
在之前的博文中介绍了 NNI 与其他自动机器学习工具的比较,NNI 的安装和使用等内容,这篇文章你将看到:
- 如何修改 NNI 官方的 Mnist-annotation 例子的配置文件;
- 官方例子支持的 tuner 介绍;
- 各个 tuner 的训练结果以及结果分析。
一、配置文件
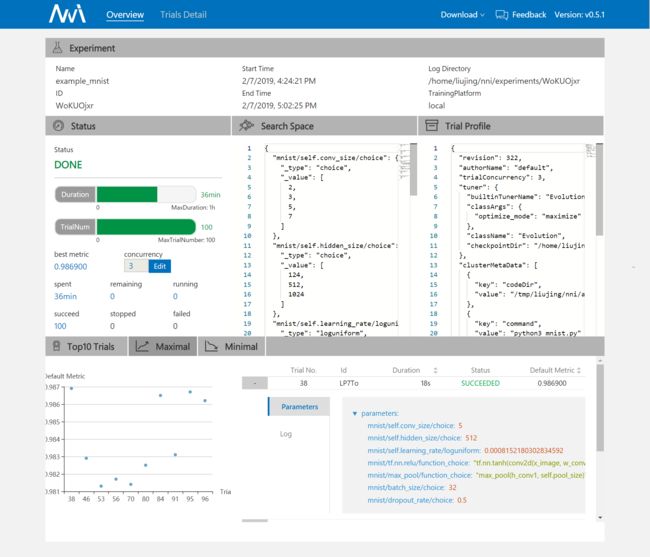
将 NNI 项目 clone 到本地,进入到目录~/nni/examples/trials/mnist-annotation,nni 有两种配置方式,分别为 Annotation 和 Assessor,nni 官方给的例子是用 Annotation 的配置方式(Assessor 可参见官方 experiment 配置参考文档),配置文件config.yml默认参数配置如下:
authorName: default
# authorName 是创建 Experiment 的作者。(你自己的名字 o(* ̄ ̄*) ブ)
experimentName: example_mnist
# experimentName 是 Experiment 的名称。
trialConcurrency: 1
# **trialConcurrency** 定义了并行运行的 trails 的数量。
# 注意:如果 trialGpuNum 大于空闲的 GPU 数量,Trial 任务会被放入队列,等待分配 GPU 资源。
maxExecDuration: 1h
# maxExecDuration 定义 Experiment 执行的最长时间。时间单位:{**s**, **m**, **h**, **d**},分别代表:{*seconds*, *minutes*, *hours*, *days*}。
# 注意:maxExecDuration 设置的是 Experiment 执行的时间,不是 Trial 的。 如果 Experiment 达到了设置的最大时间,Experiment 不会停止,但不会再启动新的 Trial 作业。
maxTrialNum: 10
# maxTrialNum 定义了你此次 Experiment 总共想要 NNI 跑多少 Trial。
trainingServicePlatform: local
#choice: local, remote, pai
# trainingServicePlatform 定义运行 Experiment 的平台
# local:在本机的 ubuntu 上运行 Experiment。
# remote:将任务提交到远程的 Ubuntu 上,必须用 **machineList** 来指定远程的 SSH 连接信息。
# pai:提交任务到微软开源的 OpenPAI 上。
# kubeflow 提交任务至 Kubeflow NNI 支持基于 Kubeflow 的 Kubenetes,以及 Azure Kubernetes
useAnnotation: true
#choice: true, false
#定义使用标记来分析代码并生成搜索空间。(官方例子使用的是 Annotation,所以 useAnnotation = true)
tuner:
builtinTunerName: TPE
#builtinTunerName 指定了系统 Tuner 的名字,NNI SDK 提供了多种 Tuner,如:{TPE, Random, Anneal, Evolution, BatchTuner, GridSearch}。
#choice: TPE, Random, Anneal, Evolution, BatchTuner
#SMAC (SMAC should be installed through nnictl)
classArgs:
#classArgs** 指定了 Tuner 算法的参数。 如果 builtinTunerName 是{TPE, Random, Anneal, Evolution},用户需要设置 optimize_mode。
#choice: maximize, minimize
optimize_mode: maximize
trial:
command: python3 mnist.py
codeDir: .
gpuNum: 0
二、tuner 对比实验
Random
建议场景
在每个 Trial 运行时间不长(例如,能够非常快的完成,或者很快的被 Assessor 终止),并有充足计算资源的情况下。 或者需要均匀的探索搜索空间。 随机搜索可作为搜索算法的基准线。
参数
- optimize_mode (maximize 或 minimize,可选,默认值为 maximize) - 如果为 'maximize',Tuner 会给出有可能产生较大值的参数组合。 如果为 'minimize',Tuner 会给出有可能产生较小值的参数组合。
使用样例:
# config.yml
tuner:
builtinTunerName: Random
classArgs:
optimize_mode: maximize
训练结果:
以下为 tuner 为 Random,TrialNum 为 30 时的训练结果,从下图右下角可以直观的得出,最大正确率为 98.28%,展开后可看到对应的超参值,在 Trails Detail 能够看到所有 Trails 在不同超参选择上的分布,便于分析。
卷积核大小:7×7
隐藏层:512
学习率:0.0018762964666695628
激活函数:ReLU
池化层:最大池化
batch size:32
dropout rate:0.5


结果分析:
正确率低于 30% 的 trails 隐藏层多数为 1024,学习率绝大多数低于 0.001,激活函数多数为 sigmoid。于此同时,正确率高于 90% 的 trails 卷积核大小大部分为 7×7,学习率主要分布在 0.001 以下。
根据以上对结果的分析,可以合理猜测,此模型下设置卷积核大小为 7×7,学习率低于 0.001,激活函数选用 relu 或 tanh,就能获得比较理想的正确率。
TPE
建议场景
TPE 是一种黑盒优化方法,可以使用在各种场景中,通常情况下都能得到较好的结果。 特别是在计算资源有限,只能运行少量 Trial 的情况。 大量的实验表明,TPE 的性能远远优于随机搜索。
参数
- optimize_mode (maximize 或 minimize,可选,默认值为 maximize) - 如果为 'maximize',Tuner 会给出有可能产生较大值的参数组合。 如果为 'minimize',Tuner 会给出有可能产生较小值的参数组合。
使用样例:
# config.yml
tuner:
builtinTunerName: TPE
classArgs:
optimize_mode: maximize
训练结果:
以下为 tuner 为 TPE,TrialNum 为 30 时的训练结果,从下图右下角可以直观的得出,最大正确率为 98.13%,展开后可看到对应的超参值:
卷积核大小:7×7
隐藏层:1024
学习率:0.0005779853380708741
激活函数:ReLU
池化层:最大池化
batch size:16
dropout rate:0.5

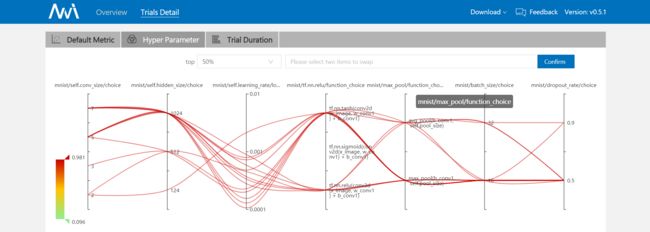
结果分析:
正确率前 50% 的 trails 隐藏层多数为 1024,学习率全部低于 0.001,激活函数多数为 relu 和 tanh,卷积核大小大部分为 7×7 和 5×5。
根据以上对结果的分析,可以合理猜测,此模型下设置卷积核大小为 7×7 或 5×5,学习率低于 0.001,激活函数选用 relu 或 tanh,就能获得比较理想的正确率。
Anneal
建议场景
当每个 Trial 的时间不长,并且有足够的计算资源时使用(与随机搜索基本相同)。 或者搜索空间的变量能从一些先验分布中采样。
参数
- optimize_mode (maximize 或 minimize,可选,默认值为 maximize) - 如果为 'maximize',Tuner 会给出有可能产生较大值的参数组合。 如果为 'minimize',Tuner 会给出有可能产生较小值的参数组合。
使用样例:
# config.yml
tuner:
builtinTunerName: Anneal
classArgs:
optimize_mode: maximize
训练结果:
以下为 tuner 为 Anneal,TrialNum 为 100 时的训练结果,从下图右下角可以直观的得出,最大正确率为 98.89%,展开后可看到对应的超参值:
卷积核大小:7×7
隐藏层:512
学习率:0.0010559236204399935
激活函数:ReLU
池化层:最大池化
batch size:32
dropout rate:0.5


结果分析:
正确率前 20% 的 trails 隐藏层基本分布于 512 和 1024,学习率分布在 0.001 左右,激活函数为 relu,卷积核大小大部分为 5×5。
根据以上对结果的分析,可以合理猜测,此模型下设置卷积核大小为 5×5,学习率在 0.001 左右,激活函数选用 relu,隐藏层为 1024 或 512,就能获得比较理想的正确率。
Evolution
建议场景
此算法对计算资源的需求相对较高。 需要非常大的初始种群,以免落入局部最优中。 如果 Trial 时间很短,或者利用了 Assessor,就非常适合此算法。 如果 Trial 代码支持权重迁移,即每次 Trial 会从上一轮继承已经收敛的权重,建议使用此算法。 这会大大提高训练速度。
参数
- optimize_mode (maximize 或 minimize,可选,默认值为 maximize) - 如果为 'maximize',Tuner 会给出有可能产生较大值的参数组合。 如果为 'minimize',Tuner 会给出有可能产生较小值的参数组合。
使用样例:
# config.yml
tuner:
builtinTunerName: Evolution
classArgs:
optimize_mode: maximize
训练结果:
以下为 tuner 为 Evolution,TrialNum 为 30 时的训练结果,从下图右下角可以直观的得出,最大正确率为 98.69%,展开后可看到对应的超参值:卷积核大小:5×5
隐藏层:512
学习率:0.0008152180302834592
激活函数:tanh
池化层:最大池化
batch size:32
dropout rate:0.5

结果分析:
正确率前 20% 的 trails 隐藏层多数分布于 512,学习率分布在 0.001 左右较为集中,激活函数为 tanh 较为集中,卷积核大小大部分为 5×5 或 3×3。
根据以上对结果的分析,可以合理猜测,此模型下设置卷积核大小为 5×5,学习率在 0.001 左右,激活函数选用 tanh,隐藏层为 512,就能获得比较理想的正确率。
三、总结
综合对比不同 tuner 的实验结果,发现不同的 tuner 算法得出的超参分布存在一定差异性,如在使用 Anneal 时准确率前 20% 的 trails 采用的激活函数都为 relu,而 Evolution 的实验中,这部分 trails 却是 tanh 居多。需要思考一下神经网络模型相同的情况下,是什么导致的这些差异性。同样,我们在对比中也能发现许多一致性,通过这些一致性能够对我们的模型调参工作以及对深度学习的理解给予一些启示。