在推荐系统中,我们经常会拿到一种数据是user—item的表格,然后对应的是每位user对每个item的评分,如下图:

对于这个问题我们通常会选择矩阵分解的方法来解决。
我们常见的推荐系统矩阵分解有BPR、SVD(funkSVD)、ALS、NMF、WRMF。
接下来就来看看推荐系统中常用的几种矩阵分解的区别,主要通过公式、特点和适合哪种数据这几个方面来讲。
1、奇异值分解SVD
1.1 传统奇异值分解SVD
对于矩阵进行SVD分解,把矩阵分解为:
其中是矩阵中较大的部分奇异值的个数,一般会远远的小于用户数和物品数。如果我们要预测第个用户对第个物品的评分,则只需要计算即可。通过这种方法,我们可以将评分表里面所有没有评分的位置得到一个预测评分。通过找到最高的若干个评分对应的物品推荐给用户。
可以看出这种方法简单直接。但是有一个很大的问题我们忽略了,就是SVD分解要求矩阵是稠密的,也就是说矩阵的所有位置不能有空白。所以传统的SVD实际上在推荐系统中还是比较难用的。
1.2 FunkSVD
前面说到,传统的SVD要求的矩阵是稠密的。那么我们现在要解决的问题就是避开矩阵稀疏的问题。
FunkSVD是将矩阵分解为两个矩阵,这里采用了线性回归的思想。我们的目标是让用户的评分和用矩阵乘积得到的评分残差尽可能的小,也就是说,可以用均方差作为损失函数,来寻找最终的。
对于某一个用户评分,用FunkSVD分解,则对应的表示为,采用均方差做为损失函数,则我们期望均方差尽可能小:
在实际应用中,我们为了防止过拟合,会加入一个L2的正则化项,因此正式的FunkSVD的优化目标函数:
其中为正则化稀疏,需要调参。对于这个优化问题,我们一般通过梯度下降法来进行优化得到结果。
将上式分别对求导,然后利用梯度下降法迭代,的迭代公式如下:
还有许多基于FunkSVD的方法进行改进的,例如BiasSVD、SVD++等,这里就不细说了。
1.3 FunkSVD小结
在很多推荐场景中,我们都是基于现有的用户和商品之间的一些数据,得到用户对所有商品的评分,选择高分的商品推荐给用户,funkSVD算法的做法最基本的做法,使用起来十分有效,而且模型的可扩展性也非常优秀,其基本思想也能广泛运用于各种场景中。并且对于相似度计算方法的选择,有多种相似度计算方法,每种都有对应优缺点,可针对不同场景使用最适合的相似度计算方法。由于funkSVD时间复杂度高,训练速度较慢,可以使用梯度下降等机器学习相关方法来进行近似计算,以减少时间消耗。
参考:https://www.cnblogs.com/pinard/p/6351319.html
https://zhuanlan.zhihu.com/p/34497989
https://blog.csdn.net/syani/article/details/52297093
2、 贝叶斯个性化排序(Bayesian Personalized Ranking,BPR)
2.1 BPR使用场景
在有些推荐场景中,我们是为了在千万级别的商品中推荐个位数的商品给用户,此时,我们更关心的是用户来说,哪些极少数商品在用户心中有更高的优先级,也就是排序更靠前。也就是说,我们需要一个排序算法,这个算法可以把每个用户对应的所有商品按喜好排序。BPR就是这样的一个我们需要的排序算法。
2.2 BPR算法流程
在BPR算法中,我们将任意用户对应的物品进行标记,如果用户在同时有物品和的时候点击了,那么我们就得到了一个三元组,它表示对用户来说,的排序要比靠前
下面简要总结下BPR的算法训练流程:
输入:训练集D三元组,梯度步长, 正则化参数,分解矩阵维度。
输出:模型参数,矩阵W,H
1. 随机初始化矩阵
2. 迭代更新模型参数:
3.如果收敛,则算法结束,输出,否则回到步骤2.
当我们拿到后,就可以计算出每一个用户对应的任意一个商品的排序分:,最终选择排序分最高的若干商品输出。
2.3 BPR小结
BPR是基于矩阵分解的一种排序算法,但是和funkSVD之类的算法比,它不是做全局的评分优化,而是针对每一个用户自己的商品喜好分贝做排序优化。因此在迭代优化的思路上完全不同。同时对于训练集的要求也是不一样的,funkSVD只需要用户物品对应评分数据二元组做训练集,而BPR则需要用户对商品的喜好排序三元组做训练集。
参考:https://www.cnblogs.com/pinard/p/9128682.html
3、交替最小二乘法ALS(alternating least squares)
3.1 ALS基本原理
ALS是交替最小二乘的简称。在机器学习中,ALS特指使用交替最小二乘求解的一个协同推荐算法。如:将用户(user)对商品(item)的评分矩阵分解成2个矩阵:user对item 潜在因素的偏好矩阵(latent factor vector),item潜在因素的偏好矩阵。
假设有m个user和n个item,所以评分矩阵为R。ALS(alternating least squares)希望找到2个比较低纬度的矩阵(X和Y)来逼近这个评分矩阵R。

ALS的核心就是这样一个假设:打分矩阵是近似低秩的。换句话说,就是一个的打分矩阵可以由分解的两个小矩阵和的乘积来近似。这就是ALS的矩阵分解方法。
3.2 ALS算法及流程
为了让X和Y相乘能逼近R,因此我们需要最小化损失函数(loss function),因此需要最小化损失函数,在此定义为平方误差和(Mean square error, MSE)。
一般损失函数都会需要加入正则化项(Regularization item)来避免过拟合的问题,通常是用L2,所以目标函数会被修改为:
上面介绍了“最小二乘(最小平方误差)”,但是还没有讲清楚“交替”是怎么回事。因为X和Y都是未知的参数矩阵,因此我们需要用“交替固定参数”来对另一个参数求解。
先固定Y, 将loss function对X求偏导,使其导数等于0:

再固定X, 将loss function对Y求偏导,使其导数等于0:

然后进行迭代。
具体流程如下:

3.3 ALS小结
在实际应用中,由于待分解的矩阵常常是非常稀疏的,与SVD相比,ALS能有效的解决过拟合问题。基于ALS的矩阵分解的协同过滤算法的可扩展性也优于SVD。与随机梯度下降的求解方式相比,一般情况下随机梯度下降比ALS速度快;但有两种情况ALS更优于随机梯度下降:(1)当系统能够并行化时,ALS的扩展性优于随机梯度下降法。(2)ALS-WR能够有效的处理用户对商品的隐式反馈的数据。
但是ALS算法是无法准确评估新加入的用户或商品。这个问题也被称为冷启动问题。
参考:https://flashgene.com/archives/46364.html
https://flashgene.com/archives/52522.html
https://lumingdong.cn/recommendation-algorithm-based-on-matrix-decomposition.html#ALS
4、非负矩阵分解(NMF,Non-negative Matrix Factorization)
4.1 NMF约束
非负矩阵分解(Non-negative Matrix Factorization,NMF)算法,即NMF是在矩阵中所有元素均为非负数约束条件之下的矩阵分解方法。NMF中要求原始的矩阵V的所有元素的均是非负的,并且矩阵V可以分解出的两个小矩阵也是非负的,
4.2 NMF算法流程
给定一个打分矩阵R,NMF的目标是求解两个非负秩矩阵 最小化目标函数如下:

计算的梯度如下:
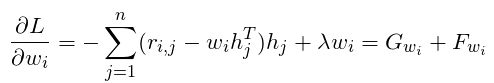

其中:


采用梯度下降的参数优化方式, 可得W以及H的更新迭代方式见下式:

在矩阵分解基础上,加入了隐向量的非负限制。然后使用非负矩阵分解的优化算法求解。

4.3 NMF小结
要用NMF做矩阵分解有一个很大的前提——用户item之间的评分矩阵要求是非负并且分解出的小矩阵也要满足非负约束。NMF分解是对原矩阵的近似还原分解,其存在的问题和ALS相像,对于未知的评分预测相当不准确。
参考:https://flashgene.com/archives/52522.html
http://tripleday.cn/2017/01/12/sparse-nmf/
5、带权正则矩阵分解(WRMF)
5.1 WRMF使用场景
在有些场景下,虽然没有得到用户具体的评分,但是能够得到一些类似于“置信度”的信息(也称为隐式反馈信息),例如用户的游戏时长、观看时长等数据。虽然时长信息不能直接体现用户的喜好,但是能够说明用户喜欢的概率更大。在此场景下,用户-物品记录可以表示为一个置信度和一个0-1指示量(用户-物品是否有交互),如果用户-物品没有交互,那么置信度就为0。
5.2 WRMF原理
“带权”就是根据置信度计算每条记录对应损失的权重,优化的目标函数如下:

权重通过置信度计算得到,可以使用。由于未发生的交互也存在于损失函数中,因此惯用的随机梯度下降存在性能问题,为此采用ALS来优化模型,因此训练过程如下:
(1)更新每个用户的向量:
(2)更新每个物品的向量:

5.3 WRMF小结
前面除了BPR以外,我们讲的算法都是针对显式反馈的评分矩阵的,因此当数据集只有隐式反馈时,应用上述矩阵分解直接建模会存在问题。而WRMF就可以解决隐式反馈的问题。
参考:https://sine-x.com/gorse-2/
https://flashgene.com/archives/52522.html
6、总结
SVD:
基于现有的用户和商品之间的一些数据,得到用户对所有商品的评分,选择高分的商品推荐给用户,可以根据以往的评分矩阵做全局的评分优化。有多种从SVD的改进算法可选择,如:表示biasSVD、SVD++、TimesSVD等
funkSVD可以解决矩阵稀疏的问题,但是其时间复杂度高,训练速度较慢,可以使用梯度下降等机器学习相关方法来进行近似计算,以减少时间消耗。
ALS:
ALS算法和SVD的使用场景相似,也是基于用户——商品评分数据得到全局用户对商品的评分。
ALS能有效的解决过拟合问题,但是ALS算法是无法准确评估新加入的用户或商品。这个问题也被称为冷启动问题。
NMF:
要用NMF做矩阵分解有一个很大的前提——用户item之间的评分矩阵要求是非负并且分解出的小矩阵也要满足非负约束。NMF分解是对原矩阵的近似还原分解,NMF用法和SVD、ALS相似。
NMF存在的问题和ALS相像,对于未知的评分预测相当不准确。
BPR:
BPR是基于矩阵分解的一种排序算法,但是,它不是做全局的评分优化,而是针对每一个用户自己的商品喜好分贝做排序优化。因此在迭代优化的思路上完全不同。BPR需要用户对商品的喜好排序三元组做训练集。
WRMF:
当没有得到用户具体的评分,但是能够得到一些类似于隐式反馈信息时,就可使用WRMF进行矩阵分解。