本文主要用于介绍一种度量图片相似度的方法。本笔记主要为方便初学者快速入门,以及自我回顾。
论文链接:http://de.arxiv.org/pdf/1504.03641
基本目录如下:
- 摘要
- 核心思想
- 总结
------------------第一菇 - 摘要------------------
1.1 论文摘要
在本论文中,我们提出了直接从图像数据中学习到的一种比较图片相似度的方法(而不是借助一些人为构建的特征)。图片相似度的比较方法是在机器视觉领域中最基础的一个问题。为了构建这样一个方法,我们采用了一种基于CNN的模型,该模型是用各种形态各异的图片训练出来的。在最后,我们还探索了多种不同的网络架构,都十分适用于这种任务。实验表明,这种训练方法及网络架构能够极大的提升一些机器视觉领域的基础问题准确率。
------------------第二菇 - 核心思想------------------
2.1 核心思想
2.1.1 背景介绍
比较一组图片中某一块的相似度应该是在机器视觉领域最基础的任务了。但是实际上,这一任务却是一个极其复杂的问题,因为有太多太多的因素会影响到最终的比对效果。这些因素包括视角的改变啊,背景的光照源不同造成的阴影啊,遮挡等,还有照相机的设置不同等。事实上,过去一段时间,有很多研究图片相似度比对的方法,比如说“SIFT”点,就是一个十分关键的图像特征点。但是,这种人为构建特征的办法根本并不能应付各种复杂的情况。同时,在现今,我们有大量可以轻而易举获取的高质量的图片数据集合,能否利用好这些数据集,去自动学习出一种图片相似度的比较方法呢?
本文最大的目标就是提出一种训练方法来解决上述提到的问题。
2.1.2 基础模型架构
2.1.2.1 Siamese & Pseudo-Siamese
在介绍本文的模型结构之前,大家有必要先行了解一下在此之前更为出名的孪生神经网络架构,其中,根据是否共享同一网络层,又可分为孪生网络和伪孪生网络。具体架构图如下所示(右图),
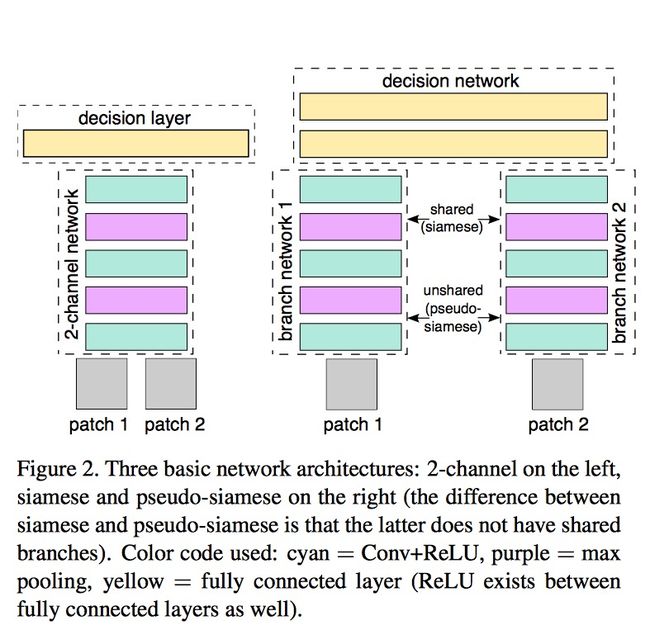
简单来说,就是将一组图片分别输入到网络架构之中,然后经过一系列的特征提取操作,生成这组图片(通常是2张的)的特征向量,再输入到最终的decision network(通常就是全连接层)。通常如果是同一类型的数据,我们都会共享网络权值;而如果是不同类型的数据(比如说,图片和文字的匹配,长文本和标题的匹配等),我们都会采用不同的网络架构来提取特征,但最终的判别网络还是一致的。
更多具体的介绍,可以看我的另一篇笔记
2.1.2.2 2-channel
本文提出了一种新的架构,不同于孪生网络是对单张图片分别提取特征,再在最后一层进行辨别,新的架构在一开始就将2张图片“合并”在了一起。
简单来讲,就是将单通道的两张灰度图,进行拼接,那输入的数据就变为了“2-channel”,直接输入到之后的卷积特征提取层。这样做的好处是,在一开始的特征提取阶段,网络就能够同时对两张图片的特征进行了处理,从而能够更好的对两张图片的相似度进行判别。而实验数据也表明,在一开始的阶段对两张图片就进行处理,最终得到的结果会更好~(ps.弱弱的说一句,虽然这样训练出的整套网络架构是一个更好但辨别器,但这样就无法训练出一个图片特征提取器了)
2.1.2.3 其他训练优化方法 - Deep Network
这其实算是网络架构设计的一个小技巧,即将非常大的卷积结构都替换成为更小的的卷积核,有兴趣的同学可以参考相关的论文(https://arxiv.org/abs/1409.1556)
2.1.2.4 其他训练优化方法 - Central-surround two-stream network
就跟这个名字暗示的一样,新提出的架构包含2个输入流,中心的和边缘的。
整体的架构如下图所示,
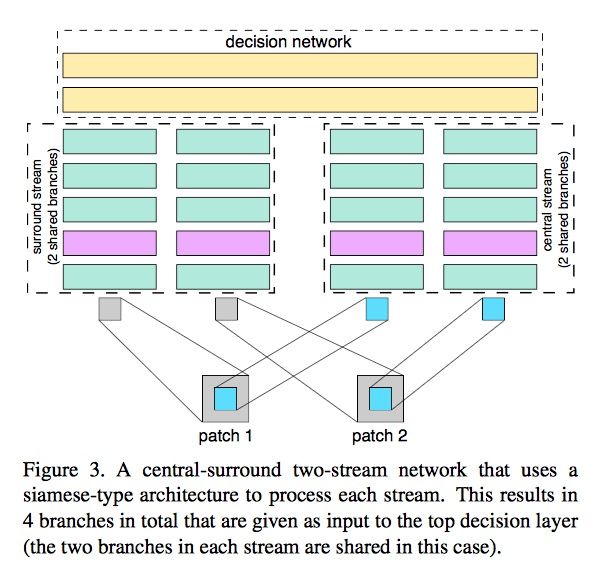
其中一个分支的输入为裁剪整张图片的中心区域(即假设输入是6464的,那就按最中心去裁剪出3232的),另一个分支的输入就是对图片的降采样,变为原来的一半(即假设输入是6464的,那就降采样为3232的)。整个特征提取的过程,就是由这两部分分别输入到同一网络架构中,最后进行拼接,再输入到最后的决策网络中~
之所以这样操作的原因是能够引入图片的多尺度特征(该项处理被证实在图片识别任务中是十分有效的),另外,之所以特地截取出图片的中心区域,也是考虑到图片的中心区域往往是更具有比较意义的,特征会更鲜明突出一点。
2.1.2.5 SPPNet池化层
SPPNet池化的处理其实本质上也是引入了多尺度的特征融合,这一层是加入到网络的决策层之前,对特征进行融合的。更多有关SPPNet的解释,可以参考我的另一篇论文笔记
2.1.3 损失函数设计
论文中采用的是hinge-based loss + L2 正则,应该说是比较好理解的。
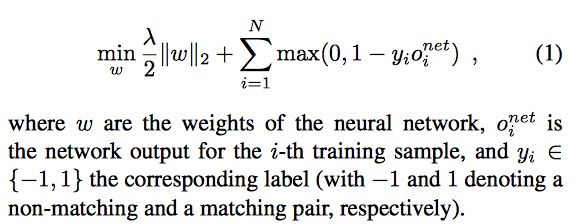
至此整套网络架构及几个比较好的优化点已经全部讲明白了。进一步的实验过程及结论就自行看论文吧。
------------------第三菇 - 总结------------------
3.1 总结
到这里,整篇论文的核心思想已经说清楚了。本论文主要是提出了一种新的用于衡量图片相似度的模型架构及一些训练方法的优化,并实验证明了其可行性,为后续发展奠定了基础。
简单总结一下本文就是先罗列了一下该论文的摘要,再具体介绍了一下本文作者的思路,也简单表述了一下,自己对整套网络架构及优化的理解。希望大家读完本文后能进一步加深对该论文的理解。有说的不对的地方也请大家指出,多多交流,大家一起进步~