上一篇MonkeyLei:Python-爬取页面内容(涉及urllib、requests、UserAgent、Json等) 我们爬取了内容,接下来就可以用xPath做内容分析了,进而获取我们想要爬的内容。
xPath知识有必要了解,然后我们需要做点实践学习熟悉它....
1. 先看基本语法
https://www.w3school.com.cn/xpath/xpath_syntax.asp
https://blog.csdn.net/Nikki0126/article/details/90752678 - 基本照着这个就可以实践了,还是比较清晰。
开始之前需要安装浏览器xPath插件哟 MonkeyLei:解决Chrome插件安装时程序包无效【CRX_HEADER_INVALID】(转载+xPath插件)
难点应该就在于语法如何写,以及根据自己的需求定制语法规则...
2. 几个点

image
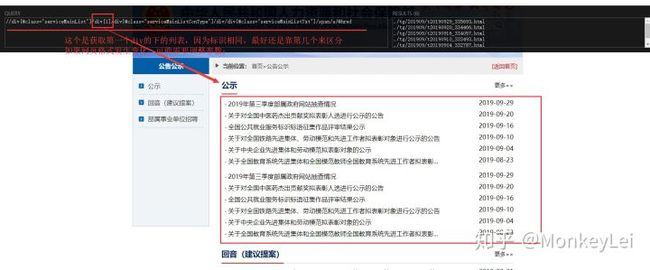
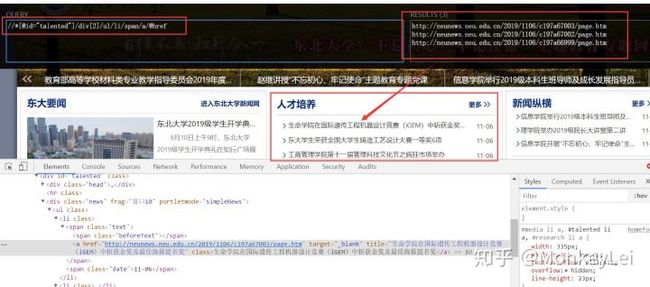
比如我们xPath工具去google浏览器瞅瞅 - 这个得出来的规则按需完善后就可以直接运用到代码里面->html_object.xpath('//[@id="talented"]/div[2]/ul/li/span/a/@href'*)
image
image
3. 开始实践
xpath.py
#!/usr/bin/python3
# -*- coding: UTF-8 -*-
# 文件名:xpath.py
from lxml import etree
from urllib import request
# 1\. 先来个简单的吧 缺