首先确定分析思路,数据来源是根据链家网北京地铁按照线路依次爬取出来的,后续分析向围绕着地铁线路来展开。(下次再写如何通过爬虫获取数据,确实没时间了)
分析思路如下:
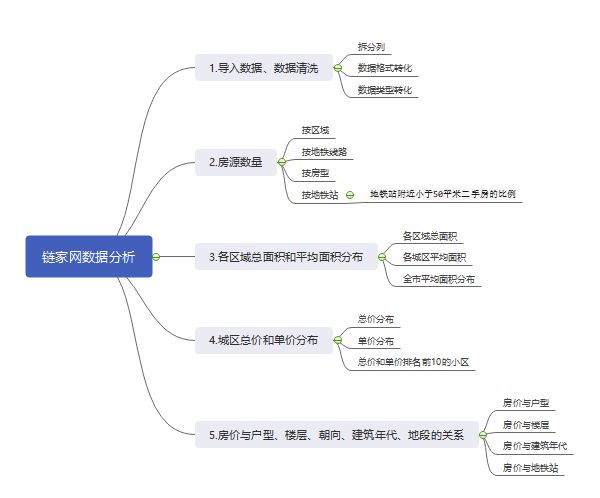
1.数据清洗
---这部分略,之后会单独开一篇。
直接开始下一步,分析整体。
导入常用包和数据。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei']#显示中文
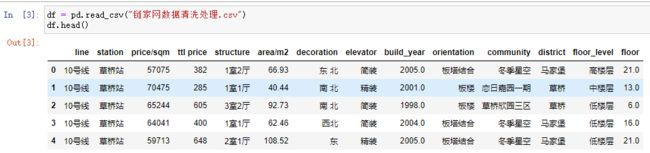
导入数据,查看数据头部
df = pd.read_csv("链家网数据清洗处理.csv")
df.head()
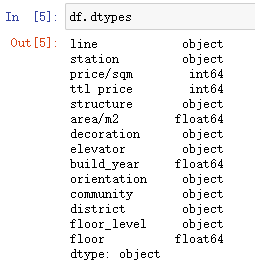
查看数据类型及缺失情况
df.dtypes
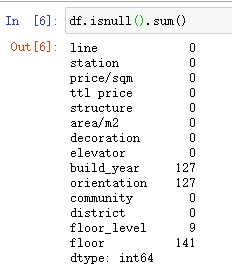
df.isnull().sum()
查看数据详细信息
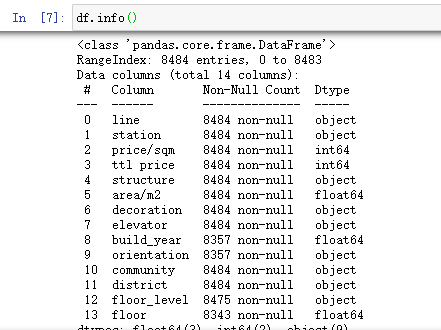
df.info()
查看描述性统计
df.describe()
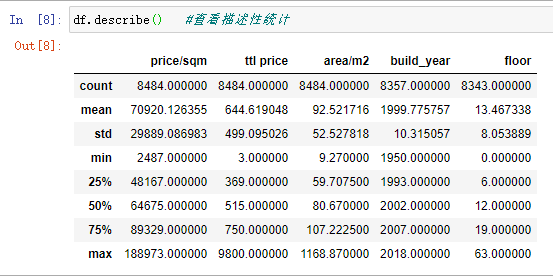
由上面的综述描述可以得到如下结论:
- 面积平均值为92㎡,面积中位数为80㎡,说明少数大面积的房源拉高了的总体平均水平
- 总价平均值为645万,总价中位数为515万,情况与上面一样,少数总价高的房源拉高了总体的平均水平
- 单价平均数为70920元,单价中位数为64675元,少数总价高的房源拉高了总体的平均水平
2.数据分析:房源数量
2.1 按区域进行房源数量排序
district_number=df.district.value_counts().reset_index().sort_values(by='district',ascending=False)
district_number

房源数量区域前15
data = df.district.value_counts().reset_index().sort_values(by='district',ascending=False).head(15)
可视化
import seaborn as sns
sns.set_style('whitegrid',{'font.sans-serif':['simhei','Arial']})#解决sns乱码问题
plt.figure(figsize=(15,6))
sns.barplot(x=data['index'],y=data.district,)
plt.title('各城区房源数量')
plt.show()

由以上柱状图分析可知,望京、回龙观、亦庄为房源最多的三个地区均在175以上。 望京在朝阳区,回龙观在昌平区,亦庄在大兴区。 大部分的房源主要集中在市中心的区,部分在郊区部分。
2.2 按地铁线路分析房源数量
data = df['line'].value_counts().reset_index().sort_values(by = 'line',ascending = False)
可视化
plt.figure(figsize=(20,6))
sns.barplot(x=data['index'],y=data.line,)
plt.title('地铁线路房源分布')
plt.show()
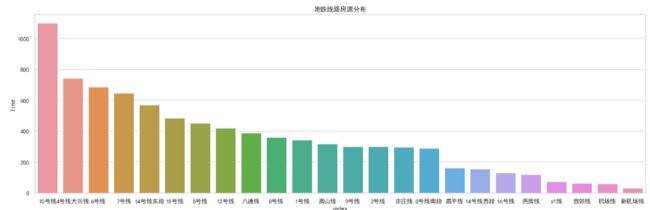
- 北京地铁10号线成环贯通运营,途经海淀区、丰台区、朝阳区,为北京地铁系统中客流量最大的线路,房源数量也是最多的。
- 四号线大兴线排第二,但是却差10号线很多,四号线途径海淀丰台区,房源数量超过700。
- 排在末尾的五位,都是处在郊区的线路,人流量稀少,房源数量也不多。
- 可以看出贯穿市中心的地铁线路,房源数量都比较多。
2.3 按地铁站
地铁站数量较多,所以做个筛选,只保留房源数量大于等于30的地铁站。
data = df['station'].value_counts().reset_index().sort_values(by='station',ascending = False)
data[data['station']>=30]
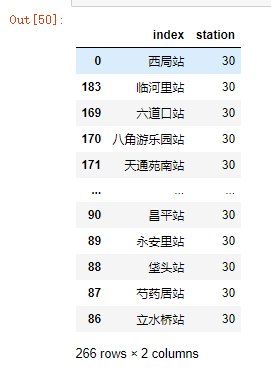
266个地铁站房源数量等于30个
查看这些地铁站在地铁线路分布的情况:
data2 = data[data['station']>=30]
data3 = df[['line','station']]
data3 = data3.drop_duplicates()
data4 = pd.merge(left=data2,right=data3,how='inner',left_on = 'index',right_on = 'station')
data4['line'].value_counts()

- 可以看出和之前的直接按照地铁线路排序的顺序一样
2.4 按照房型分析房源数量
data = df['structure'].value_counts().head(10)
可视化
plt.figure(figsize=(15,6))
sns.barplot(x=data.index,y=data.values)
plt.show()
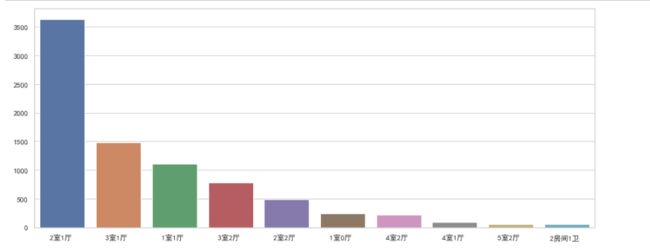
- 可以看出主流房型为2室1厅,远超于排名第二和第三的3室1厅和1室1厅
3.各区域总面积和平均面积分布
3.1 计算各城区二手房源总面积
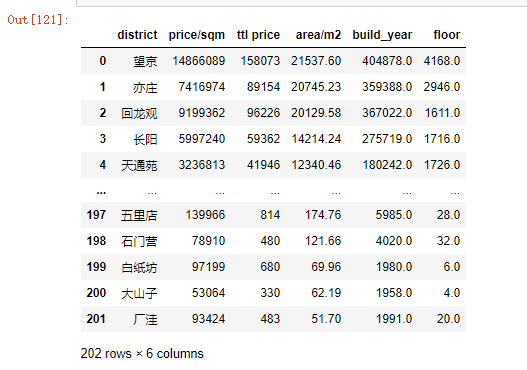
grouped_total_area = df.groupby('district').sum().sort_values('area/m2',ascending = False).reset_index()
grouped_total_area
可视化:作出各城区总面积折线图
plt.figure(figsize=(12,5))
grouped_total_area.plot(x = 'district',y = 'area/m2',kind = 'line')
plt.title('各城区总面积分布')
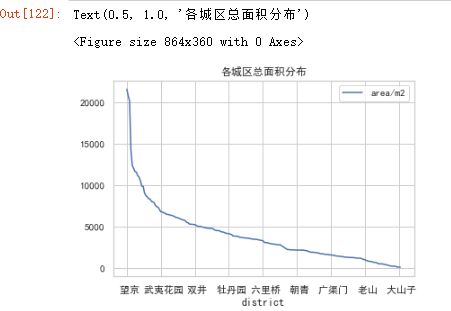
- 可以看出望京,亦庄,回龙观三个地方的面积是最多的,结合前面,这三个地方的房源数量也是最多的。
3.2各城区平均面积分布
df.groupby('district')['area/m2'].mean().reset_index().sort_values('area/m2',ascending = False)
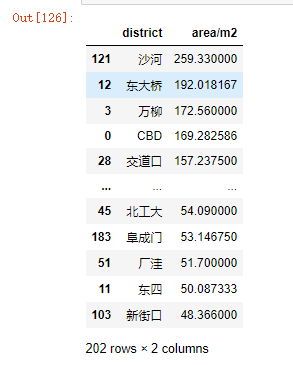
- 可以看出郊区房源的平均面积大,市中心房源的平均面积小。
- 郊区位置,不在中心位置,建设成本较低,房屋设计面积较大。
3.3 求出不同面积段的房源数量
全市平均面积分布:
- 以区间[0,50)、[50,100)、[100,150)、[150,200)、[200,+∞)为划分标准,将面积划分为tinysmall、small、medium、big、huge五个等级,分别对应极小户型、小户型、中等户型、大户型和巨大户型。
df2=df.copy()
df2.loc[(df2['area/m2'] >= 0) & (df2['area/m2'] < 50),'area_level'] = 'tinysmall'
df2.loc[(df2['area/m2'] >= 50) & (df2['area/m2'] < 100),'area_level'] = 'small'
df2.loc[(df2['area/m2'] >= 100) & (df2['area/m2'] < 150),'area_level'] = 'medium'
df2.loc[(df2['area/m2'] >= 150) & (df2['area/m2'] < 200),'area_level'] = 'big'
df2.loc[(df2['area/m2'] >= 200),'area_level'] = 'huge'
df2.head()
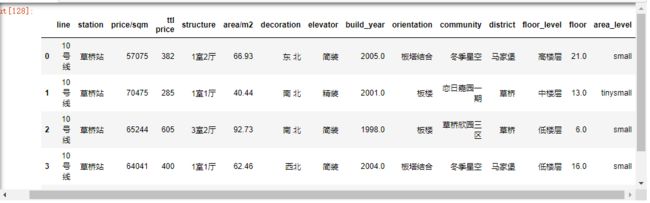
grouped_area_level=df2.groupby('area_level')['ttl price'].count().reset_index()
grouped_area_level

可视化
plt.bar(grouped_area_level['area_level'],grouped_area_level['ttl price'])
plt.title('各户型数量分布')
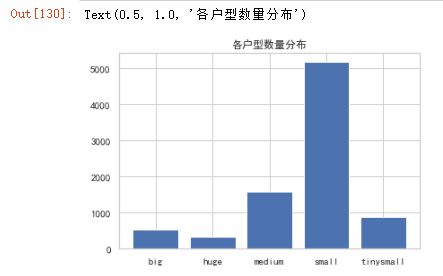
- 一半以上的房源集中在small阶段,即[50,100)这个区间
- 其次是medium房型,即[100,150)
4.数据分析:各城区总价和单价分布
4.1总价分布
按照地铁线路,具体分析其地铁站
# 把分区后的总价组成一个字典,以便下面将它转化为dataframe
good=dict(list(df2.groupby('line')['ttl price']))
# 转化为dataframe
gooddf=pd.DataFrame(good)
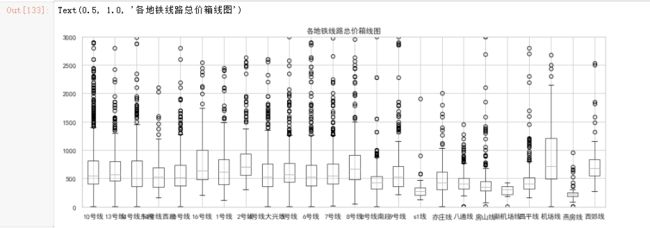
# 作出总价箱线图
plt.figure(figsize=(15,5))
gooddf.boxplot()
plt.ylim(0,3000)
plt.title('各地铁线路总价箱线图')
df.groupby('line')['ttl price'].describe().sort_values('mean',ascending = False)
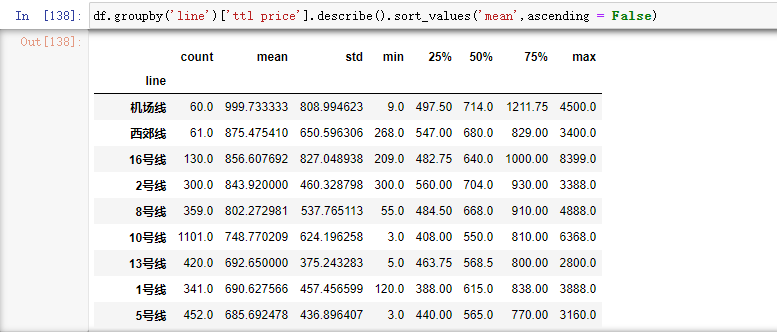
由以上结果可知:
- 总价No.1的为机场线,平均值为1000万,总价区间跨越大,总体价格价格区间为[500,1300]万,中位数小于平均值,故少数价格高的拉高总体平均值的现象比较严重
- 总价No.2的为西郊线,平均值为875.5万,总体价格区间为[547,829]万,中位数小于平均值,故少数价格高的拉高了总体平均值
平均总价分布
df2['ttl price'].hist(bins = 50)
plt.title('平均总价分布图')
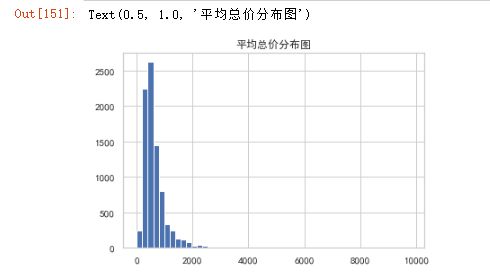
- 房屋总价是一个左凸的直方图,90%的数据集中在[200,800]的区间,即90%的房源总价在200万到800万之间,只有大概10%的房源属于极高的价格,这个结果符合现实的房价分布
4.2 总价和单价排名前十五小区
对小区进行分组,计算出各小区房源数量,并按照房源数量降序的顺序排序
df3 = df2.groupby('community')['ttl price'].count().reset_index().sort_values('ttl price',ascending = False)
df3.head()
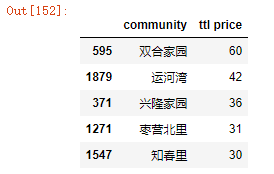
因为很多小区房源数量太少,其统计值不具有代表性,故在此过滤掉房源数量小于20的小区
df4 = df3[df3['ttl price'] > 20]
df4.head(10)
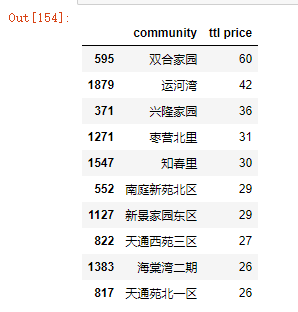
df5 = df2[df2['community'].isin(df4['community'])]
df5.head()

计算各小区总价排名前15的小区:
totalp_village = df5.groupby('community')['ttl price'].mean().sort_values(ascending = False).reset_index().head(15)
totalp_village

可视化:作出平均总价排名前十五的小区的平均总价柱状图
plt.figure(figsize=(20,4))
plt.bar(totalp_village['community'],totalp_village['ttl price'])
plt.title('平均总价排名前15的小区')
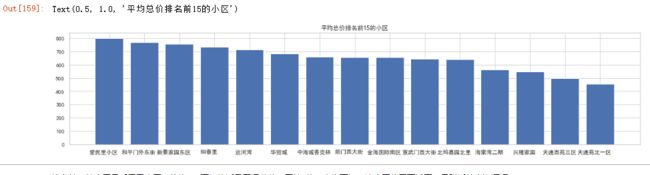
- 排名第一的小区是爱民里小区,价格800万,将近是天通苑北一区的2倍。查询可知,该小区位于西城区,且附近教育资源好。
计算单价排名前十五的小区
totalp_village1=df5.groupby('community')['price/sqm'].mean().sort_values(ascending=False).head(15).reset_index()
totalp_village1
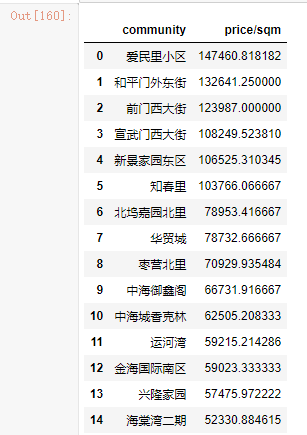
可视化:作出平均单价排名前十小区的单价柱状图
plt.figure(figsize = (20,5))
plt.bar(totalp_village1['community'],totalp_village1['price/sqm'])
plt.title('平均单价排名前15小区')
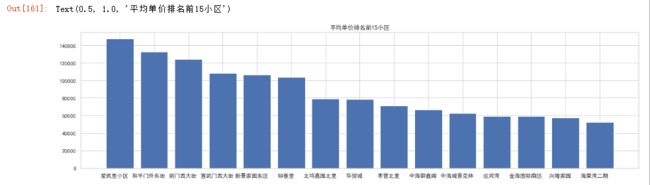
- 爱民里小区单价依旧最高,超过14万每平米最低的海棠湾二期每平米都超过5万。
5.房价与户型、楼层、朝向、建筑年代的关系
5.1 房价与户型的关系
按户型进行分组,计算出每个户型的房源数量,过滤掉房源数量小于100的户型
grouped_house_type = df2.groupby('structure')['ttl price'].count().sort_values(ascending = False).reset_index()
grouped_house_type2 = grouped_house_type.loc[grouped_house_type['ttl price']> 100]
grouped_house_type2
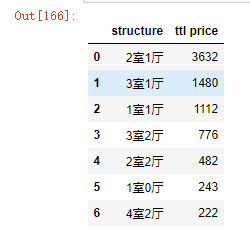
可视化:作出各户型的数量柱状图
plt.figure(figsize = (10,5))
plt.bar(grouped_house_type2['structure'],grouped_house_type2['ttl price'])
plt.title('各户型数量柱状图')
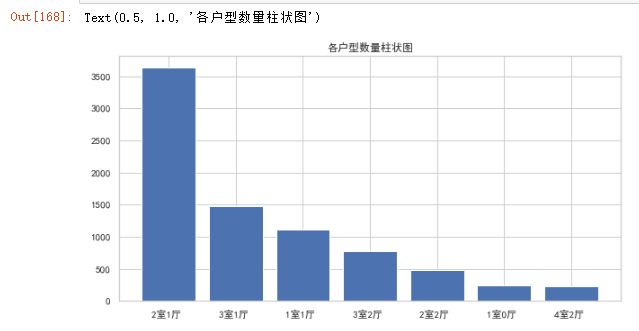
- 通过图可以知道,户型最多的是2室1厅。
户型与房屋均价
df6 = df[df['structure'].isin(grouped_house_type2['structure'])]
grouped_house_type3 = df6.groupby('structure')['price/sqm'].mean().reset_index().sort_values('price/sqm',ascending=False)
grouped_house_type3
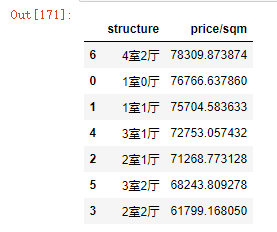
可视化:户型与房屋均价的柱状图
plt.figure(figsize=(15,5))
sns.barplot(grouped_house_type3['structure'],grouped_house_type3['price/sqm'])
plt.title('户型-房屋均价图')
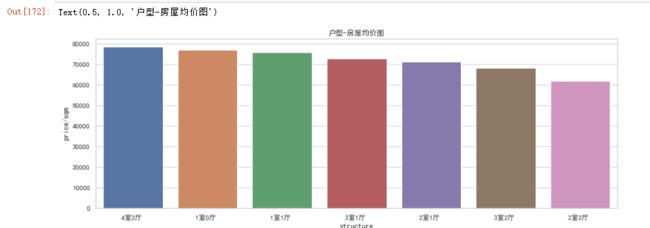
户型平摊面积
df6.groupby('structure')['area/m2'].mean().reset_index().sort_values('area/m2',ascending=False)
- 单价排名前三的是4室2厅,1室0厅,1室1厅。
- 可以预见的是,4室2厅,房屋面积大,单价高,因此需要一次性支付大量金额。
- 1室0厅,1室1厅。价格比4室2厅稍低,但是房屋面积小,单价相较4室2厅,会低很多,经济压力小。
5.2 房价与楼层的关系
df['floor_level'].value_counts()

数据杂乱多,因此先进行一下限制,只计算中楼层、低楼层、高楼层这三种
lista = [' 中楼层',' 低楼层',' 高楼层']
floor = df[df['floor_level'].isin(lista)]
floor2= floor.groupby('floor_level')['line'].count().reset_index()
floor2

可视化:作出其柱状图
plt.figure(figsize=(15,6))
sns.barplot(x=floor2['floor_level'],y=floor2['line'])
plt.title('楼层等级-数量')
plt.show()
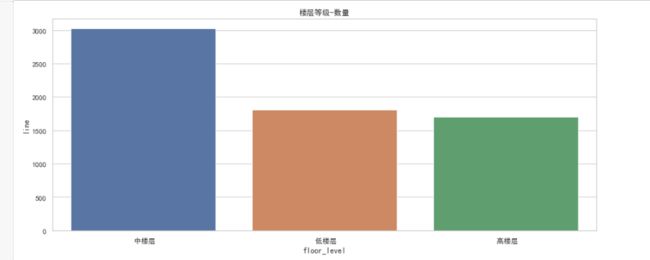
- 中楼层数量最多超3千,底层楼和高层楼平齐。
5.3 各楼层等级的平均单价平均总价
平均单价
floor_level_mean = floor.groupby('floor_level')['price/sqm'].mean().reset_index()
floor_level_mean

可视化:作出其柱状图
plt.figure(figsize=(15,6))
sns.barplot(x=floor_level_mean['floor_level'],y=floor_level_mean['price/sqm'])
plt.title('楼层等级—平均单价')
plt.show()
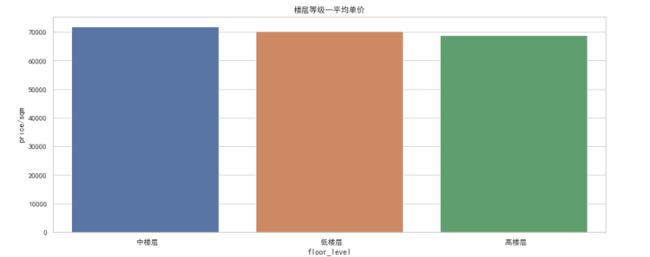
- 三种楼型价格接近,基本都在7万元左右。
层数对价格的影响
现在开始分析floor层数对价格的影响。
查看缺省值,删除缺省行
df.isnull().sum()

floor3 = df.dropna(axis=0,subset = ['floor'])
floor3.isnull().sum()
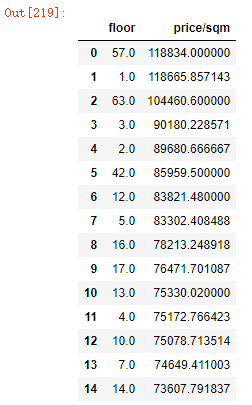
计算楼层平均单价排名前15位
floor_level = floor3.groupby('floor')['price/sqm'].mean().sort_values(ascending = False).reset_index().head(15)
floor_level
可视化:作出其折线图
plt.figure(figsize=(15,5))
sns.lineplot(x=floor_level['floor'],y=floor_level['price/sqm'])
plt.title('楼层数-单价')
plt.show()
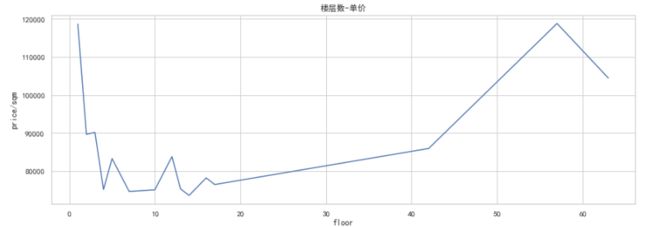
- 由上图可知低楼层(5层以下)和高楼层(40层以上)单价相较其他楼层比较高。
5.4房价与朝向的关系
df.groupby('decoration')['price/sqm'].mean().reset_index().sort_values('price/sqm',ascending = False).head(15)

数据看不懂,不具备参考意义,舍弃。
5.5 房价与建筑年代的关系
由上面的分析可知,要先删除缺失值数据,才能进行下一步
build = df.dropna(axis=0,subset=['build_year'])
build2 = build.groupby('build_year')['price/sqm'].mean().reset_index().sort_values('build_year')
build2
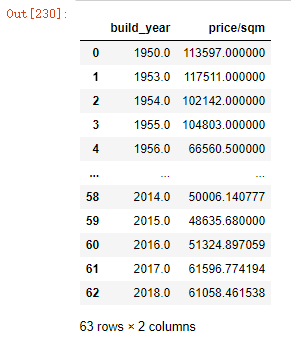
可视化:建筑年代与平均总价折线图
plt.figure(figsize=(16,5))
sns.lineplot(build2['build_year'],build2['price/sqm'])
plt.title('建筑时间-平均总价图')
plt.show()
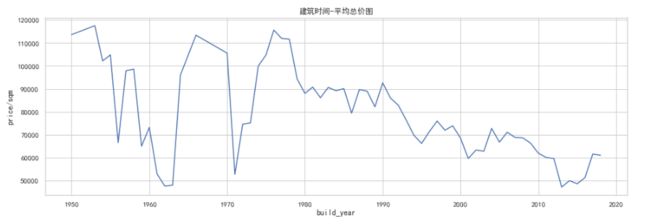
- 通过建造年代可知道,1950年、1965年、1976年左右的房子房价都超过11万元每平米,结合之前的分析,这个价位的房子,基本在市中心,且交通便利,教育资源优良。而2000年后房屋建造房价开始下降,其主要原因可能是房子开始向郊区扩建,地段不如60、70年代的好。
- 中间1962年左右房价比较低,可能原因是这个时间段建造的房屋数量不多,1971年也是同理。
build3 = build.groupby('build_year')['price/sqm'].count().reset_index().sort_values('build_year')
plt.figure(figsize=(16,5))
sns.lineplot(build3['build_year'],build3['price/sqm'])
plt.title('建筑时间-数量')
plt.show()
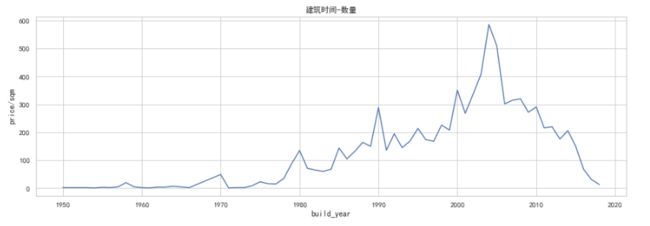
- 由图可知,1980年之后,房屋修建开始加快增长到1990年先达到第一个峰值,随后在2005年左右达到第二个峰值,之后开始逐步下降。
5.6 房价与地铁站
station = df.groupby('station')['price/sqm'].mean().reset_index().sort_values('price/sqm',ascending = False).head(10)
station

data3 = df[['line','station']]
data3 = data3.drop_duplicates()
station2 = pd.merge(left=station,right=data3,how='inner',on = 'station')
station2
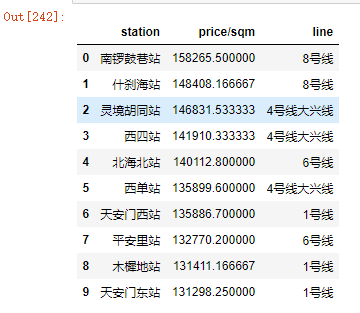
- 这些站点基本都是东西城区,是北京最繁华的地带,也是心脏地带。
station3 = df[df['station'].isin(station2['station'])]
station3.groupby('station')['area/m2'].mean().reset_index().sort_values('area/m2',ascending = False)
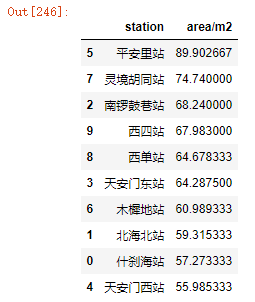
上述10个站点平均房屋面积在[55,90]这个区间房价在13万到16万不等,也就相当于,在最繁华的地方买房,至少也需要715万。