一、算法简介
主成分分析(Principal Component Analysis,简称PCA)算法是降维中最常用的一种手段,降维的算法还有很多,比如奇异值分解(SVD)、因子分析(FA)、独立成分分析(ICA)。这里我们主要讲解PCA的降维,它的目标是通过某种线性投影,将高维的数据映射到低维的空间中,并期望在所投影的维度上数据的信息量最大(方差最大),以此使用较少的数据维度,同时保留住较多的原数据点的特性。
PCA降维的目的,就是为了尽量保证"信息量不丢失"的情况下,对原始特征进行降维,也就是尽可能将原始特征往具有最大投影信息量的维度上进行投影。将原特征投影到这些维度上,使降维后信息量损失最小。
二、原理详解
1、相关概念
- 方差:
- 两个特征之间的协方差
- 协方差(假设均值为0时):
- 协方差矩阵:
- 协方差对角化:
补充一下:
(1)方差的计算公式是针对一维特征,即针对同一特征不同样本的取值来进行计算得到;而协方差则必须要求至少满足二维特征
(2)协方差为正,说明两个特征值呈正相关关系;协方差为负,说明两个特征值呈负相关关系;协方差为0,说明两个特征值不相关。
2、最大方差理论

上图中,u1就是主成分方向,然后在二维空间中取和u1方向正交的方向,就是u2的方向。则n个数据在u1轴的离散程度最大(方差最大),数据在u1上的投影代表了原始数据的绝大部分信息,即使不考虑u2,信息损失也不多。而且,u1、u2不相关。只考虑u1时,二维降为一维。椭圆的长短轴相差得越大,降维也越有道理。
最大方差理论:在信号处理中认为信号具有较大的方差,噪声有较小的方差,信噪比就是信号与噪声的方差比,越大越好。如前面的图,样本在u1上的投影方差较大,在u2上的投影方差较小,那么可认为u2上的投影是由噪声引起的。
因此我们认为,最好的k维特征是将n维样本点转换为k维后,每一维上的样本方差都很大。
3、原理分析
PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。PCA的工作就是从原始的空间中顺序地找一组相互正交的坐标轴,新的坐标轴的选择与数据本身是密切相关的。其中,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与第一个坐标轴正交的平面中使得方差最大的,第三个轴是与第1,2个轴正交的平面中方差最大的。依次类推,可以得到n个这样的坐标轴。通过这种方式获得的新的坐标轴,我们发现,大部分方差都包含在前面k个坐标轴中,后面的坐标轴所含的方差几乎为0。于是,我们可以忽略余下的坐标轴,只保留前面k个含有绝大部分方差的坐标轴。事实上,这相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,实现对数据特征的降维处理。
4、求解步骤
- 求平均值
- 计算协防差矩阵
- 计算协方差矩阵的特征值和特征向量
- 将特征值排序
- 保留前K个最大的特征值对应的特征向量
- 将原始特征转换到上面得到的K个特征向量构建的新空间中(最后两步,实现了特征压缩)
我们通过一组数据的实例进行讲解:
1、原始数据:
2、计算协方差矩阵
3、获取特征值:
4、获取特征向量:
5、特征向量一定能使协防差矩阵对角化:
6、将特征向量进行标准化,然后降维
这就得到了我们想要的降维之后的数据。
三、案例分析
这里我们使用的数据是鸢尾花的数据集,网上相关信息也比较多,有需要的同学可以私信我。这里我们讲两个方法,一种是原始求解,一种是使用sklearn包中封装好的API
1、导入我们需要的包
from sklearn.preprocessing import StandardScaler
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
2、读取数据,划分特征值与目标值
def pca():
"""
主成分分析进行特征降维
:return:
"""
#读取数据集
data = pd.read_csv('../../数据集/机器学习/分类算法/鸢尾花数据集/iris.csv')
#划分特征值与目标值
x = data.iloc[:,0:4].values
y = data.iloc[:,4].values
print(x,y)
return None
if __name__=="__main__":
pca()

截图不完整,一共有150行数据。
3、数据标准化
#数据标准化
std = StandardScaler()
x_std = std.fit_transform(x)
print(x_std)

4、主成分分析
- 求每列的平均值
#求每列的平均值
mean_vec = np.mean(x_std,axis=0)
- 求协方差矩阵(两个方法)
# 求协方差矩阵(直接求)
cov_mat = (x_std-mean_vec).T.dot((x_std-mean_vec)) / (x_std.shape[0] -1)
#使用numpy中自带的公式求协方差矩阵np.cov(x_std.T)
cov_mat = np.cov(x_std.T)
print('Covariance matrix \n%s' %cov_mat)
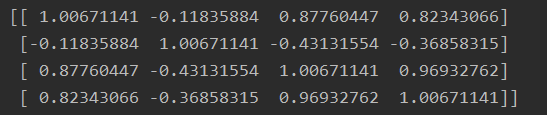
- 计算协方差的特征值和特征向量
eig_vals,eig_vecs = np.linalg.eig(cov_mat)
print('Eigenvectors \n%s' %eig_vecs)
print('\nEigenvalues \n%s' %eig_vals)
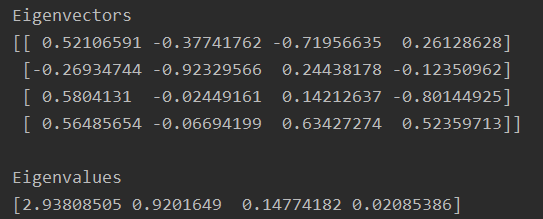
- 将特征值与特征向量对应起来并按照特征值排序
eig_pairs = [(np.abs(eig_vals[i]),eig_vecs[:,i]) for i in range(len(eig_vals))]
# print(eig_pairs)
#从高到底按特征值对eig_pairs排序
eig_pairs.sort(key=lambda x:x[0],reverse=True)
print('Eigvalues in descending order:')
for i in eig_pairs:
print(i[0])
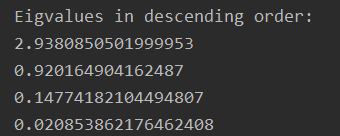
- 通过累加,确定将特征值降到几维
#通过累加,确定将特征值降到几维
tot = sum(eig_vals)
var_exp = [(i/tot)*100 for i in sorted(eig_vals,reverse=True)]
cum_var_exp = np.cumsum(var_exp)
print(cum_var_exp)
- 四维变成两维(),我们需要一个的矩阵,我们选择前两维的特征向量作为我们需要数据。
#因为前两维的数据变化比较大,所以我们决定降到2维数据,150x4->150x2 需要一个4x2的矩阵,前两维的特征向量是我们需要的2维数据
matrix_w = np.hstack((eig_pairs[0][1].reshape(4,1),eig_pairs[1][1].reshape(4,1)))#水平方向平铺
print('Matrix W:\n',matrix_w)

- 最后,我们将标准化后的数据与Matrix W相乘,得到我们降维后的数据
Y = x_std.dot(matrix_w)
print(Y)

一共150行
- 我们来对比一下,降维前与降维后的数据对比,
#画图比较进行PCA之前和之后的变化
#之前
plt.figure(figsize=(6,6))
for lab,col in zip(('setosa','versicolor','virginica'),('blue','red','green')):
plt.scatter(x[y == lab,0],
x[y == lab,1],
label=lab,
c = col)
plt.xlabel('Sepal.Length')
plt.ylabel('Sepal.Width')
plt.legend(loc='best')
plt.tight_layout()
plt.show()
#之后
plt.figure(figsize=(6,6))
for lab,col in zip(('setosa','versicolor','virginica'),('blue','red','green')):
plt.scatter(Y[y == lab,0],
Y[y == lab,1],
label=lab,
c = col)
plt.xlabel('Sepal.Length')
plt.ylabel('Sepal.Width')
plt.legend(loc='best')
plt.tight_layout()
plt.show()
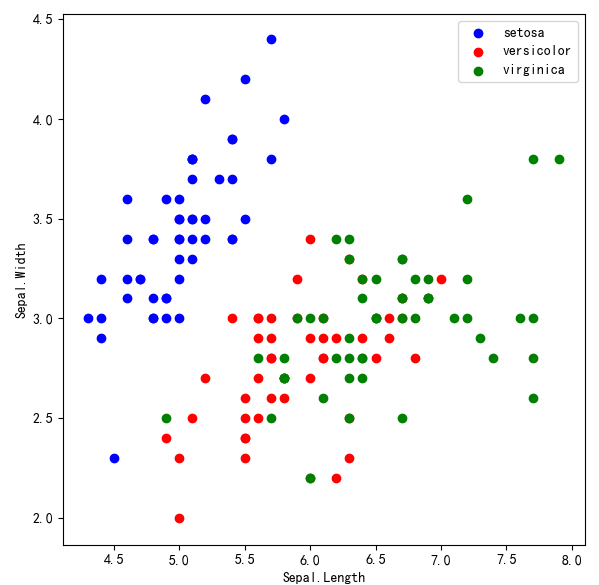

通过比较发现,经过降维之后,数据更加分明,尤其是红色与绿色部分,在降维前是比较难分离的,但是降维后我们会发现,分离效果比较明显。
补充:
sklearn中有封装好的PCA,我们可以直接调用,非常方便。
sklearn.decomposition.PCA(n_components=None, copy=True, whiten=False, svd_solver='auto', tol=0.0, iterated_power='auto',random_state=None)
- n_components:指定PCA降维后的特征维度数目
- copy表示是否在运行算法时,将原始数据复制一份。
默认为True,则运行PCA算法后,原始数据的值不会有任何改变。因为是在原始数据的副本上进行运算的。 - whiten:白化。
所谓白化,就是对降维后的数据的每个特征进行标准化,让方差都为1。对于PCA降维本身来说,一般不需要白化。如果你PCA降维后有后续的数据处理动作,可以考虑白化。默认值是False,即不进行白化。 - svd_solver:即指定奇异值分解SVD的方法
由于特征分解是奇异值分解SVD的一个特例,一般的PCA库都是基于SVD实现的。有4个可以选择的值:{‘auto’, ‘full’, ‘arpack’, ‘randomized’}。- 'randomized' 一般适用于数据量大,数据维度多同时主成分数目比例又较低的PCA降维,它使用了一些加快SVD的随机算法。
- 'full' 则是传统意义上的SVD,使用了scipy库对应的实现。
- 'arpack' 和randomized的适用场景类似,区别是randomized使用的是scikit-learn自己的SVD实现,而arpack直接使用了scipy库的sparse SVD实现。当svd_solve设置为'arpack'时,保留的成分必须少于特征数,即不能保留所有成分。默认是'auto',即PCA类会自己去在前面讲到的三种算法里面去权衡,选择一个合适的SVD算法来降维。一般来说,使用默认值就够了|
from sklearn.decomposition import PCA
import pandas as pd
import numpy as np
def pca():
"""
主成分分析进行特征降维
:return:
"""
#读取数据集
data = pd.read_csv('../../数据集/机器学习/分类算法/鸢尾花数据集/iris.csv')
#划分特征值与目标值
x = data.iloc[:,0:4].values
y = data.iloc[:,4].values
# print(x,y)
#数据标准化
std = StandardScaler()
x_std = std.fit_transform(x)
# 第二种方法:使用sklearn包
pca=PCA(n_components=2)#保留特证数目
Y=pca.fit_transform(x_std)
print(Y)
return None
if __name__=="__main__":
pca()

结果一样,使用sklearn包我们只需要三行代码就可以了,非常方便。
四、总结
1、优点
- 不受样本标签限制
- 计算方法简单,易于在计算机上实现
- 用少数指标代替多数指标
2、缺点
- 主成分解释其含义往往具有一定的模糊性,不如原始样本完整
- 贡献率小的主成分往往可能含有对样本差异的重要信息,也就是可能对于区分样本的类别(标签)更有用
- 特征值矩阵的正交向量空间是否唯一有待讨论
好了,PCA主成分分析到这里就结束了,有问题的小伙伴可以在下方留言或者私信,欢迎讨论!