最后一次更新日期: 2019/5/12
机器学习系列教程,旨在解释算法的基本原理并提供算法的入门级实现思路。
为检查代码实现的正确性,可能会与scikit-learn库作对照。
需要引入以下模块:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import math
主要使用的计算与绘图库可查阅以下资料:
numpy使用指南
pandas简要使用教程
matplotlib简要使用教程
一. 问题原型与假设函数
1. 问题原型
通常存在这样的一个场景,我们希望给程序输入一系列我们持有的数值,而程序输出另一个我们所需要的数值,比如老生常谈的房价预测问题,输入一个房屋的市中心距离、房间数、空气质量等属性(这些属性一般被称为特征),输出房屋的价格预测(这种连续的输出数值也被称为回归值)。
这样多个输入到一个输出的映射关系,可以是简单的线性关系,即每个输入与输出的函数图像都是直线(固定其他输入),也可以是复杂的非线性关系,即函数图像是曲线。
2. 假设函数
此处不妨就从最简单的场景开始,只有一个特征,且假设它与目标回归值为简单的线性关系,这种关系可以表示成这样一个函数:,和是影响输出的两个参数。可以很容易的得出,函数的完整形式应该是:,但此处先不考虑多个特征的情况。
绘制出二维图像后可以发现,我们只要找出一条直线使其能够最优地贴合已知的一些数据点就行了,所以线性回归是一种监督学习方式,需要我们提供一些已知结果的数据,否则我们无法在训练过程中判断模型输出的优劣,也就无法进行优化了。![[python][机器学习][回归]线性回归_第1张图片](http://img.e-com-net.com/image/info10/1dce27d2680b49498b1dcf4acc1f01cc.jpg)
为方便测试,可用numpy构造一个用于线性回归的简单数据集:
x1=np.linspace(0,10,20)
y=3*x1+2+np.random.randn(20)*5
plt.scatter(x1,y)
plt.plot(x1,3*x1+2,c='r')
plt.xlabel('x1')
plt.ylabel('y')
假设函数的代码实现:
#假设函数
def linear(theta0,theta1,x1):
return theta0+theta1*x1
现在我们有了一个将输入映射到输出的函数,但是还没有办法评估输出结果的好坏。
二. 代价函数与模型评估
1. 代价函数:均方误差
之所以叫做代价函数,可以理解为因为模型输出不正确的结果,我们需要它为此付出代价,接受惩罚,错得越离谱,惩罚越重。所以代价函数至少应该有如下性质:当结果完全正确时,代价值为0;偏离正确结果越多,代价值越大。
可以很快想到的就是将正确的输出与错误的输出相减(简称残差)再取绝对值就能得到衡量单条记录输出质量的数值,取绝对值是为了消除正负的影响,因为在当前场景下,无论是小于还是大于正确的回归值,都不是我们想要的,应该同等视之,而在衡量多条记录的整体输出偏差时,往往会将代价值求平均,如果有正负会相互抵消,这也不是我们想要的。
残差绝对值是一个可用的代价函数,但是却不便于优化,由于绝对值函数非连续可导,使用该函数作为代价函数会导致无法使用梯度下降法这类依赖于梯度信息的优化方法,所以此处不采用,改用残差平方和(也称均方误差),同样可以正确衡量输出质量,公式为:,其中是样本数量。公式中之所以额外除以了2只是出于计算上的习惯,在后面进行求导时分母上的2会被约去。
代价函数的代码:
#代价函数
#p_y是predict y,即模型的输出
def cost(p_y,y):
return 0.5*np.power(y-p_y,2).mean()
可以研究一下在只有一条记录时,代价函数的变化特点:
def cost1(p_y,y):
return np.power(y-p_y,2)
x=np.full((100,),2)
y=np.full((100,),3)
p_y=y+np.linspace(-5,5,100)
theta1=p_y/x
theta0=p_y-x
cost_=cost1(p_y,y)
fig=plt.figure(figsize=(12,3))
ax=fig.add_subplot(131,title='y=3')
ax.plot(p_y,cost_,c='r')
ax.set_xlabel('p_y')
ax.set_ylabel('cost')
ax=fig.add_subplot(132,title='y=3, x=2, theta1=1')
ax.plot(theta0,cost_,c='r')
ax.set_xlabel('theta0')
ax.set_ylabel('cost')
ax=fig.add_subplot(133,title='y=3, x=2, theta0=0')
ax.plot(theta1,cost_,c='r')
ax.set_xlabel('theta1')
ax.set_ylabel('cost')
![[python][机器学习][回归]线性回归_第2张图片](http://img.e-com-net.com/image/info10/bb457be22f5a4c319615f11654f42b24.jpg)
关于代价函数和损失函数的区别:
初学者往往会对这两个类似的概念感到困惑,如果追求严谨,可以用损失函数表示单条记录的输出偏差,而代价函数则是数据集中所有记录损失的平均,或者只用两个名词中的一个进行统一的表述,本文中倾向于后者,统一称为代价。
2. 评估指标:R2
代价函数是定义给程序看的,程序能够通过代价函数计算输出的偏差,并在偏离正确值越远时以更快地速度矫正。但对于用户来说,代价函数就不那么直观了,因为不同类数据集的代价函数值域不一样,我们很难从中看出离最优结果还差多少,所以需要一个更直观的统计指标,理想的情况是值域为[0,1],越接近完全准确的预测则输出越接近1,可以视作对模型优劣的评分。
R2(或叫R方)就是这样的一个指标,公式为,其中。
SSE即sum of error squares(残差平方和),SST即sum of total squares(总平方和),SSR即sum of regression squares(回归平方和),等于SST-SSE。这其中的含义可以观察下面这段代码绘制的图理解:
x1=np.array([1,2,3,10])
y=3*x1+2
p_y=2*x1+6
y_mean=np.full(4,y.mean())
plt.plot(x1,y,c='b')
plt.text(9,31,'y')
plt.plot(x1,p_y,c='g')
plt.text(9,26,'p_y')
plt.plot(x1,y_mean,c='r')
plt.text(9,12,'y_mean')
x1=[8,8,8,8]
y=[3*8+2,2*8+6,y.mean(),0]
plt.scatter(x1,y,s=40,c='k')
plt.text(8.2,1,'x_i')
plt.text(8.2,24,'SSE')
plt.text(8.2,17,'SSR')
plt.plot([x1[0],x1[2]],[y[0],y[2]],c='k');
plt.plot([x1[2],x1[3]],[y[2],y[3]],c='k',linestyle='--');
plt.title('R2')
plt.xlabel('x1')
plt.ylabel('y')
plt.ylim([0,33])
![[python][机器学习][回归]线性回归_第3张图片](http://img.e-com-net.com/image/info10/97f9d14a89c34eddaa53467f0203abe3.jpg)
图中绘制了,(p_y),(y_mean)对应的直线,拿其中一个数据点举例,SSE对应的是蓝绿线之间的差值,当预测值与真实值越接近,该差值越小,SST对应的是蓝红线之间的差值,SST的公式类似于方差,可以描述的离散程度,SSR则是SST-SSE,相当于绿红线之间的差值(注意,因为实际运算时取平方消除了正负,这种对应并不严格,当处在蓝线上方的区域时,应当参考蓝线下方的等距点)。
可以看出,R2就是在计算所表达的数据分布与在多大程度上符合。R2的计算等价于 1 - 代价值/方差,评分需要基准值,而此处就是以方差作为基准值,当代价值为0,与完全一致时,R2达到最大值1,而当模型输出非常糟糕,代价值甚至大于方差时,R2会是负数,不过在多数情况下R2还是保持在[0,1]范围内。
R2是回归模型最常用的评估指标,sklearn中也是使用该指标进行评估。在R2之上,还有调整R2,公式,其中是样本数,是特征数。该指标将样本数纳入了考虑范围,在相同R2的情况下,会倾向于样本数更少的模型,但易出现除零错误,一般可将调整R2与R2一同求出,在R2相同时再以调整R2作为进一步选择的参考。
代码实现示例:
def r2(y,p_y):
SSE=(np.power(y-p_y,2)).sum()
SST=(np.power(y-y.mean(),2)).sum()
return 1-SSE/SST
def r2_adjusted(r2,p,n):
return 1-(1-r2)*(n-1)/(n-p-1)
三. 梯度下降法优化
1. 批量梯度下降
观察一下上一章节代价函数的函数图像,可以发现,函数图像总是只有一个最低点,我们希望模型在已知数据上的输出尽可能正确,即代价值要尽可能低,只需要求出代价函数的最小值所在位置,该位置会确定所有已知数据的期望输出,然后根据假设函数便能计算出正确的。
当然,上图被限制为只有一条记录,但可以确定的是,即使应用在一个数据集上,代价函数依旧是只有一个最小值的凸函数,有兴趣的可以查找相关资料了解如何证明。
我们实现代价函数的代码时输入是模型的预测输出,但实际进行优化时,我们能改变的是模型的参数,所以需要将假设函数考虑进去,完整的表示出优化目标函数与优化项之间的关系。
下面一段代码将使用之前生成的数据集,并将和的变化置于同一个图中:
theta0=np.linspace(-8,12,100)
theta1=np.linspace(-7,13,100)
theta0,theta1=np.meshgrid(theta0,theta1)
cost_=[]
for t0,t1 in zip(theta0.flat,theta1.flat):
cost_.append(cost(linear(t0,t1,x1),y))
cost_=np.array(cost_).reshape((100,100))
fig=plt.figure(figsize=(9,3))
ax=fig.add_subplot(121)
levels=[1,2,4,8,16,32,64,128]
c=ax.contour(theta0,theta1,cost_,levels,colors='k',linewidths=0.5)
ax.clabel(c,fontsize=10)
cf=ax.contourf(theta0,theta1,cost_,levels,cmap='YlOrRd')
ax.set_xlabel('theta0')
ax.set_ylabel('theta1')
ax=fig.add_subplot(122,projection='3d')
ax.plot_surface(theta0,theta1,cost_,cmap='coolwarm',alpha=0.8)
ax.contour(theta0,theta1,cost_,levels,colors='k',linewidths=0.5)
ax.set_xlabel('theta0')
ax.set_ylabel('theta1')
ax.set_zlabel('cost')
ax.view_init(45,135)
![[python][机器学习][回归]线性回归_第4张图片](http://img.e-com-net.com/image/info10/82a270c13d9a42e3adb74ad8d550e445.jpg)
在线性回归中,有这么一种直接求最优解的优化方法:正规方程法,后面会提到,但在此处先介绍另一种更为通用的优化方法:梯度下降法。
梯度下降法具备更强的泛用性,在很多其他机器学习算法中也会用到,因为比起只有一个最小值,更多的情况是优化目标函数有多个极小值,而且特征往往也远不止一个,这种情况下直接求最优解会变得几乎不可能。因此,通过多次迭代优化逐步逼近极值点是更经济可行的做法,这种做法虽然不能保证得到最优解,但很多时候极优解带来的准确率已经足够让人满意了。这类优化算法不止梯度下降法一种,还有坐标下降法、牛顿法、拟牛顿法等,此处不做介绍。
审视一下上面重新绘制的函数图像,梯度下降法的思想很简单:选择合适的方向和速度,一步步走下山坡,直到局部最低点。代价函数的图像在参数与代价构成的数据空间中表现为低一维的“坡面”,具有至少一个局部最低点(在线性回归中只有一个全局最低点),当选取一个起始点后,可通过数学方法估计能够较快逼近局部最低点的移动方向和速度,然后不断迭代优化。
在只有一个参数的简单场景下(仅),通过微积分知识计算代价关于参数的导数,我们可以得出该参数应该增加还是减小,以及变化多少的参考量。当处于最低点左侧时,导数是负的,参数应该增大;当处于最低点右侧时,导数是正的,参数值应该减小;同时越接近最低点,导数的绝对值越小,这对应着一开始远离最低点时,参数值需要更快的改变,而接近最低点后,速度应该放缓以期获得稳定的结果。导数的绝对值只能给出一个变化量的参考值,因为导数所表示是自变量在趋向于0的极小变化量下因变量的变化趋势,而我们在进行优化时不可能一次只更新一个极小的量,那样太慢,所以一般会将负导数乘上一个学习率作为每次的更新量,通过控制学习率的大小来调整准确度与变化速度之间的平衡,学习率过大会导致变化过度,难以准确地收敛至极值点甚至离极值点原来越远,而学习率过小会导致优化速度很慢。
对求导,得到,此处使用了复合函数求导的链式法则,其中是关于的导数。然后每次迭代执行如下更新:,持续优化直至收敛到极值点(到什么程度算是收敛其实没有一个非常明确的标准,一般认为变化量小于一定的阈值,即继续更新对结果的影响微乎其微时,就可以认为是收敛了)。
学习率对优化效果的影响可以观察下面的示例:
x=np.linspace(0,10,20)
y=3*x1+np.random.randn(20)*5
theta_range=np.linspace(-7,13,21)
cost_range=[]
for t in theta_range:
cost_range.append(cost(linear(0,t,x),y))
cost_range=np.array(cost_range)
theta_=10
#单次优化
def optimize(theta,x,y,alpha):
p_y=linear(0,theta,x)
theta-=alpha*((p_y-y)*x).sum()/len(x)
return theta
#迭代优化
def train(theta,x,y,alpha,iters=10):
optimize_h=[theta]
for i in range(iters):
theta=optimize(theta,x,y,alpha)
optimize_h.append(theta)
return optimize_h
#绘制变化过程
def plot_change(alpha,axes):
axes.plot(theta_range,cost_range)
optimize_h=train(theta_,x,y,alpha)
for i in range(len(optimize_h)-1):
theta_1=optimize_h[i]
theta_2=optimize_h[i+1]
cost_1=cost(linear(0,theta_1,x),y)
cost_2=cost(linear(0,theta_2,x),y)
axes.plot([theta_1,theta_2],[cost_1,cost_2],c='r')
axes.scatter([theta_1,theta_2],[cost_1,cost_2],c='r',s=20)
axes.set_xlim([-8,14])
axes.set_ylim([-100,1900])
#不同学习率的更新
fig=plt.figure(figsize=(14,3))
ax=fig.add_subplot(141,title='alpha=0.001')
plot_change(0.001,ax)
ax=fig.add_subplot(142,title='alpha=0.01')
plot_change(0.01,ax)
ax=fig.add_subplot(143,title='alpha=0.05')
plot_change(0.05,ax)
ax=fig.add_subplot(144,title='alpha=0.06')
plot_change(0.06,ax)
![[python][机器学习][回归]线性回归_第5张图片](http://img.e-com-net.com/image/info10/94b706a2891540b7b11780cae6bb936d.jpg)
由图可知,该测试用例中学习率取0.001更新太慢,0.01比较合适,0.05偏大出现了振荡但依旧能收敛,0.06过大无法收敛。
现在再来看两个参数的情况(和),多元函数中因变量关于每个自变量的导数被称为偏导数,而所有偏导数组成的向量即是因变量关于自变量的梯度:,其中。多元函数在某点处的梯度向量指出了该点处函数值增长最快的方向,同时其模长能够体现增长量。在参数变多的情况下,我们要做的事情并没有复杂多少,只要根据当前位置的偏导数更新每一个对应的参数即可,每次迭代执行如下更新:。
梯度下降的实现代码如下:
def grad_desc(theta0,theta1,x1,y,alpha):
p_y=linear(theta0,theta1,x1)
theta0-=alpha*(p_y-y).sum()/len(y)
theta1-=alpha*((p_y-y)*x1).sum()/len(y)
return theta0,theta1
2. 随机梯度下降
上一小节中介绍的梯度下降法在每次计算梯度时都使用全部的训练样本,这被称为批量梯度下降,这种做法在数据量较大时计算梯度会变得很慢,迭代优化的速度也会因此变慢。
应对这种情况的一种方法就是使用随机梯度下降,每次优化只取用训练样本的一个随机子集,牺牲一定的准确度以大幅提高迭代速度(随机梯度下降一开始是指每次只使用一个训练样本的梯度下降,但后来都被用来指代使用随机子集的小批量梯度下降)。
为保证每个训练样本都被均匀的覆盖到,不采用每次都随机取n个样本的做法,而是每次将训练集随机排序并分割为大小n的子集,使用完所有子集算作一轮迭代,然后重复。子集的大小,常用的默认设置为200左右。
牺牲一定的准确度还带来另一个好处,在有多个极值点的数据空间中,往往还会存在很多鞍点,当批量梯度下降的起始点正好选取在鞍点的稳定方向上,就会导致最终收敛至鞍点而不是极值点,而随机梯度下降的优化方向会产生一些偏移,致使从不稳定方向上跌落鞍部。
至此,模型已经能够完成训练和预测,完整的实现代码和使用示例如下:
#线性回归
class LinearRegression:
def __init__(self,learning_rate=0.001,iter_max=100,batch_size=256):
self.learning_rate_=learning_rate
self.iter_max_=iter_max
self.batch_size_=batch_size
#初始化参数
def init_theta(self):
self.theta0_=0
self.theta1_=0
#假设函数
def linear(self,theta0,theta1,x1):
return theta0+theta1*x1
#代价函数
def cost(self,p_y,y):
return 0.5*np.power(y-p_y,2).mean()
#预测
def predict(self,x1):
return self.linear(self.theta0_,self.theta1_,x1)
#梯度下降
def grad_desc(self,theta0,theta1,x1,y,alpha):
p_y=self.linear(theta0,theta1,x1)
theta0-=alpha*(p_y-y).sum()/len(y)
theta1-=alpha*((p_y-y)*x1).sum()/len(y)
return theta0,theta1
#训练
def train(self,x1,y):
self.init_theta()
#子集数量
batches_n=math.ceil(len(y)/self.batch_size_)
#优化历史
self.theta_h_=[[self.theta0_,self.theta1_]]
self.cost_h_=[self.cost(self.predict(x1),y)]
#迭代
for i in range(self.iter_max_):
#随机排序
idx=np.random.permutation(len(y))
x1,y=x1[idx],y[idx]
#遍历子集
for j in range(batches_n):
x1_=x1[j*self.batch_size_:(j+1)*self.batch_size_]
y_=y[j*self.batch_size_:(j+1)*self.batch_size_]
self.theta0_,self.theta1_=self.grad_desc(
self.theta0_,self.theta1_,x1_,y_,self.learning_rate_
)
#记录当前参数和代价
self.theta_h_.append([self.theta0_,self.theta1_])
self.cost_h_.append(self.cost(self.predict(x1),y))
self.theta_h_=np.array(self.theta_h_)
self.cost_h_=np.array(self.cost_h_)
#R方
def r2(self,p_y,y):
SSE=(np.power(y-p_y,2)).sum()
SST=(np.power(y-y.mean(),2)).sum()
return 1-SSE/SST
#评分
def score(self,x1,y):
p_y=self.predict(x1)
return self.r2(p_y,y)
#使用示例
x1=np.linspace(0,10,50)
y=3*x1+2+np.random.randn(50)*5
model=LinearRegression()
model.train(x1,y)
plt.title("score: %f"%model.score(x1,y))
plt.scatter(x1,y)
plt.plot(x1,model.predict(x1),c='r')
plt.xlabel('x1')
plt.ylabel('y')
![[python][机器学习][回归]线性回归_第6张图片](http://img.e-com-net.com/image/info10/f3caf40275514e9696b36e91098d8e1f.jpg)
四. 多元回归与矩阵运算
1. 改进假设函数
现在我们的模型有一个很大的缺陷:只支持一个特征输入,如果需要支持更多的特征,按原本的写法需要增加更多独立的参数,但我们不确定具体使用时会有几个特征所以这种硬编码的方式是不可取的,更有效的做法是将参数向量化,简单地说就是以数组的形式存储。将参数向量化后,原本的许多运算就可以改写为矩阵运算的形式以进一步提升性能,numpy底层对矩阵运算做了充足的优化,在使用numpy时混杂大量对数组的循环遍历会发挥不出完整的性能。
可以说,凡是各元素相乘再整体求和的运算很大一部分都可以转换为矩阵运算。
假设函数的原写法:
#假设函数
def linear(self,theta0,theta1,x1):
return theta0+theta1*x1
原完整公式:,现在可以改写为矩阵形式:,其中,,对应样本数,对应特征数+1(额外增加了首列常数列),计算时按行取出每个样本的特征向量,与作点积,整个运算返回一个长度的预测值向量。值得一提的是,此处的写法和常见的写法略有不同,可能这样的形式更常见,区别在于此处给出的是作用于数据集的公式,且为了保持行对应记录、列对应属性这样的数据格式,没有对进行转置,而相应的,公式中作矩阵乘法的前后两项就颠倒了。
另一种写法是,其中,,对应样本数,对应特征数,是标量,和分别是权重和偏置的意思,这种写法在神经网络中普遍使用,在优化时需要将和分开处理。
此处为了和后面正规方程法的处理方式统一,将采用第一种形式,需要对填充常量列。
改进后的代码如下:
#初始化参数
def init_theta(self,m):
self.theta_=np.zeros(m)
#填充常量列
def fill_x0(self,X):
return np.insert(X,0,1,axis=1)
#假设函数
def linear(self,X,theta):
return np.dot(X,theta)
代价函数以预测值和真实值作为输入,因而不需要改动,但可以稍作调整以适应批量计算。
2. 改进梯度下降
原先梯度计算公式的一般形式为:,改写为矩阵形式为。
关于矩阵式如何写有个较为简单的思考方式,就是观察形状,形状的变化遵循如下规则(两个矩阵相乘时,左矩阵的第二个维度和右矩阵的第一个维度会作为抽取向量的维度,最终会有个组合,而每组向量在执行点积后会收缩为标量),比如此处应当是一个长度的向量(与长度相同,是特征数+1),而是的矩阵,和均为长度的向量,如此一来,应当沿长度的维度抽取向量,或都是可行的转换,上面即是采用了第二种。
每次迭代执行如下优化:,改进后的完整代码和使用示例如下:
#线性回归
class LinearRegression:
def __init__(self,learning_rate=0.001,iter_max=100,batch_size=256):
self.learning_rate_=learning_rate
self.iter_max_=iter_max
self.batch_size_=batch_size
#初始化参数
def init_theta(self,m):
self.theta_=np.zeros(m)
#填充常量列
def fill_x0(self,X):
return np.insert(X,0,1,axis=1)
#假设函数
def linear(self,X,theta):
if X.shape[1]==theta.shape[0]-1:
return np.dot(X,theta[1:])+theta[0]
else:
return np.dot(X,theta)
#代价函数
def cost(self,p_y,y):
return 0.5*np.power(y-p_y,2).mean(axis=0)
#预测
def predict(self,X):
return self.linear(X,self.theta_)
#梯度下降
def grad_desc(self,X,y,theta,alpha):
p_y=self.linear(X,theta)
theta-=alpha*np.dot(X.T,p_y-y)/len(y)
#训练
def train(self,X,y):
X=self.fill_x0(X)
self.init_theta(X.shape[1])
#子集数量
batches_n=math.ceil(len(y)/self.batch_size_)
#优化历史
self.theta_h_=[self.theta_]
self.cost_h_=[self.cost(self.predict(X),y)]
#迭代
for i in range(self.iter_max_):
#随机排序
idx=np.random.permutation(len(y))
X,y=X[idx],y[idx]
#遍历子集
for j in range(batches_n):
X_=X[j*self.batch_size_:(j+1)*self.batch_size_]
y_=y[j*self.batch_size_:(j+1)*self.batch_size_]
self.grad_desc(
X_,y_,self.theta_,self.learning_rate_
)
#记录当前参数和代价
self.theta_h_.append(self.theta_)
self.cost_h_.append(self.cost(self.predict(X),y))
self.theta_h_=np.array(self.theta_h_)
self.cost_h_=np.array(self.cost_h_)
#R方
def r2(self,p_y,y):
SSE=(np.power(y-p_y,2)).sum()
SST=(np.power(y-y.mean(),2)).sum()
return 1-SSE/SST
#评分
def score(self,X,y):
p_y=self.predict(X)
return self.r2(p_y,y)
#使用示例
X=np.random.randn(1000,10)
y=np.full(1000,10)+np.random.randn(1000)*5
for i in range(X.shape[1]):
y=y+(i+1)*X[:,i]
model=LinearRegression(learning_rate=0.1)
model.train(X,y)
plt.title("score: %f"%model.score(X,y))
plt.plot(range(len(model.cost_h_)),model.cost_h_,c='r')
plt.xlabel('iter')
plt.ylabel('cost')
![[python][机器学习][回归]线性回归_第7张图片](http://img.e-com-net.com/image/info10/2cfea87e2dfd4265bec10345c97fa085.jpg)
3. 特征归一化
现在我们改用真实数据集看一下模型的效果如何,这里将会使用波士顿房价数据集,该数据集通过sklearn也可加载。
#使用示例:波士顿房价数据集
f = open('D:\\training_data\\used\\boston_house_price.txt')
buf = pd.read_table(f,header=None,delim_whitespace=True)
buf.columns=['CRIM','ZN','INDUS','CHAS','NOX','RM','AGE','DIS',
'RAD','TAX','PTRATIO','B','LSTAT','MEDV']
X,y=buf.values[:,:-1],buf.values[:,-1]
model=LinearRegression(learning_rate=1e-6,iter_max=10000)
model.train(X,y)
plt.title("score: %f"%model.score(X,y))
plt.plot(range(len(model.cost_h_)),model.cost_h_,c='r')
plt.xlabel('iter')
plt.ylabel('cost')
![[python][机器学习][回归]线性回归_第8张图片](http://img.e-com-net.com/image/info10/334e8b06adc14bef9ea37962811479fd.jpg)
然后发现结果并不如预期,学习率非常不好控制,要么无法收敛,要么优化极其缓慢,无论怎么调整,评分都没法达到较高的水准,这是为什么?
其实是不同特征取值范围的差异导致的。回想一下梯度下降的公式,在计算时每个样本的误差都乘上了,这样得到的梯度在方向上的分量大小会与特征的取值范围相关,取值范围大的特征对应的梯度分量也总是较大。
我们可以选取数据集中两个取值范围差异较大的特征来观察一下cost的分布特点和优化过程:
#选取两个特征
X_=X[:,[0,-2]]
#cost分布(这里的计算使用了一些矩阵运算的技巧)
theta1=np.linspace(-20,40,100)
theta2=np.linspace(-20,20,100)
theta1,theta2=np.meshgrid(theta1,theta2)
theta=np.r_[theta1.reshape((1,-1)),theta2.reshape((1,-1))]
p_y=model.linear(X_,theta)
cost_=model.cost(p_y.T,y).reshape((100,100))
def mixed_plot(ax,learning_rate,theta_start=[30.,-15.]):
ax.set_title('learning_rate: %f'%learning_rate)
#cost等高线图
c=ax.contour(theta1,theta2,cost_,colors='k',linewidths=0.5)
ax.set_xlabel('theta1')
ax.set_ylabel('theta2')
#cost最小值
theta1_min=theta1.ravel()[cost_.argmin()]
theta2_min=theta2.ravel()[cost_.argmin()]
ax.scatter(theta1_min,theta2_min,s=100,c='r',marker='*')
#cost变化
theta=np.array(theta_start)
for i in range(100):
theta_old=theta.copy()
model.grad_desc(X_,y,theta,alpha=learning_rate)
ax.plot([theta_old[0],theta[0]],
[theta_old[1],theta[1]])
fig=plt.figure(figsize=(9,3))
ax=fig.add_subplot(121)
mixed_plot(ax,1e-6)
ax=fig.add_subplot(122)
mixed_plot(ax,1.4e-5)
![[python][机器学习][回归]线性回归_第9张图片](http://img.e-com-net.com/image/info10/20a42605d58440beb55f2649fe50c805.png)
两个特征和,的取值范围更大,从等高线图中可以看出,对应的方向上坡面更陡峭,带来的结果是方向上的梯度分量总是偏大。如果我们的起点在方向上距最低点较远时,问题就来了:一开始取用较小的学习率,我们可能会发现在方向上优化得太慢,而方向很快地收敛了,然后开始调大学习率,方向上的优化速度尚未达到满意值,学习率对而言却已经过大了,再增加下去方向上就无法正常收敛。
而解决这个问题最简单好用的办法就是将特征缩放到同样的取值范围,一般长度为1的区间,也称特征归一化,这样梯度在各方向上的分量就不容易出现差异过大的情况。归一化改变了特征的量纲,但却保留了数值的大小关系,不会因此导致模型不能正常训练。
归一化有多种方式,此处会采用最大最小值归一化的方式,公式为,是所有样本的特征组成的向量,和是缩放的参考值,一般是由训练集数据计算得到,应当保存下来,预测时也用该参考值进行归一化,因为之后如果基于用于预测的数据重新计算参考值,可能会出现同样的数值缩放后和训练时不一致的情况。
代码实现以及上方示例的重新测试:
#缩放参照统计量
def scaling_ref(X):
ref=pd.DataFrame()
ref['min']=X.min(axis=0)
ref['max']=X.max(axis=0)
return ref
#最大最小值缩放
def minmax_scaling(X,ref):
return (X-ref['min'].values)/(ref['max']-ref['min']).values
#执行特征缩放
ref=scaling_ref(X_)
X_=minmax_scaling(X_,ref)
theta1=np.linspace(-40,80,100)
theta2=np.linspace(-15,65,100)
theta1,theta2=np.meshgrid(theta1,theta2)
theta=np.r_[theta1.reshape((1,-1)),theta2.reshape((1,-1))]
p_y=model.linear(X_,theta)
cost_=model.cost(p_y.T,y).reshape((100,100))
fig=plt.figure(figsize=(9,3))
ax=fig.add_subplot(121)
mixed_plot(ax,1,[50.,0.])
ax=fig.add_subplot(122)
mixed_plot(ax,2.2,[50.,0.])
![[python][机器学习][回归]线性回归_第10张图片](http://img.e-com-net.com/image/info10/f0bfd62fc7694c2bb321911f723d3588.jpg)
可以看到,学习率相对容易设置了,优化的速度也快了很多,虽然未能达到最理想的状态(即等高线轮廓是圆形)。这主要是因为特征的取值范围不是唯一影响梯度整体大小的原因,特征对预测值的重要性也会影响。由图可以看出,特征1的重要性是不如特征2的,如果将优化后的输出,会发现的绝对值要小于,两者相吻合。
重新测试房价数据:
X,y=buf.values[:,:-1],buf.values[:,-1]
ref=scaling_ref(X)
X=minmax_scaling(X,ref)
model=LinearRegression(learning_rate=0.3,iter_max=1000)
model.train(X,y)
plt.title("score: %f"%model.score(X,y))
plt.plot(range(len(model.cost_h_)),model.cost_h_,c='r')
plt.xlabel('iter')
plt.ylabel('cost')
![[python][机器学习][回归]线性回归_第11张图片](http://img.e-com-net.com/image/info10/b685343c05cd425797e787d28a13a0d3.jpg)
这一次我们得到了理想的结果。
五. 正规方程法优化
1. 矩阵求解线性方程组
下面介绍之前提到过的,用于线性回归一次性求解的优化方法。该方法实际上是基于用矩阵解线性方程组的思想,一种线性代数的常见应用方式。
有如下一个方程组,可以将其转换为矩阵表达:
那么该如何求解呢?通过线性代数的知识我们可以知道,如果一个向量经过一个矩阵变换后得到另一个向量,那么只要对得到的向量进行逆矩阵变换就可以还原为原向量。
2. 正规方程法求解参数
正规方程法之所以可用是基于两个事实:线性回归的代价函数仅有一个最小值;极值点处所有自变量的偏导数都为0。基于以上事实可以构建如下线性方程组:
梯度的矩阵计算式前面有给出过,只要让其等于0向量就行了。下面是求解的方式:
正规方程求解的开销主要在矩阵的求逆,稠密矩阵求逆的复杂度为,其中在此处为特征数,也就是在特征数量很多的情况下,使用正规方程求解开销会很大,而且另一个问题是矩阵的逆可能不存在,这对应着方程组是无解的,这种情况大多是由于存在无用的特征。在特征数不多的情况下,用正规方程求解是一个很好的选择。
正规方程法的代码实现:
#添加进线性回归类
class LinearRegression:
#正规方程
def norm_equa(self,X,y):
return np.dot(np.linalg.inv(np.dot(X.T,X)),np.dot(X.T,y))
#训练
def train_ne(self,X,y):
X=self.fill_x0(X)
self.theta_=self.norm_equa(X,y)
model=LinearRegression()
model.train_ne(X,y)
print("score: %f"%model.score(X,y))
#与sklearn对照
from sklearn.linear_model import LinearRegression
sk_model = LinearRegression()
sk_model.fit(X,y)
print("sklearn score: %f"%sk_model.score(X,y))
score: 0.740643
sklearn score: 0.740643
与sklearn的线性回归对照,结果是一样的。使用正规方程求解时无需进行特征归一化。
六. 非线性化
1. 将非线性转换为线性
到现在为止,我们一直都在假设特征与预测值之间的关系是线性的,但实际情况是,非线性关系往往远多于线性关系,那我们的模型能够处理非线性问题吗?
线性回归模型本身是没有处理非线性问题的能力的,但是我们可以使用数学上常见的手法:转换,将非线性问题转换为线性的。譬如如下的关系,很明显,与的关系是非线性的,它的函数图像不会是一条直线的,但是,如果将和看作自变量和,那自变量与因变量的关系就成了,显然是线性的,那我们只要基于这个式子求解线性回归参数,之后模型进行预测时也采用同样的手法转换就行了。
2. 多项式特征映射
那么该如何去选择映射的函数呢?非线性函数有无数种,不可能将所有可能都尝试一遍,而是要选择尽可能简单通用的映射规则,我们无法去猜测真实的关系中存在哪些非线性函数,但应该保证我们所选的规则能够随着映射规模的拓展,实现对原关系越来越好的近似。
多项式映射是最常用的一种规则,其有效性从泰勒公式就可以看出,理论上是可以无限近似任意非线性关系的。该映射的规则就是计算出最高次的多项式的所有项,映射后的特征数量为,比如有特征,最高次为的映射应为。
多项式特征映射的代码如下:
#多项式映射
def polynomial_mapping(X,h,cross=True,size_limit=1e8):
#样本数和特征数
n,m=X.shape[0],X.shape[1]
#映射后特征数
if cross==True:
m_new=m*(m**h-1)//(m-1)
else:
m_new=m*h
#检查映射数量是否过于庞大
if m_new*X.shape[0]>size_limit:
raise Exception("The array size after mapping is over limit.")
#根据是否含组合项用不同的方式处理
mapping=np.zeros((n,m_new))
if cross==True:
#指数序列
exponent=[np.zeros(m)]
j_new=0
while len(exponent)>0:
buf=exponent.pop(0)
#达到次数上限
if buf.sum()>=h:
continue
#每次在上一轮的指数序列上取一位+1
for j in range(m):
exponent_=buf.copy()
exponent_[j]+=1
exponent.append(exponent_)
mapping[:,j_new]=np.power(X,exponent_).prod(axis=1)
j_new+=1
else:
for j in range(m):
for k in range(h):
mapping[:,k*m+j]=np.power(X[:,j],k+1)
return mapping
多项式特征映射最大的问题在于随着最高次的提升,完整映射后的特征数量会爆炸式的增长,这个缺陷限制了线性回归模型在处理非线性问题上的能力。为提高可用性,可以提供一个不生成不同特征之间组合项的选项,用于生成不完整的映射,因为可能恰好当前数据就不侧重组合项关系,这时如果还不得不生成完整的映射就会带来不必要的困难。
为了更清楚的看到特征映射的效果,下面会使用随机生成的简单数据集测试:
x=(np.random.rand(50)-0.5)*6
x=np.sort(x)
y=np.sin(x)+np.cos(x)+np.random.randn(50)*0.2
X=x.reshape((-1,1))
def subplot(ax,h):
X_=polynomial_mapping(X,h,False)
model.train_ne(X_,y)
ax.set_title('h=%d, score=%f'%(h,model.score(X_,y)))
ax.scatter(x,y)
ax.plot(x,model.predict(X_),c='r')
ax.set_xlabel('x')
ax.set_ylabel('y')
fig=plt.figure(figsize=(13.5,3))
ax=fig.add_subplot(131)
subplot(ax,h=1)
ax=fig.add_subplot(132)
subplot(ax,h=2)
ax=fig.add_subplot(133)
subplot(ax,h=3)
![[python][机器学习][回归]线性回归_第12张图片](http://img.e-com-net.com/image/info10/c82e6b742a3a443986d37f19212db2d1.jpg)
原函数是由三角函数组成的,并不包含多项式,但是却能通过多项式去近似,随着映射最高次的不断提高,预测结果也越来越接近原函数。
注意,如果在多项式映射后用梯度下降求解,需要进行特征归一化,因为特征的取值范围差距在映射后会变得更大。
七. 过拟合问题
1. 交叉验证
前面的内容中,我们在训练和测试模型时都使用了同一个数据集,这会陷入一个误区,我们会误以为模型的效果已经足够好了,但我们的模型在投入使用后处理的都是新的数据,如果在新的数据上表现得很差,就没有意义了。我们需要将训练和测试用的数据拆分开来,用训练集去训练,然后用测试集去评估,这样才能正确地评判模型的好坏,这种做法称为交叉验证。
最常用的拆分方式是8:2拆分,原始数据抽取4/5作为训练集,1/5作为测试集。当然,为了避免偶然性,有更严谨的方式:k折交叉验证,即将数据集平均分为k份,每次取其中一份作为测试集,其余作为训练集,然后训练模型,最后在所有组合中选择效果最好的。实际使用时用哪种方式取决于项目的时间和对准确度的要求。
下面是八二分的代码实现(numpy和pandas两个版本):
#numpy
def split_train_test(X,y,frac=0.8):
idx=np.arange(y.shape[0])
test_size=int(y.shape[0]*(1-frac))
test_idx=np.random.choice(idx,size=test_size,replace=False)
train_idx=idx[~np.isin(idx,test_idx)]
train_X,train_y=X[train_idx],y[train_idx]
test_X,test_y=X[test_idx],y[test_idx]
return train_X,train_y,test_X,test_y
#pandas
def split_train_test(X,y,frac=0.8):
train_X=X.sample(frac=frac)
test_X=X[~X.index.isin(train_X.index)]
train_y,test_y=y[train_X.index],y[test_X.index]
return train_X,train_y,test_X,test_y
重新在房价数据集上测试:
X,y=buf.values[:,:-1],buf.values[:,-1]
train_X,train_y,test_X,test_y=split_train_test(X,y)
ref=scaling_ref(train_X)
train_X=minmax_scaling(train_X,ref)
test_X=minmax_scaling(test_X,ref)
model.train_ne(train_X,train_y)
print("train score: %f"%model.score(train_X,train_y))
print("test score: %f"%model.score(test_X,test_y))
train score: 0.753238
test score: 0.656748
可见,之前大于0.7的score只是假象,在新数据上并没有那么高。
2. 欠拟合与过拟合
在前一章节提到了多项式映射,当准备对一个数据集执行映射时,我们其实并不知道将最高次设为多少才是合适的,为了追求更好的非线性近似,可能会把最高次设置得尽可能大。而结合上一小节的交叉验证,会发现另一个问题的存在:
x=(np.random.rand(10)-0.5)*6
x=np.sort(x)
y=np.sin(x)+np.cos(x)+np.random.randn(10)*0.4
X=x.reshape((-1,1))
x_range=np.linspace(-3,3,100)
X_range=x_range.reshape((-1,1))
test_x=(np.random.rand(10)-0.5)*6
test_y=np.sin(test_x)+np.cos(test_x)+np.random.randn(10)*0.4
test_X=test_x.reshape((-1,1))
def subplot(ax,h):
X_=polynomial_mapping(X,h,False)
test_X_=polynomial_mapping(test_X,h,False)
X_range_=polynomial_mapping(X_range,h,False)
model.train_ne(X_,y)
ax.set_title('h=%d\ntrain score=%f\ntest score=%f'%(
h,model.score(X_,y),model.score(test_X_,test_y)))
ax.scatter(x,y)
ax.plot(x_range,model.predict(X_range_),c='r')
ax.set_xlabel('x')
ax.set_ylabel('y')
fig=plt.figure(figsize=(13.5,3))
ax=fig.add_subplot(131)
subplot(ax,h=1)
ax=fig.add_subplot(132)
subplot(ax,h=3)
ax=fig.add_subplot(133)
subplot(ax,h=5)
![[python][机器学习][回归]线性回归_第13张图片](http://img.e-com-net.com/image/info10/ea298c8c58af461fa6fc30907c8ddb65.jpg)
三张图的情况分别对应了:欠拟合、正常拟合、过拟合。
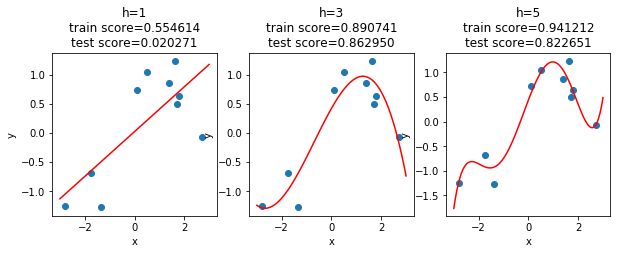
可以看到,一开始增加最高次时,训练集和测试集的score都在提升,而到某个临界点后,再增加,只有训练集的score提升,测试集的score反而下降了(由于数据集是随机生成的,如果没有看到上图的情况可以多执行几次)。至于这其中的原因,从图中可以看出端倪,在时,曲线尝试穿过每一个训练集的点,似乎在强行记住每一个点的位置,这种做法显然有些极端了,不具备容错性,时的曲线反而更合适。当训练一个模型时,应当期望它去寻找数据中的普遍规律,使得在面对新的数据时具备足够强的泛化能力,而不是仅仅记住训练数据。
避免过拟合有多种方式:
第一种是增加训练集大小,数据点越多,曲线就越难穿过每一个点,迫使模型去寻找一个更普适的函数,但数据集并不是那么好收集的,往往条件受限没法做到这点;
第二种是根据模型的复杂度在代价函数中增加惩罚项,以在准确率和复杂度之间寻求平衡;
第三种是设置优化停止阈值,只适用于迭代优化,当代价变化量小于一个指定值时或是测试集评分持续多轮没有提升就提前结束优化,迭代优化到过拟合是有一个过程的,只要在此之前停止就行了。
注意,特征映射越复杂,越可能出现过拟合,越不容易欠拟合,在不执行映射的线性模式下,过拟合的可能性很低。
3. L2正则化
正则化是一种在代价函数中增加惩罚项以避免过拟合的技巧,常用的有L1和L2两种正则化方式。L1正则化(或称L1范数)是对参数的绝对值求和,公式为,但是由于绝对值是非连续可导函数,使用L1正则化后会导致无法使用梯度下降法优化,所以这里不采用;L2正则化(或称L2范数)是对参数的平方求和,公式为。
无论是L1还是L2正则化,都是在把参数的整体大小作为惩罚项,并通过一个额外的变量来控制该惩罚项的重要性,但为什么参数的整体大小能够表示模型的复杂度呢?对此本人也没有深入的研究,但简单些说,当一个模型的非线性表达能力很强时,它往往需要更多、更大的参数来完成这种表达,多项式映射模式下,当模型优先采用高次项时,不光高次项要采用相对较大的参数,低次项也要使用更大的参数去微调函数的形态。上一小节中如果将不同下的最终正则化值输出就会发现,越大,正则化值也越大。
加入L2正则化后由于代价函数发生了改变,优化算法也要重新推导。
代价函数:
梯度下降:
正规方程:
改进代码如下:
#修改线性回归类
class LinearRegression:
def __init__(self,learning_rate=0.001,iter_max=100,batch_size=256,l2_lambda=0.001):
self.learning_rate_=learning_rate
self.iter_max_=iter_max
self.batch_size_=batch_size
self.l2_lambda_=l2_lambda
#代价函数
def cost(self,p_y,y):
return 0.5*np.power(p_y-y,2).mean(axis=-1)\
+0.5*self.l2_lambda_*np.power(self.theta_,2).sum()
#梯度下降
def grad_desc(self,X,y,theta,alpha):
p_y=self.linear(X,theta)
theta-=alpha*self.l2_lambda_*theta
theta-=alpha*np.dot(X.T,p_y-y)/len(y)
#正规方程
def norm_equa(self,X,y):
I=np.eye(X.shape[1])
return np.dot(np.linalg.inv(np.dot(X.T,X)+self.l2_lambda_*I*len(y)),np.dot(X.T,y))
重新进行测试:
model=LinearRegression(l2_lambda=0.0)
fig=plt.figure(figsize=(10,3))
ax=fig.add_subplot(131)
subplot(ax,h=1)
ax=fig.add_subplot(132)
subplot(ax,h=3)
ax=fig.add_subplot(133)
subplot(ax,h=5)
model=LinearRegression(l2_lambda=0.01)
fig=plt.figure(figsize=(10,3))
ax=fig.add_subplot(131)
subplot(ax,h=1)
ax=fig.add_subplot(132)
subplot(ax,h=3)
ax=fig.add_subplot(133)
subplot(ax,h=5)
![[python][机器学习][回归]线性回归_第14张图片](http://img.e-com-net.com/image/info10/716827b3cc51492abe64e8624f465fc8.jpg)
显然,L2正则化对避免过拟合是有帮助的,时的测试集准确率提升了。但是要注意的是,这不意味着高次+正则化就一定得到更好的结果,就此处的例子而言,得到的结果最好,模型尚未过拟合时,使用正则化反而可能会降低准确率。正则化的作用在于你可以更放心地假设数据存在复杂的非线性关系而不容易陷入过拟合的陷阱。
4. 提前终止
另一种避免过拟合的方法,只能用于梯度下降这类迭代优化算法中,就是设置提前终止优化的条件。这也是一种节省训练时间的方式,可以减少模型在低效优化上耗费的时间。一般可针对两种指标设置结束条件:一是代价变化量,当该变化量小于一定值时我们可以认为它已经接近极值点了所以梯度逐渐平缓;二是测试集的评分连续几轮迭代都没有提升。这两种情况再继续优化对模型表现的提升很有限还容易陷入过拟合,提前结束反而能节省大量时间。
因为第一种方法需要频繁的调整阈值,个人更喜欢第二种,以下是实现代码:
#在线性回归类中修改
class LinearRegression:
def __init__(self,learning_rate=0.001,iter_max=100,batch_size=256,
l2_lambda=0.001,early_stop=True):
self.learning_rate_=learning_rate
self.iter_max_=iter_max
self.batch_size_=batch_size
self.l2_lambda_=l2_lambda
self.early_stop_=early_stop
#训练
def train(self,X,y,test_X=None,test_y=None):
#提前终止机制需要提供test_X,test_y
if self.early_stop_&(type(test_X)==type(None))|(type(test_y)==type(None)):
raise Exception('test_X and test_y can not be None for early stopping')
#初始化
X=self.fill_x0(X)
self.init_theta(X.shape[1])
#子集数量
batches_n=math.ceil(len(y)/self.batch_size_)
#优化历史
self.theta_h_=[self.theta_.copy()]
if self.early_stop_:
not_improved=0
theta_best=self.theta_.copy()
score_best=self.score(test_X,test_y)
self.cost_h_=[[self.cost(self.predict(X),y),
self.cost(self.predict(test_X),test_y)]]
else:
self.cost_h_=[self.cost(self.predict(X),y)]
#迭代
for i in range(self.iter_max_):
#随机排序
idx=np.random.permutation(len(y))
X,y=X[idx],y[idx]
#遍历子集
for j in range(batches_n):
X_=X[j*self.batch_size_:(j+1)*self.batch_size_]
y_=y[j*self.batch_size_:(j+1)*self.batch_size_]
self.grad_desc(
X_,y_,self.theta_,self.learning_rate_
)
#记录当前参数和代价
self.theta_h_.append(self.theta_.copy())
#提前停止
if self.early_stop_:
self.cost_h_.append([self.cost(self.predict(X),y),
self.cost(self.predict(test_X),test_y)])
score_new=self.score(test_X,test_y)
if score_new<=score_best:
not_improved+=1
else:
not_improved=0
theta_best=self.theta_.copy()
score_best=score_new
if not_improved>=10:
self.theta_=theta_best
print("Early stopping at iter %d!"%(i+1))
break
else:
self.cost_h_.append(self.cost(self.predict(X),y))
self.theta_h_=np.array(self.theta_h_)
self.cost_h_=np.array(self.cost_h_)
最后再在房价数据集上做一次测试:
X,y=buf.values[:,:-1],buf.values[:,-1]
ref=scaling_ref(X)
X=minmax_scaling(X,ref)
train_X,train_y,test_X,test_y=split_train_test(X,y)
model=LinearRegression(learning_rate=0.3,iter_max=1000,
l2_lambda=0.001,early_stop=True)
model.train(train_X,train_y,test_X,test_y)
plt.title("train score: %f\ntest score: %f"%(
model.score(train_X,train_y),
model.score(test_X,test_y)
))
plt.plot(range(len(model.cost_h_)),model.cost_h_[:,0],label='train')
plt.plot(range(len(model.cost_h_)),model.cost_h_[:,1],label='test')
plt.xlabel('iter')
plt.ylabel('cost')
Early stopping at iter 164!
![[python][机器学习][回归]线性回归_第15张图片](http://img.e-com-net.com/image/info10/1f28a832b724413295cdd81d34dbf223.jpg)
由于房价数据的非线性关系不明显,所以就没有做特征映射。即使抛开防止过拟合的作用,提前终止在节省计算时间上的效果也是很重要的,没有过拟合的风险不代表该机制就没有用。