系列目录
- 序篇
- 准备工作
- BIOS 启动到实模式
- GDT 与保护模式
- 虚拟内存初探
- 加载并进入 kernel
- 显示与打印
- 全局描述符表 GDT
- 中断处理
- 虚拟内存完善
- 实现堆和 malloc
- 创建第一个内核线程
- 多线程运行与切换
- 锁与多线程同步
- 进程的实现
- 进入用户态
- 一个简单的文件系统
- 加载可执行程序
- 系统调用的实现
- 键盘驱动
- 运行 shell
中断
中断在 CPU 中扮演着非常重要的角色,对硬件的响应,任务的切换,异常的处理都离不开中断。它既是驱动一切的源动力,又是给我们带来各种痛苦的万恶之源。
中断相关的问题将会贯穿整个 kernel 的开发,它的难点就在于它对代码执行流的打乱,以及它的不可预知性。本篇只是初步搭建起中断处理的框架,后面它会一直如影随形,同时也是考验 kernel 设计实现的试金石。
概念准备
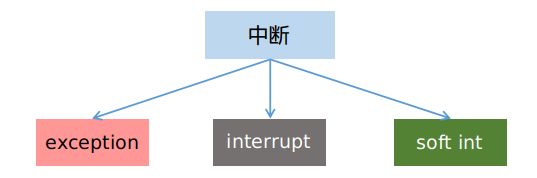
经常有一些关于中断、异常,硬中断,软中断等文字上的概念混淆,而且中英文在这些术语的使用也有些不统一。为了理解上的统一,我们在后面的术语使用上做一个声明:
- 中断,这个词用作总体概念,即它包括各种类型的中断和异常;
然后在中断这个总概念下,做如下分类:
- 异常(
exception):内部中断,它是 CPU 内部执行时遇到的错误,在英文表述上它有exception,fault,trap等几类,我们一般都统称为exception;此类问题一般是不可屏蔽,必须被处理的; - 硬中断(
interrupt):外部中断,一般就是其它硬件设备发来的,例如时钟,硬盘,键盘,网卡等,它们可以被屏蔽; - 软中断(
soft int):严格来说这不是中断,因为这是由int指令主动触发的,最常用的就是系统调用,这是用户主动请求进入 kernel 态的方式;它的处理机制和其它中断是一样的,所以也归在中断里;
后面我们就用英文单词 exception 来指第一类,即 CPU 内部异常和错误,这一点没有歧义;而 interrupt 这个单词用来专指第二类,即硬中断,这也是 Intel 文档上的原始用法;至于第三类,可以先忽略,因为目前我们还不需要讨论它;
至于中断这个中文词,我们用来指代包括上述的所有类型,是一个大概念,注意我们不将它与单词 interrupt 等同。
注意这纯粹是我的个人用法和规定,只是为了方便后面术语的表述和理解上的统一。
中断表述符表
之所以中断这个词会引起歧义,我想可能是因为所有以上这些东西的处理函数都放在了中断描述符表 IDT(Interrupt Descriptor Table)里管理,导致好像中断超出了 interrupt 这个词本身的范畴,把 exception 也给囊括了进来。这也是为什么我想用中文词中断来表示总体概念,而用英文的 interrupt 和 exception 表示它下面的两个子概念。
IDT 表项
回到中断描述符表 IDT,它的主要作用就是定义了各种中断 handler 函数,它的每个 entry 的结构定义如下:
struct idt_entry_struct {
// the lower 16 bits of the handler address
uint16 handler_addr_low;
// kernel segment selector
uint16 sel;
// this must always be zero
uint8 always0;
// attribute flags
uint8 attrs;
// The upper 16 bits of the handler address
uint16 handler_addr_high;
} __attribute__((packed));
typedef struct idt_entry_struct idt_entry_t;代码链接在 src/interrupt/interrupt.h,关于 IDT 的文档可以参考这里。
具体每个字段的含义请参考以上文档,这里细讲一下其中两个比较重要的字段:
sel:即selector,这里规定了这个中断处理函数所在的segment。进入中断处理后,CPU 的code段寄存器即cs就被替换为该值,所以这个 selector 必须指向kernel的code segment;DPL:这是attrs字段中的 2 个 bit,它规定了能够调用,或者说进入这个 handler 所需要的 CPU 的最低特权级;对我们来说必须将它置为特权级 3 即用户级,否则在用户态下就无法进入中断了;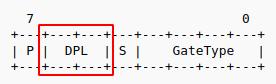
当然,上面的 IDT entry 里我们还缺了一个最重要的部分,就是中断处理函数的地址,这个后面再讲。
构建 IDT
然后就可以定义 IDT 结构,代码在 src/interrupt/interrupt.c:
static idt_entry_t idt_entries[256];这里预留了 256 个 entry,已经绰绰有余满足我们的需求。
这其中前 0 ~ 31 项是留给 exception 的。从第 32 项开始,用作 interrupt 处理函数。每一个中断都会有一个中断号,对应的就是 IDT 表中的第几项,CPU 就是根据此找到中断 handler 并跳转过去。
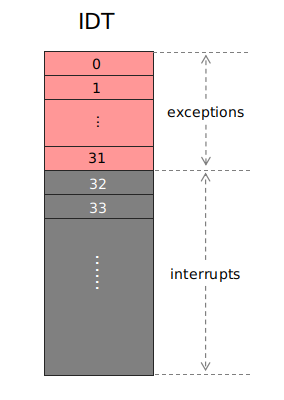
其中 exception 是以下这些,我直接从 wiki 上拿的图:

其中第 14 个 page faualt,即缺页异常,我们在下一篇虚拟内存完善中会重点处理。其它 exception 我们目前无需关注,因为它们正常情况下不应该出现。
IDT 从第 32 项开始就是给 interrupt 用的,例如第 32 项就是时钟(timer) interrupt 用的。
中断处理函数
我们回到上面提到的中断处理函数,或者叫中断 handler,它的地址被写在了上面 IDT 的每一个 entry 里。目前它们还不存在,所以我们需要定义这些函数。
每个中断的 handler 当然都不一样,但是进入以及离开这些 handler 的前后都会有一些共性的工作需要做,那就是保存以及恢复中断发生前的现场,或者叫上下文(context),这主要包括各种 register,它们将会被保存在 stack 中。因此中断的处理过程是类似这样的:
save_context();
handler();
restore_context();值得注意的是,context 的保存和恢复工作是由 CPU 和我们共同完成的,即 CPU 会自动压入一部分 register 到 stack 中,我们则根据需要也压入一部分 register 和其它信息到 stack 中。这两部分内容共同组成了中断的 context。
中断 CPU 压栈
首先来看 CPU 自动压入 stack 的寄存器:
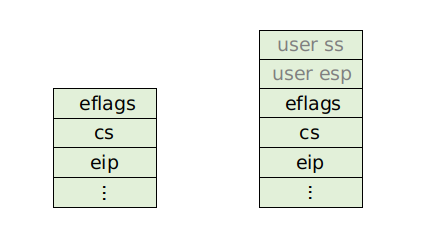
这里有两种情况:
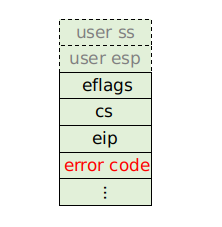
- 如果从 kernel 态进入中断的,则只会压入左图的三个值;
- 如果是从用户态进入的中断,那么 CPU 会压入右图的五个值;
两者的区别就是顶部的 user ss 和 user esp。
我们可以看一下这里的内在逻辑:CPU 做的事情的目的是很明确的,它保存的是指令执行流的上下文状态,这里包含了两个核心要素:
- 中断发生前的
instruction位置(cs和eip提供); - 中断发生前的
stack位置(ss和esp提供);
但为什么只有在发生特权级转换的时候(用户态进入 kernel 态)才需要压入当前 ss 和 esp? 因为用户态代码执行和 kernel 态代码是在不同的 stack 里进行的,从用户态进入中断处理,需要转换到 kernel 的 stack 中;等中断处理结束后再回到用户的 stack 里,所以需要将用户的 stack 信息保存下来。
下图展示了在用户态下发生中断时,stack 的跳转:

而如果中断发生在 kernel 态,那么情况会变得简单很多,因为原本就在 kernel 的 stack 中,中断处理仍然是在同一个 stack 中执行,所以它的情况有点像是一次普通的函数调用(当然略有不同):

我们看到 CPU 只负责保存了 instruction 和 stack 相关的寄存器,却没有保存 data 相关的寄存器,这主要包括了几个通用寄存器 eax,ecx,edx,ebx,esi,edi 以及 ebp,当然还有几个 data 段寄存器 ds,es,fs,gs 等。
为什么 CPU 不管这些寄存器呢?其实我也不太明白,只能说这是 CPU 体系架构设计决定的。我个人的理解是,CPU 是一个指令执行者,它只关心指令的执行流,这包括了 instruction 和 stack 这两个核心要素;至于 data,则应交由上层逻辑,也就是代码本身的逻辑来负责管理。这里面的设计理念,实际上是要对硬件和软件各自负责的逻辑做一个切分,实际上这很难界定,也可以理解为是历史遗留,从一开始就这么定下了。
中断 handler
扯远了,我们回到中断 context 保存的问题。既然 CPU 没有保存 data 相关的寄存器,那就由我们自己来保存。
我们自顶向下,来看中断 handler 的代码。首先,每一个中断显然都有它自己的中断 handler,或者叫 isr (interrupt service routine):
isr0
isr1
isr2
...这里每一个 isr* 有一个通用的结构,这里用了 asm 里的 macro 语法来定义:
; exceptions with error code pushed by CPU
%macro DEFINE_ISR_ERRCODE 1
[GLOBAL isr%1]
isr%1:
cli
push byte %1
jmp isr_common_stub
%endmacro
; exceptions/interrupts without error code
%macro DEFINE_ISR_NOERRCODE 1
[GLOBAL isr%1]
isr%1:
cli
push byte 0
push byte %1
jmp isr_common_stub
%endmacro然后我们就可以定义所有 isr*:
DEFINE_ISR_NOERRCODE 0
DEFINE_ISR_NOERRCODE 1
DEFINE_ISR_NOERRCODE 2
DEFINE_ISR_NOERRCODE 3
DEFINE_ISR_NOERRCODE 4
DEFINE_ISR_NOERRCODE 5
DEFINE_ISR_NOERRCODE 6
DEFINE_ISR_NOERRCODE 7
DEFINE_ISR_ERRCODE 8
DEFINE_ISR_NOERRCODE 9
...为什么会有两种 isr 定义呢?其实上面关于 CPU 自动压栈有一点忘记说了,除了上面提到的关于 instruction 和 stack 的信息保存,对于某些 exception,CPU 还会压入一个 error code。至于哪些 exception 会压入 error code,可以参考上面给出那张表格。
由于存在这么一个奇葩的不一致性,为了统一起见,对于那些不会压入 error code 的 exception,我们手动补充一个 0 进去。
所以总结下,isr 是中断处理的总入口,它主要做了这几件事情:
- 关闭
interrupt,注意这个只能屏蔽硬中断,对于exception是无效的; - 压入中断号码;
- 跳转进入
isr_common_stub;
来到 isr_common_stub,代码在 src/interrupt/idt.S,这里是保存和恢复 data 相关寄存器上下文,以及进入真正的中断处理的地方。
这是它的前半段:
[EXTERN isr_handler]
isr_common_stub:
; save common registers
pusha
; save original data segment
mov ax, ds
push eax
; load the kernel data segment descriptor
mov ax, 0x10
mov ds, ax
mov es, ax
mov fs, ax
mov gs, ax
call isr_handler紧接着是它的后半段:
interrupt_exit:
; recover the original data segment
pop eax
mov ds, ax
mov es, ax
mov fs, ax
mov gs, ax
popa
; clean up the pushed error code and pushed ISR number
add esp, 8
; make sure interrupt is enabled
sti
; pop cs, eip, eflags, user_ss, and user_esp by processor
iret这里其实是只有一个函数 isr_common_stub(前半段并没有 ret)。interrupt_exit 只是我加的一个标记,因为以后在别的地方会用到。当然其实汇编里本来也没什么函数的概念,本质上都是标记而已。
我们看到前半段做了几件事情:
pusha保存了所有通用寄存器;- 接着保存 data 段寄存器
ds; - 修改 data 段寄存器为 kernel 的,然后调用真正的中断处理逻辑
isr_handler(后面再讲);
在中断处理完毕后,后半段的恢复阶段做了以下几件事情,本质上是前半段的逆操作:
- 恢复原来的
data段寄存器; popa恢复所有通用寄存器;- 跳过栈里的 error code 和中断号;
- 恢复中断并返回;
这样我们可以画出完整的中断发生时的 stack,其中绿色部分是保存的中断上下文,包括了 CPU 自动压入和我们自己压入的部分:
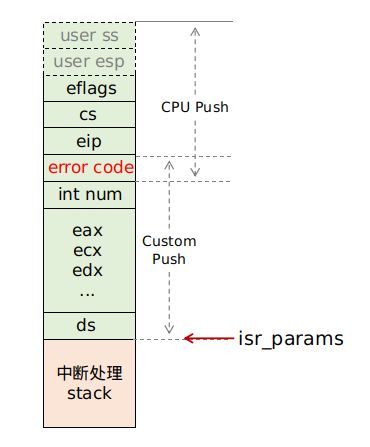
其中下方粉红色部分是真正的中断处理核心函数 isr_handler,它是用 C 语言编写的:
typedef void (*isr_t)(isr_params_t);
void isr_handler(isr_params_t regs);其中参数 isr_params_t 结构定义为:
typedef struct isr_params {
uint32 ds;
uint32 edi, esi, ebp, esp, ebx, edx, ecx, eax;
uint32 int_num;
uint32 err_code;
uint32 eip, cs, eflags, user_esp, user_ss;
} isr_params_t;之所以 isr_handler 可以以此结构作为参数,正是因为图中绿色部分的压栈,然后通过 call isr_handler,绿色部分就正好就对应了 isr_params_t 结构。红色箭头指向的正是参数 isr_params_t 的地址。
通过 isr_params_t 这个参数,我们在 isr_handler 里就能获取有关中断的所有信息:
void isr_handler(isr_params_t params) {
uint32 int_num = params.int_num;
// ...
// Bottom half of interrupt handler - now interrupt is re-enabled.
enable_interrupt();
// handle interrupt
if (interrupt_handlers[int_num] != nullptr) {
isr_t handler = interrupt_handlers[int_num];
handler(params);
} else {
monitor_printf("unknown interrupt: %d\n", int_num);
PANIC();
}
}上半部分都是关于 CPU 和中断外设芯片的必要交互,你可以暂时忽略。isr_handler 作为一个通用的中断处理入口,它实际上起的是一个分发作用,它会根据中断号来找到对应中断的真正处理函数,这些函数我们定义在了 interrupt_handlers 这个数组里:
static isr_t interrupt_handlers[256];它们通过 register_interrupt_handler 函数来设置:
void register_interrupt_handler(uint8 n, isr_t handler) {
interrupt_handlers[n] = handler;
}以上的代码都位于 src/interrupt/ 中,代码不多但是比较绕,仔细阅读应该不难理解。
打开时钟 interrupt
以上都是理论部分,我们需要一个真正的中断来实践一下效果。最理想的 interrupt 当然是时钟(timer)中断,这也是后面用来驱动多任务切换的核心中断。初始化 timer 的代码在 src/interrupt/timer.c 里,这里不多赘述,主要都是硬件端口相关的操作,设置了时钟频率,以及最重要的注册中断处理函数:
register_interrupt_handler(IRQ0_INT_NUM, &timer_callback);IRQ0_INT_NUM就是 32,这是时钟中断号;timer_callback我们可以简单做打印处理:
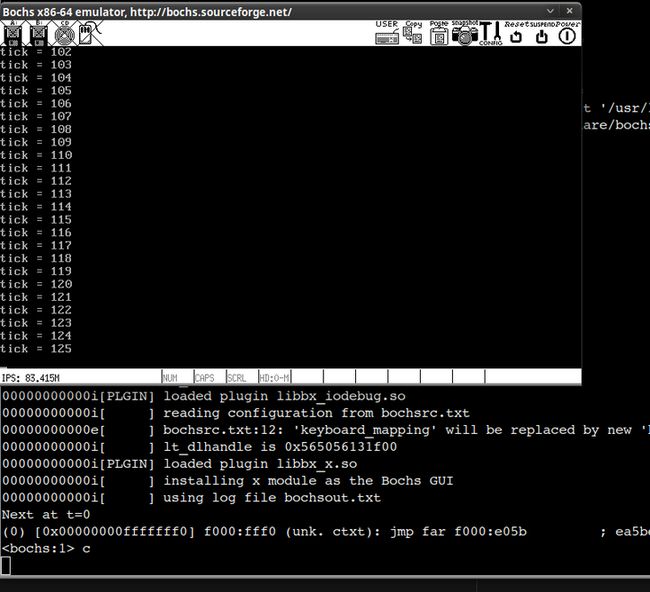
static uint32 tick = 0;
static void timer_callback(isr_params_t regs) {
monitor_printf("tick = %d\n", tick++);
}然后就可以尝试验证:
int main() {
init_gdt();
monitor_clear();
init_idt();
init_timer(TIMER_FREQUENCY);
enable_interrupt();
while (1) {}
}运行 bochs,运气好的话能看到这个:
触发 exception
timer 是硬中断 interrupt,我们再来看一个 exception 的例子,比如 page fault,中断号为 14:
register_interrupt_handler(14, page_fault_handler);void page_fault_handler(isr_params_t params) {
monitor_printf("page fault!\n");
}如何引发 page fault?很简单,只要我们去访问一个 page table 里没有被映射的 virtual 地址就可以了。
int main() {
init_gdt();
monitor_clear();
init_idt();
register_interrupt_handler(14, page_fault_handler);
int* ptr = (int*)0xD0000000;
*ptr = 5;
while (1) {}
}运行 bochs,运气好的话能看到这个:

可以看到它在不停地打印,这是因为我们的 page fault 处理函数除了打印什么也没做,它没有真正解决 page fault。处理结束后,CPU 会尝试再度去执行之前引发 page fault 的那条内存访问指令,所以会再次触发 page fault。关于 page fault 的真正处理,我们留待下一篇,虚拟内存完善。