一. 综述
深度学习比传统的逻辑回归有着更强的模型刻画能力,同时也带来了计算力百倍提升的需求。相比图像、语音、视频等领域,搜索、广告、推荐等场景有着独特的场景特点: 样本规模和特征空间通常非常巨大,千亿样本、百亿特征并不罕见,同时存在大量的稀疏特征作为Embedding输入。这就要求我们针对此场景下的计算特点对深度学习框架进行设计和优化。
本文所阐述的工作由阿里妈妈基础平台团队与PAI团队合作完成,我们基于TensorFlow在搜索、广告、推荐场景下进行了深度的优化与增强,内部项目名称为TensorFlowRS,主要的成果如下:
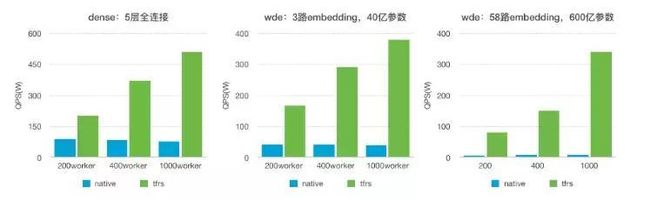
(1) 解决了原生TF水平扩展能力不足的问题。在我们的测试中,绝大多数搜索广告模型的训练性能提升在十倍以上,某些模型的极限性能最高可提升百倍。
(2) 支持完备的在线学习语义,模型变更实时写出;稀疏特征无需做连续ID化,可以直接使用原始特征表征进行训练,大幅简化了特征工程的复杂度。
(3) 异步训练的梯度修正优化器(grad-compensation optimizer),有效减少了异步大规模并发引起的训练效果损失。
(4) 集成了高效的Graph Embedding、Memory Network、Cross Media等多种高级训练模式。
(5) 模型可视化系统DeepInSight提供深度模型训练的多维度可视化分析。
二. TensorFlowRS分布式架构
在使用TensorFlow的过程中我们发现TF作为一个分布式训练系统有两个主要的问题:
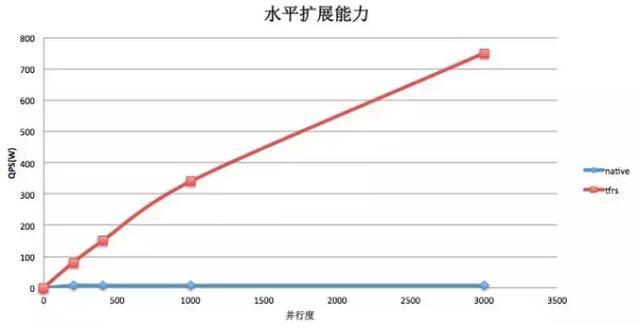
1. 水平扩展能力差:在大部分模型的性能测试中,我们发现随着数据并行度的增加,单个worker的样本处理QPS急剧下降。当worker数量增大到一定规模的时候,系统整体QPS不再有增长甚至有所下降。
2. 缺乏完备的分布式Failover机制:TF基于静态拓扑配置来构建cluster,不支持动态组网,这就意味着当某个ps或者worker挂掉重启之后,如果ip或者端口发生变化(例如机器crash),训练将无法继续。另外TF的checkpoint只包含server存储的参数信息,不包含worker端的状态,不是全局一致性的checkpoint,无法实现Exactly-Once等基本的Failover语义。
针对上述问题,TensorFlowRS采取的解决方案包括:
通过对接独立参数服务器提升水平扩展能力
在对TF做过细致的profiling之后,我们发现TF原生的PS由于设计和实现方面的多种原因(grpc,lock,graph-engine),很难达良好的水平扩展能力。于是我们决定丢掉TF-PS的包袱,重新实现一个高性能的参数服务器:PS-Plus。此外我们提供了完整的TF on PS-Plus方案,可以支持用户在Native-PS和PS-Plus之间自由切换,并且完全兼容TensorFlow的Graph语义和所有API。用户可以在深度网络代码一行不改的情况下,将参数分布和运行在PS-Plus上,享受高性能的参数交换和良好的水平扩展能力。
重新设计Failover机制,支持动态组网和Exactly-Once的Failover
TensorFlowRS引入了worker state,在checkpoint中存储了worker的状态信息,worker重启后,会从接着上次的进度继续训练。此外TensorFlowRS通过zk生成cluster配置,支持了动态组网的Failover。新的Failover机制可以保证任意角色挂掉的情况下,系统都能在分钟级完成Failover,并且不多算和漏算数据
TensorFlowRS的整体架构如图所示:

三. PS-Plus
PS-Plus相对于传统的ParameterServer有如下特点:
(1)高性能:PS-Plus通过智能参数分配,零拷贝,seastar等多项技术,进一步提升了单台server的服务能力和系统整体的水平扩展能力。在实测中,在64core的机器上单个server能轻松用满55+的核心,在dense场景下io能打满双25G网卡,系统整体在 1~4000 worker 的范围内都具有近似线性的水平扩展能力
(2)高度灵活:PS-Plus拥有完善的UDF接口,用户可使用SDK开发定制化的UDF插件,并且可以通过简单的C++以及Python接口进行调用。
(3)完备的在线学习支持:PS-Plus支持非ID化特征训练,特征动态增删,以及模型增量实时导出等支撑在线学习的重要特性。
下面从中选取几点做比较详细的介绍:
1. 智能参数分配
参数分配策略(variable placement),决定了如何将一个参数切分并放置到不同的server上。placement策略的好坏在高并发的情况下对PS的整体性能有着重大的影响。传统ParameterServer的placement方案是由系统预先实现几种常见的placement算法(比如平均切分+roundrobin),或者由用户在创建参数的时候手工划分,往往没有综合考虑全局的参数规模、Server的负载等。
PS-Plus实现了基于模拟退火算法的启发式参数分配策略,后续也在考虑实现基于运行时负载,动态rebalance的placement策略。PS-Plus的placement设计有如下优点:
综合考虑了全局参数的shape信息,在cpu,内存,网络带宽等限制条件下给出了近似最优的placement方案,避免了手工分配造成的不均匀、热点等问题。
整个参数分配过程由系统内部自动完成,用户无需配置即可获得接近最优的性能,用户无需了解PS底层实现的具体细节。
Partition由框架自动完成,在上层算法代码,如TF代码中,不需要额外使用PartitionedVariable等机制,使用简单方便。
2. 去ID化特征支持
目前主流的深度学习框架都是以连续的内存来存储训练参数,通过偏移量(ID值)来寻址到具体的权重。为了避免内存的浪费,需要对特征做从0开始的连续ID化编码,这一过程我们称之为特征ID化。特征ID化是一个非常复杂的过程,尤其是当样本和特征数量非常庞大的时候,特征ID化会占用大量的时间和机器资源,给样本构建带来了很大的复杂度。
PS-Plus内部实现了一个定制化的hashmap,针对参数交换场景做了专门的优化,在支持特征动态增删的同时提供了超高的性能。通过hashmap,PS-Plus直接实现了对非ID特征的支持,极大的简化了样本构建的复杂度。
3. 通信层优化
对于Parameter Server架构,延迟是影响整体性能的重要原因。尤其是在模型复杂度不高的情况下,模型计算部分往往在10~100ms量级,那么总体通信的延迟就成为一个关键因素。
在传统的pipeline线程模型,高并发情况下中断和线程上下文切换会导致很大的开销,同时会引起大量的cache-line miss。此外,高频的锁竞争是带来延迟的最主要原因之一,即便是各类SpinLock、读写锁等优化也并不能有效消除这个问题。我们认为polling + run to completion是一个正确的选择,并且设计了我们的整体通信层架构。在新的通信层中,我们使用了Seastar作为底层的框架。对于Server、Worker上的connection,都严格保证connection绑定到固定的线程,同时线程与CPU核心绑定。Request、response直接采用run to completion的方式在当前线程处理。整体架构如下图所示:

在Seastar的基础上,我们做了很多功能、性能的改进和优化,这里做一些简要的介绍。
外部线程交互队列。我们借鉴Seastar核心之间的交互机制,提供了一个 M:N 无锁生产者消费者队列,用于外部线程与Seastar内部线程进行交互。相比传统队列性能有极大的提升。
写请求顺序调度。从外部线程poll到的写请求,如果直接调用Seastar的写接口,会导致写buffer无法保证有序。我们通过队列机制的改造,自动保证了写顺序,同时基本不损失多connection的并发写的性能。
灵活的编解码层。我们提供了一套编解码层的抽象接口,方便用户使用,从而不需要借助protobuf等传统的序列化、反序列化的第三方库,同时也避免了protobuf的一些性能问题。
四.性能测试
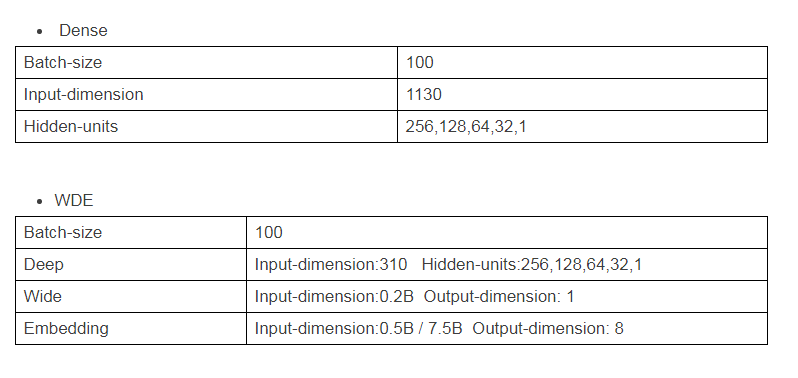
我们测试了TensorFlowRS在Dense以及WDE(Wide-Deep-Embedding)两种经典模型的性能指标:
1.模型说明:
2. 测试结果:
3. WDE模型下Native-TF与TFRS水平扩展能力比较
五. 在线学习
以Ftrl为代表,在线学习近年来在工业界开始被大规模应用,它是工程与算法的深入结合,赋予模型实时捕捉线上流量变化的能力,在一些对时效性要求很高的场景,有十分大的价值。
深度模型和LR模型一样,对在线学习有着同样强烈的需求,然而目前主流的深度学习框架都缺乏对在线学习的支持。TensorFlowRS通过对接PS-Plus,给出了一套完整的端到端的在线学习解决方案,赋予了TF支持千亿规模非ID化特征在线训练的能力。
TFRS针对在线学习的场景做了专门设计和优化,具体包括:
1. 非ID化特征支持
在在线学习的场景下做特征实时ID化是比较复杂的,需要一个超高性能的全局的ID生成器,这给样本生成带来了很大的复杂度。TensorFlowRS利用PS-Plus直接实现了对非ID特征的支持,极大的简化了实时样本构建的复杂度。
2. 特征动态增删
在在线训练的场景下,训练任务会以service的形式长期运行,在训练过程中,不断会有新特征加入到模型中,为了保证训练可以长期进行而不会因为新特征的不断加入导致OOM,PS-Plus在支持特征动态添加的同时,还提供了默认的特征删除策略,可以将低频或者低权重的特征删除掉,用户还可以通过UDF定制符合自身业务需求的删除策略
3. 模型增量实时导出
在线学习模型更新的常见方式有全量和增量两种。在模型参数较多的情况下,全量更新的方式会对在线系统的带宽带来巨大的压力,而降低更新频率又会使模型的实效性降低。PS-Plus支持以任意频率将模型增量部分实时写出到消息队列,在大幅减少网络IO的同时实现了真正意义上的模型实时更新。
4. AUC Decay
在在线学习的场景下,我们希望在训练的过程中就可以尽快的发现模型本身的异常,而不是等模型更新到线上之后。因此我们需要有一些方法来评估模型在训练过程中的 AUC等指标。TF里默认的streaming auc的实现在历史数据累积了一定量的时候,无法及时反应当前模型的状态,反馈有很大的滞后性。因此我们引入了新的AUC计算机制:AUC Decay。AUC Decay本质上是一种特殊的Moving Average,通过基于时间的减益方式,弱化历史样本和模型在当前AUC计算中的比重,以达到更快反应模型变化的目的
六. 大规模训练场景下的收敛效果优化
1. 问题阐述
大数据模型引入了分布式并行训练,同步并行训练受长尾worker的制约,并发数容易受限。异步并行是快速训练的主流。异步并行训练打破了普通SGD训练的串行性,计算的梯度与更新的模型不是严格一致,引入了梯度delay的问题。

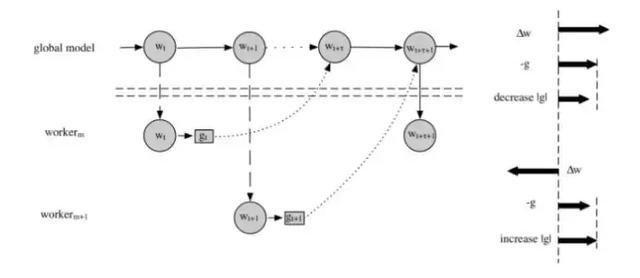
2. 梯度补偿

引入相关因子是依据如下分析前提的:
(1)异步训练时,存在隐式的梯度动量加速情况参见《Asynchrony begets Momentum, with an Application to Deep Learning》,并发越大,隐式动量越大,造成梯度往一个方向过度前进的情况。
(2)如果不是很老的w,相关因子是转折信号,暗示模型在多个worker的动量累积推动下前进的有些过度了。
(3)存在着tradeoff,太老的w,信号准确率会下降,这时要控制(调小)系数lambda。
因为
与g的相关性具备普适性,所以可以和主流的sgd-based optimizer结合,适应不同场景的不同优化器并发训练需求。
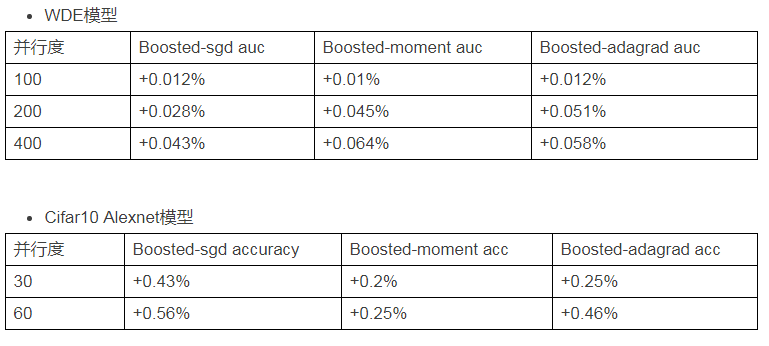
七. 实验结果
我们用相关性因子boost了SGD、Momentum、AdaGrad三种算法,并在生产环境和公开数据集上做了实验,实验结果如下
八.高级训练模式
TFRS中集成了多种高阶训练模式,例如Graph Embedding,Memory Network,Cross Media Training等。在本文我们会简要的介绍一下,在以后的文章中做详细的阐述。
Graph Embedding图是一种表征能力极强的数据结构,但是无法直接作为神经网络的输入。TFRS支持样本以图的形式进行输入,并支持多种随机游走算法动态生成正负样本。目前Graph Embedding已经应用在了搜索直通车的向量化召回等多个项目里,通过在User-Query-Item三种节点的异构有向图中随机游走,生成深度神经网络能够处理的稀疏特征。最终学习出User,Query和Item三者的高维向量化的表示,用于线上广告的向量化召回。值得一提的是,除了Graph Embedding,我们同样支持对图的结构进行学习,例如在训练过程中反馈调整图中的边的权重等。

Memory Network记忆网络最早由Facebook在2015年提出,用于QA系统中。在本模型出现之前,机器学习的模型都缺乏可以读取和写入外部知识的组件。对很多任务来说,这是一个很强的限制。比如,给定一系列事实或故事,然后要求回答关于该主题的问题,虽然原则上这可以用RNN等模型进行处理,然而它们的记忆(隐藏状态和权重编码)通常太小,并且不能精确地记住过去的事实。在阿里妈妈搜索广告场景下,我们使用记忆网络对用户行为进行建模。
相比一般的在样本组织阶段进行记忆体生成的方式,TFRS通过在训练过程中引入动态记忆存储模块,支持长短期记忆,大幅提高了序列化类行为数据的训练效率。
九. 可视化模型分析系统DeepInsight
DeepInsight是一个深度学习可视化质量评估系统,支持训练阶段模型内部数据的全面透出与可视化分析,用以解决模型评估、分析、调试等一系列问题,提高深度模型的可解释性。
下面我们通过一个过拟合的例子来说明DeepInsight在模型质量分析和问题定位方面发挥的作用:

上图是通过DeepInsight生成的特征权重分布,从图中我们可以看到右侧过拟合模型的边权重大小分布很不均匀,出现了大量权重极大的边,且集中在一条带状区域内,其为某一组特征输入所连接的所有边,这表明模型过度拟合了该组特征的信息。在使用正则项和dropout之后,过拟合的问题仍然没解决,因此我们最终定位到问题出现在该组特征的输入上。