决上述问题的“云原生”技术体系,也降低了我们做持续集成测试、发布、监控、故障演练等统一规划和平台的难度。目前有道业务服务基本都上线到容器,后续我们将陆续迁移基础服务,实现整体的容器化。
我们也会不断积极拥抱开源,借鉴业界成功案例,寻找适合我们当前业务发展需要的理想选型。
-END-