String StringBuilder StringBuffer区别以及源码分析
1. String/StringBuilder/StringBuffer 区别
1.1 String
String 对象一旦创建之后就是不可变的,不可变的!
问题:既然String 对象是不可变的,那么其包含的常用修改值的方法是如何实现的呢?
Demo
substring(int,int) 字符串截取
split(String,int) 字符串分割
toLowerCase() 字符串所有字母小写
...
其实,这些方法底层都是通过重新创建一个String 对象来接收变动后的字符串,而最初的 String 对象并未发生改动!
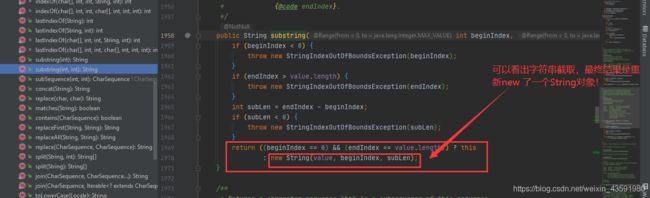
注意点(重要)
我们经常使用 String 字符串进行 + 或者 += 操作,来改变字符串的值,这种情况比较特殊!
首先在JAVA中+ 和 += 是仅有的两个重载过的操作符,在进行字符串相加时候其String 对象并未发生改变,而是值发生改变了!
案例1:
String str = "Hello" + "Wrold";
使用javap 命令对其进行反编译后得到如下代码:
str = new StringBuilder("Hello").append("Wrold").toString();
结论:从上面案例得出,String 字符串+ 的操作,底层其实是通过 StringBuilder 执行的!
从效率角度触发,在大部分情况下,使用 + 连接字符串并不会造成效率上的损失,而且还可以提高程序的易读性和简洁度!
案例2:
String str = "0";
String append = "1";
for(int i = 0; i < 10000; i++){
// 结果为:str = 011111.......(很多1)
str += append;
}
这种情况下,如果反编译的话,得到的是如下代码:
...
for(int i = 0; i < 10000; i++){
// 结果为:str = 011111.......(很多1)
str = (new StringBuilder()).append(str).append(append).toString();
}
这种情况下,由于大量 StringBuilder 创建在堆内存中,肯定会造成效率的损失,所以在这种情况下建议在循环体外创建一个 StringBuilder 对象调用 append() 方法手动拼接!
案例3:
除了上面两种情况,我们再来分析一种特殊情况,即:
当+ 两端均为字符串常量(此时指的是"xxx" 而不是final修饰的String对象)时,在编译过后会直接拼接好,例如:
System.out.println("Hello" + "World");
反编译后变为:
System.out.println("HelloWorld");
这样的情况下通过+拼接字符串效率是最佳的!
1.2 StringBuilder
StringBulider 是一个可变的字符串类!可以把它看作是一个容器。
- StringBuilder 可以通过
toString()方法转换成 String - String 可以通过 StringBuilder 的构造方法,转换成 StringBuilder
eg:
String string = new StringBuffer().toString();
StringBulider stringBuilder = new StringBulider(new String());
StringBuilder 拼接字符串的效率较高,但是它不是线程安全的!
1.3 StringBuffer
StringBuffer 同样是一个可变的字符串类!也可以被看作是一个容器。
- StringBuffer 可以通过
toString()方法转换成 String - String 可以通过 StringBuffer 的构造方法,转换成 StringBuffer
eg:
String string = new StringBuffer().toString();
StringBuffer stringBuffer = new StringBuffer(new String());
Stringbuffer拼接字符串的效率相对于 StringBuilder 较低,但是它是线程安全的!
2. String/StringBuilder/StringBuffer 源码
2.1 String 源码分析
2.1.1 String 类
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
...
}
- 首先从代码可以看出,String 类被final 关键字修饰,该类不能被继承!
- String 还实现了
Serializable ,Comparable等接口,能够被序列化,支持字符串判等比较,且是 一个 char 值的可读序列, CharSequence - Comparable 接口有
compareTo(String s)方法,CharSequence 接口有length(),charAt(int index),subSequence(int start,int end)方法。
2.1.2 String 类的属性
// 不可变的char数组用来存放字符串,说明其是不可变量.
private final char value[];
// int型的变量hash用来存放计算后的哈希值.
private int hash; // 默认为0
// 序列化版本号
private static final long serialVersionUID = -6849794470754667710L;
2.1.3 String 类的构造函数
// 不含参数的构造函数,一般没什么用,因为 value 是不可变量
public String() {
this.value = "".value;// "",注意不是null
//this.value = new char[0]; jdk1.8之前的写法
}
// 参数为String类型的构造函数
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
// 参数为char数组,使用java.utils包中的Arrays类复制
public String(char value[]) {
this.value = Arrays.copyOf(value, value.length);
}
// 调用public String(byte bytes[], int offset, int length, String charsetName)构造函数
public String(byte bytes[], String charsetName)
throws UnsupportedEncodingException {
this(bytes, 0, bytes.length, charsetName);
}
public String(byte bytes[], int offset, int length, String charsetName)
throws UnsupportedEncodingException {
if (charsetName == null)
throw new NullPointerException("charsetName");
checkBounds(bytes, offset, length);
this.value = StringCoding.decode(charsetName, bytes, offset, length);
}
还有其他的构造方法,可以自己点入String 详细阅读...
2.1.4 String 类的常用方法
简单方法
// 字符串长度
public int length() {
return value.length;
}
// 字符串是否为空
public boolean isEmpty() {
return value.length == 0;
}
// 根据下标获取字符数组对应位置的字符
public char charAt(int index) {
if ((index < 0) || (index >= value.length)) {
throw new StringIndexOutOfBoundsException(index);
}
return value[index];
}
// 得到字节数组
public byte[] getBytes() {
return StringCoding.encode(value, 0, value.length);
}
重点方法
equals(Object anObject)
// 两个对象之间判等
public boolean equals(Object anObject) {
// 如果引用的是同一个对象,返回true
if (this == anObject) {
return true;
}
// 如果不是String类型的数据,返回false
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
// 如果char数组长度不相等,返回false
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
// 从后往前单个字符判断,如果有不相等,返回false
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
该方法判等规则:
- 如果二者内存地址相同,则为true
- 如果对象类型不是String 类型,则为false,如果是就继续进行判等
- 如果对象字符长度不相等,则为false,如果相等就继续进行判等
- 从后往前,判断 String 类中char 数组 value 的单个字符是否相等,有不相等则为false。如果一直相等直到第一个数,则返回true
结论:根据判等规则得出,如果两个超长的字符串进行比较,是非常费时间的!
hashCode()
// 返回此字符串的哈希码
public int hashCode() {
int h = hash;
// 如果hash没有被计算过,并且字符串不为空,则进行hashCode计算
if (h == 0 && value.length > 0) {
char val[] = value;
//计算过程
//val[0]*31^(n-1) + val[1]*31^(n-2) + ... + val[n-1]
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
String 类重写了hashCode方法,Object中的hashCode方法是一个Native调用。String类的hash采用多项式计算得来,我们完全可以通过不相同的字符串得出同样的hash,所以两个String对象的hashCode相同,并不代表两个String是一样的。
那么计算hash值的时候为什么要使用31 作为基数呢?
先要明白为什么需要HashCode.每个对象根据值计算HashCode,这个code大小虽然不奢求必须唯一(因为这样通常计算会非常慢),但是要尽可能的不要重复,因此基数要尽量的大。另外,31N可以被编译器优化为左移5位后减1即31N = (N<<5)-1,有较高的性能。使用31的原因可能是为了更好的分配hash地址,并且31只占用5bits!
结论:
- 基数要用质数:质数的特性(只有1和自己是因子)能够使得它和其他数相乘后得到的结果比其他方式更容易产成唯一性,也就是Hash Code值的冲突概率最小。
- 选择31是观测哈希值分布结果后的一个选择,不清楚原因,但的确有利(更分散,减少冲突)。
compareTo(String anotherString)
// 按字典顺序比较两个字符串,比较是基于字符串中每个字符的Unicode值
public int compareTo(String anotherString) {
// 自身对象字符串长度len1
int len1 = value.length;
// 被比较对象字符串长度len2
int len2 = anotherString.value.length;
// 取两个字符串长度的最小值lim
int lim = Math.min(len1, len2);
char v1[] = value;
char v2[] = anotherString.value;
int k = 0;
// 从value的第一个字符开始到最小长度lim处为止,如果字符不相等,返回自身(对象不相等处字符-被比较对象不相等字符)
while (k < lim) {
char c1 = v1[k];
char c2 = v2[k];
if (c1 != c2) {
return c1 - c2;
}
k++;
}
// 如果前面都相等,则返回(自身长度-被比较对象长度)
return len1 - len2;
}
这个方法写的很巧妙,先从0开始判断字符大小。如果两个对象能比较字符的地方比较完了还相等,就直接返回自身长度减被比较对象长度,如果两个字符串长度相等,则返回的是0,巧妙地判断了三种情况。
startsWith(String prefix,int toffset)
// 判断此字符串的子字符串是否从指定的索引开始,并以指定的前缀开头
public boolean startsWith(String prefix, int toffset) {
char ta[] = value;
int to = toffset;
char pa[] = prefix.value;
int po = 0;
int pc = prefix.value.length;
// Note: toffset might be near -1>>>1.
// 如果起始地址小于0或者(起始地址+所比较对象长度)大于自身对象长度,返回false
if ((toffset < 0) || (toffset > value.length - pc)) {
return false;
}
// 从所比较对象的末尾开始比较
while (--pc >= 0) {
if (ta[to++] != pa[po++]) {
return false;
}
}
return true;
}
// startsWith重载方法1
public boolean startsWith(String prefix) {
return startsWith(prefix, 0);
}
// startsWith重载方法2
public boolean endsWith(String suffix) {
return startsWith(suffix, value.length - suffix.value.length);
}
起始比较和末尾比较都是比较经常用得到的方法,例如在判断一个字符串是不是http协议的,或者初步判断一个文件是不是mp3文件,都可以采用这个方法进行比较。
concat(String str)
// 将指定的字符串连接到该字符串的末尾
public String concat(String str) {
int otherLen = str.length();
if (otherLen == 0) {
return this;
}
int len = value.length;
char buf[] = Arrays.copyOf(value, len + otherLen);
str.getChars(buf, len);
// 注意:这里是新new一个String对象返回,而并非原来的String对象
return new String(buf, true);
}
// 位于 java.util.Arrays 类中
public static char[] copyOf(char[] original, int newLength) {
char[] copy = new char[newLength];
// 调用底层c++
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}
replace(char oldChar, char newChar)
// 返回一个字符串,该字符串是通过用 newChar 替换该字符串中所有出现的 oldChar 而产生的
public String replace(char oldChar, char newChar) {
// 新旧值先对比
if (oldChar != newChar) {
int len = value.length;
int i = -1;
char[] val = value; /* avoid getfield opcode */
// 找到旧值最开始出现的位置
while (++i < len) {
if (val[i] == oldChar) {
break;
}
}
// 从那个位置开始,直到末尾,用新值代替出现的旧值
if (i < len) {
char buf[] = new char[len];
for (int j = 0; j < i; j++) {
buf[j] = val[j];
}
while (i < len) {
char c = val[i];
buf[i] = (c == oldChar) ? newChar : c;
i++;
}
// 注意:这里是新new一个String对象返回,而并非原来的String对象
return new String(buf, true);
}
}
return this;
}
trim()
// 返回值是此字符串的字符串,其中已删除所有前导和尾随的空格
public String trim() {
int len = value.length;
int st = 0;
char[] val = value; /* avoid getfield opcode */
// 找到字符串前段没有空格的位置
while ((st < len) && (val[st] <= ' ')) {
st++;
}
// 找到字符串末尾没有空格的位置
while ((st < len) && (val[len - 1] <= ' ')) {
len--;
}
// 如果前后都没有出现空格,返回字符串本身
return ((st > 0) || (len < value.length)) ? substring(st, len) : this;
}
案例分析
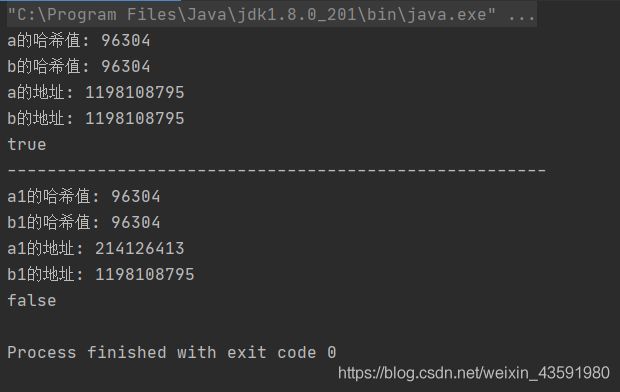
public static void main(String[] args) {
String a = "a"+"b"+1;
String b = "ab1";
// ab1 是放在常量池(constant pool)中的
// 所以,虽然a,b都等于 ab1,但是内存中只有一份副本,所以 == 的结果为true
System.out.println("a的哈希值: " + a.hashCode());
System.out.println("b的哈希值: " +b.hashCode());
System.out.println("a的地址: " +System.identityHashCode(a));
System.out.println("b的地址: " +System.identityHashCode(b));
System.out.println(a == b);
System.out.println("---------------------------------------------------
String a1 = new String("ab1");
String b1 = "ab1";
// new 方法决定了String "ab1" 被创建放在了内存heap区(堆上),被a1所指向
// b1 位于常量池 因此 == 返回了false
System.out.println("a1的哈希值: " + a1.hashCode());
System.out.println("b1的哈希值: " +b1.hashCode());
System.out.println("a1的地址: " +System.identityHashCode(a1));
System.out.println("b1的地址: " +System.identityHashCode(b1));
System.out.println(a1 == b1);
}
输出结果:
2.2 StringBuilder 源码分析
2.2.1 StringBuilder 类
public final class StringBuilder
extends AbstractStringBuilder
implements java.io.Serializable, CharSequence
{
...
}
首先 StringBuilder 同 String 一样 被 final 关键字修饰该类不能被继承!
从继承体系可以看出, StringBuilder 继承了AbstractStringBuilder类,该类中包含了可变字符串的相关操作方法:append()、insert()、delete()、replace()、charAt()等等。**StringBuffer 和 StringBuilder ** 均继承该类!
比如在 StringBuilder 中的 append(String str) 方法(后文还会讲到):
// java.lang.StringBuilder 类中
@Override
public StringBuilder append(String str) {
// 调用父类 AbstractStringBuilder 的append(String str) 方法
super.append(str);
return this;
}
// java.lang.AbstractStringBuilder 类中(有兴趣可以自己点进去阅读该类的源码,还是很有收获的,这里只作简述!)
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
// 其成员属性value[]数组扩容,类似于ArrayList 的扩容
// 扩容算法:int newCapacity = (value.length << 1) + 2;
// 注意容量有上限:MAX_ARRAY_SIZE
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
}
StringBuilder 还实现了Serializable 接口 和 CharSequence 接口,说明该类的对象可以被序列化,并附带了对字符序列进行只读访问的方法,比如:length()、charAt()、subSequence()、toString()方法等。
2.2.2 StringBuilder 类的属性
/**
* 用于字符存储的char数组,value是一个动态的数组,当存储容量不足时,会对它进行扩容.
*/
char[] value;
/**
* 表示value数组中已存储的字符数.
*/
int count;
关键点
- 该数组和 Sting 中的value数组不同,其未被 final 关键字修饰,其值是可以被修改的!
- 这两个成员属性并不位于java.lang.StringBuilder 中,而位于其父类 java.lang.AbstractStringBuilder 中,同样的StringBuffer 中的这两个属性也是位于该父类中!
2.2.3 StringBuilder 类中的构造方法
StringBuilder类提供了4个构造方法。构造方法主要完成了对value数组的初始化。
// 位于父类StringBuilder 中
// 空参StringBuilder 默认char数组容量为16
public StringBuilder() {
super(16);
}
// 由参数传入容量,构建StingBuilder
public StringBuilder(int capacity) {
super(capacity);
}
// 根据字符串参数的长度,构建容量为 16 + 字符串长度的StringBuilder
public StringBuilder(String str) {
super(str.length() + 16);
// 调用父类append 方法添加字符串str
append(str);
}
// 接收一个CharSequence对象作为参数,设置了value数组的初始容量为CharSequence对象的长度+16
// 并把CharSequence对象中的字符添加到value数组中
public StringBuilder(CharSequence seq) {
this(seq.length() + 16);
// 调用父类append 方法添加字符串seq
append(seq);
}
// 位于父类AbstractStringBuilder中
// 创建指定容量的AbstractStringBuilder
AbstractStringBuilder(int capacity) {
value = new char[capacity];
}
总结
其实String 、StingBuilder 、StirngBuffer 也类似于容器,因为其底层均在维护一个 char 类型的数组!
2.2.4 StringBuilder 类中的方法
append(Object obj)方法
append 方法的重载方法参数有多种,比如String int 等等,原理类似,这里只举String 和 Boolean 为例子:
// 位于父类StringBuilder 中
@Override
public StringBuilder append(Object obj) {
return append(String.valueOf(obj));
}
// 位于父类StringBuilder 中
@Override
public StringBuilder append(String str) {
super.append(str);
return this;
}
// 位于父类StringBuilder 中
@Override
public StringBuilder append(boolean b) {
super.append(b);
return this;
}
...
// 位于父类AbstractStringBuilder中
// 添加String 类型
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
}
// 位于父类AbstractStringBuilder中
// 添加Boolean 类型
public AbstractStringBuilder append(boolean b) {
if (b) {
ensureCapacityInternal(count + 4);
value[count++] = 't';
value[count++] = 'r';
value[count++] = 'u';
value[count++] = 'e';
} else {
ensureCapacityInternal(count + 5);
value[count++] = 'f';
value[count++] = 'a';
value[count++] = 'l';
value[count++] = 's';
value[count++] = 'e';
}
return this;
}
append()方法将指定参数类型的字符串表示形式追加到字符序列的末尾。
StringBuilder 类提供了一系列的append()方法,它可以接受boolean、char、char[]、CharSequence、double、float、int、long、Object、String、StringBuffer这些类型的参数。
这些方法最终都调用了父类AbstractStringBuilder类中对应的方法。最后,append()方法返回了StringBuilder对象自身,以便用户可以链式调用StringBuilder类中的方法。
AbstractStringBuilder类的各个append()方法大同小异。append()方法在追加字符到value数组中之前都会调用ensureCapacityInternal()方法来确保value数组有足够的容量,然后才把字符追加到value数组中。
// 位于父类AbstractStringBuilder中
// 判断value数组的容量是否足够,如果不够,那么调用newCapacity 方法进行扩容
private void ensureCapacityInternal(int minimumCapacity) {
// overflow-conscious code
if (minimumCapacity - value.length > 0) {
value = Arrays.copyOf(value,
newCapacity(minimumCapacity));
}
}
// 位于父类AbstractStringBuilder中
// 返回新数组容量
private int newCapacity(int minCapacity) {
// 将数组容量扩大到原数组容量的2倍+2
int newCapacity = (value.length << 1) + 2;
if (newCapacity - minCapacity < 0) {
newCapacity = minCapacity;
}
return (newCapacity <= 0 || MAX_ARRAY_SIZE - newCapacity < 0)
? hugeCapacity(minCapacity)
: newCapacity;
}
// 位于父类AbstractStringBuilder中
// 数组最大容量
private int hugeCapacity(int minCapacity) {
if (Integer.MAX_VALUE - minCapacity < 0) {
// overflow
throw new OutOfMemoryError();
}
return (minCapacity > MAX_ARRAY_SIZE)
? minCapacity : MAX_ARRAY_SIZE;
}
ensureCapacityInternal()方法判断value数组的容量是否足够,如果不够,那么调用newCapacity()方法进行扩容。
newCapacity()方法默认情况下将数组容量扩大到原数组容量的2倍+2。数组的容量最大只能扩容到Integer.MAX_VALUE。
最后,调用Arrays类的copyOf()静态方法来创建一个新数组和拷贝原数据到新数组,并将value指向新数组。
delete()方法
// 位于父类StringBuilder 中
@Override
public StringBuilder delete(int start, int end) {
super.delete(start, end);
return this;
}
// 位于父类AbstractStringBuilder中
public AbstractStringBuilder delete(int start, int end) {
if (start < 0)
throw new StringIndexOutOfBoundsException(start);
if (end > count)
end = count;
if (start > end)
throw new StringIndexOutOfBoundsException();
int len = end - start;
if (len > 0) {
System.arraycopy(value, start+len, value, start, count-end);
count -= len;
}
return this;
}
delete()方法删除指定位置的字符。删除的字符从指定的start位置开始,直到end-1位置。delete()方法也调用了父类AbstractStringBuilder类中对应的方法。
delete()方法首先检查参数的合法性。当end大于value数组中已存储的字符数count时,end取count值。最后,当需要删除的字符数大于1的时候,调用System类的arraycopy()静态方法进行数组拷贝完成删除字符的操作,并更新count的值。
replace()方法
// 位于父类StringBuilder 中
@Override
public StringBuilder replace(int start, int end, String str) {
super.replace(start, end, str);
return this;
}
// 位于父类AbstractStringBuilder中
public AbstractStringBuilder replace(int start, int end, String str) {
if (start < 0)
throw new StringIndexOutOfBoundsException(start);
if (start > count)
throw new StringIndexOutOfBoundsException("start > length()");
if (start > end)
throw new StringIndexOutOfBoundsException("start > end");
if (end > count)
end = count;
int len = str.length();
int newCount = count + len - (end - start);
ensureCapacityInternal(newCount);
System.arraycopy(value, end, value, start + len, count - end);
str.getChars(value, start);
count = newCount;
return this;
}
// 位于java.lang.String 中
void getChars(char dst[], int dstBegin) {
System.arraycopy(value, 0, dst, dstBegin, value.length);
}
replace()方法将指定位置的字符替换成指定字符串中的字符。替换的字符从指定的start位置开始,直到end-1位置。
replace()方法也调用了父类AbstractStringBuilder类中对应的方法。
replace()方法首先检查参数的合法性。当end大于value数组中已存储的字符数count时,end取count值。然后调用ensureCapacityInternal()方法确保value数组有足够的容量。接着调用System类的arraycopy()静态方法进行数组拷贝,主要的作用是从start位置开始空出替换的字符串长度len大小的位置。最后,调用String类的getChars()方法将替换的字符串中的字符拷贝到value数组中。这样就完成了替换字符的操作。
toString()方法
@Override
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
}
toString()方法返回一个表示该字符序列的字符串,将SrpingBuilder 转换成了 String 类型。
总结
- StringBuilder类使用了一个char数组来存储字符。该数组是一个动态的数组,当存储容量不足时,会对它进行扩容。
- StringBuilder对象是一个可变的字符序列。
- StringBuilder类是非线程安全的。
2.3 StringBuffer 源码分析
2.3.1 StringBuffer 类
public final class StringBuffer
extends AbstractStringBuilder
implements java.io.Serializable, CharSequence
{
...
}
从继承体系中得出,StingBuffer 和 StringBuilder 继承了相同父类,实现了相同的接口,且都被 final 关键字修饰不可被继承,所以不再重复赘述!
2.3.2 StringBuffer 类的属性
/**
* 用于字符存储的char数组,value是一个动态的数组,当存储容量不足时,会对它进行扩容.
*/
char[] value;
/**
* 表示value数组中已存储的字符数.
*/
int count;
StringBuffer 和 StringBuilder 以及 String 一样本质上都维护了一个字符数组!且,StringBuffer 和 StringBuilder 的字符数组没有 final 修饰可以被重新赋值,而String 中的字符数组加了final 不可变(常量)!
2.3.3 StringBuffer 类的构造函数
public StringBuffer() {
super(16);
}
public StringBuffer(int capacity) {
super(capacity);
}
public StringBuffer(String str) {
super(str.length() + 16);
append(str);
}
...
在构造函数上 StringBuffer 和 StringBuilder 没区别,不再重复赘述!
2.3.4 StringBuffer 的方法
StringBuffer的主要操作有append、insert等,这些操作都是在value上进行的,而不是像String一样每次操作都要new一个新的String对象,因此,StringBuffer在效率上要高于String。有了append、insert等操作,value的大小就会改变,那么StringBuffer是如何操作容量的改变的呢?
StringBuffer 的扩容
StringBuffer有个继承自AbstractStringBuilder类的ensureCapacity的方法:
// 位于StringBuffer 中
@Override
public synchronized void ensureCapacity(int minimumCapacity) {
super.ensureCapacity(minimumCapacity);
}
// 位于父类中
public void ensureCapacity(int minimumCapacity) {
if (minimumCapacity > 0)
ensureCapacityInternal(minimumCapacity);
}
StringBuffer对其进行了重写,直接调用父类的expandCapacity方法。这个方法用来保证value的长度大于给定的参数minimumCapacity,在父类的ensureCapacityInternal方法中这样操作:
private void ensureCapacityInternal(int minimumCapacity) {
// overflow-conscious code
if (minimumCapacity - value.length > 0) {
value = Arrays.copyOf(value,
newCapacity(minimumCapacity));
}
}
private int newCapacity(int minCapacity) {
// overflow-conscious code
int newCapacity = (value.length << 1) + 2;
if (newCapacity - minCapacity < 0) {
newCapacity = minCapacity;
}
return (newCapacity <= 0 || MAX_ARRAY_SIZE - newCapacity < 0)
? hugeCapacity(minCapacity)
: newCapacity;
}
最后得到的新value数组大小是max(value.length*2+2,minimumCapacity),上面代码中的第二个判断是为了防止newCapacity溢出。
setLength方法
该方法用于直接设置字符数组元素的count数量:
// 位于StringBuffer 中
@Override
public synchronized void setLength(int newLength) {
toStringCache = null;
super.setLength(newLength);
}
// 为于父类中
public void setLength(int newLength) {
if (newLength < 0)
throw new StringIndexOutOfBoundsException(newLength)
ensureCapacityInternal(newLength);
if (count < newLength) {
Arrays.fill(value, count, newLength, '\0');
}
count = newLength;
}
从代码中可以看出,如果newLength大于count,那么就会在后面添加’\0’补充;如果小于count,就直接使count = newLength。
appen/insert 方法
StringBuffer中的每一个append和insert函数都会调用父类的函数:
@Override
public synchronized StringBuffer append(Object obj) {
toStringCache = null;
super.append(String.valueOf(obj));
return this;
}
@Override
public synchronized StringBuffer insert(int index, char[] str, int offset, int len) {
toStringCache = null;
super.insert(index, str, offset, len);
return this;
}
而在父类中,这些函数都会首先保证value的大小够存储要添加的内容:
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
}
public AbstractStringBuilder insert(int index, char[] str, int offset, int len){
if ((index < 0) || (index > length()))
throw new StringIndexOutOfBoundsException(index);
if ((offset < 0) || (len < 0) || (offset > str.length - len))
throw new StringIndexOutOfBoundsException(
"offset " + offset + ", len " + len + ", str.length "
+ str.length);
ensureCapacityInternal(count + len);
System.arraycopy(value, index, value, index + len, count - index);
System.arraycopy(str, offset, value, index, len);
count += len;
return this;
}
父类中通过ensureCapacityInternal的函数保证大小,函数如下:
private void ensureCapacityInternal(int minimumCapacity) {
// overflow-conscious code
if (minimumCapacity - value.length > 0)
expandCapacity(minimumCapacity);
}
如果空间不够,最终也是调用expandCapacity方法。这样就保证了随着操作value的空间够用。
toString 方法
StringBuffer可以通过toString方法转换为String,它有一个私有的字段toStringCache!
这个字段表示是一个缓存,用来保存上一次调用toString的结果,如果value的字符串序列发生改变,就会将它清空
private transient char[] toStringCache;
@Override
public synchronized String toString() {
if (toStringCache == null) {
toStringCache = Arrays.copyOfRange(value, 0, count);
}
return new String(toStringCache, true);
}
首先判断toStringCache是否为null,如果是,则先将value复制到缓存里,然后使用toStringCache 为参数,去new 一个 String 对象并返回!
总结
可以看出,StringBuffer 和 StringBuilder 在添加append()方法上的区别是,前者加上了synchronized 锁,因此其是线程安全的,后者是非线程安全的!
而判断是否扩容以及扩容方式,StringBuffer 和 StringBuilder 二者没什么区别!
如果文章对您有帮助,点个关注或者赞支持下,谢谢~