一、评估规模:
部署前要理解应用的需求:
- 理解并发性、使用模式、入出的负载
- 服务级别协议
(SLAs):保证完全可以量化的(quantified)读和写延迟, 并能理解对偏差的容忍度 - Capacity:数据总量、每天入多少数据, 数据保存多少天
当以上问题搞清楚后,我们接下来就要考虑集群规模。我们需要自底向上的方法设计一个HBase集群,也就是说先考虑hardware ,然后是网络,然后是操作系统,然后是HDFS,最后是HBase。
硬件考虑
1、可分配16–24 GB的内存给heap(使用G1 GC算法的话可以分配到100GB堆内存)。如果heap的分配空间大于24G,则垃圾回收暂停是时间救护比较长(超过30s),这样RegionServers和Zookeeper直接就会差先超时问题,最终引发failures
2、当前, 为DataNodes节点分配64–128 GB内存就足以满足RegionServers、DataNodes和操作系统的需要,而且还能给block cache(有助于提升读操作效率)留足空间。
当然,在一个读的需求很大从而需要使用bucketcache的环境中,256G或者更多的RAM会更好。
3、对于CPU,一个HBase集群不会需要很多的核数,因此中等速率和少量的核数就足够了。2016年年初,标准的低端X86普通服务器配有2块8核心的处理器, 而2块12核(dodecacore)的处理器,时钟频率为2.5GHz。
如果你创建的是多租户集群 (一般是你计划使用MapReduce),最好使用大一点的核数 (数量取决与你的场景和组件使用情况)。多租户情况下会有些难度,尤其是HBase又有SLA要求,因此最好测试一下MapReduce jobs 和 HBase workload. 为保证SLAs,我们有时候需要同时有一个 batch cluster 和一个real-time cluster
存储
(JBOD(just a bunch of disks,简单磁盘捆绑,官方术语称作“Spanning”,它用来指还没有根据RAID(独立磁盘冗余阵列)系统配置以增加容错率和改进数据访问性能的电脑硬盘。)
当前,对于单纯的HBase集群来说(没有MR,没有Impala,没有Solr或者其他的应用),磁盘数量不是啥大问题,每个节点配置8–12块磁盘就已经很好了。
HBase采用了 write-ahead log (WAL) 去确认每一次写操作,在通过API, REST, 和 thrift interface去写的时候引发了slower ingest,于是在单个磁盘上会造成瓶颈。新的HBase计划增加对multi-WAL的支持,它可以通过把进来的write workload分担到每个节点的所有磁盘上来消除写瓶颈,这样更多的i磁盘就很有好处了。当我们期待一个永不过时的长期存在的HBase集群时,多购买25%–50%的存储会比较好。
只有当需要一个高SLAs时,才推荐使用SSD,毕竟SSD还是比较贵的
网络
HBase集群一般使用标准的Gigabit Ethernet (1 GbE) or 10 Gigabit Ethernet
(10 GbE) 。一般最小推荐的是使用1G,有2个或者4个端口。当要考虑未来软件和硬件的扩充,则考虑使用10GbE,当硬件失败或者发生major compaction时,10GbE就会非常有帮助
硬件失效后,HDFS会重复制(re-replicate)存于这个节点的所有数据;同时, 发生major compactions时, HFiles会被rewritten到管理这些data的RegionServer上从而形成本地化,这些都需要远程读,都会占用网络带宽
Once the cluster moves to multiple racks, top-ofrack (TOR) switches will need to be selected. TOR switches connect the nodes and bridge multiple racks. For a successful deployment, the TOR switches should be no slower than 10 GbE for inter-rack connections。Because it is important to eliminate single points of failure, redundancy between racks is highly recommended
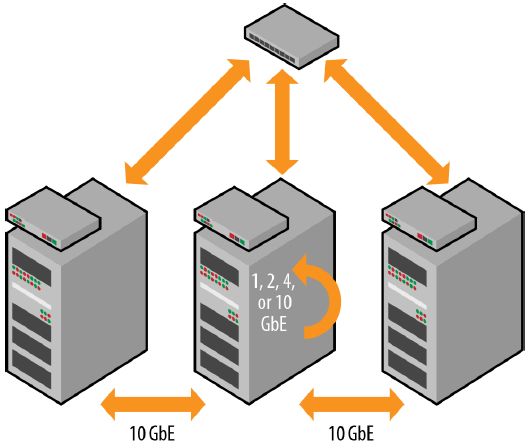
If the cluster gets so large that HBase begins to cross multiple aisles in the datacenter, core/aggregation switches may need to be introduced. These switches should not run any slower than 40 GbE, and again, redundancy is recommended. The cluster should be isolated on its own network and network equipment. Hadoop and HBase can quickly saturate a network, so separating the cluster on its own network can help ensure HBase does not impact any other systems in the datacenter. For ease of administration and security, VLANs may also be implemented on the network for the cluster.
OS调优
There is not a lot of special consideration for the operating system with Hadoop/HBase. The standard operating system for a Hadoop/HBase cluster is Linux based. For any real deployment, an enterprise-grade distribution should be used (e.g., RHEL, CentOS, Debian, Ubuntu, or SUSE). Hadoop writes its blocks directly to the operating system’s filesystem. With any of the newer operating system versions, it is recommended to use EXT4 for the local filesystem.
The next set of considerations for the operating system is swapping and swap space. It is important for HBase that swapping is not used by the kernel of the processes. Kernel and process swapping on an Hbase node can cause serious performance issues and lead to failures. It is recommended to disable swap space by setting the partition size to 0; process swapping should be disabled by setting vm.swappiness to 0 or 1.
Hadoop调优
Apache HBase 0.98+ 只支持 Hadoop2 with YARN (MR2),MapReduce workloads 会导致HBase发生资源饿死现象,所以请使用YARN而不是MR。Hadoop2 with YARN把资源管理工作移到YARN上去了。
所以调优HBase就需要调优YARN。YARN可以优化CPU使用个数及内存消耗情况。
一般要考虑3个因素:
- yarn.nodemanager.resource.cpu-vcores
给containers分派多少核CPU - yarn.nodemanager.resource.memory-mb
给containers分配多少megabytes物理内存。当使用HBase时,不要为节点过多分配内存。一般推荐- 为操作系统分配8–16 GB
- 为每个DataNode分配2–4 GB
- 为HBase分配12–24G
- 其余分配给YARN framework (假定没有其它的workloads,比如Impala或者Solr).
- yarn.scheduler.minimum-allocation-mb
每个容器向RM请求分配的最小内存(megabytes)内存请求如果小于这个值则不生效,推荐值为1–2 GB
目前大量的服务器都是使用Intel芯片组( chip set )并使能超线程(hyperthreading)(Hyper-threading允许操作系统为每个物理核呈现2个虚拟或者逻辑核),从经验上说,可以这样来计算:physicalCores * 1.5 = total v-cores(v-core是指虚拟核心)。在计算时候我们要为HBase留下一些空间:Total v-cores – 1 for HBase – 1 for DataNode – 1 for NodeManager – 1 for OS ...– 1 for any other services such as Impala or Solr。比如对于一个HBase和YARN集群,有一个双10核处理器,则性能调优应当如下:
20 * 1.5 = 30 virtual CPUs
30 – 1 – 1 – 1 – 1 = 26 total v-cores
有些资料推荐当使用基于YARN的HBase时,需要进一步把26 v-cores折半,我们最好实际测试一下看看哪个性能更好。
HBase调优
write-heavy workload
在实际应用仲,有两种方式可以往HBase里面写数据:要么通过 (Java, Thrift, or REST) ,要么通过bulk load, 这两者有个重要区别,API方式是会用到 WAL和memstore的,而bulk load则是一个short-circuit write,它不需要WAL和memstore,所以它更快(HBase的一个主要瓶颈是有WAL,且后面还跟 着memstore)。
在API驱动写模式下,有一个简便的公式可以决定性能优化:
- 每个Node应当有多少个region count:
HBaseHeap(即RegionServer内存) * memstoreUpperLimit(即分配给MemStore的比例) = availableMemstoreHeap * ColumnFamilyCounts(即列簇数目
availableMemstoreHeap / memstoreSize(即Memstore大小) = recommendedActiveRegionCount
(当一个 Region Server 中所有 MemStore 的大小总和达到了设定值(hbase.regionserver.global.memstore.upperLimit * hbase_heapsize,默认 0.4 * RS堆内存大小),会触发全部 MemStore flush。)
注意,尚未听说过一个每个RegionServer上部署有150-200个Region的成功案例
- 每个Node应当有多少raw space:
recommendedRegionCount * maxfileSize * replicationFactor = rawSpaceUsed - The number of WALs to keep:
availableMemstoreHeap / (WALSize * WALMultiplier) = numberOfWALs
(这里的WALMultiplier就是hbase.regionserver.logroll.multiplier,它是一个百分比,默认设定成0.95,意思是95%,如果WAL文件所占的空间大于或者等于95%的块大小,则这个WAL文件就会被归档)
真实的一个例子
HBase heap = 16 GB
Memstore upper limit = 0.5*
Memstore size = 128 MB
Maximum file size = 20 GB
WAL size = 128 MB
WAL rolling multiplier = 0.95
首先,确定每个节点Region数:
16,384 MB * 0.5 = 8,192 MB
8,192 MB / 128 MB = 64 activeRegions
其次, 确定每个Node的raw space:
64 activeRegions * 20 GB * 3 = 3.75 TB used
最后确定需要保持的WALs数目:
8,192 GB / (128 MB * 0.95) = 67 WALs
上例表明,每个RegionServer最多不超过67个Region,且集群里面总Region数目不要超过67个;包括复制,为了HFiles,每个Node需要提供3.7TB存储空间(不包括snapshots或者compactions)
在计算容量的时候,除去上面所述,还需要注意:
It is important to leave scratch space(临时空间) available (the typical recommendation is 20%–30% overhead). This space will be used for MapReduce scratch space, extra space for snapshots, and major compactions. Also, if using snapshots with high region counts, testing should be done to ensure there will be enough space for the desired backup pattern, as snapshots can
quickly take up space.
HBase使用LSM(Log-Structured Merge Tree日志结构合并树)树,用于为那些长期具有很高记录更新(插入或删除)频率的文件提供低成本的索引机制。
snapshot原理
 image.png
image.png
 image.png
image.png
Different Workload Tuning
内存方面:
如果你知道你的应用程序需要W GB for YARN containers, Impala will
use X memory, HBase heap needs Y to meet SLAs, and I want to save Z RAM for the OS, then my formula should be:
W + X + Y + Z = totalMemoryNeeded
但是这个公式实际上还不够,我们推荐在多给至少25%–30% free memory.
IO方面
CGroup 是 Control Groups 的缩写,是 Linux 内核提供的一种可以限制、记录、隔离进程组 (process groups) 所使用的物力资源 (如 cpu memory i/o 等等) 的机制。2007 年进入 Linux 2.6.24 内核,CGroups 不是全新创造的,它将进程管理从 cpuset 中剥离出来,作者是 Google 的 Paul Menage。CGroups 也是 LXC 为实现虚拟化所使用的资源管理手段。
CGroup 是将任意进程进行分组化管理的 Linux 内核功能。CGroup 本身是提供将进程进行分组化管理的功能和接口的基础结构,I/O 或内存的分配控制等具体的资源管理功能是通过这个功能来实现的。这些具体的资源管理功能称为 CGroup 子系统或控制器。CGroup 子系统有控制内存的 Memory 控制器、控制进程调度的 CPU 控制器等
The I/O contention is where the story really starts to fall apart. The only viable answer is to leverage control groups (cgroups) in the Linux filesystem. Setting up cgroups can be quite complex, but they provide the ability to assign specific process such as Impala, or most likely YARN/MapReduce, into specific I/O-throttled groups.
优化方面推荐几点经验:
- 对Impala要限制对内存的分配上限
- 对YARN要限制对container的使用数量
- 对Solr要限制内存和heap的使用量
只有去测试才能验证对规模的评估是否合理;
The good news with HBase and Hadoop is that they provide** linear scalability**(你可以放小规模做评估,然后线性放大即可), which allows for testing on a smaller level and then scaling out from there