2020/07/02 -
引言
实验室的深度学习服务器的环境,因为一直是公用的,各种库总是被人搞得乱七八糟;因为机器上很多个版本的python,我也不知道具体该怎么弄。现在的情况,说是给按照给学生分配jupyter的形式,但实际上有人有密码,有时候也会出现各种库被动。所以这里我就想着能不能实现深度学习库的容器化。而且,我觉得一些提供深度学习服务的厂商,应该也是这种部署方式把,毕竟这种比较方便。
那么本篇文章我就来记录一下,如何部署可以使用GPU的容器,最后能够生成一个对外开放jupyter端口,并且可以使用keras库与tensorflow_gpu。
具体的实践环境及需求
首先本次使用的机器具备三块显卡,然后nvidia的驱动等等都已经安装好了, 这个肯定是不能动了。

那么就需要按照驱动以及一些库的版本来适配后续的信息。
首先查看nvidia的驱动信息[1]
cat /proc/driver/nvidia/version
这个命令其实没有什么作用,就是看看自己的显卡驱动是不是安装好了,重要的是后面的。cuda和cudnn[2],关于为什么要安装这些库,我不是很清楚,因为最开始部署这个服务器的时候并不是我来部署的,这里就记住,这两个库是必须的就好了。(挖个坑,后面来描述他们的关系)
查看CUDA版本信息
cat /usr/local/cuda/version.txt
当前机器CUDA版本信息是
CUDA Version 9.0.176
再来看Cudnn的版本,命令如下
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
当前cudnn版本信息。
#define CUDNN_MAJOR 7
#define CUDNN_MINOR 1
#define CUDNN_PATCHLEVEL 4
--
#define CUDNN_VERSION (CUDNN_MAJOR * 1000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL)
#include "driver_types.h"
比较关键的版本信息是cuda 9,cudnn 7.1,这个时候就需要看tensorflow_gpu的版本信息了[3]。
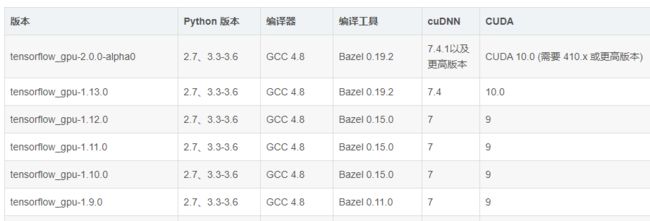
从图中可以看出,能够支持我这个Cuda和cndnn的最高版本是1.12.0,而且python版本也是3.6(这个是固定的,虽然图中1.13.0没有显示出来,python3.7是支持1.13.0的,而且最低支持就是1.13.0,但是这个版本不支持底层的驱动,所有无法使用。)
那么总结来说:
| 组件 | 版本 |
|---|---|
| CUDA | 9.0 |
| cuDnn | 7.1 |
| tensorflow_gpu | 1.12.0 |
| python | 3.6 |
在进行tensorlow_gpu安装完成后过程中,导入库,如果出现导入库错误,比如ImportError: libcublas.so.10.0,就说明版本没有对应上[5],这个错误就是我当时使用python3.7的时候,最低只能安装1.13.0,结果就是没有这个库。
注意:tensorflow分为CPU版本和GPU版本,如果要使用GPU进行加速,就必须安装tensorflow_gpu。
做过的尝试
前面说明了这个版本对应问题,这也是我经过了很多尝试得出的结论,因为在安装库的时候,并不是报错,只有你导入之后才会报错,比如前面所说的libxxx.so.10.0不行;甚至与根本没有GPU可以使用,虽然nvidia-smi可以显示GPU。这里就来列举下我当时做过的尝试,可以跳过直接看后续的真正安装过程。
首先我最终的目标是能够生成一个jupyter的服务端, 帮助我进行一些命令。那么第一想法就是是不是直接使用这个库就好了。但是怎么样将GPU给映射进去了。当时就是看了文章[4],然后我就开始手动映射这个GPU了,虽然当时我当时已经知道可以使用nvidia-docker了。
使用docker --device的形式将GPU映射进去,同时因为还需要各种库,还需要将lib及其他的驱动模块给映射进去。
docker run -it --device /dev/nvidia0:/dev/nvidia0 --device /dev/nvidiactl:/dev/nvidiactl -v /usr/bin/:/usr/bin -v /usr/lib64:/usr/lib64 -v /usr/local/cuda-9.0/targets/x86_64-linux/lib:/usr/cuda-lib centos:centos7
当时使用这个centos7作为基础镜像来做,弄完之后,进入了镜像,的确是可以看到显卡,然后keras库也安装了挺快。但是,在终端引入keras之后,就是不行。
关于检测是否使用了GPU的部分[6]。
首先执行是否存在GPU:
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
这命令在正常的GPU库上,会把所有的信息都给输出,连GPU的版本信息都会给出,但是上面的安装过程之后,虽然显示了一个GPU信息,去没有实际显卡的信息,当时也是在这个地方卡了很久,以为是版本库没弄对。实际上,是这个库根本检测不到实际的GPU,具体是什么原因我也不太清楚。虽然文章[4]中说到了这种方式和nvidia-docker实现的方式是一致的,但是实际上根本不好使。所以肯定是有些其他的地方没有关联好,导致这个驱动连接不上。
然后查看keras是否调用了GPU
from keras import backend as K
K.tensorflow_backend._get_available_gpus()
在正常机器上是可以输出GPU的,但是在不好使的机器上(上面构建的)就根本不好使,输出为空。
既然这种方式不好使,那么其他的各种直接使用jupyter的镜像的方式自然也不好使。而且,更加麻烦的是,他们的镜像的python版本等信息也都不匹配。当时还测试了各种镜像,纯python的,纯centos的(不得不说这个镜像还是很不错,下载的时候是阿里源下载的,内部的源已经都给替换好了),总之各种问题。有的镜像连yum都没法用。
那么最后只能采用那种nvidia-docker的方式,通过官方的方式来构造传递的过程。
nvidia-docker
安装的过程主要是参考文章[7],本身机器上已经安装了docker 17.03.02 - ce,这个不能动,就必须在这个基础上再进行安装别的东西。
- 添加nvidia-docker源
curl -s -L https://nvidia.github.io/nvidia-docker/centos7/x86_64/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo
- 查看可用的源
yum search --showduplicates nvidia-docker
-
安装nvidia-docker
安装时候一定要根本版本选择。在前面的命令中,匹配的版本是
 匹配版本
匹配版本
执行命令
yum install nvidia-docker2-2.0.3-1.docker17.03.2.ce.noarch
就可以执行安装,在安装完成之后,需要将docker进行重启,此时/etc/docker/daemon.json文件已经被重写,之前写的镜像源信息已经没了,需要重新将镜像源补上。
此时的deamon.json内容为
{
"registry-mirrors": ["https://vrgt48qn.mirror.aliyuncs.com"],
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
重启docker即可,文章[7]中还说要重启nvidia-docker,但是我执行了这个命令,并没有这个服务,这里就直接跳过了。此时已经可以使用nvidia-docker命令来启动镜像。
- 测试nvidia-docker是否可用
为了测试需要下载相应的镜像,这里的镜像直接使用nvidia/cuda,然后进入容器执行命令nvidia-smi。
可以使用两种形式,一种就是按照runtime参数,这个也是在deamon.json中可以看到的。
docker run --runtime=nvidia --rm nvidia/cuda nvidia-smi
但是上面这个命令是不好使的,因为这个镜像没有指定版本,这个版本并不支持底层的驱动;另外一种方式是直接使用nvidia-docekr,然后使用相应版本的镜像。
nvidia-docker rum --rm nvidia/cuda:9.0-cudnn7-runtime nvidia-smi
对于镜像的使用,为了挑选相应的版本,可以在dockerhub上搜索。在搜索框中填入9(cuda版本是9)
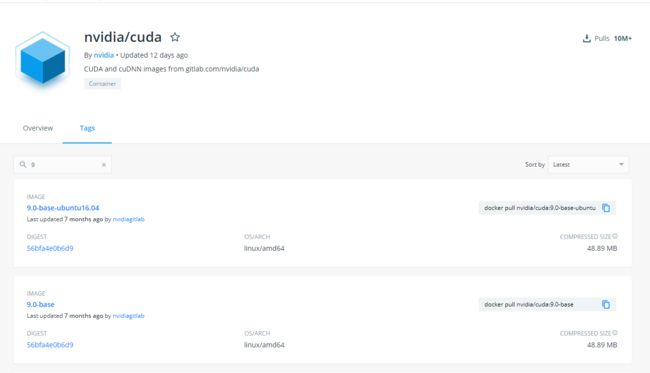
默认的这个runtime版本是ubuntu系统,下面还有其他的,比如centos。
注意:这里宿主机上已经安装了nvidia驱动,还包括cuda以及cndnn;我与一个问题,就是是不是docker的镜像会帮我把驱动在内部安装好,他只使用底层镜像呢?带着这个疑问,我下载了nvidia/cuda:10.2-runtime-ubuntu18.04的镜像,然后执行命令
nvidia-docker run --rm nvidia/cuda:10.2-runtime-ubuntu18.04 nvidia-smi
输出结果是:
nvidia-container-cli: requirement error: unsatisfied condition: cuda>=10.2
那么也就是说,这种方式并不可行。可能是我对这个驱动的信息理解的不全面,就是说前面的nvidia的驱动都是哪些东西的问题。这个问题也不大, 一般来说本地的主机也是要进行安装的。
文章[8]也是一个安装的过程,中间也说到了在安装nvidia-docker之后会覆盖原来的daemon.json文件,其他的大致思路是[7]一致的。
简单总结一下:
1)搭建过程需要宿主机安装nvidia驱动
2)安装nvidia-docker时要注意本机的docker版本
3)进行gpu是否可使用测试时,需要指定匹配的版本。
镜像选择
为了搭建自己的jupyter环境,在文章[9]中,其使用的方式利用nvidia/cuda作为基础镜像,然后再搭建各种乱七八糟的东西。他这个里面也是宿主机已经搭建了cuda和cudnn环境。
但是我在另外一个文章中看到了直接使用tensorflow环境的说明[10]。然后我以为只要你runtime是nvidia他就会把所有的东西都带进去,但是我使用centos镜像,并没有nvidia-smi这个命令,看来并不是说就能随便弄。
但是这个时候我想起了一件事,就是说,那容器内的cuda和cudnn的版本是多少呢,虽然在容器中找了很久,虽然找到了cuda的版本,但是找不到cudnn.h这个问题。
不管是tensorflow/tensorflow:1.12.0-gpu-py3,还是nvidia/cuda。通过定位文件,可以在python的库中找到这个东西,叫做use_cudnn.h类似的名字。
哦,我明白了,其实cudnn就是一个支持神经网络的库,他并不是必须的;容器内可以找到.so文件,不用其他的。
这里要说明的就是,构建出来的容器,不能通过这种方式来查看cudnn.h的信息。既然查看不到,就算了。
其实因为在最开始安装驱动的时候,我并不知道,可能这些东西就是用不到吧。
而且,我还看到了nvidia的容器中,存在这种-devel的版本,估计只有这种版本才会使用把。
就是说, 其实容器内包含了cudnn.so这种库,但是没有头文件,但是我现在构造出的镜像是说明可以成功运行的,就是说这个头文件可能是不需要的。
而且在tensorflow自己的文件夹下也有这种类似的头文件,不太清楚。
构建jupyter镜像
dockerfile如下
FROM nvidia/cuda:9.0-cudnn7-runtime
MAINTAINER VChao
ADD sources.list /etc/apt/
run rm -f /etc/apt/sources.list.d/* && apt-get update && \
ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone && \
apt-get install -y python3.6 && apt-get install -y python3-pip && \
pip3 install tensorflow_gpu==1.12.0 keras==2.2.4 -i https://pypi.douban.com/simple/
run pip3 install jupyter -i https://pypi.douban.com/simple/ && pip3 install jupyterlab -i https://pypi.douban.com/simple/
run mkdir /root/jupyter_work/
WORKDIR /root/
cmd ["jupyter","notebook", "--allow-root","--ip=0.0.0.0"]
命令很简单,首先从nvidia基础镜像开始构建,然后更换阿里源,这个源是通过赋值文件来实现的;删除
sources.list.d中的文件是因为里面的源是nvidia的一些东西,然后经常联不通影响构建,就直接删除了。下面就是更换时区,然后安装python3.6,这个一定要制定版本,而且当时测试使用中科大的源还是安装的python3.5所以前面改为了阿里源,安装pip后,从豆瓣的pypi源拉取相应的内容就好了。
对于keras的版本问题,可以看[11]。版本不对也是安装不上的。
执行命令docker build -t xx:0.1 .即可,然后启动镜像
nvidia-docker run --restart=always -it -d -p 10000:8888 -v `pwd`/qq_test:/root --env NVIDIA_VISIBLE_DEVICES=0 --name nidemingzi xxx:0.1
其中NVIDIA_VISIBLE_DEVICES=0是指定可以使用的GPU,这里只给了一个GPU。
而且这种方式,即使你修改了环境变量也使用不了其他的GPU,比原来直接使用jupyter要好。
同时挂载目录的时候,是吧整个root目录给挂在了,这是为了保存jupyter的密码等信息。
上述命令启动后,进入http://x.x.x.x:10000即可,token可以通过下面的命令获得。
Docker logs 刚生成的容器ID | grep -E -o 'token=.*?\>' | sort | uniq | cut -d"=" -f2
测试:一方面可以按照前面命令查看是否有GPU可以使用,另外可以使用keras给出的[12]脚本来测试,但是下载数据集的过程比较慢,可以手动下载,然后放置在/root/.keras/datasets中。
在运行过程中,容器内执行nvidia-smi命令能看到显存被占用,但是看不到具体的进程,不过宿主机是能看到的,这里不知道是怎么回事。可以查看文章[14]来弄。
总结
自此,通过docker容器来使用GPU的内容就结束了,可以生成可以使用的jupyter环境,后续还可以开启jupyterlab的环境。上述内容只是一个搭建过程,但是对与具体的原理不是很明白,就比如说他是如何挂在GPU的[4],这个部分也是一开始我搭建这个东西的时候错误的地方。而且由于起初安装nvidia驱动我并不是很清楚,所以导致我根本不知道这些东西的依赖。所以现在的方式基本上就是按照顺序,找对好版本搭建好了,但是具体的内容不是很清楚。
后续有机会,还是要看看这些库的依赖关系,比如为什么他们没有cudnn也是能够运行的这样一个问题。
后记
前面提到,因为我没有安装cuda的这个过程,所以就去看了看。大致上的流程也看懂了。看了文章[13]的内容,大致就是先安装cuda,然后cudnn,这个也是我前面的疑惑, 就是说,他完全是将这个东西复制过去的,我个人觉得,如果你不复制.h文件的话,应该也没问题,这就是我在那些容器中看到的,找不到这个cudnn.h头文件,虽然有库,但是这个库的版本也不跟我主机的一致,cuda是一致的。
参考
[1]检查安装的nvidia显卡驱动版本命令
[2]查看 linux系统中的 CUDA,CUDNN 版本 号
[3]tensorflow各个版本的CUDA以及Cudnn版本对应关系
[4]浅谈 docker 挂载 GPU 原理
[5]ImportError: libcublas.so.10.0: cannot open shared object file
[6]检查GPU是否可用
[7]安装使用NVIDIA-Docker-- 可使用GPU的Docker容器
[8]安装使用可支持GPU的Docker容器
[9][笔记] 基于nvidia/cuda的深度学习基础镜像构建流程
[10]使用docker在Ubuntu上安装TensorFlow-GPU
[11]keras和tensorflow的版本对应关系
[12]mnist_cnn.py
[13]https://blog.csdn.net/taoqick/article/details/79171199
[14]nvidia-smi 无进程占用GPU,但GPU显存却被占用了很多